Отчет по практике. Отчёт по практике. Отчет по учебной практике Ст гр. П911 Орлов Г. Проверила Руководитель практики Таренко Л. Б
 Скачать 368.51 Kb. Скачать 368.51 Kb.
|

|
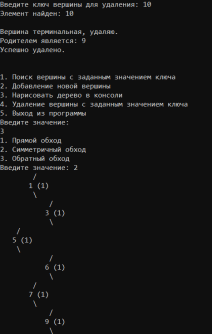
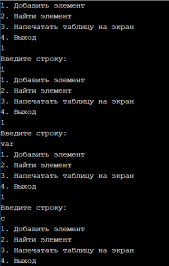
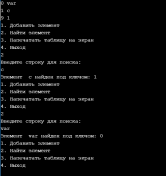
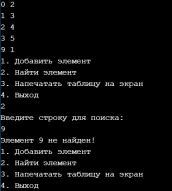
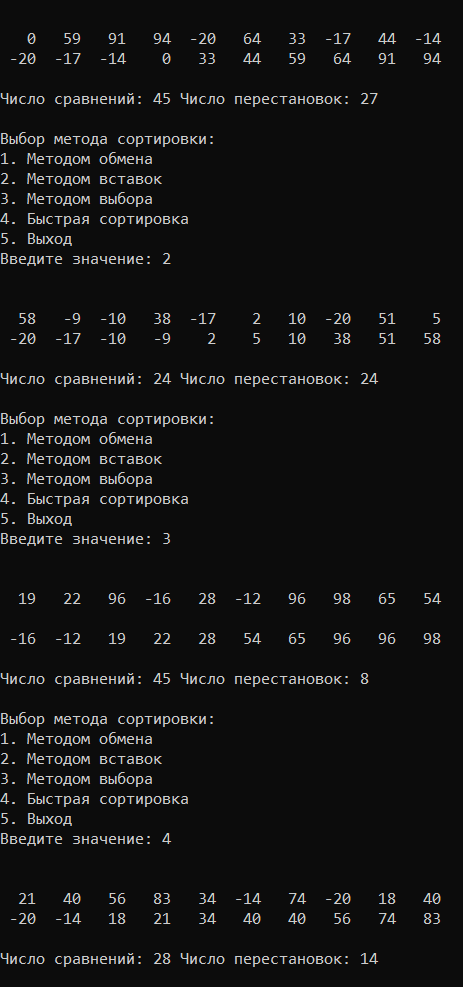
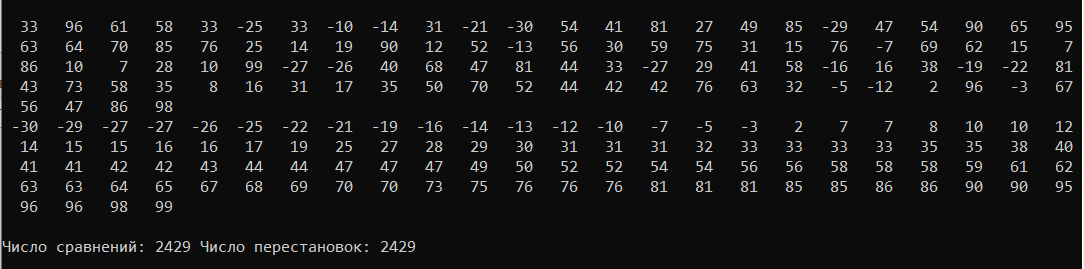
УВO “Университет управления “ТИСБИ” Кафедра информационных технологий Отчет по учебной практике Выполнил: Ст.гр. П-911 Орлов Г. Проверила Руководитель практики: Таренко Л.Б. Содержание Введение 3 Необходимо разработать программное приложение по обработке больших наборов данных с использованием инструментальных средств и компьютерных технологий: 3 Для реализации буду использовать язык разработки Pascal и бесплатную среду для разработки Lazarus, а также язык Java и среду разработки IntelliJ IDEA для реализации хеш-таблиц. 3 Тема.1 – Построение и обработка двоичных деревьев поиска 4 1.1 Постановка задачи: 4 1.2 Эффективный способ решения: 4 1.3 Программный код 6 1.4 Результаты тестирования 17 Рис.3 – Пример работы поиска 18 Рис.4 – Пример удаления не терминальной вершины (ключ = 2) 18 Рис.5 – Пример удаления терминальной вершины (ключ = 10) 19 Тема 2. Поиск в массиве данных при помощи Хэш-таблиц 20 2.1 Постановка задачи 20 2.2 Эффективный способ решения: 20 2.3 Блок схема 21 3.1 Постановка задачи: 29 3.2Эффективный способ решения 29 3.2.1Пузырьковая сортировка 29 3.2.2Сортировка вставками 29 3.2.3Сортировка выбором 29 3.2.4Быстрая сортировка 30 3.3Программная реализация 31 3.4Результаты тестирования 38 Выводы 41 Список литературы 42 ВведениеНеобходимо разработать программное приложение по обработке больших наборов данных с использованием инструментальных средств и компьютерных технологий:Для реализации буду использовать язык разработки Pascal и бесплатную среду для разработки Lazarus, а также язык Java и среду разработки IntelliJ IDEA для реализации хеш-таблиц.IntelliJ IDEA — интегрированная среда разработки программного обеспечения для многих языков программирования, в частности Java, JavaScript, Python, разработанная компанией JetBrains. Lazarus — открытая среда разработки программного обеспечения на языке Object Pascal для компилятора Free Pascal. Основная цель — предоставление кроссплатформенных и свободных средств разработки в Delphi-подобном окружении (по аналогии с Harbour для Clipper). Тема.1 – Построение и обработка двоичных деревьев поиска1.1 Постановка задачи:Необходимо разработать программу, которая будет иметь структуру двоичного дерева поиска и добавить в программу возможность построения деревьев с различными значениями. Добавить программе возможность: добавления собственных терминальных узлов, удаления терминальных и не терминальных узлов, поиск заданных ключей в двоичном дереве, а также добавить функцию вывода двоичного дерева в консоль с помощью трёх обходов (прямой, симметричный, обратный). 1.2 Эффективный способ решения:Чтобы реализовать двоичное дерево я буду использовать список с двумя указателями (левого/правого потомка), так же необходимо будет реализовать функцию поиска элемента в двоичном дереве, процедуру добавления/удаления элемента, так же реализовать три различных обхода и вывода двоичного дерева на экран с помощью этих обходов. После реализации этих функций, нужно так же добавить меню для пользователя. Добавление новой вершины. При добавлении первым шагом является поиск в дереве места для размещения новой вершины. Это место всегда находится однозначно и зависит от текущего состояния дерева и значения добавляемого ключа. Поиск должен определить адрес вершины, к которой должна быть присоединена новая вершина. Определить родительскую вершину можно двумя способами: циклический поиск и рекурсивный поиск; Воспользуемся вторым. Этот поиск позволяет определить родителя автоматически, поэтому удобно поиск совместить с добавлением в одной процедуре. Алгоритм: Если находим место новому элементу. Создаём узел и записываем ключ. Иначе рекурсивно уходим влево. Иначе рекурсивно уходим вправо. Иначе обработка неуникального ключа (в данной задаче увеличение счетчика появлений данного ключа) Вывод дерева в консоль в обратном порядке. Правило обратного обхода: Обработать левого потомка Обработать правого потомка Обработать корневую вершину Вывод дерева в консоль в обратном порядке. Используем правило симметричного обхода Обработать левого потомка левого поддерева Перейти к корневой вершине и обработать её Перейти к правому поддереву и обработать его 1.3 Программныйкодprogram project1; type pStree = ^TStree; TStree = record //Инициализация структуры с необходимыми данными Data, kol: integer; left: pStree; right: pStree; end; var //Объявление переменных pKoren, pResult, pRoditel, pTemp: pStree; menu: byte; sData, NewData, kol_i: integer; function Search(aData: integer): pStree; //Функция поиска begin if (pKoren = nil) then //Если указатель на корень равен налу то значит дерево пустое WriteLn('Поиск не возможен, дерево пустое.') else begin pTemp := pKoren; //записываем корень во временную структуру Result := nil; while (pTemp <> nil) do //Пока не дойдём до конца списка begin if (aData = pTemp^.Data) then //Сравниваем значения ключей begin WriteLn('Элемент найден: ', pTemp^.Data); //Если они равны то выводим и выходим Result := pTemp; break; end else if (aData < pTemp^.Data) then //Если искомый ключ меньше ключа в вершине переходим к левому потомку begin pRoditel := pTemp; pTemp := pTemp^.left; end else begin //Если искомый ключ больше ключа в вершине переходим к правому потомку pRoditel := pTemp; pTemp := pTemp^.right; end; end; end; end; procedure AddNode(var pTemp: pStree; aData: integer); //Добавление терминального узла begin if (pTemp = nil) then //Если узел пуст begin New(pTemp); //выделяем память и записываем данные о левом и правом узле pTemp^.Data := aData; pTemp^.left := nil; pTemp^.right := nil; pTemp^.kol := 1; kol_i := pTemp^.kol; end else if (aData < pTemp^.Data) then //Если узел не пустой и значение добавляемого ключа меньше значения в вершине, то рекурсивно переходим к левому потомку и начинаем его обработку AddNode(pTemp^.left, aData) else if (aData > pTemp^.Data) then // Если значение больше чем значение ключа в вершине рекурсивно переходим к правому потомку AddNode(pTemp^.right, aData) else begin //добавление неуникального ключа WriteLn('Такой ключ уже существует! Добавляю неуникальный ключ.'); New(pTemp); pTemp^.Data := aData; pTemp^.left := nil; pTemp^.right := nil; pTemp^.kol := kol_i + 1; kol_i := pTemp^.kol; end; end; procedure PreOrder(pTemp:pStree; tabs:integer); //Прямой метод обхода var i:integer; begin if pTemp <> nil then //Если корень не пустой begin for i:=0 to tabs do Write(' '); //Выводим необходимое кол-во пробелов WriteLn(' ',pTemp^.Data, ' (',pTemp^.kol,') '); // выводим ключ вершины PreOrder(pTemp^.left, tabs + 4); // переходим к левому потомку PreOrder(pTemp^.right, tabs + 4); //переходим к правому потомку end; end; procedure PostOrder(pTemp:pStree; tabs:integer); // обратный обход var i:integer; begin if pTemp <> nil then //Если вершина существует begin PostOrder(pTemp^.left, tabs + 4); //переходим к левому потомку PostOrder(pTemp^.right, tabs + 4); //переходим к правому потомку for i:=0 to tabs do Write(' '); //Выводим необходимое кол-во пробелов WriteLn(' ',pTemp^.Data, ' (',pTemp^.kol,') '); //выводим информацию об узле end; end; procedure StandartOrder(pTemp: pStree; tabs: integer); //Симетричный обход var i: integer; begin if (pTemp <> nil) then //Если вершина не пустая with pTemp^ do //перебираем указатели begin StandartOrder(pTemp^.left, tabs + 4); //переходим к левому потомку for i := 0 to tabs do //выводим необходимое кол-во пробелов Write(' '); WriteLn(' /'); for i := 0 to tabs do Write(' '); WriteLn(' ', pTemp^.Data, ' (', pTemp^.kol, ')'); //Выводим ключ вершины for i := 0 to tabs do Write(' '); WriteLn(' \'); StandartOrder(pTemp^.right, tabs + 4); //Переходим к правому потомку end; end; procedure Print; //Меню вывода var printType:byte; begin WriteLn('1. Прямой обход'); WriteLn('2. Симметричный обход'); WriteLn('3. Обратный обход'); Write('Введите значение: '); ReadLn(printType); case printType of 1: PreOrder(pKoren, 0); 2: StandartOrder(pKoren, 0); 3: PostOrder(pKoren, 0); end; end; procedure Pop(sData: integer); // Удаление узла var //инициализация необходимых переменных pRTemp, pLTemp: pStree; LR, nData, dData: integer; begin if (Search(sData) <> nil) then //Если мы нашли ключ(который нужно удалить) в нашем дереве, начинаем процедуру удаления begin if (pTemp^.left = nil) and (pTemp^.right = nil) then begin //если вершина терминальная WriteLn; WriteLn('Вершина терминальная, удаляю.'); WriteLn('Родителем является: ', pRoditel^.Data); if pRoditel^.left = pTemp then pRoditel^.left := nil; if pRoditel^.right = pTemp then pRoditel^.right := nil; WriteLn('Успешно удалено.'); WriteLn; end //если у вершины есть хотя бы один потомок else if (pTemp^.left = nil) xor (pTemp^.right = nil) then begin WriteLn; WriteLn('У вершины есть один потомок, удаляю безопасным методом.'); WriteLn('Родителем является: ', pRoditel^.Data); if (pTemp^.left = nil) then begin pRoditel^.right := pTemp^.right; end; if (pTemp^.right = nil) then begin pRoditel^.left := pTemp^.left; end; WriteLn('Успешно удалено.'); WriteLn; end else if (pRoditel^.left <> nil) and (pRoditel^.right <> nil) then begin //если у вершины есть оба потомка WriteLn; WriteLn('У вершины есть два потомка: удаляю методом замены.'); WriteLn('Левое поддерево: ', pTemp^.left^.Data); WriteLn('Правое поддерево: ', pTemp^.right^.Data); WriteLn('Родителем является: ', pRoditel^.Data); //ищем самую левую вершину //заходим в левое поддерево и спускаемся как можно ниже по правой стороне pLTemp := pTemp^.left; if pLTemp^.right <> nil then while (pLTemp^.right <> nil) do begin if (pLTemp^.right = nil) then break else pLTemp := pLTemp^.right; end; WriteLn('Самая правая вершина в левом поддереве: ', pLTemp^.Data); //ищем самую правую вершину //заходим в правое поддерево и спускаемся как можно ниже по левой стороне pRTemp := pTemp^.right; //WriteLn(pRTemp^.left^.Data);//для отладки, потом удалить. if pRTemp^.left <> nil then while (pRTemp^.left <> nil) do begin if (pRTemp^.left = nil) then break else pRTemp := pRTemp^.left; end; WriteLn('Самая левая вершина в правом поддереве: ', pRTemp^.Data); //выбор вершины для замены Write('Какую вершину желаете выбрать в качестве замены? (Л/П): '); ReadLn(LR); if (LR = pRTemp^.Data) then begin WriteLn('Удаляемая вершина - ', pTemp^.Data); dData := pTemp^.Data; //запоминаем ключ удаляемой вершины WriteLn('Выбрана вершина-заменитель - ', pRTemp^.Data); nData := pRTemp^.Data; //запоминаем ключ вершины-заменителя WriteLn('Cохранил ключ: ', nData); Pop(pRTemp^.Data); //удаляем вершину-заменитель pTemp := Search(dData); if pTemp <> nil then pTemp^.Data := nData else WriteLn('Непредвиденная ошибка, удаляемый элемент потерян.'); end; if (LR = pLTemp^.Data) then begin WriteLn('Удаляемая вершина - ', pTemp^.Data); dData := pTemp^.Data; //запоминаем ключ удаляемой вершины WriteLn('Выбрана вершина-заменитель - ', pLTemp^.Data); nData := pLTemp^.Data; //запоминаем ключ вершины-заменителя WriteLn('Cохранил ключ: ', nData); Pop(pLTemp^.Data); //удаляем вершину-заменитель pTemp := Search(dData); if pTemp <> nil then pTemp^.Data := nData else WriteLn('Непредвиденная ошибка, удаляемый элемент потерян.'); end; end; end else begin WriteLn; WriteLn('404: Вершина не найдена.'); end; WriteLn; end; begin repeat //Меню пользователя WriteLn('1. Поиск вершины с заданным значением ключа'); WriteLn('2. Добавление новой вершины'); WriteLn('3. Нарисовать дерево в консоли'); WriteLn('4. Удаление вершины с заданным значением ключа'); WriteLn('5. Выход из программы'); Write('Введите значение: '); ReadLn(menu); case menu of 1: begin WriteLn; Write('Введите значение ключа для поиска: '); ReadLn(sData); pResult := Search(sData); if (pResult = nil) then begin WriteLn('Ошибка 404: Узел не найден.'); WriteLn; end; end; 2: begin Write('Введите ключ добавляемого элемента: '); ReadLn(NewData); AddNode(pKoren, NewData); WriteLn('Успешно добавлено.'); WriteLn; end; 3: Print; //(pKoren, 0); 4: begin Write('Введите ключ вершины для удаления: '); ReadLn(sData); Pop(sData); end; end; until menu = 5; end. 1.4 Результаты тестированияРис.1 – Дерево после добавление 7-ми элементов 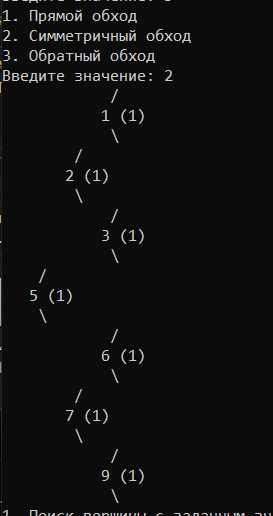 Рис.2 – Дерево после добавления 8-мого элемента с ключом 10  Рис.3 – Пример работы поиска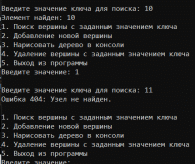 Рис.4 – Пример удаления не терминальной вершины (ключ = 2) Рис.5 – Пример удаления терминальной вершины (ключ = 10) |