обзор кластерного анализа. Обзор кластерного анализа. Обзор кластерного анализа
 Скачать 131.63 Kb. Скачать 131.63 Kb.
|

Обзор кластерного анализаВ нашем обсуждении простой линейной регрессии вы видели, как мы можем различать разные типы моделей в соответствии с их конкретным назначением, переменными требованиями и предположениями о данных . Эти отличительные характеристики помогут вам определить, какой тип модели может подойти для вашего конкретного анализа данных. Итак, давайте посмотрим на эти характеристики для модели кластерного анализа . Цель кластерного анализаКак уже отмечалось, все методы моделирования, такие как кластерный анализ, были разработаны для достижения определенной цели или ответа на определенный тип вопросов. Цель кластерного анализа состоит в том, чтобы разбить большую группу на более мелкие группы на основе схожих признаков . Это иногда называют данными «подмножества». В маркетинговой аналитике наиболее распространенным использованием кластерного анализа является сегментация рынка или процесс создания подгрупп в вашей клиентской базе с использованием общих черт или потребностей. Это позволяет более эффективно нацеливать рекламные кампании на каждую группу. Существует множество различных анализов, подпадающих под этот тип модели, и каждый из них имеет разные подходы к тому, как ваши данные «кластеризуются». Но все эти различные кластерные анализы имеют одну и ту же основную цель: сгруппировать ваши данные в подгруппы, которые можно оценить и сравнить. Мы сосредоточимся на типе кластерного анализа, известном как кластеризация K-средних . Это кластерный анализ, который вы, скорее всего, будете использовать в маркетинговом анализе. Кластеризация K-средних — это метод кластеризации по умолчанию в нескольких различных программах, включая Tableau, и он включает в себя вычисление определенных точек в ваших данных и минимизацию расстояния от них для создания групп. Требования к переменным для кластерного анализаКак и в случае с простой моделью линейной регрессии, кластерный анализ K-средних предназначен для работы с количественной независимой переменной и количественной зависимой переменной . Таким образом, для проведения кластерного анализа ваши данные должны включать по крайней мере одну независимую переменную и по крайней мере одну зависимую переменную, и обе они должны быть количественными переменными. Предположения о данных для кластерного анализаКак только вы определили, что кластерный анализ K-средних соответствует потребностям вашего анализа данных, исходя из цели и требований к переменным для кластерного анализа, вы должны просмотреть свои данные, чтобы убедиться, что они соответствуют предположениям , перечисленным ниже. Помните, что ваши данные должны соответствовать этим предположениям, чтобы дать вам точные результаты! Для запуска кластерного анализа ваши данные должны иметь: Минимальный размер выборки 50 точек данных на группу . Это означает, что у вас должно быть 50 образцов для каждой ожидаемой группы. Если вы думаете, что будете анализировать три группы, то это будет 50 точек данных, умноженных на три, или всего 150 точек данных. Сферичность . Второе допущение кластеризации K-средних — это сферичность. Все это означает, что ваши группы попадут примерно в округленную область, когда вы нанесете свои точки данных. Эти закругленные кластеры возникают при кластеризации K-средних, потому что эта модель определяет группу путем вычисления центральной точки данных, а затем определения местоположения других ваших данных в этой группе в соответствии с их расстоянием от этой центральной точки. Это объединяет данные примерно в пределах замкнутой кривой вокруг центральных точек, определяющих группу. Однородность дисперсии : это означает, что вариации независимых и зависимых переменных примерно одинаковы. Мы видели это же предположение для простой модели линейной регрессии. (Чтобы освежить в памяти дисперсию, вернитесь к нашему уроку «Меры дисперсии», который был ранее в этом курсе.) Равная априорная вероятность : это просто означает, что каждая группа в вашем анализе должна иметь примерно одинаковую вероятность появления в ваших данных. Если вы знаете, что в двух группах много членов, а в третьей группе только один или два члена, кластеризация K-средних все равно будет пытаться уравнять группы, беря членов из более крупных групп и искусственно передавая их в меньшие группы. Таким образом, чтобы убедиться, что ваш анализ точно группирует точки данных, вы должны иметь возможность предположить, что все группы будут иметь одинаковое количество членов. В целом характерная цель, переменные требования и предположения о данных, перечисленные выше, предлагают вам удобный контрольный список вещей, на которые следует обращать внимание при принятии решения о том, будет ли кластерный анализ K-средних хорошей моделью для вашего анализа данных.  Вы должны попытаться проверить все эти требования и предположения, прежде чем использовать эту модель кластерного анализа в своем маркетинговом анализе! Кластерный анализ в действииПосле того как вы определили, что кластерный анализ является хорошей моделью для вашего анализа, вот основные шаги для его запуска. В видеороликах этой недели мы использовали Tableau для запуска кластерного анализа и создания визуальных эффектов. Давайте резюмируем: Вы начинаете кластерный анализ K-средних, создавая точечную диаграмму для ваших независимых и зависимых переменных. Пусть независимой переменной будет ваша ось X (горизонтальная ось вдоль основания), а вашей зависимой переменной будет ваша ось Y (вертикальная ось вдоль левой стороны). В Tableau мы можем создать этот график, перетащив нашу независимую переменную на «полку столбцов» в верхней части страницы рабочего листа Tableau, которая заполнит ее по оси X. Затем мы щелкаем раскрывающийся список и выбираем «Измерение», чтобы все отдельные значения могли отображаться в виде точек данных. Затем мы перетаскиваем нашу зависимую переменную на «полку строк», которая будет заполнять ось Y. (В Tableau вам может потребоваться изменить настройки на «полке Метки» с «Автоматически» на «Круг», чтобы ваши значения отображались в виде точечной диаграммы, а не линейного графика. После того, как вы нанесли данные на график, вы можете сгруппировать эти данные в группы, которые хотите проанализировать. В Tableau мы можем сделать это, нажав на вкладку «Аналитика» и выбрав опцию «Кластер». ( Нажмите здесь, чтобы увидеть быстрое демонстрационное видео этого процесса в действии.) Вот пример визуализации для кластерного анализа, который мы провели с помощью Tableau (мы добавили овалы для четкости): 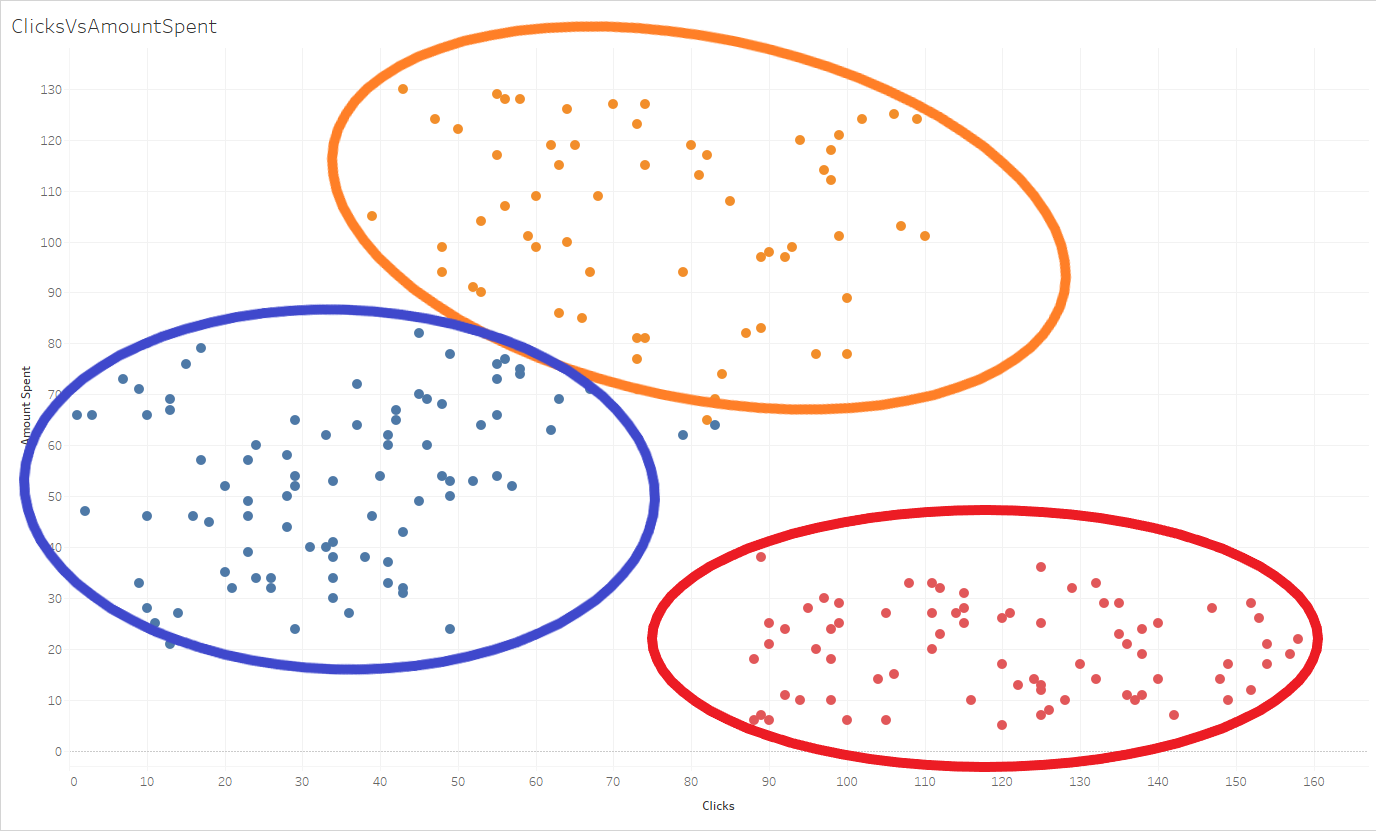 В этом примере мы анализируем данные о расходах клиентов, что позволяет нам построить график «Потраченная сумма» (зависимая переменная) и «Клики» (независимая переменная). Из этого графика рассеяния мы можем определить группы в соответствии с их расходами. Одно интересное наблюдение, которое вы можете сделать из этого анализа, заключается в том, что группа с наименьшими затратами (красный кластер) также, как правило, является нашей группой с наибольшим количеством кликов. Какие еще связи вы видите в этом примере модели кластерного анализа? |