кек. Ответы на вопросы контрольной работы. Ответы на вопросы по к р. 1 Основные элементы проектирования ис
 Скачать 157.45 Kb. Скачать 157.45 Kb.
|

|
8 Структурные элементы БД Первичный ключ — в реляционной модели данных один из потенциальных ключей отношения, выбранный в качестве основного ключа (или ключа по умолчанию). Внешний ключ — понятие теории реляционных баз данных, относящееся к ограничениям целостности базы данных. Понятие базы данных тесно связано с такими понятиями структурных элементов, как поле, запись, таблица (файл): Поле – элементарная единица логической организации данных, которая соответствует неделимой единице информации – реквизиту. Для описания поля используются следующие характеристики: Имя, например, Фамилия, Дата рождения; Тип, например, текстовый, числовой; Длина, например, 15 байт и т.д. +Запись – совокупность логически связанных полей. Экземпляр записи – отдельная реализация записи, содержащая конкретные значения ее полей. Таблица (файл) – совокупность экземпляров записей одной структуры. Если проще, то поле – это столбец таблицы, а экземпляр записи – строка Описание логической структуры записи таблицы содержит последовательность расположения полей записи и их основные характеристики. В структуре записи файла указываются поля, значения которых являются ключами: первичными (ПК), которые идентифицируют экземпляр записи, и вторичными (ВК), которые выполняют роль поисковых или группировочных признаков (по значению вторичного ключа можно найти несколько записей). Виды моделей данных Общие положения Ядром любой базы данных является модель данных. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью модели данных могут быть представлены объекты предметной областей взаимосвязи между ними. Модель данных — совокупность структур данных и операций их обработки. СУБД основывается на использовании иерархической, сетевой или реляционной модели, на комбинации этих моделей или на некотором их подмножестве. Рассмотрим три основных типа моделей данных: иерархическую, сетевую и реляционную. Иерархическая модель данных Иерархическая структура представляет совокупность элементов, связанных между собой по определенным правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевернутое дерево) К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один (иерархический) путь от корневой записи. 9 Понятие и виды модели данных Данные, хранимые в БД, имеют определенную логическую структуру, т.е. описываются некоторой моделью представления данных (моделью данных). Модель данных — это совокупность взаимосвязанных структур данных, операций над ними и множества ограничений для хранимых данных. Различные СУБД поддерживают различные модели данных. Как уже было отмечено, одной из наиболее распространенных в настоящее время моделей является реляционная. Кроме нее к числу классических моделей данных относят иерархическую и сетевую. Выбор той или иной модели данных связан с определенной гипотезой о строении предметной области и, как следствие, с некоторыми допущениями. Исторически сложилось так, что первой появилась иерархическая модель данных, затем сетевая. Обе эти модели для создания БД уже не используются, однако созданные на их основе БД продолжают действовать. Иерархическая модель данных. Описание отображаемой предметной области в иерархической модели данных базируется на гипотезе о том, что моделируемую область можно рассматривать как иерархию объектов. Вся предметная область, представляющая некоторый класс объектов, разбивается на подклассы, каждый подкласс — на подклассы более низкого уровня и т.д., — это модель типа «дерево». Дерево — это связный граф, который не содержит циклов. Связный граф — это неориентированный граф, в котором между каждыми двумя вершинами имеется путь. Иерархическая модель организует данные в виде структуры, состоящей из узлов и ветвей. Паивысший уровень называется «корнем». На нижних уровнях находятся предки по отношению к нижестоящим узлам и потомки но отношению к вышестоящим. Каждый потомок может быть связан только с одним предком, а один предок может иметь О, 1 или N потомков. Доступ к каждому потомку выполняется через его непосредственного предка, и существует единственный иерархический путь доступа к любому узлу, начинающийся с корня дерева. В схеме иерархической БД узлы иерархической модели представляют сущности (информационные объекты), а дуги — связи между ними. Для БД определен порядок обхода — «сверху-вниз», «слева-направо». В иерархической БД для поддержания целостности данных должно выполняться правило: никакой потомок не может существовать без своего предка. 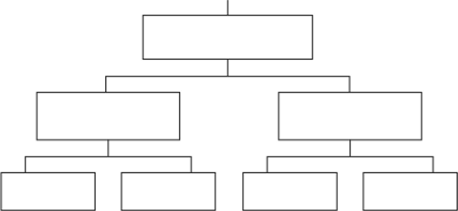 Иерархическая модель данных Достоинствами этой модели являются простота понимания и использования. Такая модель удобна для работы с иерархически упорядоченной информацией. Иерархическая модель данных, как показала практика, позволяет эффективно использовать память компьютера и демонстрирует достаточно высокую скорость выполнения основных операций над данными. Недостаток модели — отсутствие универсальности: для большинства задач требуется дублирование данных, возможна потеря данных, связи «многие-ко-многим» (см. ниже) могут быть реализованы только искусственно при избыточности данных. Другой недостаток — допустимость только навигационного принципа доступа к данным (последовательным перемещением по БД для нахождения требуемой записи): записи извлекаются по одной, и чтобы извлечь некое множество данных, нужно повторять операции извлечения многократно. Непосредственный доступ по ключу (см. ниже), как правило, возможен только к объекту самого высокого уровня (корневому). Для обработки информации с достаточно сложными логическими связями иерархическая модель подходит плохо, поскольку становится громоздкой и сложной для понимания обычного пользователя. На иерархической модели основано сравнительно небольшое число СУБД. Типичным представителем иерархических БД является IMS (Information Management System) компании IBM. Другие примеры: зарубежные системы PC/Focus, Team-Up и Data Edge, а также отечественные разработки — Ока, ИНЭС и МИРИС |9, 33J. Сетевая модель данных. Применение сетевой модели данных предполагает наличие сетевой структуры моделируемой предметной области. Вся область рассматривается как совокупность частей, связанных между собой бинарными связями различных типов. Допускаются связи между различными уровнями, т.с. сетевая модель представляет собой пересекающиеся иерархии. В сетевой модели потомок может иметь любое число предков. 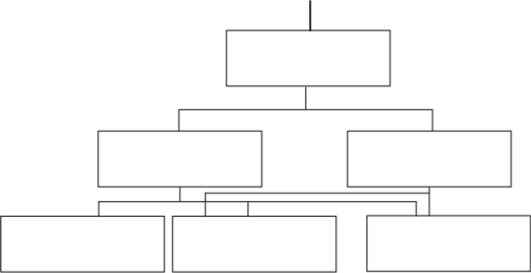 Сетевая модель данных Сетевая модель по сравнению с иерархической является более универсальной. В ней возможен доступ по ключу не только к объекту на высшем уровне иерархии, но и к объектам любого уровня. В данной модели возможно обеспечить связи «многие-ко-многим», отсутствие дублирования данных и формирование запросов. Однако ее существенным недостатком является сложность, т.е. обилие понятий, вариантов их взаимосвязей и особенностей реализации. Такие усложнения приводят к необходимости хранения вместе с данными множества указателей, а также допустимости только навигационного принципа доступа к данным. В сетевой модели ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями. Системы на основе сетевой модели не получили широкого практического распространения. Типичным примером сетевой БД является IDMS (Integrated Database Management System) компании Cullinet Software. Другие примеры: db_VistaIII, СЕТЬ, CETOP и КОМПАС [9, 33]. Реляционная модель данных. Описание отображаемой предметной области базируется на гипотезе о том, что моделируемую область можно рассматривать как совокупность нескольких множеств, между элементами которых существуют некоторые отношения. Основными элементами модели являются реляционные таблицы и связи между ними. В каждой таблице содержатся сведения об одной сущности. В исходных таблицах, из которых данные вводятся в таблицы БД, столбцы должны иметь уникальные имена, содержать данные только одного типа (либо числа, либо текст и т.п.), быть неделимыми и не иметь пустых и повторяющихся строк. Структура таблицы определяется составом и последовательностью ее полей с указанием типа элементарного данного, размещаемого в поле. Основными типами данных являются числовой, текстовый, дата/время, логический. Содержание таблицы заключено в ее записях. Каждая запись содержит данные о конкретном экземпляре сущности. Для однозначного определения каждой записи таблица должна иметь уникальный ключ (ключевое поле или совокупность нескольких полей), называемый первичным ключом. Так, в таблице «Клиент» ключевым полем может быть «Код клиента». По значению ключа отыскивается единственная запись. Связи между таблицами дают возможность совместно использовать данные из разных таблиц. При этом одна из таблиц играет роль главной, а вторая — подчиненной. Например, при связывании таблиц «Клиент» и «Заказ» одной записи со значением поля «Код клиента», равным 1224, может соответствовать несколько записей с таким же значением поля «Код клиента» в таблице «Заказ» (один клиент может сделать несколько заказов). Операции, производимые над реляционными таблицами, разделяются на традиционные операции над множествами — объединение, пересечение, вычитание, декартово произведение, и операции реляционной алгебры - выбор, проекция и соединение. Основными ограничениями реляционной модели являются функциональные зависимости между полями реляционных таблиц. Считается, что одно иоле в таблице функционально определяет другое, если каждому значению первого поля соответствует единственное значение второго. Некоторые виды функциональной зависимости могут приводить к избыточности данных в базе. Для ее устранения (минимизации) при проектировании реляционных БД используется нормализация — процесс преобразования данных от одной нормальной формы к другой, более высокой. Нормальные формы (НФ) формируются последовательно и по возрастанию (1НФ, 211Ф, ЗНФ), и чем больше номер, тем больше ограничений на хранимые значения должно соблюдаться в соответствующей реляционной таблице. Любая реляционная таблица находится в первой нормальной форме (1НФ). Одним из основных достоинств реляционной модели является привычное для пользователя-экономиста представление данных в форме таблиц. Структуры данных легко создавать и понимать, программы для манипулирования данными также пишутся достаточно просто. Другим достоинством является наличие теоретически обоснованных методов получения минимальной избыточности представления данных. Существуют специальные методы нормализации, в частности есть возможность средствами некоторых СУБД в результате анализа исходной таблицы получить варианты нормализованных таблиц и устранить избыточность. Существенным недостатком модели можно считать низкое быстродействие при реализации операции соединения таблиц. Нормализация данных реляционной модели приводит к значительной фрагментации данных, в то время как в большинстве задач необходимо объединение фрагментированных данных. Недостатком, обусловившим появление многомерной модели, является невозможность использования данных базы аналитиками (а не программистами) для оперативного анализа данных, изменяющихся во времени. Другим недостатком этой модели в последние годы стала считаться идея пассивного множества данных, положенных в ее основу. Этой моделью не предусмотрено описание реального поведения данных, а также в ней ограничены семантические возможности, затруднено представление смысла данных. Это привело к появлению объектно-ориентированной модели данных. 10 Методы проектирования ИС Методы проектирования ИС можно классифицировать по степени использования средств автоматизации, типовых проектных решений, адаптивности к предполагаемым изменениям. Так, по степени автоматизации методы проектирования разделяются на: ручное, при котором проектирование компонентов ИС осуществляется без использования специальных инструментальных программных средств, а программирование — на алгоритмических языках; компьютерное, при котором производится генерация или конфигурирование (настройка) проектных решений на основе использования специальных инструментальных программных средств. По степени использования типовых проектных решений различают следующие методы проектирования: оригинальное (индивидуальное), когда проектные решения разрабатываются «с нуля» в соответствии с требованиями к АИС. Характеризуется тем, что все виды проектных работ ориентированы на создание индивидуальных для каждого объекта проектов, которые в максимальной степени отражают все его особенности; типовое, предполагающее конфигурирование ИС из готовых типовых проектных решений (программных модулей). Выполняется на основе опыта, полученного при разработке индивидуальных проектов. Типовые проекты, как обобщение опыта для некоторых групп организационно-экономических систем или видов работ, в каждом конкретном случае связаны со множеством специфических особенностей и различаются по степени охвата функций управления, выполняемым работам и разрабатываемой проектной документации. По степени адаптивности проектных решений выделяют методы: реконструкции, когда адаптация проектных решений выполняется путем переработки соответствующих компонентов (перепрограммирования программных модулей); параметризации, когда проектные решения настраиваются (генерируются) в соответствии с изменяемыми параметрами; реструктуризации модели, когда изменяется модель проблемной области, на основе которой автоматически заново генерируются проектные решения. Сочетание различных признаков классификации методов обусловливает характер используемых технологий проектирования ИС, среди которых выделяют два основных класса: каноническую и индустриальную технологии. Индустриальная технология проектирования, в свою очередь, разбивается на два подкласса: автоматизированное (использование CASE-технологий) и типовое (параметрически-ориентированное или модельно-ориентированное) проектирование. Использование индустриальных технологий не исключает использования в отдельных случаях канонических. |