Лингвистическое и программное обеспечение систем. Лингвистическое и программное обеспечение систем
 Скачать 0.87 Mb. Скачать 0.87 Mb.
|

   Министерство образования и науки Российской Федерации Министерство образования и науки Российской ФедерацииФедеральное государственное бюджетное образовательное учреждение высшего профессионального образования «» Факультет электроники и вычислительной техники Кафедра «» Семестровая работа по дисциплине «Лингвистическое и программное обеспечение систем» Выполнил: Группы: Шифр Проверил: Тамбов, 2019 ОглавлениеПоисковые системы 8 Список литературы: 22 Семантика – раздел языкознания, изучающий значение единиц языка, прежде всего его слов и словосочетаний. В более общем смысле, семантика определяет смысл знаков (образов, обозначений) и их сочетаний. Семантическая сеть — информационная модель предметной области, имеющая вид ориентированного графа, вершины которого соответствуют объектам предметной области, а дуги (рёбра) задают отношения между ними. Объектами могут быть понятия, события, свойства, процессы. Таким образом, семантическая сеть является одним из способов представления знаний. В семантической сети роль вершин выполняют понятия базы знаний, а дуги (причем направленные) задают отношения между ними. Таким образом, семантическая сеть отражает семантику предметной области в виде понятий и отношений. Семантизация — процесс изменения текстов, в которых выделяются семантические отношения без изменения их содержания. Попытка создания семантической сети на основе Всемирной паутины получила название семантической паутины. Эта концепция подразумевает использование языка RDF (языка разметки на основе XML) и призвана придать ссылкам некий смысл, понятный компьютерным системам. Это позволит превратить Интернет в распределённую базу знаний глобального масштаба. В качестве понятий обычно выступают абстрактные или конкретные объекты (огурец, машина, любовь, Маша). В качестве отношений наиболее часто используются следующие (смысловая классификация): - таксономические («класс – подкласс – экземпляр», «множество – подмножество – элемент» и т.п.). Данный тип отношения называют также отношением AKO (англ. A Kind Of – является разновидностью), IS A (является, это есть) или гипонимии (гипероним – общая сущность; гипоним – частная сущность); - структурные («часть – целое»). Данный тип отношения называют также отношением Part of (является частью), Has part (состоит из, включает в себя), агрегации (лат. aggregatio – присоединение), композиции (лат. compositio – составление, связывание, сложение, соединение) или меронимии (холоним – сущность, включающая в себя другие; мероним – сущность, являющаяся частью другой); - родовые («предок» - «потомок»); - производственные («начальник» - «подчиненный»); - функциональные (определяемые обычно глаголами «производит», «влияет» и т.п.); - количественные (больше, меньше, равно и т.п.); - пространственные (далеко от, близко от, за, под, над и т.п.); - временные (раньше, позже, в течение и т.п.); - атрибутивные (иметь свойство, иметь значение); - логические (И, ИЛИ, НЕ); - казуальные (причинно-следственные). Отношения можно также классифицировать по степени участия (арности) понятий в отношениях: - унарное (рекурсивное) - отношение связывает понятие само с собой; - бинарное - отношение связывает два понятия; - N-арное - отношение, связывающее более двух понятий. Классифицировать семантические сети можно по следующим признакам: - по количеству типов отношений: - однородные (с единственным типом отношений); - неоднородные (с различными типами отношений); - по назначению. Обычно совпадает с преобладающим типом отношений, например: - классифицирующие - позволяют описывать различные иерархические отношения между понятиями. Могут содержать таксономические, структурные, родовые и производственные отношения. В частности, если известную биологическую классификацию Карла Линнея (жизнь – домен – царство – тип – класс – порядок – семейство – род – вид) представить в виде семантической сети, то отношения между понятиями разных уровней можно рассматривать одновременно как таксономические и структурные (например, семейство является одновременно разновидностью и частью порядка); - функциональные — вычислительные модели, позволяющие описывать процедуры вычислений одних информационных единиц через другие; - сценарии — используются для описания казуальных отношений (причинно-следственных или устанавливающих влияние одних явлений или фактов на другие), а также отношений типа «средство — результат», «орудие — действие» и т.п.; - другие. Большая популярность семантических сетей объясняется их высокой ассоциативностью, и гибкостью в представлении информации. Основным же недостатком данного подхода является то, что современные ЭВМ все еще недостаточно эффективно работают с такими сложно-структурированными данными, как сети, причем время решения задач на сетях значительно зависит от их объема и может оказаться неприемлемым для больших баз знаний. Однако с прогрессом вычислительной техники этот недостаток становится все менее существенным. В качестве примера представления информации в виде семантической сети рассмотрим пример с классом «Бытовая техника». Фрагмент семантической сети, которая описывает иерархию классов данной предметной области, может быть изображен следующим образом. На данном рисунке отдельные вершины семантической сети изображаются прямоугольниками и служат для условного обозначения классов данной предметной области. Соединяющие вершины ребра имеют вполне определенный смысл или семантику. А именно, они явно указывают, что вершина или класс, расположенные на рисунке ниже, являются подклассом того класса уровнем выше, с которым имеется связь в форме соединяющего их ребра. Например, классы «Телевизоры» и «Чайники» и «Пылесосы» являются подклассами класса «Бытовая техника», а класс «Model A» является подклассом класса «Sharp». Ребра или связи данной семантической сети имеют единственный тип, определяемый семантикой включения классов друг в друга. Поэтому никаких дополнительных обозначений они не содержат. 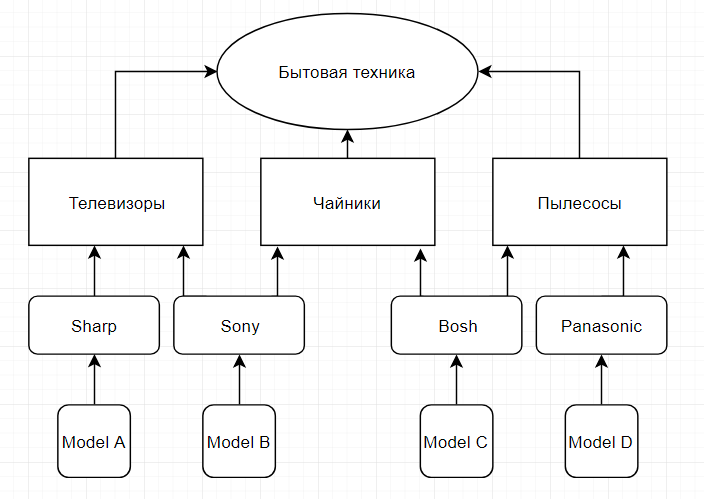 Рис 1. Фрагмент семантической сети для представления иерархии классов «Бытовая техника» Пример семантической сети, которая отражает иерархию подчиненности и понятий на корабле (рис. 2).  Рис. 2. Семантическая сеть «Корабль». Приведенные связи показывают подчиненность корабля. Также показывает разницу между PART OF и IS-A на примере класса «океанский лайнер». Поисковые системыПоисковая система - это программно-аппаратный комплекс, предназначенный для осуществления поиска в сети Интернет и реагирующий на запрос пользователя, задаваемый в виде текстовой фразы (поискового запроса), выдачей списка ссылок на источники информации, в порядке релевантности (в соответствии запросу). Наиболее крупные международные поисковые системы: «Google», «Yahoo», «MSN». В русском Интернете это – «Яндекс», «Рамблер», «Апорт». Для поиска информации с помощью поисковой системы пользователь формулирует поисковый запрос. Работа поисковой системы заключается в том, чтобы по запросу пользователя найти документы, содержащие либо указанные ключевые слова, либо слова, как-либо связанные с ключевыми словами. При этом поисковая система генерирует страницу результатов поиска. Такая поисковая выдача может содержать различные типы результатов, например: веб-страницы, изображения, аудио файлы. Некоторые поисковые системы также извлекают информацию из подходящих баз данных и каталогов ресурсов в Интернете. 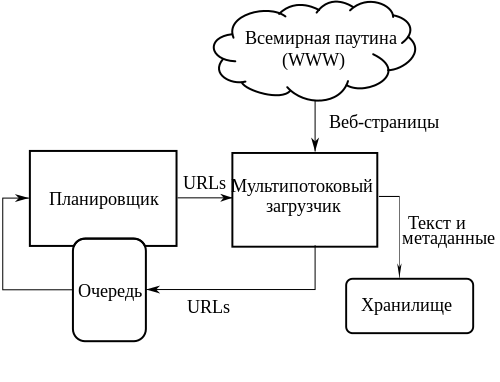 Рис. 3. Структура поисковой системы Основные составляющие поисковой системы: поисковый робот, индексатор, поисковик. Как правило системы работают поэтапно. Сначала поисковый робот получает контент, затем индексатор генерирует доступный для поиска индекс, и наконец, поисковик обеспечивает функциональность для поиска индексируемых данных. Чтобы обновить поисковую систему, этот цикл индексации выполняется повторно. Поисковые системы работают, храня информацию о многих веб-страницах, которые они получают из HTML страниц. Поисковый робот — программа, которая автоматически проходит по всем ссылкам, найденным на странице, и осуществляет поиск новых документов, ещё не известных поисковой системе. Поисковая система анализирует содержание каждой страницы для дальнейшего индексирования. Индексатор — это модуль, который анализирует страницу, предварительно разбив её на части, применяя собственные лексические и морфологические алгоритмы. Данные о веб-страницах хранятся в индексной базе данных для использования в последующих запросах. Индекс позволяет быстро находить информацию по запросу пользователя. Использование КЭШа помогает ускорить извлечение информации с уже посещённых страниц. Кэшированные страницы всегда содержат тот текст, который пользователь задал в поисковом запросе. Поисковик работает с выходными файлами, полученными от индексатора, он принимает пользовательские запросы, обрабатывает их при помощи индекса возвращает результаты поиска. Когда пользователь вводит запрос в поисковую систему (обычно при помощи ключевых слов), система проверяет свой индекс и выдаёт список наиболее подходящих веб-страниц, содержащей заголовок документа и иногда части текста. Поисковый индекс строится по специальной методике на основе информации, извлечённой из веб-страниц. Полезность поисковой системы зависит от релевантности найденных ею страниц. Хоть миллионы веб-страниц и могут включать некое слово или фразу, но одни из них могут быть более релевантные, популярны или авторитетны, чем другие. Большинство поисковых систем использует методы ранжирования, чтобы вывести в начало списка «лучшие» результаты. Так появились два основных типа поисковых систем: системы предопределенных и иерархически упорядоченных ключевых слов и системы, в которых генерируется инвертированный индекс на основе анализа текста. Существует четыре типа поисковых систем:
Google – это поисковая система, которая использует количество ссылок на веб-сайт, как основной параметр популярности сайта. Это особенно полезно при поиске хороших сайтов с помощью простых поисковых запросов. Google знаменит высокой релевантностью ссылок. Google имеет очень большую базу данных проиндексированных сайтов и предоставляет часть своих результатов Yahoo и Netscape Search. Google определенным образом отличается от остальных глобальных систем поиска. Если Яндекс, прежде всего, - это поиск, а уже потом все остальное, то Google - это качественные сервисы-монополисты, например, YouTube и Blogger. Основным преимуществом поисковой системы Google все называют простоту ее использования. Среди прочих положительных качеств можно отметить:
Достижения и новинки поисковой компании Google:
Отличительная особенность Yandex – интуитивный поиск во всех словоформах. Уникальная разработка под особенности русского языка. В каталоге Яндекса используется такое понятие, как тематический индекс цитирования (тИЦ). Он определяется количеством и качеством внешних ссылок на ваш сайт. На качество ссылки влияет тИЦ ресурса, ссылающегося на вас. Немаловажную роль играет тематическая близость вашего сайта ссылающимися на вас ресурсам. При подсчете индекса цитирования не берутся во внимание ссылки с форумов, веб-досок, конференций, сайтов, расположенных на бесплатных хостингах (если они не описаны в каталоге Яндекса). Естественно, не учитываются ссылки с тех сайтов, которые Яндекс не индексирует (например, зарубежные сайты). Количество хостов зависит от посетителей (чем их больше, тем больше хостов), а индекс цитирования Яндекса – от авторов сайтов (чем больше авторов поставят ссылку на ваш ресурс, тем выше значение CY). По значению индекса цитирования определяется релевантность ресурса в каталоге Яндекса и, соответственно, позиция вашего сайта в выбранном разделе. Переиндексация документа происходит примерно раз в две недели, но под каждый сайт робот подстраивается в отдельности. Все зависит от частоты обновления. По словам Яндекса, тег < meta name="Revizit-after" content="n-days"> никакой роли в работе робота не играет. Яндекс индексирует российскую сеть, поэтому в поисковую машину вносятся сервера в доменах su, ru, am, az, by, ge, kg, kz, md, ua, uz. Остальные сервера вносятся, только если на них найден текст на русском языке. Информация в заголовке (тег < title >) Яндекс отображает в результатах поиска. Слова, находящиеся в теге < title >, имеют больший вес чем все остальные. Ключевые слова в теге < meta> также увеличивают вес слова в документе, но только если само слово находится на странице. Помимо вышеперечисленных способов, на релевантность слова влияют частота его использования в заголовках (< h1>, < h2> ...), в атрибуте alt, во всплывающих подсказках (тег < acronym>) и процент встречаемости этого слова в документе, т.е. как часто вы его используете. Но при этом необходимо сохранить смысл документа, иначе Яндекс может посчитать это слово спамом. Достижения:
Системы анализа речи На сегодняшний день, под понятием “распознавание речи” скрывается целая сфера научной и инженерной деятельности. В общем, каждая задача распознавания речи сводится к тому, чтобы выделить, классифицировать и соответствующим образом отреагировать на человеческую речь из входного звукового потока. Это может быть и выполнение определенного действия на команду человека, и выделение определенного слова-маркера из большого массива телефонных переговоров, и системы для голосового ввода текста. Каждая такая система имеет некоторые задачи, которые она призвана решать и комплекс подходов, которые применяются для решения поставленных задач. Рассмотрим основные признаки, по которым можно классифицировать системы распознавания человеческой речи и то, как этот признак может влиять на работу системы. Размер словаря. Очевидно, что чем больше размер словаря, который заложен в систему распознавания, тем больше частота ошибок при распознавании слов системой. Например, словарь из 10 цифр может быть распознан практически безошибочно, тогда как частота ошибок при распознавании словаря в 100000 слов может достигать 45%. С другой стороны, даже распознавание небольшого словаря может давать большое количество ошибок распознавания, если слова в этом словаре очень похожи друг на друга. Дикторозависимость или дикторонезависимость системы. По определению, дикторозависимая система предназначена для использования одним пользователем, в то время как дикторонезависимая система предназначена для работы с любым диктором. Дикторонезависимость – труднодостижимая цель, так как при обучении системы, она настраивается на параметры того диктора, на примере которого обучается. Частота ошибок распознавания таких систем обычно в 3-5 раз больше, чем частота ошибок дикторозависимых систем. Раздельная или слитная речь. Если в речи каждое слово разделяется от другого участком тишины, то говорят, что эта речь – раздельная. Слитная речь – это естественно произнесенные предложения. Распознавание слитной речи намного труднее в связи с тем, что границы отдельных слов не четко определены и их произношение сильно искажено смазыванием произносимых звуков. Назначение. Назначение системы определяет требуемый уровень абстракции, на котором будет происходить распознавание произнесенной речи. В командной системе (например, голосовой набор в сотовом телефоне) скорее всего, распознавание слова или фразы будет происходить как распознавание единого речевого элемента. А система диктовки текста потребует большей точности распознавания и, скорее всего, при интерпретации произнесенной фразы будет полагаться не только на то, что было произнесено в текущий момент, но и на то, как оно соотносится с тем, что было произнесено до этого. Также, в системе должен быть встроен набор грамматических правил, которым должен удовлетворять произносимый и распознаваемый текст. Чем строже эти правила, тем проще реализовать систему распознавания и тем ограниченней будет набор предложений, которые она сможет распознать. 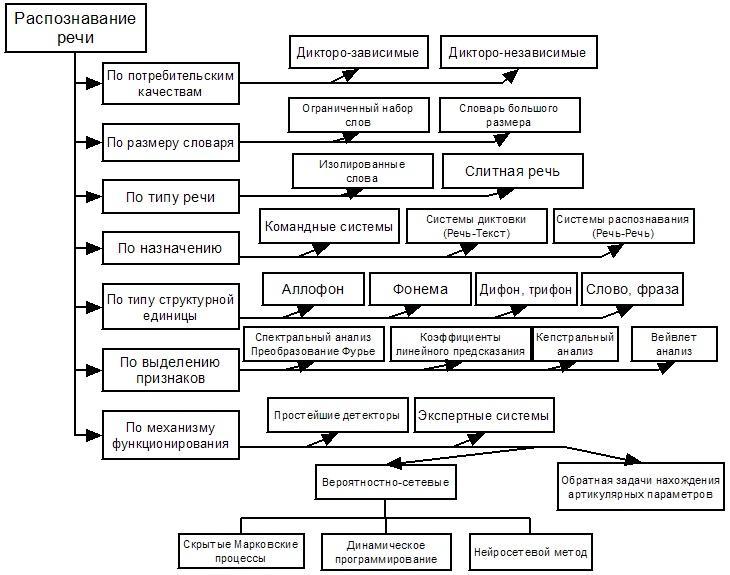 Рис. 4. Классификация систем анализа речи Примеры существующих систем анализа речи: Google Voice Search С недавнего времени голосовой поиск от Google встроен в браузер Google Chrome, что позволяет использовать этот сервис на различных платформах. Характеристики: - поддержка русского языка; - возможность встраивать распознавание речи на веб-ресурсы; - голосовые команды, словосочетания; - для работы необходимо постоянное подключение к сети internet. Способы анализа речи можно разделить на группы: конкатенативный, или компиляционный (компилятивный) синтез; параметрический синтез; предметно-ориентированный синтез. синтез по правилам; VoiceNavigator Это высокотехнологичное решение для контакт-центров, предназначенное для построения Систем Голосового Самообслуживания (СГС).VoiceNavigator позволяет автоматически обрабатывать вызовы с помощью технологий синтеза и распознавания речи. Характеристики: - дикторонезависимость; - устойчивость к окружающим шумам и помехам в телефонном канале; Yandex Speech Kit. Технология распознавания и синтеза речи от российской компании Яндекс. Система состоит из комплекса речевых технологий Яндекса, который включает в себя:
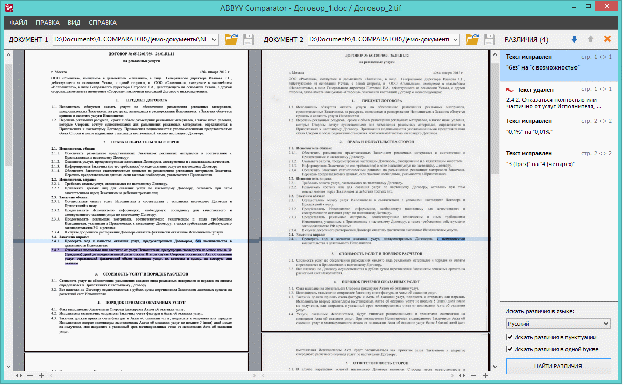
Имеет тяжелую для восприятия документацию и ограничения по количеству запросов: 10 000 в сутки. По уверению разработчиков — этот инструментарий является номером 1 для русского языка и, что исследовательская группа компании смогла сделать технологический прорыв в этой области. Системы анализа текста Интеллектуальный анализ текстов (text mining) — направление в искусственном интеллекте, целью которого является получение информации из коллекций текстовых документов, основываясь на применении эффективных в практическом плане методов машинного обучения и обработки естественного языка. Название «интеллектуальный анализ текстов» перекликается с понятием «интеллектуальный анализ данных» (data mining), что выражает схожесть их целей, подходов к переработке информации и сфер применения; разница проявляется лишь в конечных методах, а также в том, что ИАД имеет дело с хранилищами и базами данных, а не электронными библиотеками и корпусами текстов. Методы анализа текста бываю следующих видов. Графематический анализ — метод начального анализа естественного текста, представленного в виде цепочки ASCII символов, вырабатывающая информацию, необходимую для дальнейшей обработки Морфологическим и Синтаксическим процессорами. Морфологический анализ — метод основан на подборе возможных решений для отдельных частей задачи (так называемых морфологических признаков, характеризующих устройство) и последующем систематизированном получении их сочетаний (комбинировании). Синтаксический анализ (парсинг) — преобразование последовательности символов на естественном или искусственном языке в соответствии с формальной грамматикой. Проверка правописания — метод проверки заданного текста на предмет наличия в нём орфографических, пунктуационных, а также стилевых ошибок. Построение конкордансов —– получение списока всех употреблений заданного языкового выражения (например, слова) в контексте, возможно, со ссылками на источник. Извлечение именованных сущностей — одна из ключевых задач систем автоматической обработки текста. В заглавии поста приведена примерная иллюстрация того, что нас ждет. Именованные сущности — это объекты определенного типа, чаще всего составные, например, названия, имена людей, даты, места, денежные единицы и.т.д. В общем смысле это все те объекты, которые можно вытащить из текста. ABBYY. ABBYY — российская компания-разработчик решений в области распознавания текстов (OCR) и лингвистики. Наиболее известные продукты — программа для распознавания текстов ABBYY FineReader, система потокового ввода данных ABBYY FlexiCapture и электронные словари ABBYY Lingvo. В 2008 году FineReader поставлялся с устройствами ведущих производителей, таких как Fujitsu, Panasonic и Xerox. ABBYY Comparator – универсальное решение для сравнения двух версий документа в различных форматах. Программа быстро выявляет значимые несоответствия в тексте и помогает предотвратить подписание или публикацию некорректной версии документа. Основные возможности
Рис.5. ABBYY Comparator. Программа поможет существенно сэкономить время юристам, менеджерам по продажам, финансистам, логистам, а также всем офисным сотрудникам, которые сталкиваются со сравнением документов – договоров, актов, прайс-листов или других материалов. Кроме того, доступен инструментарий разработчика – технологии сравнения документов в различных форматах можно встроить в существующие IT-системы предприятия или в приложения сторонних разработчиков. Достоинства: анализ текста; развивающийся производитель; доступность пробной версии; доброжелательный интерфейс; необходимая техническая поддержка. Недостатки: бесплатная ограниченная версия. TextAnalyst 2.0 Программа построения семантической сети понятий, выделяемых из обрабатываемого текста, со ссылками на контекст. Позволяет анализировать текст путем построения иерархического дерева тем/подтем, затрагиваемых в тексте. Также имеется возможность реферирования текста. Лингвистический анализ проводится в основном на основе Стемминга. Рис.6 TextAnalyst 2.0 Морфологический анализ реализован для сравнительно небольшого количества слов. Из лингвистического анализа исключаются не только стоп-слова, но и все глаголы. Синтаксический и семантический машинный анализ тестов не реализован. SDK реализует функции лемматизации для русского и английского языков, построения частотных списков понятий, поиска слов в контексте. TextAnalyst Lib реализует создание гипертекстовых связей выявляемых понятий. Недостатки: при поиске не учитывается порядок слов. Достоинства : функции лемматизации для русского и английского языков. SyTech ИАС "АРИОН". Информационно-аналитическая система «АРИОН» - мощное средство работы с разнородными источниками информации, использующее инновационные технологии извлечения и обработки знаний. Система позволяет работать как со структурированными (таблицы, базы данных, xml), так и неструктурированными (документы и тексты на естественном языке) источниками информации. В основу системы «АРИОН» заложены алгоритмы обработки информации, разработанные компанией «САЙТЭК» совместно с ИПИ РАН. Результатом работы Лингвистического процессора является набор объектов и связей между ними, который традиционно представляют в виде так называемой фактографической (семантической) сети. Система работает по принципу извлечения именованных сущностей - это задача автоматического извлечения (построения) структурированных данных из неструктурированных или слабоструктурированных машиночитаемых документов. 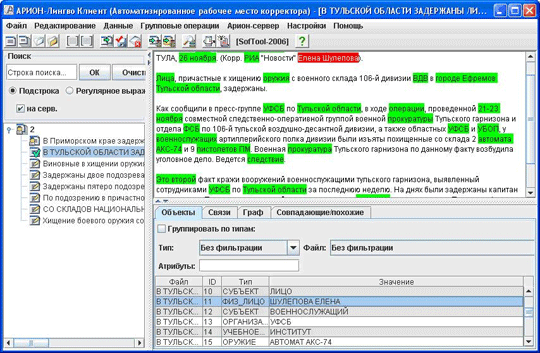 Рис.7. Интерфейс АРИОН ИАС «АРИОН» позволяет эффективно решать следующие классы задач: выделение значимых материалов из больших информационных массивов; поиск, извлечение, анализ и обобщение информации по интересующим объектам, фактам и событиям; формирование онтологий предметных областей; мониторинг деятельности организации; расследование происшествий и инцидентов; сбор и ведение досье на объекты учета; оперативная обработка и мониторинг материалов СМИ; аналитическая обработка обращений граждан и организаций В настоящее время система не имеет аналогов на российском рынке, как с точки зрения технологичности, так и с точки зрения функциональности и удобства применения. Платформа: JAVA. Достоинства: анализ русского текста; Недостатки: отсутствие бесплатной пробной (демо) версии. WordTabulator программа анализа текстов в среде Windows 9x/NT/2000/XP. Позволяет построить упорядоченные индексы словоформ или словосочетаний заданной размерности для множества входных текстов в ASCII-формате или HTML. Поддерживает основные кириллические кодировки. Возможность поиска с использованием символов маскирования. Имеет встроенный морфологический модуль, позволяюший искать все видоизменения русских слов, заданных базовой формой. Позволяет осушествлять контекстный просмотр результатов, представленных в виде гипертекстового индекса. Возможность анализа двух текстовых корпусов на сходство или различие. Рис.8. Интерфейс WordTabulator Недостатки: сортировка индекса, содержащего сотни тысяч различных элементов может оказаться весьма затруднительной. Достоинства: позволяет строить упорядоченные индексы встречающихся в тексте морфологических и синтаксических элементов - словоформ, словосочетаний заданной размерности или синтагм. Link Grammar Parser for Russian On-line программа синтаксического анализа предложений русского языка. Создана по образу Link Grammar Parser. Алгоритм работы синтаксического анализатора основан на использовании разработанной грамматики связей для русского языка. Доступен для тестирования web интерфейс программы. Алгоритм работы синтаксического анализатора основан на использовании грамматики связей. Морфологический словарь используется от aot.ru. Программа реализована на unix C, Perl под лицензией Apache License. Программа и исходные коды распространяются на коммерческой основе.   Рис.9 Link Grammar Parser for Russian On-line Достоинства: открытый доступ к сайту. Недостатки: требуется доступ в интернет. Список литературы:
|