Методические указания по выполнению лабораторных работ по дисциплине Методы разработки программного обеспечения
 Скачать 301.5 Kb. Скачать 301.5 Kb.
|

Метрики сложности программПри оценке сложности программ, как правило, выделяют три основные группы метрик: метрики размера программ, метрики сложности потока управления программ и метрики сложности потока данных программ. Оценки первой группы наиболее просты и поэтому получили широкое распространение. Традиционной характеристикой размера программ является количество строк исходного текста. Под строкой понимается любой оператор программы. Непосредственное измерение размера программы, несмотря на свою простоту, дает хорошие результаты. Оценка размера программы недостаточна для принятия решения о ее сложности. Но вполне применима для классификации программ, существенно различающихся объемами. При уменьшении различий в объеме программ на первый план выдвигаются оценки других факторов, оказывающих влияние на сложность. Таким образом, оценка размера программы есть оценка по номинальной шкале, на основе которой определяются только категории программ без уточнения оценки для каждой категории. К группе оценок размера программ можно отнести также метрику Холстеда. За базу принят подсчет количества операторов и операндов используемых в программе, т.е. определение размера программы. Основу метрики Холстеда составляют четыре измеряемые характеристики программы: h1 - число уникальных операторов программы, включая символы-разделители, имена процедур и знаки операций (словарь операторов); h2 – число уникальных операндов программы (словарь операндов); N1 – общее число операторов в программе N2 – общее число операндов в программе. Опираясь на эти характеристики, получаемые непосредственно при анализе исходных текстов программ, Холстед вводит следующие оценки Словарь программы h=h1 + h2 Длину программы N=N1+N2 Объем программы V=N log2 h Смысл оценок h и N достаточно очевиден, поэтому подробно рассмотрим только характеристику V. Количество символов, используемых при реализации некоторого алгоритма, определяется в числе прочих параметров и словарей программы h, представляющим собой минимально необходимое число символов, обеспечивающих реализацию алгоритма. Далее Холстед вводит h* - теоретический словарь программы, т.е. словарный запас, необходимый для написания программы с учетом того, что необходимая функция уже реализована в данном языке и, следовательно, программа сводится к вызову этой функции. Например, согласно Холстеду возможное осуществление процедуры выделения простого числа могло бы выглядеть так: CALL SIMPLE (X, Y), где Y- массив численных значений, содержащих искомое число X. Теоретический словарь в этом случае будет состоять из n1*: {CALL, SIMPLE (...)} n1*=2; n2*: {X,Y}, h2*=2; а его длина, определяемая как h* = h1* + h2* будет равна 4. Используя h*, Холстед вводит оценку V*: V* = h*log2h*, с помощью которой описывается потенциальный объем программы, соответствующий максимально компактно реализующей данный алгоритм. Вторая наиболее представительная группа оценок сложности программ – метрики сложности потока управления программ. Как правило, с помощью этих оценок оперируют либо плотностью управляющих переходов внутри программ, либо взаимосвязями этих переходов. И в том и в другом случае стало традиционным представление программ в виде управляющего ориентированного графа G(V,E), где V – вершины, соответствующие операторам, а E – дуги, соответствующие переходам. В дуге (U,V) – вершина V является исходной, а U – конечной. При этом U непосредственно следует V, а V непосредственно предшествует U. Если путь от V до U состоит более чем из одной дуги, тогда U следует за V, а V предшествует U. Впервые графическое представление программ было предложено Маккейбом. Основной метрикой сложности он предлагает считать цикломатическую сложность графа программы, или, как еще называют, цикломатическое число Маккейба, характеризующее трудоемкость тестирования программы. Для вычисления цикломатического числа Маккейба Z(G) применяется формула Z(G) = l-v+2p, где l – число дуг ориентированного графа G; v – число вершин; p- число компонентов связности графа. Число компонентов связности графа можно рассматривать как количество дуг, которые необходимо добавить для преобразования графа сильносвязный. Сильносвязным называется граф, любые две вершины которого взаимно достижимы. Для графов корректных программ, т.е. графов, не имеющих недостижимых от точек входа участков и “висячих” входа и выхода, сильносвязный граф, как правило, получается путем замыкания одной вершины, обозначающей конец программы на вершину, обозначающую точку входа в эту программу. По сути Z(G) определяет число линейно независимых контуров в сильносвязном графе. Иначе говоря, цикломатическое число Маккейба показывает требуемое число проходов для покрытия всех контуров сильносвязанного графа или количество тестовых прогонов программы, необходимых для исчерпывающего тестирования по критерию “работает каждая ветвь”.  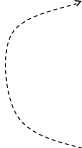    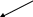            Для программы цикломатическое число при l=10, v=8, n=1 определится как Z(G) = 10-8+2=4. Таким образом, имеется сильносвязанный граф с четырьмя линейно независимыми контурами: a-b-c-g-e-h-a; a-b-c-e-h-a; a-b-d-f-e-h-a; a-b-d-e-h-a; Рассмотрим метрику сложности программы, получившую название “подсчет точек пересечения”, авторами которой являются М Вудвард, М Хенел и Д Хидлей. Метрика ориентирована на анализ программ, при создании которых использовалось неструктурное кодирование на таких языках, как язык ассемблера и фортран. Вводя эту метрику, ее авторы стремились оценить взаимосвязи между физическими местоположениями управляющих переходов. Структурное кодирование предполагает использование ограниченного множества управляющих структур в качестве первичных элементов любой программы. В классическом структурном кодировании, базирующемся на работах профессора Эйндховенского технологического университета(Нидерланды) Э. Дейкстры, оперируют только тремя такими структурами: следованием операторов, развилкой из операторов, циклом над оператором. все эти разновидности изображаются простейшими планарными графами программ. По правилам структурного кодирования любая программа составляется путем выстраивания цепочек из 3х упомянутых структур или помещения одной структуры в другую. Эти операции не нарушают планарности графа всей программы. В графе программы, где каждому оператору соответствует вершина, т.е. не исключены линейные участки , при передаче управления от вершины a к b номер оператора a равен min (a,b), а номер оператора b - max(a,b). Тогда пересечение дуг появятся, если min(a,b) < min(p,q) < max(a,b) & max(p,q) > max (a,b) | | min (a,b) < max(p,q) < max(a,b) & min(p,q) < min(a,b). Иными словами, точка пересечения дуг возникает в случае выхода управления за пределы пары вершин (a,b). К 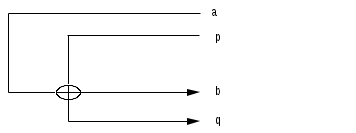 оличество точек пересечения дуг графа программы дает характеристику неструктурированности программы. Одной из наиболее простых, но достаточно эффективных оценок сложности программ является метрика Т. Джилба, в которой логическая сложность программы определяется как насыщенность программы выражениями IF_THEN_ELSE. При этом вводятся две характеристики: СL - абсолютная сложность программы, характеризующаяся количеством операторов условия; cl - относительная сложность программы, характеризующаяся насыщенностью программы операторами условия, т.е. cl определяется как отношение CL к общему числу операторов. Используя метрику Джилба, ее дополнили еще одной составляющей, а именно характеристикой максимального уровня вложенности оператора CLI, что позволило применить метрику Джилба к анализу циклических конструкций. Большой интерес представляет оценка сложности программ по методу граничных значений. Введем несколько дополнительных понятий, связанных с графом программы. Пусть G=(V,E) - ориентированный граф программы с единственной начальной и единственной конечной вершинами. В этом графе число входящих в вершину дуг называется отрицательной степенью вершины, а число исходящих из вершины дуг - положительной степенью вершины. Тогда набор вершин графа можно разбить на две группы: вершины у которых положительная степень <=1; вершины у которых положительная степень >=2. Вершины первой группы назовем принимающими вершинами, а вершины второй группы - вершинами отбора. Для получения оценки по методу граничных значений необходимо разбить граф G на максимальное число подграфов G', удовлетворяющих следующим условиям: вход в подграф осуществляется только через вершину отбора; каждый подграф включает вершину (называемую нижней границей подграфа), в которую можно попасть из любой другой вершины подграфа. Например, вершина отбора соединенная сама с собой дугой петлей, образует подграф.                        Число вершин, образующих такой подграф, равно скорректированной сложности вершины отбора:
Каждая принимающая вершина имеет скорректированную сложность, равную 1, кроме конечной вершины, скорректированная сложность которой равна 0. Скорректированные сложности всех вершин графа G суммируются, образуя абсолютную граничную сложность программы. После этого определяется относительная граничная сложность программы: S0=1-(v-1)/Sa, где S0 – относительная граничная сложность программы; Sa – абсолютная граничная сложность программы, v – общее число вершин графа программы. Таким образом, относительная сложность программы равна S0=1-(11/25)=0,56. Другая группа метрик сложности программ – метрика сложности потока данных, то есть использования, конфигурации и размещения данных в программах. Пара “модуль – глобальная переменная” обозначается как (p,r), где p – модуль, имеющий доступ к глобальной переменной r. В зависимости от наличия в программе реального обращения к переменной r формируются два типа пар “модуль – глобальная переменная” : фактические и возможные. Возможное обращение к r с помощью p показывает, что область существования r включает в себя p. Характеристика Aup говорит о том, сколько раз модули Up действительно получили доступ к глобальным переменным, а число Pup – сколько раз они могли бы получить доступ. Отношение числа фактических обращений к возможным определяется Rup=Aup/Pup Эта формула показывает приближенную вероятность ссылки произвольного модуля на произвольную глобальную переменную. Очевидно, чем выше эта вероятность, тем выше вероятность “несанкционированного” изменения какой-либо переменной, что может существенно осложнить работы, связанные с модификацией программы. Покажем расчет метрики “модуль – глобальная переменная”. Пусть в программе имеются три глобальные переменные и три подпрограммы. Если предположить, что каждая подпрограмма имеет доступ к каждой из переменных, то мы получим девять возможных пар, то есть Pup=9. Далее пусть первая подпрограмма обращается к одной переменной, вторая – двум, а третья не обращается ни к одной переменной. Тогда Aup=3, Rup=3/9. Еще одна метрика сложности потока данных – спен. Определение спена основывается на локализации обращения к данным внутри каждой программной секции. Спен – это число утверждений, содержащих данный идентификатор, между его первым и последним появлением в тексте программы. Идентификатор, появившийся n раз, имеет спен, равный n-1. Спен определяет количество контролирующих утверждений, вводимых в тело программы при построении трассы программы по этому идентификатору в процессе тестирования и отладки. Следующей метрикой сложности потока данных программ является метрика Чепина. Существует несколько ее модификаций. Рассмотрим более простой, а с точки зрения практического использования – достаточно эффективный вариант этой метрики. Суть метода состоит в оценке информационной прочности отдельно взятого программного модуля с помощью анализа характера использования переменных из списка ввода-вывода. Все множество переменных, составляющих список ввода-вывода разбивается на четыре функциональные группы Р – вводимые переменные для расчетов и для обеспечения вывода. Примером может служить используемая в программах лексического анализатора переменная, содержащая строку исходного текста программы, то есть сама переменная не модифицируется, а только содержит исходную информацию. М – модифицируемые или создаваемые внутри программы переменные. C – переменные, участвующие в управлении работой программного модуля (управляющие переменные). Не используемые в программе (“паразитные”) переменные. Поскольку каждая переменная может выполнять одновременно несколько функций, необходимо учитывать ее в каждой соответствующей функциональной группе. Далее вводится значение метрики Чепина: Q = a1P + a2M + a3C + a4T ,где a1, a2, a3, a4 – весовые коэффициенты. Весовые коэффициенты использованы для отражения различного влияния на сложность программы каждой функциональной группы. По мнению автора метрики, наибольший вес, равный трем, имеет функциональная группа С, так как она влияет на поток управления программы. Весовые коэффициенты остальных групп распределяются следующим образом: a1=1; a2=2; a4=0.5. Весовой коэффициент группы T не равен нулю, поскольку “паразитные” переменные не увеличивают сложности потока данных программы, но иногда затрудняют ее понимание. С учетом весовых коэффициентов выражение примет вил: Q = P + 2M + 3C + 0.5T . Следует отметить, что рассмотренные метрики сложности программы основаны на анализе исходных текстов программ, что обеспечивает единый подход к автоматизации их расчета. | |||||||||||||||||||||||||||||