Методические указания. +Му к практ.работам всс. Методические указания к практическим работам по дисциплине Вычислительные системы и сети Специальность 5В070200 Автоматизация и управление
 Скачать 0.98 Mb. Скачать 0.98 Mb.
|

Практическая работа№3Принципы систолической обработки информацииЦель работы: Изучение принципов обработки информации в систолической системе. Задачи: 1. Расписать процедуру умножения матриц А и В размерностью 3х3 в систолической системе. 2. Нарисовать схему умножения, составить таблицу и проверить экспериментально результат. Краткая теория Операция поиска вхождений с помощью линейной систолической структурыОперация поиска вхождений заключается в том, что в некоторой исходной последовательности A=(a1,a2,...an), ai=0 или 1, найти эталонную последовательность B=(b1,b2,...,bm), причем bj=0,1 или (*), где символом (*) обозначено безразличное состояние соответствующего разряда. Результатом операции является вектор R=(rk), в котором каждый компонент ri определяется по правилу: ri=1, если (b1=ai)(b2=ai+1)...(bm=ai+m), 0 в противном случае, где i=1,(n-m+1). Для реализации этой операции используем ПЭ, способные выполнять поразрядное сравнение и сохранять результаты этого сравнения, соединив ПЭ в линейную конфигурацию. На входы каждого ПЭ поступают значения ai и bi; каждый ПЭ производит сравнение и запоминает частичный результат r, кроме того, по завершении сравнения синхронно с поступлением тактовых импульсов значения ai и bi передаются на входы следующих ПЭ, то есть: aвых(t)=aвх(t-1) и bвых(t)=bвх(t-1), где t=1,2,.. – номер такта. Пусть поиск вхождений производится для трехразрядного эталона–образца B=(b1,b2,b3) в исходной последовательности A=(a1,...a5). На рисунке 7 показана временная диаграмма выполнения операции в систолической линейной матрице. На первом такте (t=1) значения a1 и b1 загружаются в ПЭ1 и ПЭ2 соответственно. На втором такте производится сдвиг a1 и b1 (соответственно в ПЭ2 и ПЭ4), на третьем - очередной сдвиг и загрузка a2 и b2 в ПЭ1 и ПЭ5 и т.д. На третьем такте в ПЭ3 попадают a1 и b1, где и производится их сравнение; результат сравнения rij(t) сохраняется в ПЭ3. Дальнейшее перемещение А и В по систолической структуре очевидно из диаграммы. На пятом такте в ПЭ3 попадают элементы a2 и b2, сравниваются там и вырабатывается результат ri+1,j+1(t+2); находится конъюнкция частичных результатов r(t+2)=r(t)ri+1,j+1(t+2), которая и сохраняется в ПЭ3. Первый окончательный результат – элемент r1 вектора R – будет получен в ПЭ3 на седьмом такте в результате сравнения a3и b3. Второй элемент r2 будет получен на восьмом такте, но в ПЭ4 и т.д. Очевидно, что каждый ПЭ может выполнять операцию сравнения байтов или слов, что позволяет находить определенные последовательности в цепочках символов, то есть выполнять операции сравнения цепочек символов. Кроме того, осуществляя циклический сдвиг эталона - образца, может сократить число ступеней систолического конвейера, однако это приводит к дополнительным затратам времени. Отметим, что в рассматриваемой схеме ПЭ5 и ПЭ4 служат только для задержки элементов bi, поэтому они могут быть заменены регистром сдвига.  Рисунок 7 - Реализация операции сравнения цепочек литер Операция умножения квадратных матриц с помощью прямоугольной систолической матрицы.Результат перемножения двух матриц C=AB формируется согласно формуле: причем каждый элемент С=|cij| можно рассматривать как результат рекуррентных вычислений: cij(0)=0; cij(k)=cij(k-1)+aikbik, k=1,n. Такие суммы образуются при накапливании частичных сумм в процессе продвижения aij и bij по систолической матрице. Пусть обе матрицы A и B имеют размерность 2х2: 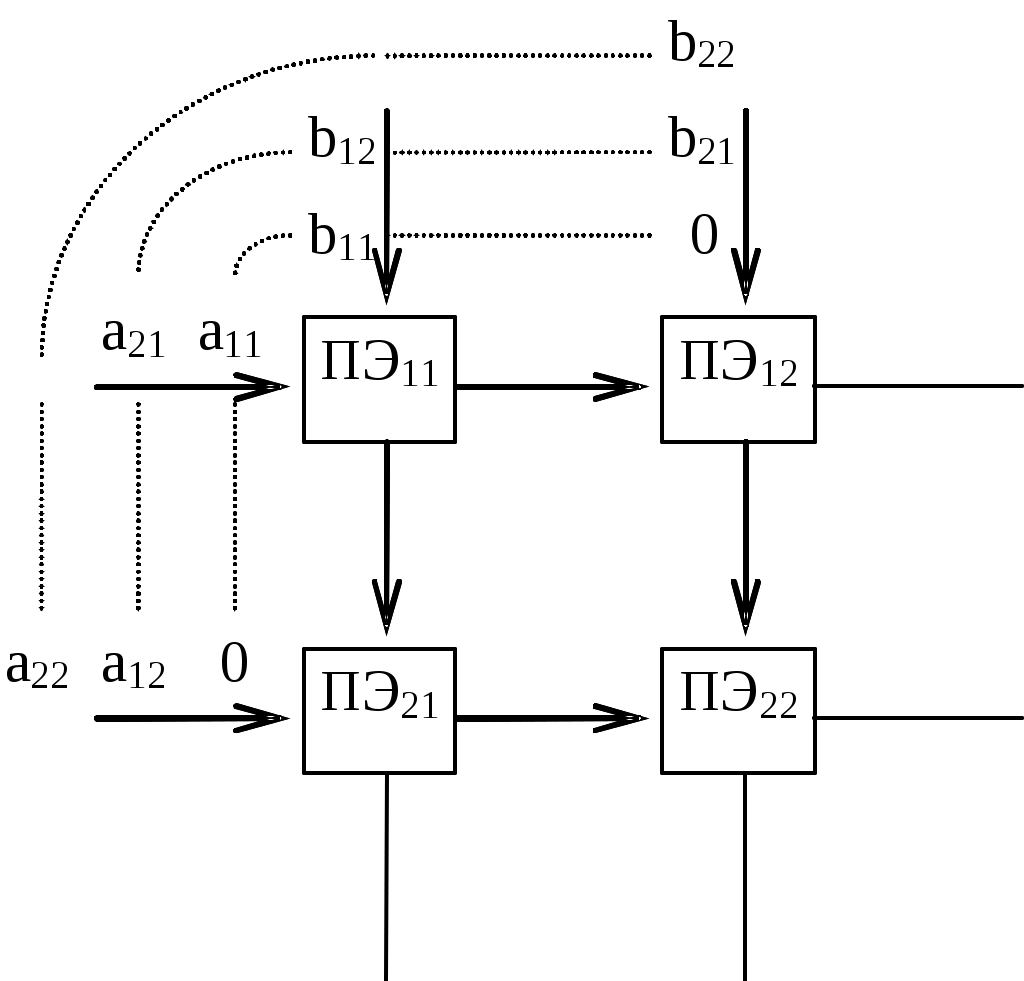 Рисунок 8 - Умножение матриц в систолической структуре – и операция умножения производится с помощью ПЭ (рисунок 8), объединенных в прямоугольную матрицу. Загрузка элементов матриц А и В из памяти производится по строкам (А) и по столбцам (В) с характерным для систолической обработки сдвигом. Этот сдвиг (рисунок 8) обозначен 0. В начальный момент все ПЭ установлены в исходное нулевое состояние. На первом такте в ПЭ11 загружаются элементы a11 и b11. На втором такте элементы a11 и b11 поступают на входы ПЭ12 и ПЭ21 соответственно. На ПЭ11 поступают a21 и b12 и в нем вычисляется сумма произведений a11b11+a21b12 (первое слагаемое этой суммы сохранено в ПЭ11 с первого такта). Одновременно в ПЭ12 и ПЭ21 вычисляются произведения a12b11 и a11 и b21 соответственно. Этот процесс продолжается, как показано в таблице. Весь процесс перемножения матриц требует 3n-2 шагов, где n – размерность перемножаемых матриц.
Здесь полезно вспомнить, что в последовательной ЭВМ перемножение матриц выполняется за n3 шагов, то есть достигаемое ускорение для систолической СОД составляет n3/(3n-2). |