Лекции по программированию. Основные понятия классификация программного обеспечения
 Скачать 1.57 Mb. Скачать 1.57 Mb.
|

|
1.8. СРЕДЫ И РЕАЛИЗАЦИИ ЯЗЫКОВ ПРОГРАММИРОВАНИЯ Среда программирования - это совокупность инструментов, используемых при разработке программного обеспечения. Этот набор обычно состоит из файловой системы, текстового редактора, редактора связей и компилятора. Дополнительно он может включать большое количество инструментальных комплексов с единообразным интерфейсом пользователя. Старейшей средой программирования считается UNIX - машинно-независимая операционная система с разделением времени. Она предоставляет многочисленные мощные инструментальные средства для производства ПО и эксплуатации разнообразных языков. Работа с этой средой осуществляется с помощью графического интерфейса, устанавливаемого поверх нее. Во многих случаях этим интерфейсом является CommonDesktopEnvironment (CDE). Последнюю стадию развития сред разработки ПО представляют MicrosoftVisual C++, VisualBASIC, Delphiи JavaDevelopmentKit, которые предлагают легкий способ создания графических интерфейсов для программ пользователя. Ключевой вопрос реализации языка программирования заключается в том, какое представление имеет программа во время ее выполнения на реальном компьютере, является ли этот язык машинным языком данного компьютера или нет? В зависимости от ответа на этот вопрос языки (вернее, их реализации) делятся на компилируемые и интерпретируемые. Компилируемые языки. Компилируемыми принято считать такие языки как С, C++, FORTRAN, Pascalи Ada. Это означает, что программы, написанные на этих языках, транслируются в машинный код данного компьютера перед началом выполнения. Программная интерпретация при этом ограничивается только интерпретацией набора программ поддержки выполнения, которые моделируют элементарные операции исходного языка, не имеющие близкого аналога в машинном языке. Транслятор компилируемого языка является большой и сложной программой, и при трансляции основное значение имеет создание максимально эффективных (с точки зрения их выполнения) исполняемых программ. Интерпретируемые языки. Реализуются с использованием программного интерпретатора. К таковым относятся языки LISP, ML, Perl, Postscript, Prologи Smalltalk. При такой реализации транслятор выдает не машинный код используемого компьютера, а некую промежуточную форму программы. Эта форма легче для выполнения, чем исходная программа, но все же она отличается от машинного кода. Использование необходимого для этого программного интерпретатора приводит к относительно медленному выполнению программы. Основная сложность здесь реализуется в программном обеспечении процесса интерпретации, поэтому трансляторы интерпретируемых языков обычно представляют собой довольно простые программы. Развитие Всемирной паутины WWWи появление языка Javaвнесли изменения в описанную схему. Язык Javaпохож скорее на Pascalи C++, чем на LISP, но в большинстве случаев реализуется как интерпретируемый язык. Компилятор Javaвырабатывает промежуточный набор байт-кодов для виртуальной машины Java. Передача байт-кодов на локальный компьютер (даже если он медленнее, чем web-сервер) выгоднее в отношении временных затрат, чем передача результатов выполнения программы на web-сервере. Однако web-сервер не в состоянии предугадать машинную архитектуру хост-компьютера. Поэтому браузер создает виртуальную машину Java, которая и выполняет стандартный набор байт-кодов Java. СТРУКТУРЫ УПРАВЛЕНИЯ И ПОДПРОГРАММЫ 2.1. ТЕОРИЯ ПЕРВИЧНЫХ ПРОГРАММ Теория первичных программ была предложена Маддуксом в качестве обобщения методологии структурного программирования для определения однозначной иерархической декомпозиции блок-схем. В этой теории предполагается, что графы программ могут содержать три класса узлов (рис. 2): функциональные узлы — представляют вычисления, производимые программой, и изображаются прямоугольниками с одной входящей в этот узел дугой и одной выходящей. Функциональные узлы представляют операторы присваивания, выполнение которых вызывает изменение состояния виртуальной машины; узлы принятия решения - изображаются в виде ромбов с одной входящей дутой и двумя выходящими (истина и ложь). Эти узлы представляют предикаты, и управление из узла принятия решения передается дальше либо по ветви истина, либо по ветви ложь; узел соединения — представляется в виде точки, в которой сходятся две дуги графа, чтобы сформировать одну выходную дугу. 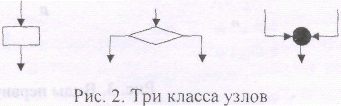 Любая блок-схема состоит только из этих трех компонентов. Правильная программа — блок-схема, являющаяся некоторой формальной моделью структуры управления, которая имеет: одну входящую дугу; одну выходящую дугу; путь от входящей дуги к любому узлу и из любого узла - к выходящей дуге. Первичная программа является правильной программой, которую нельзя разделить на более мелкие правильные программы. Исключением из этого правила является последовательность функциональных узлов, которая считается одной первичной программой.  На рис. 3 изображены все первичные программы, которые включают в себя не более четырех узлов. Первичные программы а, б, д, и представляют собой последовательности функциональных узлов. Первичная программа е — конструкция if-then, .ж— do-while, з - repeat-until, к- if-then-else, л - do-while-do. Первичные программы в, г, м-т состоят только из узлов принятия решения и соединения. В них нет функциональных узлов, поэтому они не изменяют пространство состояний виртуальной машины. Ни один из этих вариантов первичных программ не представляет эффективной структуры управления в программе. Многие из описанных выше наборов управляющих структур были включены в существующие языки программирования. Эти структуры представляют собой первичные программы с небольшим количеством узлов и просты для понимания. Перечислив все первичные программы, можно сделать очевидный вывод, что конструкция do-while-doявляется естественной структурой управления, хотя она была проигнорирована разработчиками языков. 2.2. АЛЬТЕРНАТИВЫ Операторы выбора используются для выбора одного из нескольких возможных путей, по которому должно выполняться вычисление. Обобщенный оператор выбора называется case-оператором (switch-оператор в языке С). Условный оператор является частным случаем case- или switch-оператора, в котором выражение имеет булев тип. Так как булевы типы имеют только два допустимых значения, условный оператор делает выбор между двумя возможными путями. Конструкция для двух альтернатив на Паскале имеет следующий вид: if L then begin {Действиепри L-True} end; else begin {Действие при L=False} end; здесь L-логическое выражение. Вариант конструкции для нескольких альтернатив имеет вид: Switch : = 0; L1 : = . . . L2 : = . . . L3 : = . . . if L1 then Swich : = 1; if L2 then Swich : = 2; if L3 then Swich : = 3; case Swich of 1: begin {Действиепри L1=True} end; 2 : begin {Действиепри L2=True} end; 3:begin {Действиепри L3=Тrие} end; else begin {Вывод сообщения об ошибочном кодировании модуля} end; end; {EndofCase} 2.3. ЦИКЛЫ Оператор цикла имеет одну точку входа, последовательность операторов, которые составляют цикл, и одну или несколько точек выхода. Чтобы циклы завершались, с точкой выхода бывает связано условие, которое определяет, следует сделать выход или продолжить выполнение цикла. Циклы различаются числом, типом и расположением условий выхода. Универсальные циклы в Паскале имеют следующие конструкции. Цикл while-do Цикл repeat-until {Подготовка} {Подготовка} While L do repeat begin {телоцикла} {телоцикла}until L; end; здесь L -логическое выражение, которое при значении Trueявляется условием продолжения выполнения while-doили условием окончания выполнения repeat-until. Подготовка и тело цикла являются цепочками функциональных узлов. Тело цикла выполняется столько раз, сколько и весь цикл. При равноценности, из двух конструкций выбирают ту, запись которой короче. Операторы цикла наиболее трудны: в них легко сделать ошибку, особенно на границах цикла. Очень часто количество итераций цикла известно заранее: это либо константа, известная при написании программы, либо значение, вычисляемое перед началом цикла. Цикл со счетчиком можно запрограммировать следующим образом: for <параметр_цикла> := <нач_знач> to <кон знач> do <оператор>; здесь for, to, do — зарезервированные слова; <параметр _цикла> — переменная любого перечисляемого типа. Цикл выполняется для каждого из значений от <нач_знач> и до <кон_знач>. 2.4. ОПЕРАТОРЫ ПЕРЕХОДА Оператор безусловного перехода имеет следующий вид: goto, здесь goto — зарезервированное слово: <метка> — метка. Метка - это произвольный идентификатор, позволяющий именовать некоторый оператор программы и таким образом ссылаться на него. Можно теоретически показать, что достаточно if- и while-операторов, чтобы записать любую необходимую управляющую структуру. Однако есть несколько вполне определенных ситуаций, где лучше использовать оператор goto. Первая состоит в том, что многие циклы не могут завершаться в точке входа, как этого требует цикл while. Вторая ситуация, которую легко запрограммировать с помощью goto, - выход из глубоко вложенного вычисления. Например, если глубоко внутри вызовов процедур обнаружена ошибка, что делает неверным все вычисление. В этой ситуации естественно запрограммировать выдачу сообщения об ошибке и возвратить в исходное состояние все вычисление. Однако для этого требуется сделать возврат из многих процедур, которые должны знать, что произошла ошибка. Проще и понятнее выйти в основную программу с помощью goto. В языке С нет никаких средств для обработки этой ситуации (не подходит даже gotoпо причине ограниченности рамками отдельной процедуры), поэтому для обработки серьезных ошибок нужно использовать средства операционной системы. В современных языках ObjectPascal, Ada, C++ и Eiffelесть специальные языковые конструкции, так называемые исключения, которые непосредственно решают и эту проблему. 2.5. ПОДПРОГРАММЫ. ПРОЦЕДУРЫ И ФУНКЦИИ Часто некоторую последовательность инструкций требуется повторить в нескольких местах программы. Чтобы программисту не приходилось тратить время и усилия на копирование этих инструкций, в большинстве языков программирования предусматриваются средства для организации подпрограмм. Таким образом, программист получает возможность присвоить последовательности инструкций произвольное имя и использовать это имя в качестве сокращенной записи в тех местах, где встречается соответствующая последовательность инструкций. Подпрограмма -- некоторая последовательность инструкций, которая может повторяться в нескольких местах программы. Процедурой называется особым образом оформленный фрагмент программы, имеющий собственное имя (идентификатор), который выполняет некоторую четко определенную операцию над данными, определяемыми параметрами. Упоминание имени процедуры в тексте программы приводит к ее активизации и называется вызовом процедуры. Вызов может быть осуществлен из любой точки программы. При каждом таком вызове могут пересылаться различные параметры. Сразу после активизации процедуры начинают выполняться входящие в нее операторы, после выполнения последнего из них управление возвращается обратно в основную программу, и выполняются операторы, стоящие непосредственно за оператором вызова процедуры. Описание процедуры состоит из заголовка и тела. Заголовок процедуры имеет вид: procedure <имя> [ (<сп.ф.п.>) ] ; здесь <имя> имя процедуры (правильный идентификатор); <сп. ф. п. > - список формальных параметров. Список формальных параметров необязателен и может отсутствовать. Если же он есть, то в нем должны быть перечислены имена формальных параметров и их типы, например procedure MyProc (a: Real; b: Integer; с: Char); Функция отличается от процедуры тем, что результат ее работы возвращается в виде значения этой функции, и, следовательно, идентификатор функции может использоваться наряду с другими операндами в выражениях. Описание функции состоит из заголовка и тела. Заголовок функции имеет следующий вид: function <имя> [(<сп.ф.п.>)]: <тип>; здесь <тип> — тип возвращаемого функцией результата. Заголовок функции может иметь следующий вид: function MyFunc (a, b: Real): Real; Операторы тела подпрограммы рассматривают список формальных параметров как своеобразное расширение раздела описаний: все переменные из этого списка могут использоваться в любых выражениях внутри подпрограммы. Так осуществляется настройка алгоритма подпрограммы на конкретную задачу. Работа с процедурами и функциями отличаются в следующем:
2.6. ПЕРЕДАЧА ПАРАМЕТРОВ Для обмена информацией между основной программой и процедурой используется один или несколько параметров вызова. Они перечисляются за именем процедуры и вместе с ним образуют оператор ее вызова. Механизм замены формальных параметров на фактические позволяет нужным образом настроить алгоритм, реализованный в подпрограмме. Компилятор обычно следит за тем, чтобы количество и тип формальных параметров строго соответствовали количеству и типам фактических параметров в момент обращения к подпрограмме. Смысл используемых фактических параметров зависит от того, в каком порядке они перечислены при вызове подпрограммы. Поэтому программист должен сам следить за правильным порядком перечисления фактических параметров при обращении к подпрограмме. Формальные параметры подпрограммы могут быть трех видов: параметры-значения; параметры-переменные; параметры-константы. Например, procedure MyProc (A: Real; var В: Real; const С: String); здесь А - параметр-значение, в - параметр-переменная, С - параметр-константа. Способ определения формального параметра очень важен для вызывающей программы. Если формальный параметр объявлен как параметр-значение или параметр-константа, то при вызове ему может соответствовать произвольное выражение. Если формальный параметр объявлен как параметр-переменная, то при вызове подпрограммы ему должен соответствовать фактический параметр в виде переменной нужного типа. Чтобы понять, в каких случаях использовать тот или иной тип параметров, нужно знать, как осуществляется замена формальных параметров на фактические в момент обращения к подпрограмме. Если параметр определен как параметр-значение, то перед вызовом подпрограммы это значение вычисляется, полученный результат копируется во временную память и передается подпрограмме. Любые возможные изменения в подпрограмме параметра-значения никак не воспринимаются вызывающей программой, так как в этом случае изменяется копия фактического параметра. Если параметр определен как параметр-переменная, то при вызове подпрограммы передается сама переменная, а не ее копия (фактически в этом случае подпрограмме передается адрес переменной). Изменение параметра-переменной приводит к изменению самого фактического параметра в вызывающей программе. В случае параметра-константы в подпрограмму также передается адрес области памяти, в которой располагается переменная или вычисленное значение. Однако компилятор блокирует любые присваивания параметру-константе нового значения в теле подпрограммы. Параметры-переменные используются как средство связи алгоритма, реализованного в подпрограмме, с внешним миром. С помощью этих параметров подпрограмма может передавать результаты своей работы вызывающей программе. Однако описание всех формальных параметров как параметров-переменных нежелательно по двум причинам. Во-первых, это исключает возможность вызова подпрограммы с фактическими параметрами в виде выражений, что делает программу менее компактной. Во-вторых, в подпрограмме возможно случайное использование формального параметра, например, для временного хранения промежуточного результата, т.е. всегда существует опасность непреднамеренно испортить фактическую переменную. По той же причине не рекомендуется использовать параметры-переменные в заголовке функции. Если результатом работы функции не может быть единственное значение, то логичнее использовать процедуру или нужным образом декомпозировать алгоритм на несколько подпрограмм. Существует еще одно обстоятельство, которое следует учитывать при выборе вида формальных параметров. Как уже говорилось, при объявлении параметра-значения осуществляется копирование фактического параметра во временную память. Если этим параметром будет массив большой размерности, то существенные затраты времени и памяти на копирование при многократных обращениях к подпрограмме можно минимизировать, объявив этот параметр параметром-константой. Параметр-константа не копируется во временную область памяти, что сокращает затраты времени на вызов подпрограммы, однако любые его изменения в теле подпрограммы невозможны - за этим строго следит компилятор. Нетипизированные параметры. Одним из свойств языка ObjectPascalявляется возможность использования нетипизированных параметров. Параметр считается нетипизированным, если тип формального параметра-переменной в заголовке подпрограммы не указан, при этом соответствующий ему фактический параметр может быть переменной любого типа. Нетипизированными могут быть только параметры-переменные: procedure MyProc(var aParametr); Нетипизированные параметры обычно используются в случае, когда тип данных несуществен. Такие ситуации чаще всего возникают при разного рода копированиях одной области памяти в другую, например, с помощью процедур BlockRead, BlockWrite, Move-Memoryи т. п. Процедурные типы. Основное назначение процедурных типов — дать программисту гибкие средства передачи функций и процедур в качестве фактических параметров обращения к другим процедурам и функциям. Для объявления процедурного типа используется заголовок процедуры (функции), в котором опускается ее имя, например: type Prod = procedure (a, b, с: Real; var d: Real); РгосЗ == procedure; Fund = function: String; Func2 = function (var s: String): Real; В программе могут быть объявлены переменные процедурных типов, например: var p1 : Proc1; fl, f2: Func2; ар: array [1. . N] of Prod; Переменным процедурных типов допускается присваивать в качестве значений имена соответствующих подпрограмм. После такого присваивания имя переменной становится синонимом имени подпрограммы. 2.7. РЕКУРСИЯ Содержание и мощность рекурсивного определения, а также его главное назначение, состоит в том, что оно позволяет с помощью конечного выражения определить бесконечное множество объектов. Аналогично, с помощью конечного рекурсивного алгоритма можно определить бесконечное вычисление, причем алгоритм не будет содержать повторений фрагментов текста. Рекурсия - это такой способ организации вычислительного процесса, при котором подпрограмма в ходе выполнения составляющих ее операторов обращается сама к себе. Программы, в которых используются рекурсивные процедуры, отличаются простотой, наглядностью и компактностью текста. Такие качества рекурсивных алгоритмов вытекают из того, что рекурсивная процедура указывает что нужно делать, а нерекурсивная больше акцентирует внимание на том, как нужно делать. Однако за эту простоту приходится расплачиваться неэкономным использованием оперативной памяти, так как выполнение рекурсивных процедур требует значительно большего размера оперативной памяти во время выполнения, чем нерекурсивных. При каждом рекурсивном вызове для локальных переменных, а также для параметров процедуры, которые передаются по значению, выделяются новые ячейки памяти. Таким образом, какой-либо локальной переменной А на разных уровнях рекурсии будут соответствовать различные ячейки памяти, которые могут иметь разные значения. Глубиной рекурсии называется максимальное число рекурсивных вызовов процедуры без возвратов, которое происходит во время выполнения программы. В общем случае любая рекурсивная процедура Recвключает в себя некоторое множество операторов Sи один или несколько операторов рекурсивного вызова. Безусловные рекурсивные процедуры приводят к бесконечным процессам, и на эту проблему нужно обратить особое внимание, так как практическое использование процедур с бесконечным самовызовом невозможно. Следовательно, главное требование к рекурсивным процедурам заключается в том, что вызов рекурсивной процедуры должен выполняться по условию, которое на каком-то уровне рекурсии станет ложным. Если условие истинно, то рекурсивный спуск продолжается. Когда оно становится ложным, то спуск заканчивается и начинается поочередный рекурсивный возврат из всех вызванных на данный момент копий рекурсивной процедуры. Структура рекурсивной процедуры может принимать три разных формы: 1) форма с выполнением действий до рекурсивного вызова (на рекурсивном спуске); procedure Rec; begin S; if условие then Rec; end; 2) форма с выполнением действий после рекурсивного вызова (на рекурсивном возврате); procedure Rec; begin if условие then Rec; S; end; 3) форма с выполнением действий как до, так и после рекурсивного вызова (с выполнением действий как на рекурсивном спуске, так и на рекурсивном возврате). procedure Rec; begin S1; if условие then Rec; S2 ; end; Все формы рекурсивных процедур находят применение на практике. Многие задачи, в том числе вычисление факториала, безразличны к тому, какая используется форма рекурсивной процедуры. Однако есть классы задач, при решении которых программисту требуется сознательно управлять ходом работы рекурсивных процедур и функций. Такими, в частности, являются задачи, использующие списковые и древовидные структуры данных. ТЕХНОЛОГИЯ СТРУКТУРНОГО ПРОГРАММИРОВАНИЯ 3.1. ПОНЯТИЕ СТРУКТУРНОГО ПРОГРАММИРОВАНИЯ Исторически сложилось так, что императивные языки в настоящее время доминируют в программировании. Однако исследования, проведенные в 70-80-х годах XX века, показали, что аппликативная методика обеспечивает более эффективные способы верификации программ и доказательство их корректности. Это видно из блок-схем, представленных на рис. 4. На рис. 4, а изображена блок-схема, типичная для программ 60-х годов XX века. В ней нет никакой явной структуры. Такие программы называют про-граммами-спагетти. Из-за большого числа нерациональных передач управления назад и вперед трудно понять, каково состояние программы в каждый момент времени в процессе ее выполнения. На рис. 4, б приведена более структурированная конструкция. Каждый сегмент данной блок-схемы можно заключить в пунктирный прямоугольник. Каждый из таких прямоугольников на этой схеме будет иметь одну точку входа и одну точку выхода. Эту программу можно рассматривать как композицию четырех функций-подпрограмм, и поведение программы можно определить как функцию, которая получает данное состояние на входе выделенного пунктиром прямоугольника и преобразует его в результирующее состояние на выходе из него. Писать сложные программы в тысячи и десятки тысяч строк без расчленения на самостоятельные фрагменты, т. е. без структурирования, просто невозможно. Структурное программирование - подход, при котором для передачи управления в программе используются только три конструкции, допускающих последовательную, условную и итеративную передачи управления. При этом безусловная передача управления например, оператором goto запрещается.  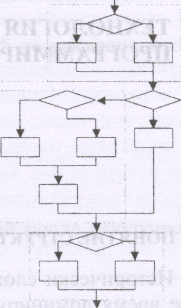 Рис. 4. Аппликативные методы в императивных языках В результате каждая сложная команда в программе, являющаяся комбинацией последовательных, условных и циклических операторов, имеет только одну точку входа и одну точку выхода, что дает возможность разбиения программы на относительно самостоятельные фрагменты. Структурное программирование является результатом применения аппликативных методов к императивным программам. Для этого используются процедурно-ориентированные языки, в которых имеется возможность описания программы как совокупности процедур. Процедуры могут вызывать друг друга, и каждая из них может быть вызвана основной программой, которую также можно рассматривать как процедуру. Структурный подход к программированию представляет собой методологию создания программ. Его внедрение обеспечивает: повышение производительности труда программистов при написании и контроле программ; получение программ, которые более пригодны для сопровождения, так как состоят из отдельных модулей; создание программ коллективом разработчиков; окончание создания программ в заданный срок. В структурированных программах обычно легко прослеживается основной алгоритм, они удобнее в отладке и менее чувствительны к ошибкам программирования. Эти свойства являются следствием важной особенности подпрограмм, каждая из которых представляет собой во многом самостоятельный фрагмент программы, связанный с основной программой лишь с помощью нескольких параметров. Такая самостоятельность подпрограмм позволяет локализовать в них все детали программной реализации того или иного алгоритмического действия, и поэтому изменение этих деталей, например в процессе отладки, обычно не приводит к изменениям основной программы. 3.2. ПРИНЦИП УТАИВАНИЯ ИНФОРМАЦИИ Концепция структурного программирования предполагает разбиение программы на отдельные компоненты согласно принципу утаивания информации. Принцип утаивания информации заключается в том, что идентификаторы локальных объектов (имена констант, типов, переменных, процедур, функций, меток, и полей в записях переменных), то есть тех, которые используются только внутри заданной последовательности инструкций, не должны иметь смысла за пределами этих инструкций. Процедуры и функции выступают как естественные текстовые единицы, с помощью которых ограничивается область существования локальных идентификаторов. Идентификатором называется строка символов, используемая для идентификации или именованная (последовательность букв, цифр и знаков подчеркивания, которая начинается с буквы или символа подчеркивания и не содержит пробелов). Областью видимости (действия) идентификатора называется часть программы, где он может быть использован. Область видимости идентификаторов определяется местом их объявления. Если идентификаторы допускается использовать только в рамках одной процедуры или функции, то такие идентификаторы называются локальными. Если действие идентификаторов распространяется на несколько вложенных (не менее одной) процедур и/или функций, то такие идентификаторы называются глобальными. Правила определения области видимости для идентификаторов состоят в следующем: 1) действуют все идентификаторы, определенные внутри процедуры/функции;
3.3. МЕТОДЫ СТРУКТУРНОГО ПРОГРАММИРОВАНИЯ При проектировании любого изделия, в том числе и алгоритма, на ранних стадиях основное внимание обращается на самые главные проблемы, и искусственно упускаются из виду многие частные детали. Поэтому наиболее общая тактика программирования состоит в разложении процесса на отдельные действия. На каждом таком шаге декомпозиции нужно удостовериться, что: решения частных задач приводят к решению общей задачи; данная последовательность отдельных действий наиболее рациональна; осуществленная декомпозиция позволяет получить инструкции, по своему смыслу наиболее близкие к языку, на котором впоследствии будет написана программа. Нисходящий подход к разработке программных систем. В соответствии с этим методом создание программы начинается сверху, т.е. с разработки самого главного, генерального алгоритма. Так как на верхнем уровне обычно еще не ясны детали реализации той или иной части программы, то эти части следует заменить временными заглушками . Прогон незаконченной программы (перед заменой заглушек реально работающими процедурами) дает определенную уверенность перед разработкой и реализацией алгоритмов нижнего уровня. Если реализуемый в заглушке алгоритм достаточно сложен, его вновь структурируют, выделяя главный алгоритм и применяя новые заглушки и т.д. (Заглушка - заменяющая компонента, которая временно используется в программе с тем, чтобы можно было продолжать ее разработку, т. е. компилирование или тестирование, до того времени, когда эта компонента будет сделана в надлежащем виде.). Процесс продолжается вниз до тех пор, пока не будет создан полностью работоспособный вариант программы. На практике «чистую» нисходящую разработку осуществить невозможно. На одной из более поздних стадий часто обнаруживается, что некоторый выбор, сделанный ранее, был неадекватным и это приводит к необходимости итеративной разработки. Восходящий подход к разработке программ. В этом случае осуществляется последовательное построение программы из уже имеющихся элементов, начиная с примитивов, предоставляемых выбранным языком программирования. Этот процесс заканчивается получением требуемой готовой программы. На каждом этапе из имеющихся элементов строятся более мощные элементы. Эти элементы будут использоваться на следующем этапе для построения еще более мощных элементов, и так далее до тех пор, пока не будут получены элементы, из которых можно непосредственно составить требуемую программу. На практике восходящая разработка в чистом виде также как и нисходящая невозможна. Построение каждого нового элемента должно сопровождаться просмотром вперед с целью проверки, удовлетворяет ли он требованиям к разрабатываемой программе; но даже и при таком подходе на более позднем этапе часто обнаруживается, что использованная ранее последовательность построения была выбрана неправильно и требуется новая итерация. При конструировании новых алгоритмов обычно доминирует нисходящий метод. При адаптации программ к несколько измененным требованиям предпочтение зачастую отдается восходящему методу. Оба этих метода позволяют разрабатывать структурированные программы. 3.4. СТРУКТУРНАЯ СХЕМА ПРОГРАММЫ И СРЕДСТВА ДЛЯ ЕЕ ИЗМЕНЕНИЯ  В понятие структуры программы (programstructure) включается состав и описание связей всех модулей, которые реализуют самостоятельные функции программы и описание носителей вводимых и выводимых данных, а также данных, участвующих в обмене между отдельными подпрограммами. Для разработки больших и сложных программ программисту необходимо овладеть специальными приемами получения рациональной структуры программы, которая обеспечивает почти двукратное сокращение объема программирования и многократное сокращение Подчиненность модулей программы отражается в схеме иерархии. Однако последняя не отражает порядок их вызова или функционирование программы. Схема иерархии может иметь вид, показанный на рис. 5. Она, обычно, дополняется расшифровкой функций, выполняемой модулями. Перед составлением схемы иерархии целесообразно составить внешние спецификации программы и составить функциональные описания программы вместе с описанием переменных-носителей данных. Особое внимание следует уделять иерархии типов структурированных данных и их комментированию. Расчленение программы на подпрограммы производится по принципу от общего к частному, более детальному. Процесс составления функционального описания и составления схемы иерархии является итерационным, а выбор наилучшего варианта является многокритериальным. Расчленение должно обеспечивать удобный порядок ввода частей в эксплуатацию. Схеме иерархии можно придать любой топологический рисунок. Фрагменты с вертикальными вызовами могут быть преобразованы в вызовы одного уровня посредством введения дополнительного модуля, который может не выполнять никаких полезных функций с точки зрения алгоритма программы. Функция нового модуля может состоять лишь в мониторинге, то есть вызове других модулей в определенном порядке. Фрагменты с горизонтальными вызовами на одном уровне могут быть преобразованы в вертикальные вызовы модулей разных уровней посредством введения дополнительных переменных, которые не могли быть получены декомпозицией функционального описания на подфункции. Эти дополнительные переменные обычно имеют тип целый или логический и называются флагами, семафорами, ключами событий. Их смысл обычно характеризуется фразой: в зависимости от следующей предыстории действий, выполнить такие-то действия. В процессе проектирования нужно сделать несколько проектных итераций, каждый раз генерируя новую схему иерархии, и сравнить эти иерархии по данным критериям для отбора лучшего варианта. Ключ - значение переменной, используемое для подтверждения полномочий на доступ к некоторой информации или подпрограмме. Флаг — переменная, значение которой свидетельствует о том, что некоторый аппаратный или программный компонент находится в определенном состоянии или что для него выполняется определенное условие. Флаг используется для реализации условного ветвления и прочих процессов принятия решений. Семафор - тип данных специального назначения, который является средством управления доступом к критическому ресурсу со стороны совместно идущих последовательных процессов. Над семафором можно производить только две операции (не считая создания и аннулирования): операцию ожидания (занятия) и операцию сигнализации (освобождения). Семафор принимает целое значение, которое не может быть отрицательным. Операция ожидания уменьшает значение семафора на единицу, когда это можно сделать, не получая при этом отрицательного значения, и это означает, что свободный ресурс используется. Операция сигнализации увеличивает значение семафора на единицу, что означает освобождение ресурса. Критический ресурс - ресурс, который в каждый момент времени используется не более чем одним процессом. Когда требуется, чтобы несколько асинхронных процессов координировали свой доступ к критическому ресурсу, используется управляемый доступ через семафор. 3.5. КРИТЕРИИ ОЦЕНКИ КАЧЕСТВА СТРУКТУРНОЙ СХЕМЫ ПРОГРАММЫ Первый вариант структурной схемы, полученный путем простого членения функций программы на подфункции с указанием переменных, необходимых для размещения данных, чаще всего не является оптимальным и требуются проектные итерации для улучшения топологии схемы. Эти действия обычно выполняются методом «проб и ошибок». Каждый новый вариант сравнивается с предшествующим по описанным ниже критериям:
Генерация вариантов прекращается при невозможности дальнейших улучшений. Рациональная структура программы обеспечивает сокращение общего объема текстов в 2-3 раза, что соответственно удешевляет создание программы и ее тестирование, на которое обычно приходится не менее 60% от общих затрат. При этом облегчается и снижается стоимость сопровождения программы. 3.6. МОДУЛЬНОЕ ПРОГРАММИРОВАНИЕ Реализация принципа структурного программирования осуществляется с использованием макрокоманд и механизмов вызова подпрограмм. Эти же механизмы подходят и для реализации модульного программирования, которое можно рассматривать как часть структурного подхода. Необходимо различать использование слова модуль, когда имеется в виду единица дробления большой программы на отдельные блоки (которые могут быть реализованы в виде процедур и функций) и когда имеется ввиду синтаксическая конструкция языков программирования (unitв ObjectPascal). Модульное программирование — это организация программы как совокупности независимых блоков, называемых модулями, структура и поведение которых подчиняются определенным правилам. Концепцию модульного программирования можно сформулировать в виде нескольких понятий и положений:
Большое значение в концепции модульного программирования придается организации управляющих и информационных связей между модулями программы, совместно решающими одну или несколько больших задач. При работе с модулями нужно помнить их основное отличие от процедур и функций. Традиционные правила сферы действия глобальных и локальных переменных для модулей не работают. Эта языковая конструкция разработана так, чтобы исключить влияние глобальных переменных, объявленных в главной программе, на внутренние описания модуля. Поэтому, если возникает необходимость ввести доступные для всех блоков программы глобальные описания то следует создать модуль глобальных объявлений и включить его в список импорта всех модулей, где нужны его описания. 3.7. СТРУКТУРА МОДУЛЯ В OBJECTPASCAL ObjectPascalимеет различные средства для структурирования программ. На нижнем уровне деления (для элементарных подзадач) чаще всего используются процедуры и функции, а на верхнем уровне (для больших задач) используются модули. В среде Delphiкаждой форме обязательно соответствует свой модуль, что позволяет локализовать все свойства окна в отдельной программной единице. Кроме этого, невизуальные алгоритмические действия также оформляются в виде отдельных модулей. Первая строка модуля начинается с ключевого слова: unit <идентификатор_модуля>; Для правильной работы среды программирования это имя должно совпадать с именем дискового файла, в который помещается исходный текст модуля. Далее следует {Интерфейсный раздел} interface где описывается взаимодействие данного модуля с другими пользовательскими и стандартными модулями, а также с главной программой. Здесь содержатся объявления всех глобальных объектов модуля (типов, констант, переменных и подпрограмм), которые должны стать доступными основной программе и/или другим модулям. При объявлении глобальных подпрограмм в интерфейсной части указывается только их заголовок. Связь модуля с другими модулями устанавливается специальным предложением: {Список импорта интерфейсного раздела} uses <список_модулей> В этом списке через запятые перечисляются идентификаторы модулей, информация интерфейсных частей которых должна быть доступна в данном модуле. {Список экспорта интерфейсного раздела} const type var procedure function Список экспорта состоит из подразделов описания констант, типов, переменных, заголовков процедур и функций, которые определены в данном модуле, но использовать которые разрешено во всех других модулях и программах, включающих имя данного модуля в своей строке uses. Для процедур и функций здесь описываются только заголовки, но с обязательным полным описанием формальных параметров. {Раздел реализации) implementation В этом разделе указывается реализационная (личная) часть описаний данного модуля, которая недоступна для других модулей и программ. {Список импорта раздела реализации) uses В этом списке через запятые перечисляются идентификаторы модулей, информация интерфейсных частей которых должна быть доступна в данном модуле. Здесь целесообразно описывать идентификаторы всех необходимых модулей, информация из которых не используется в описаниях раздела interface данного модуля. {Подразделы внутренних для модуля описаний} label const type var procedure function В этих подразделах описываются метки, константы, типы, переменные, процедуры и функции, которые описывают алгоритмические действия, выполняемые данным модулем, и которые являются «личной собственностью» исключительно только данного модуля. Эти описания недоступны ни одному другому модулю. Исполняемая часть содержит описания подпрограмм, объявленных в интерфейсной части. Описанию подпрограммы должен предшествовать заголовок, в котором можно опускать список формальных параметров и тип результата для функции. Если заголовки указаны с параметрами, то их список должен быть идентичен такому же списку для соответствующей процедуры или функции в разделе interface. {Раздел инициализации} initialization В этом разделе между ключевыми словами initialization и finalization располагаются операторы начальных установок, необходимых для запуска корректной работы модуля. Эти операторы исполняются до передачи управления основной программе и обычно используются для подготовки ее работы. Операторы разделов инициализации модулей, используемых в программе, выполняются при начальном запуске программы в том же порядке, в каком идентификаторы модулей описаны в предложениях uses файла проекта. Если операторы инициализации не требуются, то зарезервированное слово initialization может быть опущено. {Раздел завершения) finalization |