формальные модели в лингвистике (копия). Лекция 1 Онтология Введение. Основные определения Онтология
 Скачать 34.36 Kb. Скачать 34.36 Kb.
|

|
Лекция 1 Онтология Введение. Основные определения: «Онтология» имеет два значения: 1) философская дисциплина, которая изучает наиболее общие характеристики бытия и сущностей; 2) артефакт, структура, описывающая значение элементов некоторой системы. Неформально О. представляет собой некоторое описание взгляда на мир применительно к конкретной области интересов. Это описание состоит из терминов и правил использования этих терминов, ограничивающих их значений в рамках конкретной области. На формальном уровне О. – это система, состоящая из набора понятий и набора утверждений об этих понятиях, на основе которых можно строить классы, объекты, отношения, функции и теории. Основными компонентами О. являются: Классы или понятия Отношения Функции Аксиомы Примеры Грубер: О. – это спецификация концептуализации. Концептуализация – это структура реальности, рассматриваемая независимо от словаря предметной области и конкретной ситуации. Например, если мы рассматриваем простую предметную область, описывающую кубики на столе, то концептуализацией является набор возможных положений кубиков, а не конкретное их расположение в текущий момент времени. В качестве примера того, что в рамках онтологий понимается под аксиомами, можно привести следующее положение и его формальную запись на языке исчисления предиката первого порядка: Работник, являющийся руководителем проекта, работает в проекте Вводятся переменные Е (работник), Р (руководитель проекта) Forall (E, P) Employee(E) and Head-Of-Project(E,P) = > Works-At-Project(E,P) Будут рассмотрены следующие вопросы: Структура конкретных онтологий таких как Онтологии верхнего уровня Онтологии вина и пищи Структура, проблемы и применение наиболее известной лингвистической онтологии WordNet Традиции использования таких ресурсов для информационного поиска, как информационно-поисковые тезаурусы, которые рассматриваются как вид онтологических ресурсов, и методы их автоматических обработки Текстов в различных приложениях в области информационного поиска. Типы онтологий: верхнего уровня, предметных областей, прикладных онтологий. Лексические онтологии. Классификация онтологий В проектировании онтологий условно можно выделить два направления, до некоторого времени развивавшихся отдельно. Первое связано с представлением онтологии, как формальной системы, основанной на математически точных аксиомах. Второе направление развивалось в рамках компьютерной лингвистики и когнитивной науки. Там онтология понималась, как система абстрактных понятий, существующих только в сознании человека, которая может быть выражена на естественном языке (или какой-то другой системой символов). При этом обычно не делается предположений о точности или непротиворечивости такой системы. Таким образом, существует два альтернативных подхода к созданию и исследованию онтологий. Первый (формальный) основан на логике (предикатов первого порядка, дескриптивной, модальной и т.п.). Второй (лингвистический) основан на изучении естественного языка (в частности, семантики) и построении онтологий на больших текстовых массивах, так называемых корпусах. В настоящее время данные подходы тесно взаимодействуют. Идет поиск связей, позволяющих комбинировать соответствующие методы. Поэтому иногда бывает сложно отделить лексические онтологии с элементами формальных аксиоматик от логических систем с включениями лингвистических знаний. Независимо от различных подходов, можно выделить 3 основных принципа классификации онтологий: По степени формальности По наполнению, содержимому По цели создания Рассмотрим соответствующие классификации по порядку. Лекция 2 Классификация по степени формальности. «Спектр онтологий» Обычно люди и компьютерные агенты (программы) имеют некоторое представление значений терминов. Программные агенты иногда предоставляют спецификацию входных и выходных данных, которые могут быть использованы как спецификация программы. Сходным образом онтологии могут быть использованы, чтобы предоставить конкретную спецификацию имен терминов и значений терминов. В рамках такого понимания (где онтология является спецификацией концептуальной модели концептуализации) существует простор для вариаций. Онтологии могут быть представлены как спектр в зависимости от деталей реализации. Словари терминов Каталоги на основе ID Неформальные таксономии Тезаурусы Отношение «Выше-Ниже» 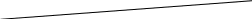 Формальные экземпляры Формальные таксономии Ограничения на значения Свойства на основе фреймов Произвольные логические ограничения Дизъюнктивные классы, обратные свойства На рисунке 1 изображен так называемый спектр онтологий по степени формальности представления, использованию тех или иных формальных элементов. Каждая точка соответствует наличию некоторых ключевых структур и онтологии, отличающих ее от друг их точек на спектре. Косая черта условно отделяет онтологии от других ресурсов, имеющих онтологический характер. Первой точке на спектре соответствует контролируемый словарь, то есть конечный список терминов (простейшим примером является каталог на основе идентификаторов). Каталог представляет точную (не многозначную) интерпретацию терминов. Например, каждый раз ссылаясь на термин. Каталоги на основе ID Словари терминов Тезаурусы Отношение «Выше-Ниже» Неформальные таксономии Формальные таксономии Формальные экземпляры Свойства на основе фреймов Ограничения на значения Произвольные логические ограничения Дизъюнктивные классы, Обратные свойства «машина» мы будем использовать одно и то же значение (соответствующее некоторому ID в словаре), вне зависимости от того, о чем идет речь в контексте: о «стиральной машине», «автомобиле» или «государственной машине». Другой спецификацией онтологии может быть глоссарий, представляющий список терминов с их значениями. Значения описываются в виде комментариев на естественном языке. Это дает больше информации, поскольку люди могут прочесть такой комментарий и понять смысл термина. Интерпретации терминов могут быть многозначными. Глоссарии непригодны для автоматической обработки программными агентами, но можно, как и ране, присвоить терминам ID. Тезаурусы несут дополнительную семантику, определяя связи между терминами. Отношения свойственные тезаурусам: синонимия, иерархическое отношение и ассоциация. Обычно тезаурусы в явном виде не имеют иерархии терминов, но она может быть восстановлена. Ранние иерархии терминов, появившиеся в Сети, определяли общие понятия обобщения и уточнения. Yahoo, например, ввела небольшое число категорий, верхнего уровня таких как «предметы одежды». Затем «Платье» определялось как вид (женской) одежды. Явная иерархия не соответствовала в точности формальным свойствам иерархического отношения (isA). В таких иерархиях может встретиться ситуация, в которой экземпляр класса-потомка также является экземпляром класса предка. Например, общая категория «предметы одежды» включает подкатегорию «женские» (которая должна более точно называться «женские предметы одежды»), а эта категория в свою очередь включает подкатегории «аксессуары» и «платья». Каждый экземпляр категории «платья» является экземпляром категории «предмет одежды» (и, возможно, экземпляром «женского платья» - ведь существуют и «кукольные платья»). Ясно, что экземпляр категории «духи» (как женские «аксессуары») не может быть экземпляром категории «предмет одежды». Здесь не выполняется важное свойство отношения isA – транзитивность. Далее следует точка «формальные таксономии». Эти онтологии включают точное определение отношения isA (класс-подкласс). В таких системах строго соблюдается транзитивность отношений isA: если B является подклассом класса А, то каждый подкласс класса В также является подклассом класса А. А для отношения класс-экземпляр (isInstanceOf) выполняется следующее свойство: если В является подклассом А, то каждый экземпляр класса В также является экземпляром класса А. Поэтому в приведенном выше примером с «духами», «духи» не могут быть помещены ниже в иерархии «предмет одежды» (аксессуары, строго говоря, не являются предметами одежды) или стать экземпляром этой категории. Строгая иерархия необходима при использовании наследования для процедуры логического выбора. Следующая точка – наличие формального отношения класс-экземпляр. Некоторые классификации включают только имена классов, другие содержат на нижнем уровни экземпляры. Данная точка спектра включает экземпляры классов. Далее среди структурных элементов появляются фреймы. Здесь классы (фреймы) могут иметь информацию о свойствах. Напри мер, класс «предмет одежды» может иметь свойства «цена», «сделанИз». Свойства бывают особенно полезными, когда они определены на верхних уровнях иерархии и наследуются подклассами. В потребительской иерархии класс продукт может иметь свойство «цена», которое получат все его подклассы. Большей выразительностью обладают понятия, включающие ограничения на область значений свойств. Значения свойств берутся из некоторого предопределенного множества (целые числа, символы алфавита) или из подмножества концептов онтологии (множество экземпляров данного класса, множество классов). Можно ввести дополнительные ограничения на то, что может заполнять свойство. Например, для свойства «сделанИз» класса «предмет одежды» значения можно получать как экземпляры класса «Материал». Легко увидеть, какие проблемы могут возникнуть в этом случае при использовании нестрогой таксономии. Если «духи» - подкласс класса «предмет одежды», то он наследует свойство «сделанИз» вместе с ограничением («Материал»). В целом с необходимостью выразить больше информации выразительные средства онтологии (и ее структура) усложняются. Например, может потребоваться заполнить значения какого-либо свойства экземпляра, используя математическое выражение, основанное на значениях других свойств и даже других экземплярах. Многие онтологии позволяют объявлять два и более классов дизъюнктивными (непересекающимися). Это означает, что у данных классов не существует общих экземпляров. Некоторые языки позволяют делать произвольные логические утверждения о концептах – аксиомы. Языки описания онтологии, подобные Cyct. и Ontolingua позволяют описывать утверждения на языке логики предикатов первого порядка (FOL). Классификация по цели создания В рамках этой классификации выделяют 4 уровня (см. рис. 2). Онтологии представления, онтологии верхнего уровня, онтологии предметных областей и прикладные онтологии. Лекция 3 Онтологии представления Цель создания: описать область представления знаний, создать язык для спецификации других отнологий более низких уровней. Пример: описание языка OWL средствами RDF. Онтологии верхнего уровня Назначение: создание единой «правильной онтологии», фиксирующей знания общие для всех ПО и многократном исп-и данной онтологии. Проекты: SUMO, Sowa’s Onthologу. Попытки создать онтологию верхнего ур-ня не привели к желаемым результатам, многие из них похожи. В них содерж-ся 1 и те же концепты: Сущность, Явление, Процесс, Объект, Роль и т.п. Онтология ПО Назначение похоже с назначением онтологий верхнего ур-ня; область интереса ограничена ПО. Примеры: АвнаОнтология, CRM. Прикладные онтологии Назначение: описать концептуальную модель определенной задачи или приложения. Они содержат наиболее специфичную инф-ю. Примеры: TOVE, Plinius. Классификация онтологий по содержимому Общие онтологии (Сущности, События, Простр-во, Время…) Онтологии задач (Сост-е расписаний, опр-е целей, классификация) Предметные онтологии (Множества предметов: скальпели, сканеры) Эта классификация похожа на предыдущую, но упор в ней делается на реальное содержимое онтологии, а не на абстрактную цель. Онтология и обработка текстов на естественном языке Необходимо понятиям онтологий сопоставить набор языковых выражений (слов и с/соч), которыми понятия могут содержаться в тексте. Способы процедуры сопоставления онтологий: Онтология может быть сделана заранее, путем логической классификации, а затем к ней могут быть приписаны языковые единицы. Онтологию предлагается создавать путем анализа – сверху вниз. При этом имена вводимых понятий должны содержать признаки, которые заложены в основу деления. Результат: имена понятий достаточно громоздкие, с ними трудно работать. Другая проблема данного подхода – приписывание языковых выражений к логически обоснованной системе понятий получается, что одно и то же слово может соотв-ть слишком большому количеству таких «правильных» понятий в зав-ти от контекста. Кроме этого, разработка подробных онтологий для реальных приложений – нетривиальная задача. Во многих ПО знание содержится в основном в текстах. Из-за внутренних свойств языка, непростой задачей является связать знания, содержащиеся в текстах с онтологиями. Главная характеристика лингвистических онтологий – то, что они связаны со значениями языковых выражений. Лингвистические онтологии охватывают большинство слов языка, одновременно имея онтологическую структуру, проявляющуюся в отношениях между понятиями. Поэтому они рассматриваются как особый вид лингвистической базы данных и особый тип онтологий. Лингвистические онтологии отличаются от формальных онтологий по степени формализации. Предположительно, их разработчики разрабатывают иерархию лексических значений естест. языка, для более строго описания знаний нужно сопоставить ресурсы с какими-либо формальными онтологиями. Так, содержанием одного из проектов является установление отношений между WordNet и EuroWordNet с одной стороны, и формальной онтологией SUMO с другой стороны. Проект состоит в том, чтобы установить соответствие между синсетами WordNet и понятиями онтологии. Участники другого проекта OntoWordNet считают, что недостаточно провести формальную склейку ресурса типа WordNet и формальной онтологии, необходима реструктуризация исходного лексического ресурса. Третий путь – попытаться разработать единый ресурс, в котором были бы сбалансированы обе части: система понятий и система лексических значений. Попытка такого подхода реализуется в онтологиях MikroKosmos, OntoSem. Лекция 4 Архитектура инструментальных ЕЯ-систем Различные ЕЯ-системы имеют различную архитектуру, однако практически все в той или иной мере предполагают разбиение на независимые модули, которые можно в общем назвать компонентами. Слои ЕЯ-системы Слой взаимодействия (communication layer), который описывает взаимодействия между различными компонентами в системе для решения задачи обработки текста; Слой данных (data layer), включающий различные форматы представления преобразования между компонентами; данных правила их Слой (interpretation layer), описывающий то, как компоненты интерпретируют те или иные данные в процессе своей работы. Компонентная организация С точки зрения организации взаимодействия точки компонентов стоит начать с классификации, которая подразделяет системы на три категории: Каждый компонент взаимодействует непосредственно с другим компонентом. В этом случае все компоненты должны иметь информацию о среде выполнения, формате данных и их интерпретации; Компоненты взаимодействуют через центральный координатор, который берет на себя ответственность за распределение задач и преобразование данных между различными форматами; Компоненты работают некоторым общим хранилищем данных, не имея информации о среде выполнения. Уточнение каждой из категорий Компоненты, взаимодействующие независимо друг с другом могут совместно работать как минимум одним из нескольких способов: Подход, основанный на потоках данных (data-flow), в котором компоненты организуют некоторый граф и обмениваются данными друг с другом по соединениям, являющимся ребрами этого графа. Примером является архитектура Сatalyst [2]. Преимущество – возможность осуществлять обработку различными распределенной среде. компонентами одновременно, возможно в распределенной среде. Другим вариантом организации компонентов является схема «каналов и фильтров», в которой компоненты передают данные между собой последовательно. Примером является архитектура LTNSL. В этом случае одновременность обработки ограничена локальностью анализа конкретных компонентов. Например, tokenizer и стеммер обрабатывают данные локально и могут успешно работать параллельно, однако компоненты, требующие анализа более протяженных сущностей, могут блокировать работу последующих компонентов. Также, знание компонентов друг о друге вовсе не является обязательным при этом подходе. Использование некоторого стандартизированного представления данных в системе позволяет компонентам взаимодействовать без наличия информации об устройстве системы. Такая информация необходима только на этапе сборки системы, осуществляемой разработчиком. Подходы, основанные на взаимодействии через центрального координатора, также имеют несколько разновидностей, но они имеют больше специфики с точки зрения реализации, поэтому здесь не имеет смысла их рассматривать. При использовании общего хранилища порядок доступа данных значительным аспектом является порядок доступа компонентов к данным. В частности, в рассматриваемых приложениях наиболее распространены две модели: Линейная схема активации, в которой компоненты работают различные последовательность обработки задается на этапе сборки системы. Подобный подход используется в системе GATE. C точки зрения одновременности обработки подход эквивалентен схеме "каналы и фильтры. Другая разновидность схема представлена в системе Ellogon, определяется на основе пред- и постусловий. Эта схема является более гибкой. Кроме того, задание предусловий позволяет организовать автоматическое формирование порядка обработки. с данными последовательно, обработки. Процессы обработки текста 1.Фиксированный процесс Один из базовых подходов к обработке текстов в ЕЯ- системах состоит в последовательном применении к тексту фиксированных обработки нескольких этапов Простейшим примером такого подхода применительно к системе перевода является следующая цепочка этапов: Графематический анализ; Морфологический анализ; Синтаксический анализ; Преобразование; Генерация текста. Такой подход не является очень гибким - достаточно часто необходимо в зависимости от тех или иных условий использовать различные этапы обработки. 2.Динамический процесс Более гибким вариантом является возможность использования в процессе обработки различных этапов в зависимости от выполнения каких-то условий. Такой подход называется динамическим процессом и часто компонента, реализуется помощью специального знания необходимом порядке инкапсулирующего знания о необходимом порядке выполнения этапов и условиях, влияющего на него. В начале обработки текст передается этому компоненту, который выбирает первый этап обработки и передает текст на него. По окончании этапа возвращается центральному компоненту, который выбирает следующий этап или возвращает его в качестве результата. 3.Вложенные процессы Часто полный текст не нужен для выполнения этапа обработки (например, синтаксический анализ производится в рамках одного предложения). В таких случаях используется вложенный процесс обработки может текста. Во вложенном процессе один или несколько из этапов обработки могут осуществлять разбиение текста (или его части) на более мелкие участки с тем, чтобы применить некоторый новый процесс к каждому из них. Например, разбить текст на предложения с тем, чтобы произвести синтаксический анализ и последующий перевод каждого предложения по отдельности. При этом каждый подпроцесс может включать другие вложенные процессы (например, разбиение предложения на слова и их обработка). 4.Итерационные процессы Другим интересным расширением процесса обработки является итеративное применение некоторой его части. Например, если есть два компонента синтаксического анализа, первый из которых осуществляет поверхностный анализ, а второй – глубокий, используя некоторый анализ в качестве первого приближения, то можно используя поверхностный анализ в качестве первого приближения глубокого к результату предыдущей итерации (или же к взвешенной сумме предыдущей и итеративно применять компонент синтаксического анализа первой итерации). В некоторых случаях использование такого подхода позволяет увеличить точность производимого анализа. Системы обработки ЕЯ-текстов Системы на базе разметки Одна из крупнейших ветвей систем обработки ЕЯ-текстов основана на представлении лингвистической информации в форме разметки в одном из стандартных форматов, например SGML и XML. При этом различные компоненты системы обычно обмениваются размеченными документами в текстовой форме. LT-NSL (разработан в 1996году как система для обработки больших корпусов текста) Для представления лингвистической информации в системе LТ-NSL используется разметка в документе на языке SGML. Такое решение мотивировано следующим: SGML – четко определенный язык, позволяющий задавать структурную информацию в тексте; Доступ приложения к тексту в SGML может быть осуществлен с выбором необходимого уровня абстракции. В частности, приложение может просто игнорировать узлы, не затрагиваемые конкретным видом анализа; SGML способствует формальному описанию используемой нотации и предоставляет утилиты для проверки соответствия документов этому формальному описанию. Wraetlic (2000-2006) Использование разметки легко объединять компоненты мотивировано возможностью в систему используя стандартные средства операционной системы, такие как каналы. Лингвистическая разметка представляется в форме XML, этом проблема разметки решена путем использования внешних XМL-узлы и ссылок в документе. Для обработки такой разметки реализован специальный модуль, позволяющий извлекать при представления пересекающейся участки документа по ссылкам. Преимуществом использования XМL является возможность простого создания инструментов для визуализации результатов в виде XSLT-преобразований, генерирующих данные для браузера. Системы на базе аннотаций Значительное влияние на ЕЯ-системы оказал проект ТIPSTER, проводимый в 1991-1998 годах. Целью проекта было проведение исследований и разработок в области извлечения информации. Одним из направлений проекта было создание стандартной архитектуры для систем, осуществляющих извлечение информации из текстов на естественном языке, позволяющей решить следующие задачи: Задачи Предоставление программного интерфейса для задач и управления документами в системе и извлечения информации из них; Поддержка одноязычных и многоязычных приложений; Обмен модулями различных разработчиков; Работоспособность в различном аппаратном и программном окружении; Масштабируемость на различные объемы документов и потоки их обработки; Небольшое время отклика приложений; Возможность использования многоуровневой системы безопасности; |