Статья в Бишкек. Методы извлечения терминов из нормативной документации на основе онтологии Аннотация
 Скачать 285.96 Kb. Скачать 285.96 Kb.
|

|
Сакан Ерлан Мухтарханулы ye.sakan@aues.kz Утегенова Анар Урантаевна an.utegenova@aues.kz Методы извлечения терминов из нормативной документации на основе онтологии Аннотация В статье приведен анализ методов обработки нормативных документов, описаны методы извлечения сущностей для классификации документов. Традиционно специалисты в области стандартизации при сортировке документов по разделам тратят больше времени на чтение документов и пониманию сути, использование автоматической классификации документов с помощью NLP ускоряет данный процесс, а также исключает человеческие ошибки. В данной работе описаны и реализованы основные методы очистки неструктурированных данных, такие как токенизация, стэмминг, лемматизация, удаление пробелов, стоп-слов и приведении его к структурированному виду. Проведен сравнительный анализ с аналогичными программами и указаны преимущества реализованного алгоритма. Реализованный алгоритм, использует методы из области NLP, классифицирует нормативные документы по разделам, такие как раздел информационных систем, раздел медицины, раздел стандартизации и т.д. Вступление Одним из стратегических вопросов для промышленного Казахстана является межгосударственная, региональная стандартизация, для успешного осуществления торгово-экономического и научно-технического сотрудничества различных стран. Целью данной статьи является разработка интеллектуальной автоматизированной системы управления, мониторинга и контроля процессами операционного цикла разработки стандарта с применением технологических интеграций оптимальных методов создания единого репозитория метаданных в соответствии с разрабатываемыми стандартами и требованиями на основе экспертных систем. Для реализации проекта планируется применение представление стандартов и нормативных требований в форме размеченного текста, автоматизация разметки текстов с применением системного подхода по методологии онтологического инжиниринга, для дальнейшего формирования связей между стандартами, и исключения противоречий или несоответствий терминологического единства действующих нормативных документов РК. Сложный процесс извлечения информации порождает новые модели, методы и технологии, которые в настоящее время все больше ориентируются на природу данных. Проследить историю возникновения и написания национального стандарта на сегодняшний день является очень трудозатратным процессом. Быстрые темпы развития новых технологий порождают рост услуг и инфраструктуры современной стандартизации, при этом все больше усиливаются проблемы отставания ее результативности. В статье рассматривается основная проблема для разработчиков стандарта на государственном (казахском) языке в части небольшого отклонения от семантическо-терминологического смысла и логики, смежных или взаимосвязанных стандартов. Приводится краткое решение задач проблем обработки неструктурированной информации. Одним из предполагаемых решений представленной проблемы авторы статьи видят в представлении данных в виде онтологий. Возможность использования онтологий представлена анализом инженерии знаний, которые допустимо решают задачи искусственного интеллекта и информатики; в приложениях, связанных с управлением знаниями, обработкой естественного языка, электронной коммерцией, интеллектуальной интеграцией информации, поиском информации, интеграцией баз данных, биоинформатикой и образованием; и в новых развивающихся областях, таких как Семантическая сеть. Проблемы, с которыми сталкиваются международные органы по стандартизации, становятся все более актуальными по мере того, как количество и размер производимых ими стандартов увеличиваются. Иногда также отсутствие координации среди комитетов, отвечающих за разработку стандартов, может привести к дублированию, ошибкам или несовместимости в документах. Цель исследования - представить методологию, позволяющую автоматически извлекать технические данные, сущности (термины), встречающиеся в нормативных документах, посредством использования семантических инструментов, происходящих из области языковой обработки, такие как онтологические методы В рамках выполнения задач была разработана схема взаимодействия единой базовой онтологии стандартов. 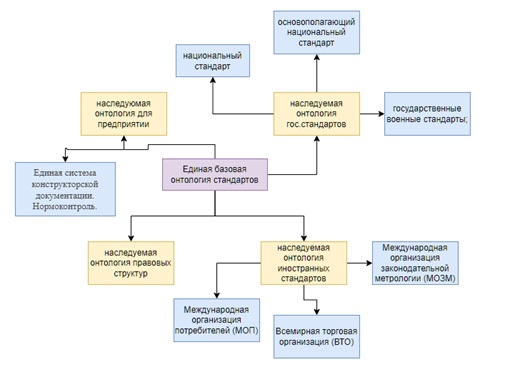 Рисунок 1. Единая базовая онтология стандартов При разработке алгоритма были выделенны используемые технологии: Back end- Spring Boot, Среда разработки- IntelliJ Idea Ultimate, Visual Studio code, Front end- React.js, БД- MySQL, Сборка библиотек- Apache Maven, Сервер приложении- Apache Tomcat, API онтологии- Apache Jena/ 1. Обзор методов обработки текстовой информации Подробная класификация методов обработки текстовой информации представлена в учебном пособии «Автоматическая обработка текстов на естественном языке и анализ данных» Большакова Е.И. и группы соавторов, представленный анализ помогает выявить подходы и методы для обработки естественного языка[1]. В настоящее время для создания модулей лингвистических процессоров применяется два главных подхода: основанных на правилах (rulebased), инженерный и основанный на машинном обучении (machine learning).[1] В рамках подхода, основанного на машинном обучении, источником лингвистической информации выступают не правила, а отобранные тексты проблемной области. Среди методов, применяемых в рамках подхода, выделяют методы обучения с учителем (supervised), методы обучения без учителя (unsupervised), методы частичного обучения с учителем (bootstrapping).[1] Разновидностями признаковой модели являются модель BOW (bag of words — мешок слов), в которой текст характеризуется набором значимых слов (обычно это все знаменательные слова, точнее, их леммы), а также векторная модель текста, в которой указанный набор упорядочен. Векторная модель применяется, например, в информационном поиске, при этом в качестве признаков чаще берутся не слова, а более сложные характеристики, такие как показатель TF-IDF для слов.[1] Разбор морфем — малоизученная задача в области компьютерной лингвистики, тогда как для русскоязычных текстов практически отсутствует. Однако, как отмечалось выше, введение функции морфемного синтаксического анализа может значительно расширить область применения морфологического процессора, особенно для такого сильно флективного языка как русский[2]. Метод Харриса базируется на простой идее подсчета количества различных букв в словах корпуса или словаря, идущих после различных начальных частей слова и перед конечными частями слова. На рисунке 1.1 приведен пример такого подсчета: в верхней строке находятся количества различных букв в словах словаря, идущих после начальной части данной длины, в нижней находятся количества перед конечной частью слова на морфемы происходит с помощью нахождения пиков (локальных максимумов) в каждом из рядов. В том месте, где обнаружен пик, и находится граница морфем слова [1] 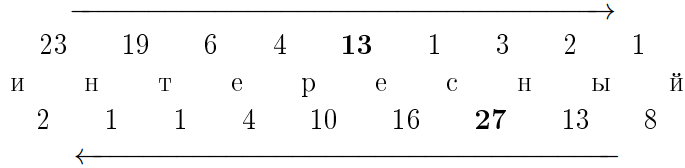 Рисунок 2 Количество различных букв c аффиксами слова Этот метод существенно зависит от исходного корпуса слов. Основным недостатком метода для высокофлективных языков является проблема чрезмерного деления полученного аффикса на набор более коротких морфем (пересегментация). Как отмечают авторы, они избегали таких разделение из-за наличия однобуквенных морфем, иначе слово превратилось бы в набор однобуквенных морфем. Метод Дежона является расширением метода Харриса и состоит из три этапа: поиск начальных морфем, поиск дополнительных морфем, сегментация слов. На первом этапе алгоритм использует метод Харриса, однако нет поиска пиков по количеству различных последующих буквы, и нахождение значений, превышающих определенный порог (половину длины алфавита). На втором этапе завершается список морфем: с помощью найденного на первом этапе набора от слова отделяется известная морфема, а если оставшаяся часть встречается с другим аффиксом более 𝑛 раз, то этот аффикс также входит в список морфем. После первых двух этапов строится список морфем и слово сегментируется по жадному алгоритму: ищется набор морфем суффикс или префикс максимальной длины, соответствующий концу или началу слова соответственно.[1] Для сильно флективного языка наиболее распространенный подход к решению задачей морфологического анализа является словарная морфология на основе словаря словоформ [3]. В основе морфологического процессора, построенного на такой морфологии, лежит создание словаря всех форм язык, который можно представить в виде таблицы Определение нормальной формы и морфологических характеристик сводится к поиску словоформы в таблице. Синтез словоформы, похожей таким образом сводится сначала к нахождению нормальной формы, а затем формы соответствующие требуемым морфологическим характеристикам. Серьезной проблемой всех словарных морфологий, особенно тех, которые основаны на словарях словоформ, является структура хранения словаря, которая может занимать несколько гигабайт. Однако при использовании эффективной структуры данных даже более обширный словарь словоформ становится не только хорошей теоретической моделью, но и удобным практическим инструментом. Преимуществом является возможность выполнения анализ и синтез. К основным недостаткам словарных морфологий следует отнести включают: проблему разбора слов, которых нет в словаре, необходимость качественный и объемный словарь, проблема морфологической омонимии[4]. Метод Бернхарда [1] также основан на методе Харриса и имеет несколько дополнительных шагов для уточнения результата. Во-первых шаг использует метод Харриса, чтобы получить список всех суффиксов и префиксы из входных слов. На втором этапе выявляются основы слов с помощью простого перебора всех возможных аффиксов слова, полученные с помощью различных комбинаций аффиксов, выявленных на первом этапе. Набор оснований в этом случае очень велик, поэтому используются некоторые эвристики, например, предположение, что длина основы не может быть меньше трех символов. На третьем этапе происходит сегментация слова на морфы путем сравнения слов с одинаковыми основами. Сравнение заключается в том, чтобы найти границы между общие и разные части слова. После третьего шага для одного слова могут быть обнаружены несколькими различными разборами. Для выбора наилучшего используется жадный алгоритм поиска наилучших результатов. В случае выбора между несколькими аффиксами выбирается наиболее частотный. Также применяются простые эвристики, например, префикс не может стоять после суффикса. Метод был протестирован на нескольких языках, в результате чего оценки 𝐹-меры были получены в диапазоне от 24 до 60 процентов. Метод системы Морфессора также использует статистику, собранную с неразмеченного корпуса, но не основан на методе Харриса, а основан на алгоритме машинного обучения. Алгоритм пытается найти баланс между компактным описанием словаря морфов и, в то же время, компактным членением слов корпуса с использованием этих морфов. Morfessor был протестирован на английском, финском и турецком языках. Наилучший результат был достигнут на корпусе турецких слов, 𝐹-мера составила около 70%. Результаты. На данном этапе разработан функционал алгоритма, который реализует поиск документов по ключевым словам. Имеются некоторая погрешность в достигнутых результатах, которая сводится к дороботке библиотеки ключевых слов и не мешает автоматическому поиску близких по содержимому нормативных документов с которыми будут ознакомлены эксперты, для дальнейшего согласования. На этапе экперементальной проверки без участия экспертов поиск выдает правельный результат на 95%, что подтверждает корректно построенную модель. 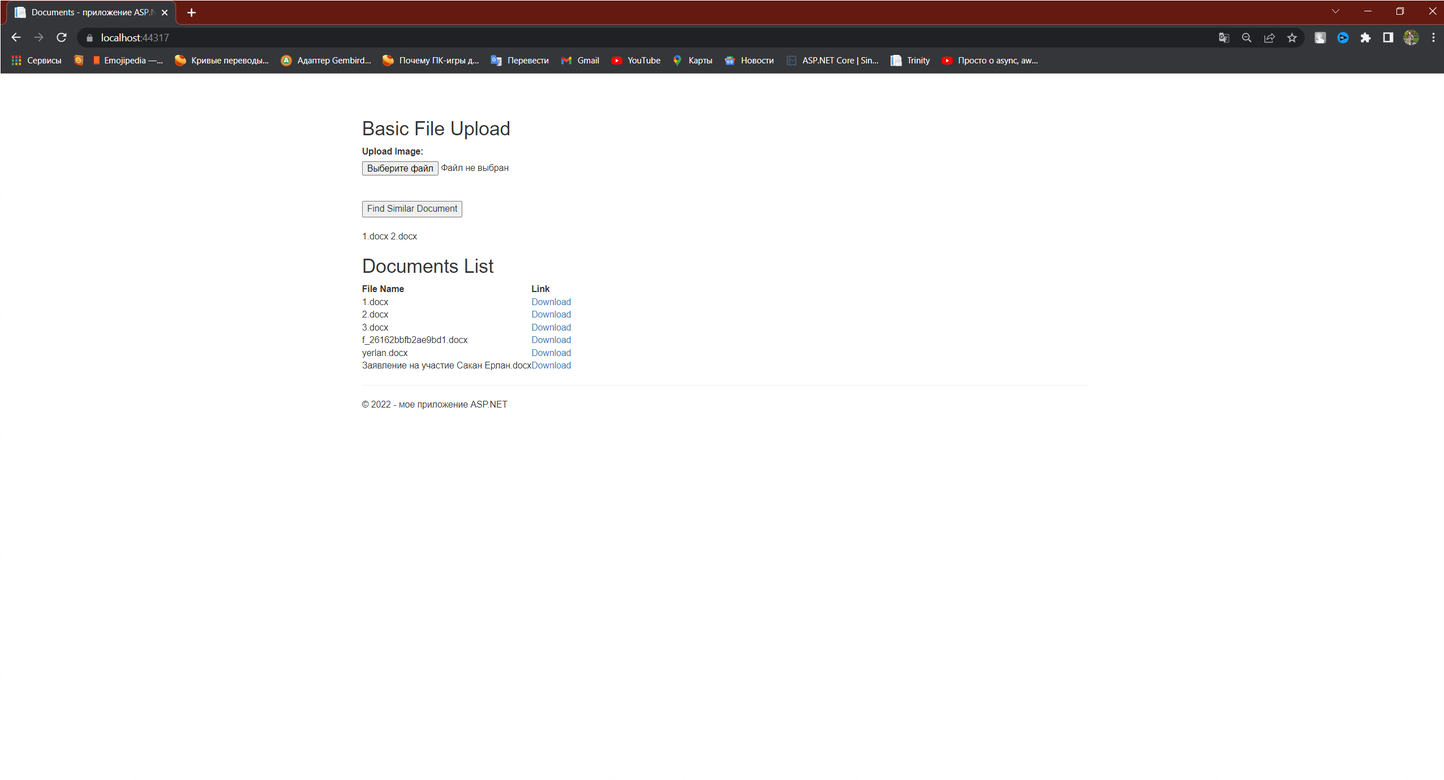 Рисунок 3. Базовый интерфейс, Поиск близких по содержимому нормативных документов Далее продемонстрируем результаты поиска с группировкой по направлениям отдельно взятых файлов.  Рисунок 4. Полученные результаты 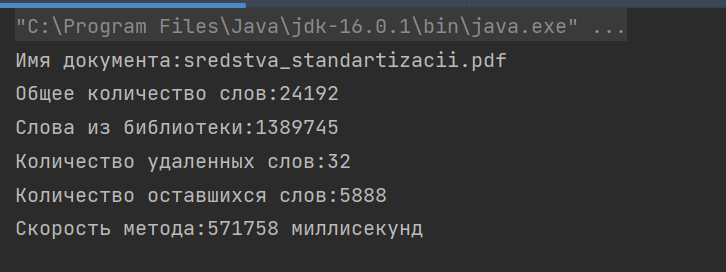 Рисунок 5. Результат запроса по отдельно взятому документу Заключение Статья демонстрирует проведенное исследование методов и моделей по обработке естественного языка. Выполненая задача в ходе эксперементальной работы отвечает первоначальным заявленным требованиям и открывает возможность дальнейших этапов исследования. Получены результаты исследования моделей формирования единого репозитория ключевых слов. Осуществлено комплексное исследование и комбинирование моделей с базами онтологий. Получена первичная проектная документация по инструментарию программного обеспечения. Следующим этапом исследований планируется разработка фронтенд программы, удобный интерфейс позволит проводить мониторинг национальных стандартов по группам и экспертам. Данное исследование выполнено и финансируется Комитетом науки Министерства образования и науки Республики Казахстан (грант № АР09058441 «Построение системы интеллектуального управления процессами разработки и гармонизации стандартов в рамках межгосударственной и национальной стандартизации на основе онтологического инжиниринга») Список используемой литературы Автоматическая обработка текстов на естественном языке и анализ данных : учеб. пособие / Большакова Е.И., Воронцов К.В., Ефремова Н.Э., Клышинский Э.С., Лукашевич Н.В., Сапин А.С. — М.: Изд-во НИУ ВШЭ, 2017. — 269 с. Сапин А.С. Автоматический морфемный разбор русских слов на основе решающих деревьев с применением бустинга // Новые информационные технологии в автоматизированных системах. 2019. №22. Розанов А.К. Быстрый алгоритм анализа словоформ естественного языка с трехуровневой моделью словаря начальных форм // Cloud of science. 2016. №1. Риз Р. Р49 Обработка естественного языка на Java / пер. с англ. А. В. Снастина. – М.: ДМК Пресс, 2016. – 264 с.: ил. |