Реферат (1). Обеспечение надежности передачи и хранения информации. Вторая теорема Шеннона.
 Скачать 476.97 Kb. Скачать 476.97 Kb.
|

|
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ АВТОНОМНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ «БАЛТИЙСКИЙ ФЕДЕРАЛЬНЫЙ УНИВЕРСИТЕТ им. И. КАНТА» ИНСТИТУТ ФИЗИКО-МАТЕМАТИЧЕСКИХ НАУК И ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ Реферат Тема: «Обеспечение надежности передачи и хранения информации. Вторая теорема Шеннона.» Направление подготовки: «Прикладная математика и информатика» Выполнил: студент 1 курса магистратуры Исмаилзада Э. Б. Калининград 2020ОглавлениеОбеспечение надежности передачи информацииПостановка задачи обеспечения надежности передачи информацииВсе реальные каналы связи подвержены воздействию помех. Означает ли это, что надежная (то есть без потерь) передача по ним информации невозможна в принципе? К. Шеннон доказал теоретическую возможность передачи сообщения без потерь информации по реальным каналам, если обеспечить выполнение ряда условий. Задача была сформулирована в виде теоремы, которая затем получила строгое математическое доказательство. Первая теорема Шеннона, касается кодирования информации при передаче по идеальному каналу связи. Критерием оптимальности кодирования служит избыточность кода. Эту избыточность можно сделать сколь угодно малой (близкой к нулю), применяя блочное кодирование по методу Хаффмана. Вторая теорема Шеннона касается реальных каналов связи и гласит: При передаче информации по каналу с шумом всегда существует способ кодирования, при котором сообщение будет передаваться со сколь угодно высокой достоверностью, если скорость передачи не превышает пропускной способности канала. Из этой теоремы следуют два вывода: в случае передачи сообщений, как по идеальному (без помех), так и по реальному (с помехами) каналу связи при превышении скорости передачи пропускной способности канала возможна потеря информации. при передаче по реальным каналам можно закодировать сообщение таким образом, что воздействие шумов не приведет к потере информации. То есть, теоретически он доказал возможность построения таких методов кодирования информации, которые позволили бы контролировать правильность передачи (хранения) и при обнаружении ошибки исправлять ее. Последняя часть определения, относится и к идеальному каналу – в любом случае, если скорость передачи превышает пропускную способность канала, происходит потеря информации. Смысл данной теоремы в том, что при передаче по реальным каналам можно закодировать сообщение таким образом, что действие шумов не приведет к потере информации. Это достигается за счет повышения избыточности кода, то есть за счет увеличения длины кодовой цепочки. Безусловно, при этом возрастает время передачи, что следует считать платой за надежность. При этом в теореме и в ее доказательстве не указывается, каким образом следует осуществлять такое кодирование. Вторая теорема Шеннона лишь утверждает, что существует принципиальная возможность такого кодирования, причем поиск необходимого кода – это отдельная задача. Для примера оценим, какова вероятность возникновения ошибки, но не при передаче, а при хранении информации (что не меняет сути дела). Тем самым подчеркнем важность учета влияния помех не только на передачу, но и на хранение информации. Рассмотрим следующую ситуацию. Пластмассовые корпуса микросхем памяти в компьютерах содержат в малых количествах примеси, претерпевающие Предположив, что оперативная память персонального компьютера составляет 48 Мбайт, можно заключить, что время появления ошибки составляет уже около 1 дня. Нужно отметить, что в настоящее время нет экономичных технических способов исключения влияния этих ионизирующих излучений на элементы памяти. Поэтому проблема защиты информации от искажений не только при передаче, но и при хранении весьма актуальна. Решение проблемы, как уже было сказано, состоит в использовании таких методов кодирования информации, которые позволили бы контролировать правильность передачи (или хранения) информации, а при обнаружении ошибки эти методы должны позволять исправлять ее. Общим условием осуществимости обнаружения и исправления ошибки является использование только равномерных кодов. Во-первых, в этом случае недополучение одного из битов будет сразу свидетельствовать об ошибочности передачи, то есть постоянство длины кодовой цепочки является дополнительным средством контроля правильности передачи. Во-вторых, часто для увеличения скорости передачи используется параллельная (одновременная) передача нескольких (фиксированного, постоянного количества) бит по шинам (с фиксированной, разумеется, шириной). Надежность передачи обеспечивается тем, что наряду с битами, непосредственно кодирующими сообщение (информационными битами), передаются (или хранятся) дополнительные биты (контрольные биты). При равномерном кодировании сообщения длина Избыточность сообщения – это величина, показывающая, во сколько раз требуется удлинить сообщение, чтобы обеспечить его надежную (безошибочную) передачу (хранение). Таким образом, величина L характеризует эффективность кодирования при передаче по реальным каналам. Если какие-то два способа кодирования обеспечивают одинаковую надежность передачи, то при равных надежностях предпочтение должно быть отдано тому способу, при котором избыточность окажется наименьшей. Однако надо отметить, что для практики важна еще и простота того или иного способа кодирования. Далее рассмотрим отдельно две ситуации: способ кодирования обеспечивает только установление факта искажения информации – в этом случае исправление ошибки производится путем повторной передачи сообщения; способ кодирования позволяет локализовать (обнаружить факт существования ошибки и найти ее) и автоматически исправить ошибку передачи (хранения). Коды, обнаруживающие одиночную ошибкуЗадача обнаружения ошибки может быть решена довольно легко. Достаточно просто передавать каждую букву сообщения дважды. Например, при необходимости передачи слова «гора» можно передать «ггоорраа». При получении искаженного сообщения, например, «гготрраа» с большой вероятностью (практически, достоверно) можно догадаться, каким было исходное слово. Конечно, возможно такое искажение, которое делает неоднозначным интерпретацию полученного сообщения. Однако цель такого способа кодирования состоит не в исправлении ошибки, а в обнаружении факта искажения и в повторной передаче подозрительной на наличие ошибки части сообщения. Недостаток данного способа обеспечения надежности состоит в том, что относительная избыточность сообщения оказывается очень большой – очевидно, Так как должен быть установлен только факт наличия ошибки, можно предложить и другой способ, позволяющий с высокой вероятностью обнаружить ошибку в сообщении. Суть этого способа заключается в следующем. На входе в канал связи производится подсчет числа единиц в двоичной кодовой последовательности – во входном сообщении. Если число единиц оказывается нечетным, то в хвост передаваемого сообщения добавляется «1», а если нет, то «0». Таким образом, к сообщению добавляют так называемый контрольный бит четности, чтобы суммарное количество единиц вместе с этим контрольным битом было четным. На принимающем конце канала связи производится аналогичный подсчет числа единиц, и если контрольная сумма единиц в принятой кодовой последовательности оказывается нечетной, то делается вывод о том, что при передаче произошло искажение информации, в противном случае принятая информация признается правильной. Разумеется, этот способ отнюдь не совершенен и применяется, когда вероятность ошибки не очень велика. При контроле на четность единственный способ получить достоверную информацию – это повторная передача сообщения. Избыточность сообщения при контроле на четность равна: На первый взгляд кажется, что путем увеличения Коды, исправляющие одиночную ошибкуПо аналогии с предыдущим пунктом можно было бы предложить простой способ установления факта наличия ошибки – передавать каждый символ сообщения трижды, например, «гггооорррааа» – тогда при получении, например, сообщения «гггооопррааа» ясно, что ошибочной является буква «п» и ее следует заменить на «р». Безусловно, при этом предполагается, что вероятность появления парной ошибки невелика. Такой метод кодирования приводит к огромной избыточности сообщения Прежде, чем обсуждать метод кодирования, позволяющий локализовать и исправить ошибку передачи, произведем некоторые количественные оценки. Как указывалось в предыдущей лекции, наличие шумов в канале связи ведет к частичной потере передаваемой информации на величину возникающей неопределенности. В случае передачи одного бита исходного сообщения эта неопределенность составляет где p – вероятность появления ошибки в сообщении (искажения этого бита, то есть его инверсии в случае двоичного кодирования нулями и единицами). Для восстановления информационного содержания сообщения следует дополнительно передать количество информации не менее величины ее потерь, то есть вместо передачи каждого 1 бита следует передавать Эта избыточность является минимальной; в случае передачи сообщения по каналу, характеризуемому определенной вероятностью возникновения ошибки, при избыточности, меньшей минимальной, восстановление информации оказывается невозможным. Выражение указывает нижнюю границу избыточности, необходимой для восстановления информации. Однако поиск конкретного способа осуществления кодирования, при котором ошибка может быть локализована (то есть определено, в каком конкретно бите она находится) и устранена – отдельная задача, которую мы теперь и обсудим. Изложенный ниже метод кодирования был предложен в 1948 году Р. Хеммингом; построенные по этому методу коды получили название «коды Хемминга». Основная идея такого кодирования состоит в добавлении к информационным битам нескольких битов четности, каждый из которых контролирует определенные информационные биты. Если пронумеровать все передаваемые биты (вместе с битами четности) слева направо (напомним, что информационные биты нумеруются справа налево – от 0 до 7), то контрольными (проверочными) оказываются биты, номера которых равны степени 2, а остальные биты являются информационными. Например, для 8-битного информационного кода «01101101» передаваемый код (код Хемминга) будет 12-битным, так как к информационному коду добавятся 4 контрольных бита – 1-й, 2-й, 4-й и 8-й. Принцип выделения контролируемых битов такой: для любого номера n проверочного (контрольного) бита, начиная с него, n битов подряд оказываются проверяемыми (контролируемыми), затем – группа из n непроверяемых бит, и так далее – происходит чередование групп. В число контролируемых (проверяемых) битов входит и сам контрольный (проверочный). Состояние контрольного (проверочного) бита устанавливается при кодировании таким образом, чтобы суммарное количество единиц во всех контролируемых им битах было бы четным. Таким образом, контрольный (проверочный) бит может содержать как нуль, так и единицу.Номера контролируемых (прверяемых) битов для каждого контрольного приведены в табл. 1: Табл. 1. Контрольные и контролируемые биты
Контрольный бит (бит четности) признается неверным, если сумма единиц в контролируемых им битах (включая его самого) нечетна.Если контрольный бит оказался неверным, значит, в каком-то из контролируемых им битов имеется ошибка.Существует общее свойство кодов Хемминга: Ошибка содержится в бите, номер которого является суммой номеров неверных контрольных битов, указавших на ее наличие. На основании сказанного можно сформулировать простой алгоритм проверки и исправления передаваемой кодовой последовательности в представлении Хемминга: Произвести проверку всех битов четности; Если все биты четности верны, то перейти к пункту е); Вычислить сумму номеров всех неверных битов четности; Инвертировать (единицу заменить на нуль или наоборот) содержимое бита, номер которого равен сумме, найденной в пункте с); Исключить биты четности. Избыточность кодов Хемминга для различных длин передаваемых кодовых последовательностей приведена в табл. 2: Табл. 2. Избыточность кодов Хемминга для передаваемых кодовых последовательностей различной длины
Количество контрольных битов определяется следующим образом (см. таблицу выше): Из сопоставления данных этой таблицы видно, что выгоднее (с меньшей избыточностью) передавать и хранить более длинные последовательности битов. При этом избыточность не должна оказаться меньше, чем минимально допустимая Данный способ кодирования требует увеличения объема памяти компьютера приблизительно на одну треть при 16-битной длине машинного слова (см. таблицу), однако такой способ позволяет автоматически исправлять одиночные ошибки. Поэтому, оценивая время наработки на отказ этого способа, следует исходить из вероятности появления парной ошибки внутри одной кодовой последовательности (то есть сбои должны произойти в двух битах одновременно). Расчеты показывают, что для указанного ранее количества ( Обеспечение надежности хранения информацииС каждым годом производительность компьютерного железа увеличивается высокими темпами. Процессоры оснащают все большим количеством ядер и потоков, а видеокарты покоряют более высокую частоту чипа. Однако, что касается жестких дисков, пока их предел скорости застыл на отметке 7200 об/мин. Технические характеристики HDD в последнее время изменяются только в плане объема, но не скорости. Исправить такую ситуацию могут SSD-накопители, но, как правило, они значительно дороже и обладают относительно низким ресурсным потенциалом. Еще до появления SSD на свет в 1987 году были придуманы так называемые RAID-массивы. RAID (англ. Redundant Array of Independent Disks — избыточный массив независимых дисков) — технология виртуализации данных, которая объединяет несколько дисков в логический элемент для повышения производительности. Соответственно, минимальное количество требуемых дисков — 2, но может потребоваться и больше. Всё зависит от того, какой именно массив вам нужен и для чего. RAID 0Принцип работы — striping (чередование). Массив при котором информация разбивается на одинаковые по длине блоки, а затем записывается поочерёдно на каждый диск в структуре. Основное предназначение такой системы — фактическое увеличение производительности в 2 раза, при этом вам будет доступен полный объем всех дисков. Можно использовать неограниченное количество дисков. В случае если диски обладают разными показателями скорости, то конечный результат будет высчитываться по самому медленному HDD. Позволяет объединять диски любого объема. Например, 320 Гбайт + 1 Тбайт + 3 Тбайт — будут функционировать должным образом. 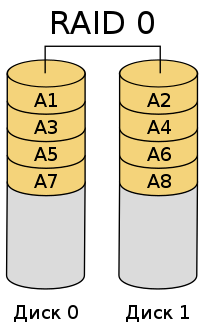 Рис.2 Схема RAID 0 Преимущества Высокая производительность Недостатки Низкая надежность Сложность подбора дисков с одинаковыми характеристиками RAID 1Принцип работы — mirroring («зеркалирование»). Самая простая система RAID-массивов из всех возможных. Представляет собой параллельную запись информации с основного диска на другие — дублирующие. Производительность при этом никак не изменяется. Имеет широкое применение в серверном обслуживании, потому что в случае выхода из строя одного из накопителей, все продублированные данные остаются на других носителях. При этом вам будет доступен объем лишь одного винчестера. Предположим у вас есть 3 диска по 500 Гбайт каждый. Из 1500 Гбайт вам останется лишь 500 Гбайт. В общем, предназначение таких систем — резервация и клонирование информации. Есть смысл использовать диски с высокой скоростью (7200 об/мин) — например, такой:. RAID 1 часто используют в корпоративной сфере, где потеря информации может обернуться серьезными убытками. 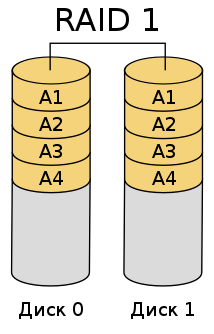 Рис. 3. Схема RAID 1. Преимущества: Высокая надежность Недостатки: Дороговизна RAID 10 (1+0)Все остальные виды массивов являются различными вариациями первых двух. RAID 10 — совмещает в себе всё самое лучшее из RAID 1 и RAID 0. Вам потребуется минимум 4 носителя, и их количество всегда должно быть четным. В данном массиве вы получаете высокую производительность и высокую надежность. Однако, как в случае и с RAID 1, вам будет доступна лишь половина от общего объема всей системы. Пример. 4 винчестера на 1000 Гбайт со скоростью 200 Мбайт/c. Итоговая скорость — 400 Мбайт/c. Итоговый объем — 2000 Гбайт.  Рис. 4. Схема RAID 10 Преимущества : Высокая производительность Высокая надежность Недостатки : Итоговый объем равный 1/2 от общего Дороговизна RAID 5Сильно схож по своему принципу работы с RAID 1. Только вам теперь потребуется минимум 3 накопителя, на одном из которых будет храниться продублированная информация. В этом случае вам будет доступен практически весь объем в системе, кроме одного диска с данными под восстановление. Кроме того, увеличится и производительность, но не в несколько раз, как в случае с RAID 0. Основное отличие RAID 5 от RAID 10 — это уровень надежности и доступный объем. Данный массив предназначен для более специфических задач, когда вместе собрано огромное количество дисков. Предположим, вы имеете 4 диска на 2 Тбайт каждый. RAID 10 даст вам объем равный 4 Тбайт, в 2 раза большую скорость и возможность полностью восстановить информацию в случае поломки сразу двух основных носителей. RAID 5 же в таком случае даст 6 Тбайт под ваши нужды, немного увеличенную скорость записи данных и возможность восстановления данных только с одного поврежденного винчестера. В таком случае RAID 10 выглядит более привлекательной системой, нежели RAID 5, ведь за плату в 2 Tбайт, мы получаем высокую производительность и возможность полного восстановления. Но ситуация меняется, когда дисков становится значительно больше. Как мы и говорили, RAID 5 — специфическая структура. Если вы имеете 10 дисков на 2 Тбайт каждый, то RAID 10 даст вам лишь 10 Тбайт, которые вам будут доступны. В случае с RAID 5 это уже 18 Тбайт (доступны все диски, кроме одного, который хранит дублированные данные). Здесь уже 50% доступного объема — слишком высокая цена за возможность полного восстановления и двукратную скорость. Куда выгоднее получить слегка увеличенную скорость, практически полный объем и возможность восстановления одного любого диска. Для простого же обывателя такие системы не нужны.  Рис. 5. RAID 5. Преимущества : Не требует много места под восстановление Слегка увеличивает производительность Недостатки : Не предназначен для бытового использования Обеспечивает не полное резервирование данных Прирост скорости не такой большой, как у RAID 10 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||