Нормализация баз данных
 Скачать 469 Kb. Скачать 469 Kb.
|

|
Нормализация баз данных Процедура нормализации считается самым сложным этапом в создании базы данных. Отчасти потому что многое в ней совершается интуитивно. Существует множество нормальных форм, но проектировщику базы данных важно суметь найти компромисс между степенью нормализации и производительностью СУБД. Эта статья родилась из стремления изложить достаточно сложный материал наиболее понятным языком, чтобы не только дать учащимся возможность освоить навыки пользователей конкретной СУБД, но и приблизить их к творчеству создателей баз данных. *** Существует множество классификаций баз данных – по модели данных, по степени распределённости, по содержимому, по технологии хранения и т.д. Мы же рассмотрим классификацию баз данных по организации связей между её объектами. Виды структур данных Линейная организация, или список. Она объединяет не связанные между собой однотипные элементы, собранные по какому-либо признаку. Пример – список учеников 10 класса:  Рис. 1 Однотипные элементы здесь – ученики. А признак, по которому они объединены, - принадлежность одному классу. Несвязанность их между собой означает, что удаление одного ученика из списка класса не влечёт за собой удаление других. Линейная организация является простейшей структурой базы данных, тем её кирпичиком, из совокупности которых складываются более сложные структуры. (Освоить приёмы работы со списком можно в Ecxel или Calc (OpenOffice).) К сложным структурам относятся: 2. Иерархическая организация, или многоуровневый список, или дерево. В ней каждый элемент нижнего уровня связан только с одним элементом верхнего. Таким образом, можно говорить о вложенности, подчинённости, наследовании элементов. Примером иерархической организации может служить классификация животных: 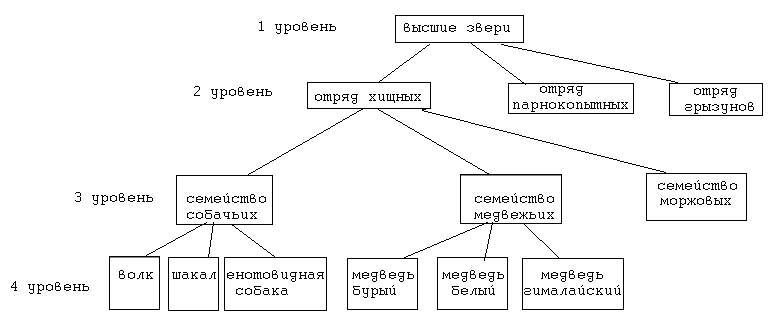 Рис. 2 В иерархической организации количество уровней подчинённости соответствует количеству участвующих в ней классов объектов. На рис. 2 показаны связи между тремя классами объектов: отряды, семейства, роды. Внутри иерархической организации можно выделить два вида списков. Списки первого вида назовём горизонтальными, поскольку образованы они из объектов, принадлежащих одному классу и могут рассматриваться независимо друг от друга. В нашем примере к ним относятся списки Отряды, Семейства, Роды. 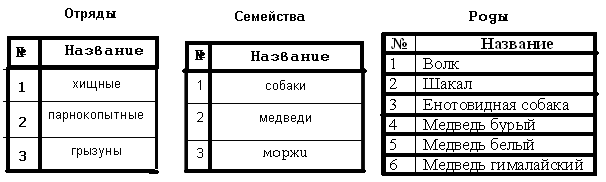 Рис. 3 Список второго вида может быть назван вертикальным, поскольку представляет собой совокупность связей, каждая из которых соединяет один элемент нижнего уровня с корнем дерева через промежуточные элементы. Количество элементов вертикального списка равно числу элементов нижнего уровня дерева.  Рис. 4 Очевидно, что в иерархической базе данных вертикальный список объектов является расширением горизонтального списка для самого нижнего уровня. 3. Сетевая организация – набор объектов двух разных классов, в котором каждый объект одного класса может быть связан с каждым объектом другого класса. Примером может служить граф, иллюстрирующий денежные вклады граждан в разные банки: 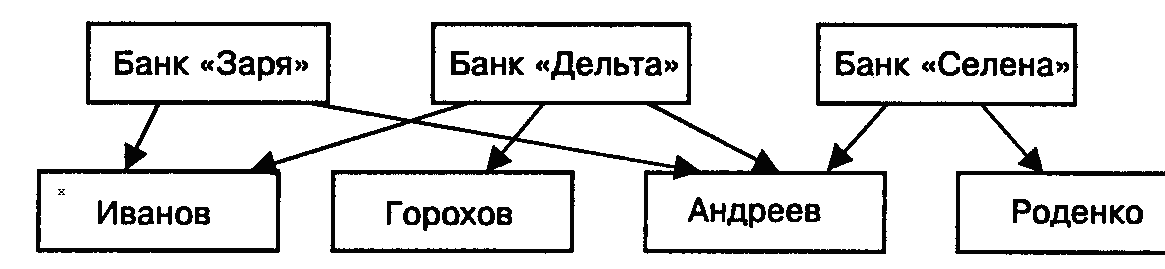 Рис. 5 Здесь можно выделить два класса объектов – Банки и Вкладчики, каждый из которых является по своей организации горизонтальным списком. 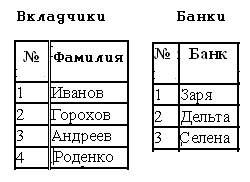 Рис. 6 Так же, как в иерархической структуре, в сетевой есть и вертикальный список, отражающий связи между объектами разных классов. В нашем примере это список вкладов всех вкладчиков. Если граф – взвешенный, то вес каждого ребра – ещё одна характеристика связи между объектами разных классов, и она, так же как и другие характеристики связи, может быть отражена в вертикальном списке: 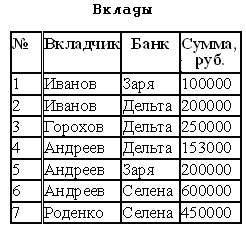 Рис. 7 Элементы вертикального списка, как и полагается элементам линейной структуры, являются независимыми друг от друга. Это значит, что отзыв, к примеру, Ивановым своего вклада из банка «Заря», никак не повлияет на остальные вклады из списка. В то же время удаление любого элемента из горизонтального списка повлечёт за собой удаление всех связей, в которые он вовлечён. Если обанкротится банк «Заря», то потребуют удаления 1 и 5 элементы из списка Вклады (см. рис. 7). То же случится, если будет удалён какой-либо элемент из списка Вкладчики. Вообще говоря, вертикального списка достаточно, чтобы полностью описать структуру базы данных. Классы объектов базы данных можно восстановить по названиям столбцов, содержимое горизонтальных списков – по их уникальным значениям, а связи между элементами разных классов – по строкам. Таким образом, именно вертикальный список отражает главную идею базы данных. *** Задание: определить из текста, содержащего неструктурированную информацию, классы объектов. Представить её в виде графа (иерархического или сетевого), а также составить вертикальный список. А) «Поезд №22 приезжает на станцию Клубникино в 12.20, а на станцию Земляникинов 12.50. НаКлубникиноон стоит 10 минут и отправляется в 12.30. На ст. Земляникино стоянка составляет 5 минут. Поезд № 26 приезжает на станцию Клубникинов 15.10, а на станцию Земляникинов 16.00. На ст. Клубникиностоянка составляет 7 минут, а на ст. Земляникино - 13. Поезд № 30 приезжает на станцию Клубникино в 18.50, а на станцию Земляникинов 19.05. Стоянка на ст. Клубникиносоставляет 7 минут, а отъезд со ст. Земляникино происходит в 19.08…» Решение: 1 класс объектов – станции. 2 класс объектов – поезда. Каждый элемент из 1-го класса связан с каждым элементов из 2-го класса такими характеристиками, как время прибытия, стоянки и отправления. Следовательно, это сетевая организация, которую можно изобразить так: 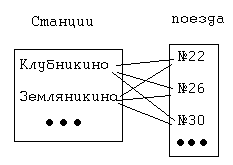 Рис. 8 Горизонтальные списки представляют собой перечни станций и поездов. А вертикальный – перечень остановок:
Рис. 9 Независимость элементов этого списка выражается в том, что отмена одной остановки в маршруте какого-либо поезда никак не повлияет на существование остальных остановок. В то же время удаление какого-либо элемента из горизонтального списка (например, поезда №26) повлечёт за собой удаление всех связей, в которые он вовлечён (3 и 4 строки вертикального списка – рис. 9). В теории баз данных связь, подобную связи горизонтального списка с вертикальным, называют отношением «один – ко многим». А обозначают так: «1 - ∞». Из этого примера видно, что связи в сетевой структуре (см. рис. 8) - «многие ко многим» (∞ - ∞) – между горизонтальными списками с помощью вертикального списка можно заменить на две связи «один – ко многим». Б) «Миша Иванов посещает танцевальные занятия, которые ведёт преподаватель Сергеев по понедельникам и четвергам, в 15.00. Туда же приходят Саша Андреев и Валя Марченко. А вот их приятели Петя Карпов и Яна Молчанова занимаются танцами у другого преподавателя – Макаровой, по вторникам и пятницам. В эти же дни, но на 2 часа позже к Макаровой на занятия приходят дети помладше: Вова Иванов, брат Миши, Стёпа и Соня Емцевы». Решение: 1 класс объектов – дети, 2 класс объектов – преподаватели. Каждый ребёнок (объект из 1 класса) посещает занятия только у одного преподавателя (объект 2 класса). При этом у Макаровой ученики разбиты на младшую и старшую группы. Значит, можно выделить 3-й класс объектов – группы. Каждый ученик ходит в одну из групп. При этом ни один ученик не посещает сразу две группы. Налицо иерархические отношения между элементами: 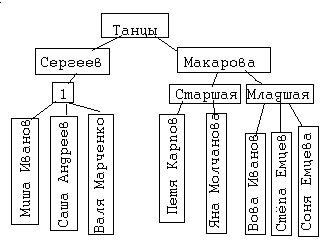 Рис. 10 Обратите внимание: чтобы всех детей, посещающих занятия, представить элементами одного уровня, мы добавили промежуточный элемент (1 группа у преподавателя Сергеева), который не был упомянут в тексте, но не противоречит его смыслу. Таким образом, горизонтальных списков здесь три: 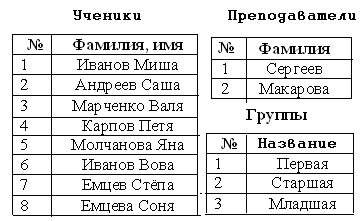 Рис. 11 А вертикальный список (связи) представляет собой распределение учеников по танцевальным группам: 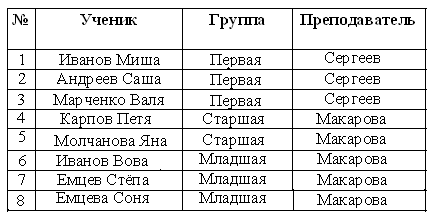 Рис. 12 Поскольку вертикальный список является расширением горизонтального (в данном случае – списка Ученики), то удаление какого-либо элемента из соответствующего ему горизонтального списка влечёт за собой удаление ровно одного элемента из вертикального. В этом случае говорят, что между этими списками существует связь «один к одному», которая обозначается «1 – 1». Если два класса объектов связаны друг с другом соотношением «1 – 1», то они могут рассматриваться как объект и атрибут. Следовательно, в иерархической базе данных элементы горизонтальных списков являются атрибутами связанного с ними элемента нижнего уровня. Удаление же одного элемента из любого другого (не нижнего) горизонтального списка, вообще говоря, означает удаление нескольких элементов из вертикального списка. Например, увольнение преподавателя Серова отменяет занятия у всех учеников первой группы, т.е. у Иванова Миши, Андреева Саши и Марченко Вали. Аналогично, если младшую группу решат распустить, то из списка учеников будут исключены Вова Иванов и близнецы Емцевы. Значит, остальные горизонтальные списки связаны с вертикальным отношениями «1 - ∞». Из этих двух примеров видны основные различия между иерархической и сетевой структурами. В первой вертикальный список связан с горизонтальными одной связью «1-1» и несколькими «1 - ∞». В сетевой структуре все горизонтальные списки находятся по отношению к вертикальному в связи «1- ∞». Реляционные базы данных Теперь пора перейти на терминологию баз данных. Заменим слово «список» на слово «таблица». Таблица относится к способу представления данных и действительно является наиболее удобной формой представления списка. Таблица состоит из строк и полей. Строки в базах данных принято называть записями, а столбцы – полями. Записи описывают элементы списка, или объекты, а поля – их характеристики, или атрибуты. Атрибуты делятся на параметры, признаки и свойства. Параметры отражают количественные характеристики объекта (числовой тип или тип дата/время). Признаки описывают качественные характеристики объекта (текстовый тип). Свойства обозначают способность объекта получить некоторый результат (логический тип). Чтобы отличать одну запись от другой, в таблицах вводится понятие ключа. Так называют поле или комбинацию полей, по которым одну запись в таблице можно отличить от другой. В наших предыдущих примерах в качестве ключа можно использовать порядковый номер в списках. База данных, представленная в виде набора связанных между собой простых таблиц, называется реляционной. Поскольку, как показано выше, любая информационная структура представима в виде набора списков, то реляционные базы данных являются универсальными. *** Вернёмся теперь к вертикальному списку из первого примера (рис. 4). Как уже было сказано, вертикальный список содержит полную информацию о структуре базы данных. Однако, как видно из таблицы, в нём много повторов. А это значит, что информация занимает в компьютерной памяти излишне много места. Кроме того, в базе данных могут возникнуть так называемые аномалии обновления. Это значит, что если, например, пользователями базы будет решено заменить русское название отряда Хищные на латинское – Carnivora, то вносить исправления придётся во все записи, где встречается это название. Кроме того, если два разных пользователя одной базы данных назовут одно и то же семейство по-разному (например, Собачьи и Псовые), то компьютер воспримет эти семейства как разные. Кроме аномалий обновления, существуют ещё аномалии добавления и удаления. Они возникают в сетевых структурах, если в качестве атрибута в вертикальном списке берётся атрибут (-ы) какого-либо объекта из горизонтального списка. Например, если в базу данных «Спортсмены» 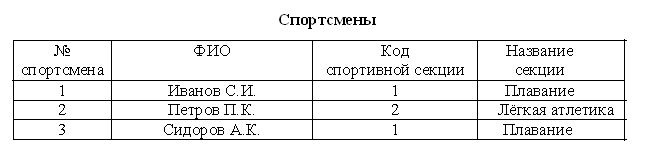 добавят следующую запись, то возникнет противоречие: код секции не будет совпадать с названием этой секции (аномалия добавления). Если же из секции Плавание решат уйти все спортсмены, то из базы данных исчезнет и вся информация об этой секции (аномалия удаления). Очевидно, что Название секции является характеристикой Секции, т.е. атрибутом соответствующего ей горизонтального списка:  Чтобы избавиться от всевозможных аномалий при работе с информацией, проводят нормализацию базы данных. Нормализация – это процедура, которая позволяет устранить дублирование и потенциальную противоречивость хранимых данных. В идеале при нормализации надо добиться того, чтобы любое значение хранилось в единственном экземпляре, причём значение это не должно быть получено расчётным путём из других данных, хранящихся в базе. Первый шаг к нормализации БД – это избавление от повторов. Для этого воспользуемся тем, что таблица вертикального списка связана с таблицами горизонтальных списков отношениями «1 - ∞» и «1 – 1». Это значит, что мы можем заменить значения всех полей в вертикальном списке на соответствующий им ключ в горизонтальных списках. В нашем примере вертикальный список получит вид:
Рис. 13 Но теперь его надо дополнить горизонтальными списками с указанием связей: 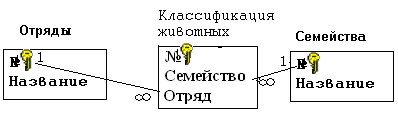 Рис. 14 Проделав аналогичную процедуру с базой данных сетевой структуры (см. рис. 7), вертикальный список приобретёт вид: 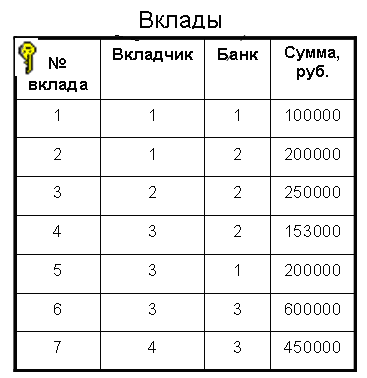 Рис. 15 А структура базы данных выразится в следующем наборе таблиц: 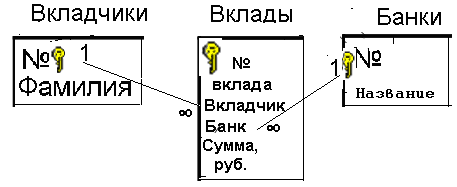 Рис. 16 *** Дополнительными требованиями к нормализованной базе данных являются следующие: 1. Любое поле должно быть неделимым. Например, поле ФИО следует разделить на Имя, Фамилия и Отчество, если перед пользователями базы данных может стоять задача поиска людей по отчеству или имени. (Если такой задачи нет, то поле ФИО будет восприниматься СУБД как неделимое.) 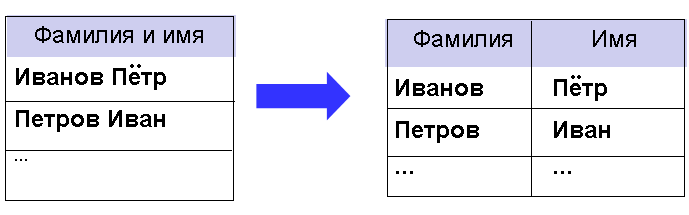 Рис. 17 Нарушение этого требования может привести к так называемым аномалиям удаления и добавления. Например, если в БД «Ученик» будет решено избавиться от отчества и тем самым сократить объём базы, то выудить отчество из поля ФИО во всех записях гораздо более затратно, чем просто удалить из структуры БД поле Отчество. 2. Не должно быть полей, которые могут быть найдены с помощью остальных. Нарушение этого требования приводит к неоправданному увеличению объёма базы данных. Например, в таблице, отражающей сведения о хранящихся на продуктовой базе фруктах, не должно быть поля Стоимость, значение которого может быть получено как произведение значений полей Цена и Количество. 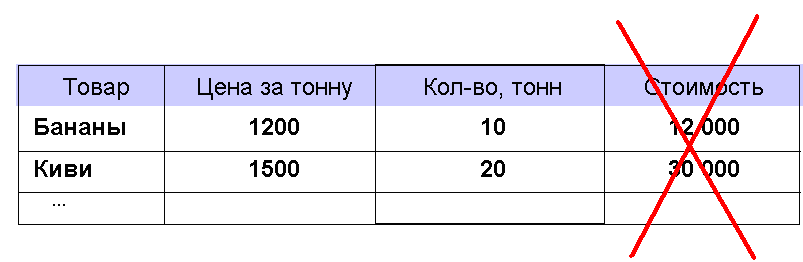 Рис. 18 3. Не должно быть полей, которые обозначают различные виды одного и того же:  Рис. 19 Такая ситуация может возникнуть в том случае, если в сетевой базе данных классы первых и вторых объектов совпадают. Например, на шахматном турнире каждый участник соревнования должен сразиться с остальными. Логично было бы составить вертикальный список «Игры» следующим образом:
Но тогда нарушалась бы однозначность связей между таблицами Игры и Игроки: 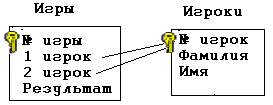 Рис. 20 Поскольку очевидно, что в подобных случаях связь между таблицами сетевая (несколько игроков одновременно принимают участие в одной игре, и один игрок может участвовать в нескольких играх) используют третью таблицу «Участие в играх»:
Здесь связь двух игроков, участвующих в одной и той же игре, осуществляется по общему значению в поле «№ игры». *** Теперь можно полностью сформулировать алгоритм нормализации базы данных: Определение классов объектов, входящих в её состав. Замена связи «1 – 1» объединённым списком, в котором объект одного класса выступает в качестве атрибута для объекта другого класса. Определение структуры связи между классами. Замена каждой сложной структуры на вертикальный и горизонтальные списки с указанием связей по ключевым полям. Внесение дополнительных атрибутов для каждого класса объектов – в зависимости от степени детализации объектов. Обеспечение требования неделимости полей – в зависимости от целей, стоящих перед будущими пользователями базой данных. Исключение вычисляемых полей. Следование этому алгоритму обеспечивает выполнение ещё одного требования к нормализованной базе данных: каждое не ключевое поле должно однозначно зависеть от ключа. Пример задачи. Нормализовать базу данных, заданную следующей схемой: 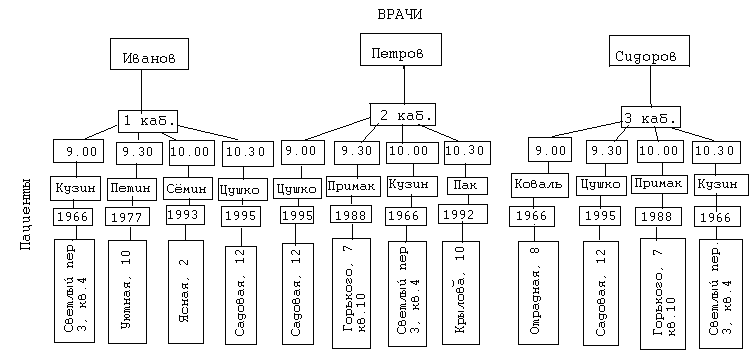 Рис. 21 Решение. Определим классы объектов из представленных на схеме категорий: врачи, пациенты, кабинеты, годы рожденья, адреса, время. Тип связи «врачи – кабинеты» определяется отношением «1 – 1» - значит, номер кабинета можно считать атрибутом врача (и наоборот). Точно те же рассуждения применимы к связи «пациент – год – адрес». Будем считать год и адрес атрибутами пациентов. Таким образом, остаётся два класса объектов: врачи и пациенты. Определим статус категории время. Видно, что время не является ни атрибутом пациентов, ни атрибутом врачей. Однако оно характеризует связь между ними и, следовательно, относится к атрибутам связи. Определяем структуру между классами. Одному врачу соответствует несколько пациентов. Один и тот же пациент – например, Кузин – записан к нескольким врачам. Значит, структура – сетевая. Составляем горизонтальные и вертикальный списки и связи между ними: 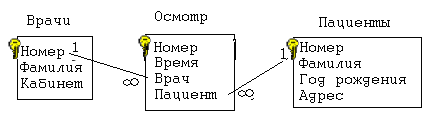 Рис. 22 Выполнение пунктов 5 – 7 не требуется. Задача решена. *** Несколько сложнее обстоит дело с обратной задачей: по заданному списку нормализовать базу данных. Для этого надо восстановить её структуру, т.е. определить, какие поля списка соответствуют классам объектов, какие – их атрибутам и какого типа – иерархические или сетевые – связи между объектами разных классов. Рассмотрим следующий пример. Дана таблица, содержащая сведения об учебной литературе. 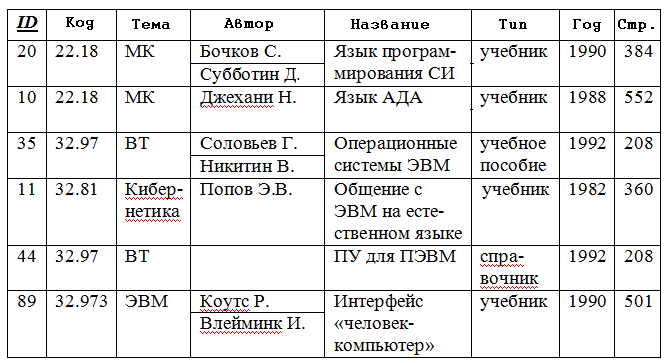 Рис. 23 Требуется нормализовать соответствующую ей базу данных. Решение: Определим классы, связанные соотношением «1 – 1». Это все поля, за исключением поля автор: 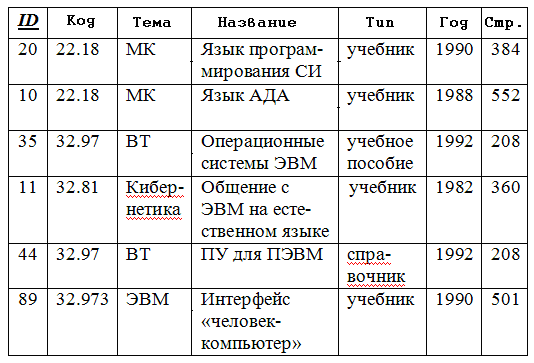 Рис. 24 Это значит, что каждая запись описывает один объект – книгу. Это – первый класс объектов. Объекты других классов выдают повторения. Это коды, темы и типы. Вынесем их в отдельные списки: 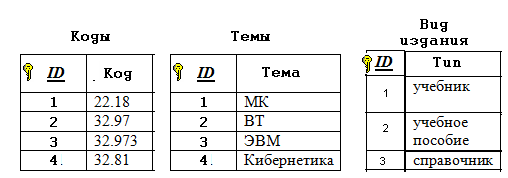 Рис. 25 Обратим внимание на то, что коды и темы входят в исходную таблицу, образуя связь «1 – 1». Это значит, что тему можно считать атрибутом кода. А поскольку сам код представляет собой неповторяющиеся числа, то его можно считать ключом: 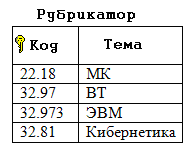 Рис. 26 Теперь список книг будет выглядеть так: 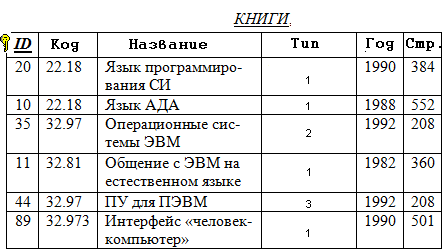 Рис. 27 А структура связей между классами книги – рубрикатор – темы так: 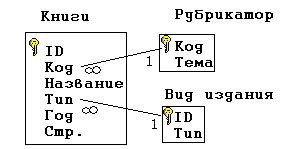 Рис. 28 Определим тип связи между объектами классов книги и авторы: одна книга может быть написана несколькими авторам; один автор может написать несколько книг. Значит, структура связи сетевая. Следовательно, исходная таблица преобразуется в таблицу, отражающую связи между книгами и авторами, т.е. публикации: 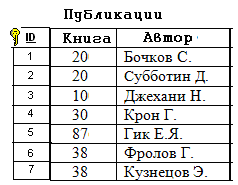 Рис. 29 Одновременно мы выполнили требование неделимости для поля Автор. Общая структура базы данных будет выглядеть так: 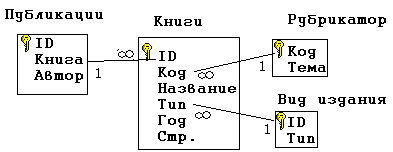 Рис. 30 Приложение: самостоятельные работы по вариантам Сведение произвольной структуры к табличному виду. (Дополнительные задачи по этой теме можно взять из [2], стр. 114 – 118, изменив условие следующим образом: представить данные в виде набора простых таблиц). Создание БД: знакомство с СУБД OpenOfficeBase. Работа с таблицей в двух режимах - дизайнера и пользователя. Усложнение БД: добавление в БД новых таблиц. Сам. работа – нормализация БД, представленных таблицей или схемой. Проектирование БД: по описанию данных, которые должны быть отражены в базе данных, спроектировать многотабличную БД. Литература Информатика и ИКТ. Практикум 8-9 класс / под редакцией Н.В. Макаровой. – СПб.: Питер, 2010. Информатика и ИКТ. Задачник-практикум. В 2 т. / под редакцией И.Г.Семакина, Е.К. Хеннера. – 3 изд. – М.: Бином. Лаборатория знаний, т. 1, 2011. Информатика и ИКТ. Задачник-практикум. В 2 т. / под редакцией И.Г.Семакина, Е.К. Хеннера. – 3 изд. – М.: Бином. Лаборатория знаний, т. 2, 2011. |