ЕГЭ информатика. Обработка символьных строк
 Скачать 0.5 Mb. Скачать 0.5 Mb.
|

|
© К. Поляков, 2018-2022 24 (высокий уровень, время – 18 минут)Тема: Обработка символьных строк Что проверяется: Умение создавать собственные программы (10–20 строк) для обработки символьной информации. 1.5.2. Цепочки (конечные последовательности), деревья, списки, графы, матрицы (массивы), псевдослучайные последовательности. 1.1.3. Строить информационные модели объектов, систем и процессов в виде алгоритмов. Что нужно знать: сначала нужно прочитать строку из файла; эта задача в разных языках программирования решается несколько по-разному в языке Python удобнее всего использовать такую конструкцию: with open("k7.txt", "r") as F: s = F.readline() конструкция with-as – это контекстный менеджер, в данном случае он открывает указанный файл в режиме чтения (второй аргумент «r» при вызове функции open), записывает ссылку на него в файловую переменную F, выполняет тело блока (читает первую строку файла в переменную s) и закрывает (освобождает) файл в языке PascalABC.NET можно выполнить перенаправление потока ввода: assign( input, 'k7.txt' ); readln(s); программа будет «думать», что читает данные, введённые с клавиатуры (с консоли), а на самом деле эти данные будут прочитаны из файла k7.txt в языке FreePascal также можно выполнить перенаправление потока ввода, но нужно дополнительно открывать входной поток: assign( input, 'k7.txt' ); reset( input ); { для FreePascal!!! } readln(s); при работе в среде FreePascal нужно убедиться, что в параметрах компилятора включена поддержка длинных символьных строк; на всякий случай стоит добавить в первой строке программы директиву {$H+} Среда PascalABC НЕ ПОДДЕРЖИВАЕТ работу с длинными символьными строками, поэтому для решения задачи использовать версию PascalABC.NET, которую можно бесплатно скачать с сайта автора www.pascalabc.net. в языке С++ используем потоки: #include <fstream> #include using namespace std; int main() { ifstream F("k7.txt"); string s; getline( F, s ); ... } Самая длинная цепочка символов «С» пусть требуется найти самую длинную цепочку символов С (или каких-то других, в соответствии с заданием) в символьной строке s; можно использовать такой алгоритм: while не конец строки: найти очередную букву C длина := длина текущей цепочки букв C if длина > максимальной длины: максимальная длина := длина однако этот алгоритм содержит вложенный цикл и при составлении программы легко запутаться и не учесть какой-то особый случай (например, когда строка состоит только из букв С) лучше применить однопроходный алгоритм без вложенного цикла for c in s: обработать символ c будем использовать переменные cLen – длина текущей цепочки букв C maxLen – максимальная длина цепочки букв C на данный момент рассмотрим очередной символ строки; если это буква C, увеличиваем cLen на 1 и, если нужно запоминаем новую максимальную длину; если это не буква C, просто записываем с cLen ноль: maxLen = 0 cLen = 0 for c in s: if c == 'C': cLen += 1 # ещё одна буква C if cLen > maxLen: # возможно, новая максимальная длина maxLen = cLen else: cLen = 0 # цепочка букв C кончилась проверим правильность работы алгоритма в особых случаях: если вся строка состоит из букв C, значение переменной cLen постоянно увеличивается и в конце станет равно длине символьной строки; то же значение окажется и в переменной maxLen; если в строке нет символов C, переменная cLen всегда равна 0, такое же значение будет и в переменной maxLen Самая длинная цепочка любых символов теперь поставим задачу найти самую длинную цепочку символов в символьной строке s; сложность состоит в том, что мы (в отличие от предыдущей задачи) не знаем, из каких именно символов состоит самая длинная цепочка если символов в алфавите немного (скажем, A, B и С), то можно с помощью описанного выше алгоритма найти самые длинные цепочки из букв A, B и C, а затем выбрать из них «длиннейшую»; такая идея может сработать при аккуратной реализации, но плохо обобщается на случай, когда возможных символов много (например, используются все заглавные латинские буквы и цифры) поэтому лучше применить однопроходный алгоритм без вложенного цикла будем использовать переменные curLen – длина текущей цепочки одинаковых символов maxLen – максимальная длина цепочки одинаковых символов на данный момент c – символ, из которого строится самая длинная подцепочка в начальный момент рассмотрим один первый символ (цепочка длины 1 есть всегда!): maxLen = 1 curLen = 1 c = s[0] будем перебирать в цикле все символы, начиная с s[1] (второго по счёту) до конца строки, постоянно «оглядываясь назад», на предыдущий символ for i in range(1,len(s)): обработать пару символов s[i-1] и s[i] если очередной символ s[i] такой же, как и предыдущий, цепочка одинаковых символов продолжается, и нужно увеличить значение переменной curLen; если значение curLen стало больше maxLen, обновляем maxLen и запоминаем новый базовый символ в переменной c: if s[i] == s[i-1]: # цепочка продолжается curLen += 1 # увеличиваем длину if curLen > maxLen: # если цепочка побила рекорд maxLen = curLen # запоминаем её длину... c = s[i] # и образующий символ else: curLen = 1 # началась новая цепочка если очередной символ не совпал с предыдущим, началась новая цепочка, и её длина пока равна 1 (это значение записывается в переменную curLen) получается такой цикл обработки строки: maxLen, curLen, c = 1, 1, s[0] for i in range(1, len(s)): if s[i] == s[i-1]: curLen += 1 if curLen > maxLen: maxLen = curLen c = s[i] else: curLen = 1 проверим правильность работы алгоритма в особых случаях: если вся строка состоит из одинаковых символов, значение переменной curLen постоянно увеличивается и в конце станет равно длине символьной строки; то же значение окажется и в переменной maxLen; если в строке нет пар одинаковых символов, переменная curLen всегда равна 1, такое же значение будет и в переменной maxLen Пример задания:Р-07 (демо-2021). Текстовый файл 24.txt состоит не более чем из 106 символов X, Y и Z. Определите максимальное количество идущих подряд символов, среди которых каждые два соседних различны. Для выполнения этого задания следует написать программу. Решение: считывание из файла и перебор символов аналогичен задачам Р00-Р02 (см. ниже). чтобы считать длину цепочки, соответствующей условию, нам нужно будет ввести два счётчика: curLen – длина текущей цепочки (которая сейчас обрабатывается) maxLen – длина самой длинной на данный момент цепочки в уже обработанной части строки обработка строки сводится к тому, что текущая длина цепочки увеличивается, если соседние символы, s[i-1] и s[i], различны; если это не так, сбрасываем длину текущей цепочки в 1 можно заметить, что эта задача очень напоминает Р-05, только тут обратное условие – нужно искать цепочку, где все соседние символы не одинаковые, а разные, поэтому и решение сводится к изменению условия (см. выделение маркером): with open( "24.txt", "r" ) as F: s = F.readline() maxLen, curLen = 1, 1 for i in range(1, len(s)): if s[i] != s[i-1]: curLen += 1 if curLen > maxLen: maxLen = curLen else: curLen = 1 print( maxLen ) Ответ: 35. программа на Паскале: var maxLen, curLen, i: integer; s: string; begin assign(input, '24.txt'); readln(s); maxLen := 1; curLen := 1; for i:=2 to Length(s) do if s[i] <> s[i-1] then begin curLen := curLen + 1; if curLen > maxLen then maxLen := curLen; end else curLen := 1; writeln(maxLen); end. программа на C++: #include #include #include using namespace std; int main() { ifstream F("24.txt"); string s; getline( F, s ); int maxLen = 1, curLen = 1; for( int i = 1; i < s.length(); i++ ) if( s[i] != s[i-1] ) { curLen ++; if( curLen > maxLen ) maxLen = curLen; } else curLen = 1; cout << maxLen; } Пример задания:Р-06. В текстовом файле k8.txt находится цепочка из символов, в которую могут входить заглавные буквы латинского алфавита A…Z и десятичные цифры. Найдите длину самой длинной подцепочки, состоящей из одинаковых символов. Для каждой цепочки максимальной длины выведите в отдельной строке сначала символ, из которого строится эта цепочка, а затем через пробел – длину этой цепочки. Решение: особенность этой задачи в сравнении с Р-05 состоит в следующем: если найдено несколько цепочек одинаковой максимальной длины, для каждой из них нужно вывести символ, из которого состоит цепочка, и длину цепочки это значит, что для хранения символа нужна не одна переменная, а массив (в Python – список); если найдена первая цепочка (выполнено условие ) итак, теперь c – это массив (список); когда найдена первая цепочка максимальной длины (на данный момент), в этот массив записывается символ этой цепочки; если же найдена новая цепочка такой же длины, в массив добавляется символ этой цепочки таким образом, в конце прохода в массиве c находятся все символы, из которых состоят самые длинные цепочки, и остаётся вывести их на экран; справа от каждого символа выводится длина цепочки: for c1 in c: print( c1, maxLen ) вот полная программа (изменения в сравнении с решением задачи Р-05 выделены): with open( "k8.txt", "r" ) as F: s = F.readline() maxLen, curLen, c = 1, 1, [s[0]] # c – массив из одного символа for i in range(1, len(s)): if s[i] == s[i-1]: curLen += 1 if curLen == maxLen: # новая цепочка максимальной длины c.append( s[i] ) # добавить символ в массив elif curLen > maxLen: maxLen = curLen c = [s[i]] # c – массив из одного символа else: curLen = 1 for c1 in c: # для всех символов в массиве print( c1, maxLen ) # вывести символ и длину Решение (программа на языке Pascal): проблема состоит в том, что мы не знаем, сколько цепочек максимальной длины может быть в файле; тут нужен динамический массив (список), для этого далее мы будем использовать язык PascalABC.NET, в котором есть тип данных List (список) вначале создаём новый список и записываем у него первый символ строки: var c := new List c.Add( s[1] ); если нашли новую (не первую) цепочку максимальной длины, добавляем новый символ в список: c.Add( s[i] ); если нашли новую самую длинную цепочку с длиной бОльшей, чем все предыдущие, очищаем список и добавляем в него новый символ. c.Clear; c.Add( s[i] ); после окончания обработки нужно вывести все символы и длины цепочек, удобнее всего использовать для этого цикл foreach; получается почти так же, как и на Python: foreach var c1 in c do writeln( c1, ' ', maxLen ); вот полная программа: var maxLen, curLen, i: integer; s: string; begin assign(input, 'k8.txt'); readln(s); maxLen := 1; curLen := 1; var c := new List c.Add( s[1] ); for i:=2 to Length(s) do if s[i] = s[i-1] then begin curLen := curLen + 1; if curLen = maxLen then begin c.Add( s[i] ); end else if curLen > maxLen then begin maxLen := curLen; c.Clear; c.Add( s[i] ); end end else curLen := 1; foreach var c1 in c do writeln( c1, ' ', maxLen ); end. Решение (программа на языке C++): динамический массив (список), для этого далее мы будем использовать тип данных list (список) из библиотеки STL; не забудьте, что нужно подключить заголовочный файл list: #include вначале создаём список символов, состоящий из одного первого символа строки: list если нашли новую (не первую) цепочку максимальной длины, добавляем новый символ в список с помощью метода push_back: c.push_back( s[i] ); если нашли новую самую длинную цепочку с длиной бОльшей, чем все предыдущие, очищаем список и добавляем в него новый символ: c.clear(); c.push_back( s[i] ); после окончания обработки нужно вывести все символы и длины цепочек, удобнее всего использовать для этого особую форму цикла for; получается почти так же, как и на Python: for( char c1: c ) cout << c1 << ' ' << maxLen << endl; вот полная программа: #include #include #include #include using namespace std; int main() { ifstream F("k8.txt"); string s; getline( F, s ); int maxLen = 1, curLen = 1; list for( int i = 1; i < s.length(); i++ ) if( s[i] == s[i-1] ) { curLen ++; if( curLen == maxLen ) c.push_back(s[i]); else if( curLen > maxLen ) { maxLen = curLen; c.clear(); c.push_back( s[i] ); } } else curLen = 1; for( char c1: c ) cout << c1 << ' ' << maxLen << endl; } Ещё пример задания:Р-05. В текстовом файле k8.txt находится цепочка из символов, в которую могут входить заглавные буквы латинского алфавита A…Z и десятичные цифры. Найдите длину самой длинной подцепочки, состоящей из одинаковых символов. Выведите сначала символ, из которого строится цепочка, а затем через пробел – длину этой цепочки. Замечание (Б.С. Михлин). Может случиться так, что в файле будут несколько самых длинных цепочек (одинаковой длины), состоящих из разных символов. На этот случай условие задачи требует уточнения – какой именно символ выводить в ответе? Далее мы будем считать, что в этом случае нужно вывести символ, который формирует первую цепочку максимальной длины. Решение: сначала нужно открыть файл и прочитать все символы в символьную строку: with open("k8.txt", "r") as F: s = F.readline() теперь задача свелась к определению наибольшего количества подряд идущих одинаковых символов в символьной строке s (этот алгоритм приведён в начале файла) полная программа на языке Python: with open( "k8.txt", "r" ) as F: s = F.readline() maxLen, curLen, c = 1, 1, s[0] for i in range(1, len(s)): if s[i] == s[i-1]: curLen += 1 if curLen > maxLen: maxLen = curLen c = s[i] else: curLen = 1 print( c, maxLen ) Обратим внимание, что условие if curLen > maxLen: ... гарантирует, что будет запомнена именно первая цепочка максимальной длины, так как это условие выполнится, когда новая цепочка строго длиннее предыдущего «рекорда». Если бы нужно было вывести символ, формирующий последнюю из самых длинных цепочек, неравенство следовало бы сделать нестрогим: if curLen >= maxLen: ... Решение (программа на языке Pascal): далее мы будем использовать язык PascalABC.NET, который обладает двумя важными достоинствами, упрощающими решение таких задач: позволяет легко переключать входной поток с консоли на нужный файл: assign( input, 'k8.txt' ); теперь можно писать программу так же, как и при вводе данных с клавиатуры, а она на самом деле будет читать их из указанного файла; не имеет ограничения на длину строк (переменных типа string); в устаревших версиях языка Pascal длина строки не может превышать 255 символов читаем одну строку из файла в строковую переменную s: readln(s); теперь можно в цикле перебрать все символы строки s, начиная со второго (чтобы сравнивать его с предыдущим): for i:=2 to Length(s) do обработать пару s[i-1] и s[i] обработка выполняется по алгоритму, описанному выше (см. программу на Python) полная программа на языке Pascal: var maxLen, curLen, i: integer; s: string; c: char; begin assign(input, 'k8.txt'); readln(s); maxLen := 1; curLen := 1; c := s[1]; for i:=2 to Length(s) do if s[i] = s[i-1] then begin curLen := curLen + 1; if curLen > maxLen then begin maxLen := curLen; c := s[i]; end end else curLen := 1; writeln(c, ' ', maxLen); end. Решение (программа на языке C++): в C++ удобно работать с файлами через файловые потоки; для того, чтобы использовать эту возможность, нужно подключить заголовочный файл fstream: #include теперь можно открыть файловый поток, связать его с нужным файлом и прочитать из потока строку в переменную типа string: ifstream F("k8.txt"); string s; getline( F, s ); алгоритм обработки строки тот же, что и в программах на языках Python и Pascal, рассмотренных выше поскольку в программе используется много объектов из пространства имён std, имеет смысл подключить его в начале программы: using namespace std; полная программа на языке C++: #include #include #include using namespace std; int main() { ifstream F("k8.txt"); string s; getline( F, s ); int maxLen = 1, curLen = 1; char c = s[0]; for( int i = 1; i < s.length(); i++ ) if( s[i] == s[i-1] ) { curLen ++; if( curLen > maxLen ) { maxLen = curLen; c = s[i]; } } else curLen = 1; cout << c << ' ' << maxLen; } Ещё пример задания:Р-04. (А.М. Кабанов) В текстовом файле k7.txt находится цепочка из символов латинского алфавита A, B, C, D, E. Найдите количество цепочек длины 3, удовлетворяющих следующим условиям: 1-й символ – один из символов B, C или D; 2-й символ – один из символов B, D, E, который не совпадает с первым; 3-й символ – один из символов B, C, E, который не совпадает со вторым. Решение: Считывание из файла и перебор символов аналогичен задачам Р00-Р02 (см. ниже). Переберём все тройки символов. Примем, что переменная i будет хранить номер первого элемента в тройке, то есть, будем рассматривать тройки (s[i], s[i+1], s[i+2]). Организуем цикл который перебирает значения i от 1 до len(s)-2 for i in range(len(s)-2): ... Проверяем символы в каждой тройке на соответствие условию. Проверка принадлежности символов набору аналогична заданию 1. Дополнительно необходимо указать условия неравенства символов, указанных в условии задачи. Если условия выполняются, то к переменной количества прибавляется единица. полная программа на Python: s = open('k7.txt').read() count = 0 for i in range(len(s)-2): if s[i] in 'BCD' and s[i+1] in 'BDE' \ and s[i+2] in 'BCE' and s[i]!=s[i+1] \ and s[i+1]!=s[i+2]: count += 1 print(count) Решение (программа на языке PascalABC.NET): begin var s: string; var i, count: integer; assign(input,'k7.txt'); readln(s); count:=0; for i:=1 to Length(s)-2 do if (s[i] in 'BCD') and (s[i+1] in 'BDE') and (s[i+2] in 'BCE') and (s[i]<>s[i+1]) and (s[i+1]<>s[i+2]) then count := count+1; writeln(count); end. Решение (программа на языке С++): using namespace std; #include #include #include int main(){ ifstream F("k7.txt"); string s; getline( F, s ); int count = 0; for( int i = 0; i < s.length()-2; i++ ) if( (s[i]=='B' || s[i]=='C' || s[i]=='D') && (s[i+1]=='B' || s[i+1]=='D' || s[i+1]=='E') && (s[i+2]=='B' || s[i+2]=='C' || s[i+2]=='E') && s[i]!=s[i+1] && s[i+1]!=s[i+2] ) count++; cout << count; } Ещё пример задания:Р-03. (А.М. Кабанов) В текстовом файле k7.txt находится цепочка из символов латинского алфавита A, B, C, D, E. Найдите максимальную длину цепочки вида EABEABEABE... (составленной из фрагментов EAB, последний фрагмент может быть неполным). Решение: Считывание из файла и перебор символов аналогичен задачам Р00-Р02 (см. ниже). Проверка того, что символ принадлежит цепочке, производится следующим образом. Заметим, что в искомой цепочке чередуется группа из трёх символов (EAB). Пронумеруем символы искомой цепочки, начиная с нуля.  Видно, что позиция каждого символа имеет одинаковый остаток от деления на 3. Позиция есть значения переменной счётчика в момент проверки символа. Поэтому если совпадает символ и соответствующий ему остаток от деления, то он принадлежит цепочке. Для приведённого примера условие проверки выглядит так if (char == 'E' and count%3==0) or \ (char == 'A' and count%3==1) or \ (char == 'B' and count%3==2): Если символ не является частью этой цепочки, но может являться её началом (Е), длина цепочки принимается равной единице, в противном случае длина обнуляется elif (char=='E'): count = 1 else: count = 0 Полная программа на языке Python: s = open('k7.txt').read() count = 0 maxCount = 0 for char in s: if (char == 'E' and count%3 == 0) or \ (char == 'A' and count%3 == 1) or \ (char == 'B' and count%3 == 2): count += 1 if count > maxCount: maxCount = count elif (char=='E'): count = 1 else: count = 0 print(maxCount) Решение (полная программа на языке PascalABC.NET): begin var s: string; var i, count, maxCount: integer; assign(input,'k7.txt'); readln(s); count:=0; maxCount:=0; for i:=1 to Length(s) do if ((s[i]='E') and (count mod 3=0)) or ((s[i]='A') and (count mod 3=1)) or ((s[i]='B') and (count mod 3=2)) then begin count := count+1; if count > maxCount then maxCount := count; end else if s[i]='E' then count:=1 else count := 0; writeln(maxCount); end. Решение (полная программа на языке С++): using namespace std; #include #include #include int main(){ ifstream F("k7.txt"); string s; getline( F, s ); int count = 0, maxCount = 0; for( int i = 0; i < s.length(); i++ ) if( (s[i] == 'E' && count%3 == 0) || (s[i] == 'A' && count%3 == 1) || (s[i] == 'B' && count%3 == 2) ) { count ++; if( count > maxCount ) maxCount = count; } else if(s[i]== 'E') count = 1 else count = 0 cout << maxCount; } Решение (программа на Python, М. Магомедов): with open( "k7.txt", "r" ) as F: s = F.readline() k = '' while k in s: k += 'E' if k in s: k += 'A' if k in s: k += 'B' print ( len (k) - 1 ) Ещё пример задания:Р-02. (А.М. Кабанов) В текстовом файле k7.txt находится цепочка из символов латинского алфавита A, B, C, D, E. Найдите длину самой длинной подцепочки, состоящей из символов A, B или C (в произвольном порядке). Решение: сначала нужно открыть файл и прочитать все символы в символьную строку: s = open('k7.txt').read() теперь можно в цикле перебрать все символы строки s: for char in s: … теперь задача свелась к определению наибольшей подстроки, состоящей из символов A, B или C, в символьной строке s. Проверку того, что символ – один из набора A, B, C удобно записывать с помощью условия if char in 'ABC': Полная программа на языке Python: s = open('k7.txt').read() count = 0 maxCount = 0 for char in s: if char in 'ABC': count += 1 if count>maxCount: maxCount = count else: count=0 print(maxCount) Решение (программа на языке PascalABC.NET): В начале переключим входной поток с консоли на нужный файл, а затем считаем одну строку из файла в строковую переменную s assign(input,'k7.txt'); readln(s); теперь можно в цикле перебрать все символы строки s: for i:=1 to Length(s) do … обработка символа выполняется по алгоритму, описанному выше (см. программу на Python) Проверка того, что символ – один из набора A, B, C – в PascalABC.NET записывается аналогично if s[i] in 'ABC' then а в среде FreePascal придётся использовать старинный способ: if s[i] in ['A','B','C'] then Полная программа на языке PascalABC.NET: begin var s: string; var i, count, maxCount: integer; assign(input,'k7.txt'); readln(s); count:=0; maxCount:=0; for i:=1 to Length(s) do if s[i] in 'ABC' then { if s[i] in ['A','B','C'] } begin count := count+1; if count > maxCount then maxCount := count; end else count := 0; writeln(maxCount); end. Решение (программа на языке C++): Для чтения из файла подключим заголовочный файл fstream, откроем файловый поток и считаем его в строковую переменную s #include #include … ifstream F("k7.txt"); string s; getline( F, s ); алгоритм обработки строки тот же, что и в программах на языках Python и Pascal, рассмотренных выше, однако проверка того, что символ – один из набора A, B, C записывается по-другому if( s[i]=='A' || s[i]=='B' || s[i]=='C' ) Полная программа на языке С++: using namespace std; #include #include #include int main(){ ifstream F("k7.txt"); string s; getline( F, s ); int count = 0, maxCount = 0; for( int i = 0; i < s.length(); i++ ) if( s[i] == 'A' || s[i] == 'B' || s[i] == 'C' ) { count ++; if( count > maxCount ) maxCount = count; } else count = 0; cout << maxCount; } Ещё пример задания:Р-01. В текстовом файле k7.txt находится цепочка из символов латинского алфавита A, B, C. Найдите длину самой длинной подцепочки, состоящей из символов C. Решение: сначала нужно открыть файл и прочитать все символы в символьную строку: with open("k7.txt", "r") as F: s = F.readline() теперь задача свелась к определению наибольшего количества подряд идущих букв C в символьной строке s (этот алгоритм приведён в начале файла) полная программа на языке Python: with open( "k7.txt", "r" ) as F: s = F.readline() maxLen, cLen = 0, 0 for c in s: if c == 'C': cLen += 1 if cLen > maxLen: maxLen = cLen else: cLen = 0 print( maxLen ) Решение (программа на языке Pascal): далее мы будем использовать язык PascalABC.NET, который обладает двумя важными достоинствами, упрощающими решение таких задач: позволяет легко переключать входной поток с консоли на нужный файл: assign( input, 'k7.txt' ); теперь можно писать программу так же, как и при вводе данных с клавиатуры, а она на самом деле будет читать их из указанного файла; не имеет ограничения на длину строк (переменных типа string); в устаревших версиях языка Pascal длина строки не может превышать 255 символов читаем одну строку из файла в строковую переменную s: readln(s); теперь можно в цикле перебрать все символы строки s: for i:=1 to Length(s) do обработать s[i] обработка символа выполняется по алгоритму, описанному выше (см. программу на Python) полная программа на языке Pascal: var maxLen, cLen, i: integer; s: string; begin assign(input, 'k7.txt'); readln(s); maxLen := 0; cLen := 0; for i:=1 to Length(s) do if s[i] = 'C' then begin cLen := cLen + 1; if cLen > maxLen then maxLen := cLen; end else cLen := 0; writeln(maxLen); end. Решение (программа на языке C++): в C++ удобно работать с файлами через файловые потоки; для того, чтобы использовать эту возможность, нужно подключить заголовочный файл fstream: #include для того чтобы читать всю строку целиком с помощью функции getline, нужно подключить заголовочный файл string: #include теперь можно открыть файловый поток, связать его с нужным файлом и прочитать из потока строку в переменную типа string: ifstream F("k7.txt"); string s; getline( F, s ); алгоритм обработки строки тот же, что и в программах на языках Python и Pascal, рассмотренных выше поскольку в программе используется много объектов из пространства имён std, имеет смысл подключить его в начале программы: using namespace std; полная программа на языке C++: #include #include #include using namespace std; int main() { ifstream F("k7.txt"); string s; getline( F, s ); int maxLen = 0, cLen = 0; for( int i = 0; i < s.length(); i++ ) if( s[i] == 'C' ) { cLen ++; if( cLen > maxLen ) maxLen = cLen; } else cLen = 0; cout << maxLen; } Решение методом грубой силы (Б.С. Михлин): если решить красиво не получается, можно применить метод грубой силы, использующий встроенную функцию поиска подстроки: ищём строку из одного символа C, потом – из двух символов, из трёх и т.д.; в какой-то момент поиск не даст результата, значит ответ – это длина предыдущей цепочки, которая короче текущей на единицу вот решение на Python: with open( "k7.txt", "r" ) as F: s = F.readline() cc = 'C' while cc in s: cc += 'C' print( len(cc)-1 ) решение на Паскале: var cc, s: string; begin assign(input, 'k7.txt'); readln(s); cc := 'C'; while Pos(cc, s) > 0 do cc := cc + 'C'; writeln( Length(cc)-1 ); end. решение на C++: #include #include #include using namespace std; int main() { ifstream F("k7.txt"); string s, cc; getline( F, s ); cc = 'C'; while( s.find(cc) != string::npos ) cc += 'C'; cout << cc.length()-1; } эту задачу можно решать вообще без программирования, используя функцию поиска в любом текстовом редакторе или процессоре; для ускорения можно сначала удваивать длину искомой цепочки, а после того, как поиск закончится неудачно, применять двоичный поиск в интервале конечно, нужно понимать, что эффективность (скорость работы) этого алгоритма крайне низкая в сравнении с описанным выше однопроходным поиском, но на небольших файлах и этот метод вполне может сработать. Решение в электронных таблицах (Б.С. Михлин): можно применить тот же метод грубой силы, использующий электронные таблицы. Сначала откроем файл в текстовом редакторе и скопируем все его содержимое в буфер обмена. Затем откроем новую электронную таблицу и вставим строку из буфера обмена в какую-нибудь ячейку (в примере ниже это ячейка А2). Затем в окне «Найти» вбиваем один символ «С» и нажимаем кнопку «Найти все», потом два символа «С», три и т.д., пока не появится сообщение «…не удается найти искомые данные». Значит максимальная длина подцепочки из символов «С», входящая в заданную цепочку, на единицу меньше. При большой длине максимальной подцепочки при подсчете в ней количества символов легко ошибиться. можно также использовать встроенные текстовые функции электронных таблиц: FIND (НАЙТИ) или SEARCH (ПОИСК) и REPT (ПОВТОР). Меняя в функции ПОВТОР коэффициент повторения символа "C" мы повторяем идею п. 1. Для ускорения поиска можно коэффициент повторения менять сперва с крупным шагом, а затем с более мелким. Также можно обойтись только одной ячейкой с формулой. Функции НАЙТИ и ПОИСК выводят положение начала искомой подцепочки в заданной цепочке символов или сообщение #ЗНАЧ!, если подцепочка не найдена. Если поиск надо осуществлять с начала цепочки, то третий параметр функций НАЙТИ и ПОИСК можно не указывать. Функция НАЙТИ учитывает регистр символов. Функция ПОИСК не учитывает регистр символов и в ней можно использовать подстановочные символы (* и ?). Вот решение задачи в OpenOffice Calc: 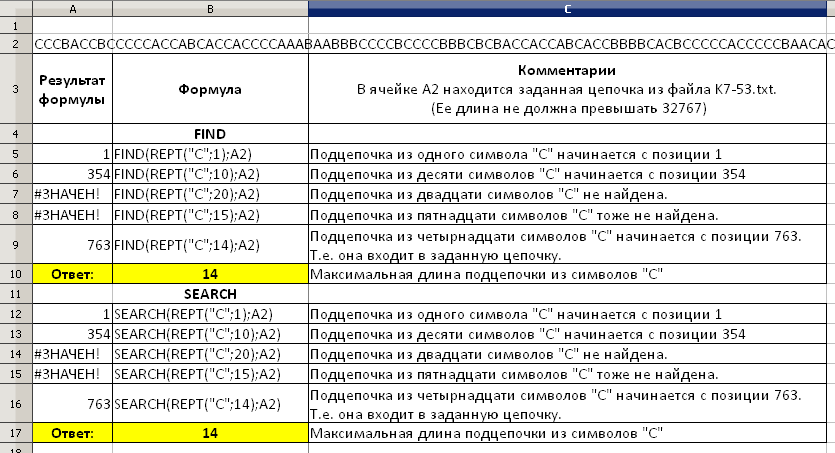 и в русской версии Excel:  |