базы данных. Объектом исследования являются Распределенные базы данных
 Скачать 3.84 Mb. Скачать 3.84 Mb.
|

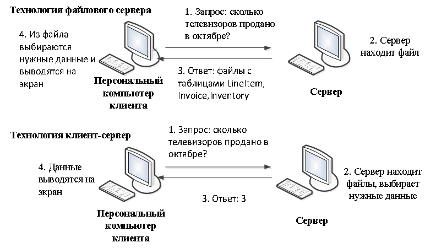 Рисунок 5 - Сравнение технологий файлового сервера и «клиент-сервера». При больших объемах данных и работе в многопользовательском режиме существенно снижается быстродействие - ведь чем больше пользователей, тем выше требования к разделению данных. Кроме того, может возникнуть повреждение баз данных. Например, в момент записи в файл может возникнуть сбой сети или авария питания. В этом случае, компьютер прерывает работу и база данных может оказаться поврежденной, а индексный файл - разрушенным. Переиндексация, которую необходимо провести после подобных сбоев, может длиться несколько часов [12]. Клиент-серверная версия позволяет обойти эти проблемы, так как вся работа с базой данных происходит на сервере, не проходит по проводам и не зависит от сбоев на рабочих станциях. Все запросы на запись в файл перехватываются сервером. В файл изменения вносятся только после того, как сервер получит сообщение о том, что корректировка файла завершена. Это исключает повреждение индексных файлов и существенно повышает быстродействие системы. распределенный база данные Кроме высокого быстродействия и надежности, архитектура «клиент-сервер» дает много преимуществ и в части технического обеспечения. Во-первых, сервер оптимизирует выполнение функций обработки данных, что избавляет от необходимости оптимизации рабочих станций. Рабочая станция может быть укомплектована не очень быстрым процессором, и, тем не менее, сервер позволит быстро получить результаты обработки запроса. Во-вторых, поскольку рабочие станции не обрабатывают все промежуточные данные, существенно снижается нагрузка на сеть. Появляется возможность ведения журнала операций, в котором автоматически регистрируются все прошедшие транзакции что, в свою очередь, поможет быстрому восстановлению системы при аппаратных сбоях [21]. Различают двухуровневую и трехуровневую модель «клиент-сервер». На рисунке 6 представлена двухуровневая модель «клиент-сервер». Эта модель, возможно, наиболее общая, поскольку она подобна схеме разработки локальных баз данных. Многие системы «клиент-сервер», используемые сегодня, развились из существующих локальных приложений базы данных, которые хранят свои данные в файле на сервере. Перенос систем осуществляется для повышения эффективности работы, защищенности и надежности базы данных [3]. 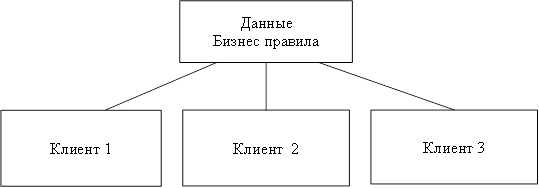 Рисунок 6 – Двухуровневая модель «клиент-сервер». Преимущества модели: делает возможным, в большинстве случаев, распределение функций вычислительной системы между несколькими независимыми компьютерами. Это позволяет упростить обслуживание вычислительной системы. В частности, замена, ремонт, модернизация или перемещение сервера не затрагивают клиентов. Все данные хранятся на сервере, который, как правило, защищён гораздо лучше большинства клиентов. На сервере проще обеспечить контроль полномочий, чтобы разрешать доступ к данным только клиентам с соответствующими правами доступа; позволяет объединить различные клиенты. Использовать ресурсы одного сервера часто могут клиенты с разными аппаратными платформами, операционными системами и т. п. [24]. Недостатки модели: неработоспособность сервера может сделать неработоспособной всю вычислительную сеть; поддержка работы данной системы требует отдельного специалиста - системного администратора; высокая стоимость оборудования [5]. В такой модели данные постоянно находятся на сервере, а клиентные приложения на своем компьютере. Бизнес-правила при этом могут располагаться на любом из компьютеров (или даже на обоих одновременно). Трехуровневая архитектура клиент-сервер — разновидность модели «клиент-сервер», в которой функция обработки данных вынесена на один или несколько отдельных серверов. Это позволяет разделить функции хранения, обработки и представления данных для более эффективного использования возможностей серверов и клиентов [24]. Достоинства: масштабируемость; конфигурируемость — изолированность уровней друг от друга позволяет (при правильном развертывании архитектуры) быстро и простыми средствами переконфигурировать систему при возникновении сбоев или при плановом обслуживании на одном из уровней; высокая безопасность; высокая надёжность; низкие требования к скорости канала (сети) между терминалами и сервером приложений; низкие требования к производительности и техническим характеристикам терминалов, как следствие снижение их стоимости. Терминалом может выступать не только компьютер, но и, например, мобильный телефон [20]. Недостатки вытекают из достоинств. По сравнению c клиент-серверной или файл-серверной архитектурой можно выделить следующие недостатки трёхуровневой архитектуры: более высокая сложность создания приложений; сложнее в разворачивании и администрировании; высокие требования к производительности серверов приложений и сервера базы данных, а, значит, и высокая стоимость серверного оборудования; высокие требования к скорости канала (сети) между сервером базы данных и серверами приложений. На рисунке 7 показана трехуровневая модель «клиент-сервер». Здесь клиент это пользовательский интерфейс к данным, а данные находятся на удаленном сервере. Клиентное приложение делает запросы для получения доступа или изменения данных через сервер. Если клиент, сервер и бизнес-правила распределены по отдельным компьютерам, разработчик может оптимизировать доступ к данным и поддерживать их целостность во всей системе. 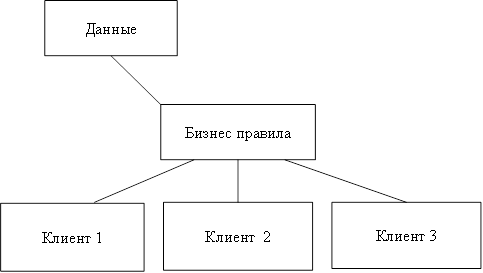 Рисунок 7 - Трехуровневая модель «клиент-сервер». Технология клиент-сервер — это особый способ взаимодействия компьютеров в локальной сети, при котором один из компьютеров (сервер) предоставляет свои ресурсы другому компьютеру (клиенту). В соответствии с этим различают одноранговые сети и серверные сети [12]. При одноранговой архитектуре в сети отсутствуют выделенные серверы, каждая рабочая станция может выполнять функции клиента и сервера. В этом случае рабочая станция выделяет часть своих ресурсов в общее пользование всем рабочим станциям сети. Как правило, одноранговые сети создаются на базе одинаковых по мощности компьютеров. Одноранговые сети являются достаточно простыми в наладке и эксплуатации. В том случае, когда сеть состоит из небольшого числа компьютеров и ее основной функцией является обмен информацией между рабочими станциями, одноранговая архитектура является наиболее приемлемым решением [3]. Наличие распределенных данных и возможность изменения своих серверных ресурсов каждой рабочей станцией усложняет защиту информации от несанкционированного доступа, что является одним из недостатков одноранговых сетей. Понимая это, разработчики начинают уделять особое внимание вопросам защиты информации в одноранговых сетях. Другим недостатком одноранговых сетей является их более низкая производительность. Это объясняется тем, что сетевые ресурсы сосредоточены на рабочих станциях, которым приходится одновременно выполнять функции клиентов и серверов. В серверных сетях осуществляется четкое разделение функций между компьютерами: одни их них постоянно являются клиентами, а другие — серверами. Учитывая многообразие услуг, предоставляемых компьютерными сетями, существует несколько типов серверов, а именно: сетевой сервер, файловый сервер, сервер печати, почтовый сервер и др. Сетевой сервер представляет собой специализированный компьютер, ориентированный на выполнение основного объема вычислительных работ и функций по управлению компьютерной сетью. Этот сервер содержит ядро сетевой операционной системы, под управлением которой осуществляется работа всей локальной сети. Сетевой сервер обладает достаточно высоким быстродействием и большим объемом памяти. При подобной сетевой организации функции рабочих станций сводятся к вводу-выводу информации и обмену ею с сетевым сервером [18]. Термин файловый сервер относится к компьютеру, основной функцией которого является хранение, управление и передача файлов данных. Он не обрабатывает и не изменяет сохраняемые и передаваемые им файлы. Сервер может «не знать», является ли файл текстовым документом, графическим изображением или электронной таблицей. В общем случае на файловом сервере может даже отсутствовать клавиатура и монитор. Все изменения в файлах данных осуществляются с клиентских рабочих станций. Для этого клиенты считывают файлы данных с файлового сервера, осуществляют необходимые изменения данных и возвращают их обратно на файловый сервер. Подобная организация наиболее эффективна при работе большого количества пользователей с общей базой данных. В рамках больших сетей может одновременно использоваться несколько файловых серверов. Сервер печати (принт-сервер) представляет собой печатающее устройство, которое с помощью сетевого адаптера подключается к передающей среде. Подобное сетевое печатающее устройство является самостоятельным и работает независимо от других сетевых устройств. Сервер печати обслуживает заявки на печать от всех серверов и рабочих станций. В качестве серверов печати используются специальные высокопроизводительные принтеры. При высокой интенсивности обмена данными с глобальными сетями в рамках локальных сетей выделяются почтовые серверы, с помощью которых обрабатываются сообщения электронной почты. Для эффективного взаимодействия с сетью Internet могут использоваться Web-серверы [12]. 2.2 Стратегии распределения данных Стратегия распределения данных по узлам сети ЭВМ могут классифицироваться в зависимости от количества узлов, содержащих данные, и наличия дублирования информации. Допустимые стратегии определяются архитектурой системы и программным обеспечением системы управления базой данных. Особенности реализации стратегий распределения данных определяются обычно в процессе проектирования базы данных. Существует четыре альтернативные стратегии распределения данных: Централизация (единственная копия базы данных, расположена в одном узле), Расчленение (единственная копня базы данных, непересекающиеся подмножеств распределены по различным узлам), Дублирование (несколько копий базы данных, в каждом узле располагается полная копня всех данных), Смешанная (несколько копий подмножеств базы данных, в каждом узле может содержаться произвольный фрагмент базы данных). Система управления распределенными базами данных, допускающая лишь централизованное распределение, является простейшей, а система, допускающая смешанное распределение данных, —наиболее сложной. Стратегии расчленения и дублирования являются в различной степени более сложными, чем централизованная. Стратегии расчленении предполагает наличие лишь одной копии базы данных, но при этом необходимо знать, какая часть базы данных расположена в каждом узле. Стратегия дублирования предполагает наличие в каждом узле полной копии базы данных, причем все копии должны обслуживаться согласованно для обеспечения их полноты и целостности. Смешанная стратегия сочетает сложности двух других распределенных стратегии, приобретая при этом гибкость и достоинства обеих стратегий. Для системы управления распределенными базами данных может потребоваться следить за изменением состояний копий каждого подмножества базы данных, а также за размещением каждой копии. Основным преимуществом централизованной базы данных (рис. 1) является простота. Все операции осуществляются под контролем единственного узла, все проблемы и действия полностью ясны. Так как в централизованных базах данных все данные располагаются в единственном узле, то наличие вторичной памяти в этом узле ограничивает возможный размер базы данных. Все запросы на выборку и обновление данных направляются в центральный узел со всеми сопутствующими затратами на стоимость связи и временную задержку. База может быть недоступной для удаленных пользователей при появлении ошибок связи и полностью выходит из строя при отказе центрального сервера. 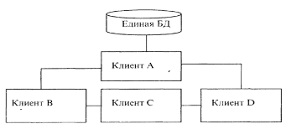 Рис. 1 – Стратегия централизации распределения данных При распределении данных на основе стратегии расчленения база данных распределяется по многим узлам сети, но существование копий отдельных частей базы данных не допускается. База данных разделяется на непересекающееся подмножества (логические фрагменты) и каждый логический фрагмент размещается в отдельном узле. Объем базы данных ограничивается объемом вторичной памяти, имеющейся во всей сети, анне в единственном узле. Эффективность стратегии расчленения тем выше, чем выше степень локализации ссылок, то есть чем больше число запросов пользователей реализуется в базах данных соответствующих локальных информационных систем (рис.2). 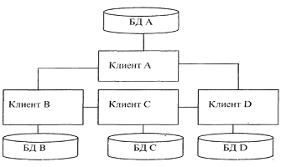 Рис. 2 – Стратегия расчленения распределения данных Достоинствами данного метода являются увеличение объема базы данных; большинство запросов удовлетворяется локальными базами, что сокращает время ответа; увеличение доступности и надежности; снижение стоимости запросов на выборку и обновление по сравнению с централизованным распределением; система останется частично работоспособной, если выйдет из строя один сервер. К недостаткам метода относится то, что часть удаленных запросов или транзакций могут потребовать доступ ко всем серверам, что увеличивает время ожидания и цену; необходимо иметь сведения о размещении данных в БД. Однако доступность и надежность увеличиваются. Расчлененные базы данных наиболее подходят к случаю совместного использования локальных и глобальных сетей ЭВМ. При распределении данных с использованием стратегии дублирования (рис. 3) в каждом узле сети размещается полная копия базы данных, т.е. в каждом узле, в котором имеются данные, имеется вся база данных. Основное преимущество данной стратегии заключаются в высокой надежности, доступности и эффективности выборки. Недостатками стратегии дублирования являются повышенные требования к объему внешней памяти, усложнение корректировки баз, т.к. требуется синхронизация с целью согласования копий. К достоинствам стратегии относится то, что все запросы выполняются локально, благодаря чему обеспечивается быстрый доступ. 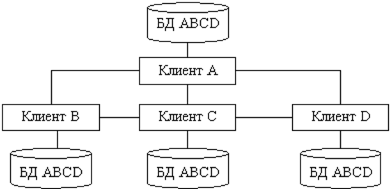 Рис. 3 – Стратегия дублирования распределения данных Смешанная стратегия распределения данных (рис. 4) объединяет подходы, связанные с расчленением и дублированием данных с целью приобретения преимуществ, которыми они обладают. Эта стратегия подразделяет базы данных на логические фрагменты, как это делается в стратегии расчленения, но в дополнение к этому дает возможность иметь произвольное количество физических копий каждого фрагмента, называемых хранимыми фрагментами. Ключевым преимуществом этой системы является гибкость, т.к. можно установить компромисс между объемом памяти, используемой в целом и в каждом отдельном узле, для обеспечения надежности и эффективности работы. В этой стратегии легко реализуется параллельная обработка, т.е. обслуживание распределенного запроса или транзакции. Недостатком стратегии остается проблема взаимозависимости факторов, влияющих на производительность системы, ее надежность, повышаются требования к памяти. 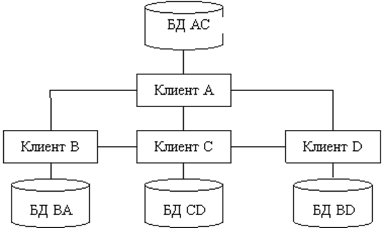 Рис. 4 – Стратегия смешанного распределения данных 2.3 Распределение сетевого справочника данных Справочник сетевой базы данных может быть распределен по узлам сети согласно любой из четырех стратегий, применяющихся для самой базы данных: централизованной, расчлененной, дублированной или смешанной. Какая стратегия является наиболее подходящей, определяется обычно сочетанием стратегий распределения данных, используемым сетевой СУБД, и допущениями относительно требований (пользователей и приложений) к системам баз данных. Это означает, что обычно основная стратегия будет предоставляться сетевой СУБД и, следовательно, ее воздействия должны быть оценены до выбора именно сетевой СУБД. Многое из сказанного о распределении данных может быть перенесено и на распределения справочника. Например, наличие нескольких копий справочника приводит к необходимости согласования при его модификации. Хотя теоретически можно пользоваться любой стратегией распределения справочника независимо от стратегии распределения данных, на практике используется лишь несколько сочетаний. Использование стратегии централизации при распределении справочника совместно со смешанной стратегией распределении данных обычно приводит к потеря многих преимуществ, присущих смешанной стратегией распределения данных. Необходимо отметить, что характеристики запросов к сетевому справочнику, такие, как отношение количества обновлений к количеству выборок (изменчивость), и ряд других важных при выборе стратегии распределения характеристик могут сильна различаться для сетевого справочника и собственно для базы данных, управляемой этим справочником. Запросы на выборку из справочника возникают при обработке любого запроса пользователя, что служит доводом в пользу расчлененного и дублированного справочника. При использовании смешанной стратегии требуется иметь справочник справочника, чтобы обеспечить возможность сетевой СУБД найти необходимую часть справочника. В системе SDD-1 такой справочник называется указателем справочника и дублируется в каждом узле. В общем сетевой справочник рассматривается как часть сетевой СУБД, а не как отдельный объект. Применяемая стратегия распределения справочника должна рассматриваться в свете стратегии распределения данных и целей функционирования базы данных. Проектирование сетевого справочника может потребоваться уже при реализации базы данник, хотя при этом возможно возникновение большого количества ограничений по сравнению с количеством ограничений на этапе проектирования базы данных Некоторые СУБД могут потребовать размещения сетевого справочника аналогично размещению данных. То есть, сетевой справочник может быть разделен на логические фрагменты, а затем логические фрагменты могут быть размещены по узлам сети, возможно с использованием избыточности. Если справочник обрабатывается аналогично базе данных, то такие механизмы поддержания базы данных, как управление параллелизмом и безопасность, также применяются и для поддержания справочника. При этом необходимо еще раз оценить такие факторы, как надежность, и характеристики производительности. |