кек. Ответы на вопросы контрольной работы. Ответы на вопросы по к р. 1 Основные элементы проектирования ис
 Скачать 157.45 Kb. Скачать 157.45 Kb.
|

|
Ответы на вопросы по к.р. 1 Основные элементы проектирования ИС Проектирование ИС охватывает три основные области: проектирование объектов данных, которые будут реализованы в базе данных; проектирование программ, экранных форм, отчетов, которые будут обеспечивать выполнение запросов к данным; учет конкретной среды или технологии, а именно: топологии сети, конфигурации аппаратных средств, используемой архитектуры (файл-сервер или клиент-сервер), параллельной обработки, распределенной обработки данных и т.п. Проектирование информационных систем всегда начинается с определения цели проекта. В общем виде цель проекта можно определить как решение ряда взаимосвязанных задач, включающих в себя обеспечение на момент запуска системы и в течение всего времени ее эксплуатации: требуемой функциональности системы и уровня ее адаптивности к изменяющимся условиям функционирования; требуемой пропускной способности системы; требуемого времени реакции системы на запрос; безотказной работы системы; необходимого уровня безопасности; простоты эксплуатации и поддержки системы. Согласно современной методологии, процесс создания ИС представляет собой процесс построения и последовательного преобразования ряда согласованных моделей на всех этапах жизненного цикла (ЖЦ) ИС. На каждом этапе ЖЦ создаются специфичные для него модели - организации, требований к ИС, проекта ИС, требований к приложениям и т.д. Модели формируются рабочими группами команды проекта, сохраняются и накапливаются в репозитории проекта. Создание моделей, их контроль, преобразование и предоставление в коллективное пользование осуществляется с использованием специальных программных инструментов - CASE-средств. Процесс создания ИС делится на ряд этапов (стадий ), ограниченных некоторыми временными рамками и заканчивающихся выпуском конкретного продукта (моделей, программных продуктов, документации и пр.). Обычно выделяют следующие этапы создания ИС: формирование требований к системе, проектирование, реализация, тестирование, ввод в действие, эксплуатация и сопровождение . (Последние два этапа далее не рассматриваются, поскольку выходят за рамки тематики курса.) Начальным этапом процесса создания ИС является моделирование бизнес-процессов, протекающих в организации и реализующих ее цели и задачи. Модель организации, описанная в терминах бизнес-процессов и бизнес-функций, позволяет сформулировать основные требования к ИС. Это фундаментальное положение методологии обеспечивает объективность в выработке требований к проектированию системы. Множество моделей описания требований к ИС затем преобразуется в систему моделей, описывающих концептуальный проект ИС. Формируются модели архитектуры ИС, требований к программному обеспечению (ПО) и информационному обеспечению (ИО). Затем формируется архитектура ПО и ИО, выделяются корпоративные БД и отдельные приложения, формируются модели требований к приложениям и проводится их разработка, тестирование и интеграция. Целью начальных этапов создания ИС, выполняемых на стадии анализа деятельности организации, является формирование требований к ИС, корректно и точно отражающих цели и задачи организации-заказчика. Чтобы специфицировать процесс создания ИС, отвечающей потребностям организации, нужно выяснить и четко сформулировать, в чем заключаются эти потребности. Для этого необходимо определить требования заказчиков к ИС и отобразить их на языке моделей в требования к разработке проекта ИС так, чтобы обеспечить соответствие целям и задачам организации. Задача формирования требований к ИС является одной из наиболее ответственных, трудно формализуемых и наиболее дорогих и тяжелых для исправления в случае ошибки. Современные инструментальные средства и программные продукты позволяют достаточно быстро создавать ИС по готовым требованиям. Но зачастую эти системы не удовлетворяют заказчиков, требуют многочисленных доработок, что приводит к резкому удорожанию фактической стоимости ИС. Основной причиной такого положения является неправильное, неточное или неполное определение требований к ИС на этапе анализа. На этапе проектирования прежде всего формируются модели данных. Проектировщики в качестве исходной информации получают результаты анализа. Построение логической и физической моделей данных является основной частью проектирования базы данных. Полученная в процессе анализа информационная модель сначала преобразуется в логическую, а затем в физическую модель данных. Параллельно с проектированием схемы базы данных выполняется проектирование процессов, чтобы получить спецификации (описания) всех модулей ИС. Оба эти процесса проектирования тесно связаны, поскольку часть бизнес-логики обычно реализуется в базе данных (ограничения, триггеры, хранимые процедуры). Главная цель проектирования процессов заключается в отображении функций, полученных на этапе анализа, в модули информационной системы. При проектировании модулей определяют интерфейсы программ: разметку меню, вид окон, горячие клавиши и связанные с ними вызовы. Конечными продуктами этапа проектирования являются: схема базы данных (на основании ER-модели, разработанной на этапе анализа); набор спецификаций модулей системы (они строятся на базе моделей функций). Кроме того, на этапе проектирования осуществляется также разработка архитектуры ИС, включающая в себя выбор платформы (платформ) и операционной системы (операционных систем). В неоднородной ИС могут работать несколько компьютеров на разных аппаратных платформах и под управлением различных операционных систем. Кроме выбора платформы, на этапе проектирования определяются следующие характеристики архитектуры: будет ли это архитектура "файл-сервер" или "клиент-сервер"; будет ли это 3-уровневая архитектура со следующими слоями: сервер, ПО промежуточного слоя (сервер приложений), клиентское ПО; будет ли база данных централизованной или распределенной. Если база данных будет распределенной, то какие механизмы поддержки согласованности и актуальности данных будут использоваться; будет ли база данных однородной, то есть, будут ли все серверы баз данных продуктами одного и того же производителя (например, все серверы только Oracle или все серверы только DB2 UDB). Если база данных не будет однородной, то какое ПО будет использовано для обмена данными между СУБД разных производителей (уже существующее или разработанное специально как часть проекта); будут ли для достижения должной производительности использоваться параллельные серверы баз данных (например, Oracle Parallel Server, DB2 UDB и т.п.). Этап проектирования завершается разработкой технического проекта ИС. На этапе реализации осуществляется создание программного обеспечения системы, установка технических средств, разработка эксплуатационной документации. Этап тестирования обычно оказывается распределенным во времени. После завершения разработки отдельного модуля системы выполняют автономный тест, который преследует две основные цели: обнаружение отказов модуля (жестких сбоев); соответствие модуля спецификации (наличие всех необходимых функций, отсутствие лишних функций). После того как автономный тест успешно пройден, модуль включается в состав разработанной части системы и группа сгенерированных модулей проходит тесты связей, которые должны отследить их взаимное влияние. Далее группа модулей тестируется на надежность работы, то есть проходят, во-первых, тесты имитации отказов системы, а во-вторых, тесты наработки на отказ. Первая группа тестов показывает, насколько хорошо система восстанавливается после сбоев программного обеспечения, отказов аппаратного обеспечения. Вторая группа тестов определяет степень устойчивости системы при штатной работе и позволяет оценить время безотказной работы системы. В комплект тестов устойчивости должны входить тесты, имитирующие пиковую нагрузку на систему. Затем весь комплект модулей проходит системный тест - тест внутренней приемки продукта, показывающий уровень его качества. Сюда входят тесты функциональности и тесты надежности системы. Последний тест информационной системы - приемо-сдаточные испытания. Такой тест предусматривает показ информационной системы заказчику и должен содержать группу тестов, моделирующих реальные бизнес-процессы, чтобы показать соответствие реализации требованиям заказчика. Необходимость контролировать процесс создания ИС, гарантировать достижение целей разработки и соблюдение различных ограничений (бюджетных, временных и пр.) привело к широкому использованию в этой сфере методов и средств программной инженерии: структурного анализа, объектно-ориентированного моделирования, CASE-систем. 2 Автоматизация проектирования ИС Аббревиатура CASE (Computer-Aided Software Engineering – автоматизированная разработка программного обеспечения) обозначает специальный тип программного обеспечения, предназначенного для поддержки таких процессов создания ПО, как разработка требований, проектирование, кодирование и тестирование программ. Поэтому к CASE-средствам относятся редакторы проектов, словари данных, компиляторы, отладчики, средства построения систем и т.п. CASE-средства предлагают поддержку процесса создания ПО путем автоматизации некоторых этапов разработки, а также создания и представления информации, необходимой для разработки. +В настоящее время подходящие CASE-технологии существуют для большинства процессов, выполняемых в ходе разработки ПО. Это ведет к улучшению качества создаваемых программ и повышению производительности труда разработчиков программного обеспечения. Уже сложилась развитая индустрия CASE-средств, а круг поставщиков и разработчиков этих программных продуктов очень широк. Классификация case-средств Существует несколько различных классификаций CASE-средств, и каждая предлагает свой взгляд на эти программные продукты. Рассмотрим классификацию по категориям, где CASE-средства классифицируются по степени интеграции программных модулей, поддерживающих различные процессы разработки ПО. Эта классификация содержит три основные категории: вспомогательные программы (tools) поддерживают отдельные процессы разработки ПО, такие как проверка непротиворечивости архитектуры системы, компиляция программ, сравнение результатов тестов и т.д. Вспомогательные программы могут быть универсальными функционально законченными средствами или могут входить в состав инструментальных средств; инструментальные средства (workbenches) поддерживают определенные процессы разработки ПО, такие как создание спецификации, проектирования. Обычно они представляют собой набор интегрированных вспомогательных программ; рабочие среды разработчиков (environments) поддерживают все или большинство процессов разработки ПО и включают в себя несколько различных интегрированных инструментальных средств. Вспомогательные программы выбираются разработчиками ПО обычно по своему усмотрению. Инструментальные средства поддерживают определенные методы разработки на основе некоторой модели разработки ПО, наборов правил и нормативных указаний. Интегрированные рабочие среды представляют инфраструктуру поддержки для данных, управления и интеграции системных представлений. Экспертные рабочие среды более интеллектуальны. Они включают базу знаний о процессах создания ПО и механизм, предлагающий разработчику те или иные вспомогательные или инструментальные средства. 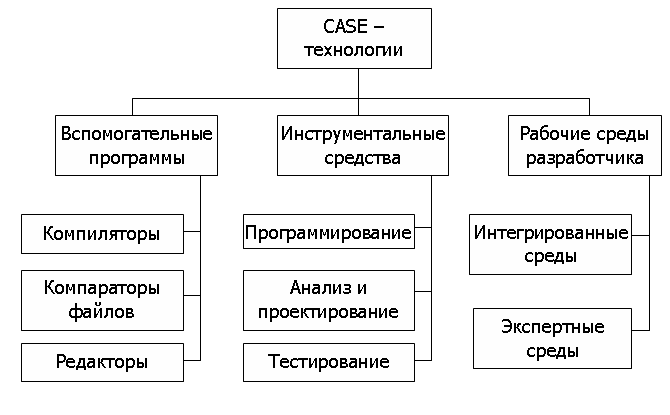 Классификация CASE-средств по категориям 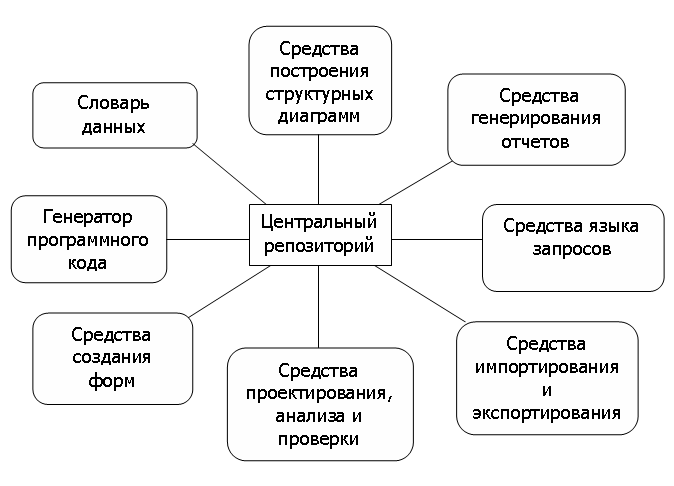 Пакет инструментальных CASE-средств Такой пакет образуют следующие средства. Редакторы диаграмм предназначены для создания диаграмм потоков данных, иерархий объектов, диаграмм «сущность-связь». Эти редакторы не только имеют средства рисования, но и поддерживают различные типы объектов, используемых в диаграммах. Средства проектирования, анализа и проверки выполняют проектирование ПО и создают отчет об ошибках и дефектах в системной архитектуре. Они могут работать совместно с системой редактирования, поэтому обнаруженные ошибки можно устранить на ранней стадии проектирования. Центральный репозиторий позволяет проектировщику найти нужный проект и соответствующую ему проектную информацию. Словарь данных хранит информацию об объектах, которые используются в структуре системы. Средства генерирования отчетов на основе информации из центрального репозитория автоматически генерируют системную документацию. Средства создания форм определяют форматы экранных форм и документов. Средства импортирования и экспортирования позволяют обмениваться информацией из центрального репозитория различным инструментальным средствам. Генераторы программного кода автоматически генерируют программы на основе проектов, хранящихся в центральном репозитории. Инструментальная система поддержки проекта это открытая система, способная поддерживать разработку ПС на разных языках программирования после соответствующего ее расширения программными инструментами, ориентированными на выбранный язык. Набор инструментов такой системы поддерживает разработку ПС, а также содержит независимые от языка программирования инструменты, поддерживающие разработку ПС (текстовые и графические редакторы, генераторы отчетов и т.п.). Кроме того, он содержит инструменты расширения системы. Ядро такой системы обеспечивает, в частности, доступ к репозиторию. Языково-зависимая инструментальная система это система поддержки разработки ПС на каком-либо одном языке программирования, существенно использующая в организации своей работы специфику этого языка. Эта специфика может сказываться и на возможностях ядра (в том числе и на структуре репозитория), и на требованиях к оболочке и инструментам. Примером такой системы является среда поддержки программирования на Аде. Помимо этого CASE-средства можно классифицировать по применяемым методологиям и моделям систем и БД; степени интегрированности с СУБД; доступным платформам. Классификация по типам в основном совпадает с компонентным составом CASE-средств и включает: средства анализа (Upper CASE), предназначенные для построения и анализа моделей предметной области (Design/IDEF (Meta Software), BPwin (Logic Works)); средства анализа и проектирования (Middle CASE), поддерживающие наиболее распространенные методологии проектирования и использующиеся для создания проектных спецификаций (Vantage Team Builder (Cayenne), Designer/2000 (ORACLE), Silverrun (CSA), PRO-IV (McDonnell Douglas), CASE Аналитик (МакроПроджект)). Выходом таких средств являются спецификации компонентов и интерфейсов системы, архитектуры системы, алгоритмов и структур данных; средства проектирования баз данных, обеспечивающие моделирование данных и генерацию схем баз данных (как правило, на языке SQL) для наиболее распространенных СУБД. К ним относятся ERwin (Logic Works), S-Designor (SDP) и DataBase Designer (ORACLE); средства разработки приложений. К ним относятся средства 4GL (Uniface (Compuware), JAM (JYACC), PowerBuilder (Sybase), Developer/2000 (ORACLE), New Era (Informix), SQL Windows (Gupta), Delphi (Borland) и др.) и генераторы кодов, входящие в состав Vantage Team Builder, PRO-IV и частично – в Silverrun; средства реинжиниринга, обеспечивающие анализ программных кодов и схем баз данных и формирование на их основе различных моделей и проектных спецификаций. Средства анализа схем БД и формирования ERD входят в состав Vantage Team Builder, PRO-IV, Silverrun, Designer/2000, ERwin и S-Designor. В области анализа программных кодов наибольшее распространение получают объектно-ориентированные CASE-средства, обеспечивающие реинжиниринг программ на языке С++ (Rational Rose (Rational Software), Object Team (Cayenne)). Вспомогательные типы включают: средства планирования и управления проектом (SE Companion, Microsoft Project и др.); средства конфигурационного управления (PVCS (Intersolv)); средства тестирования (Quality Works (Segue Software)); средства документирования (SoDA (Rational Software)). 3 Методология и технология проектирования ИС по архитектуре файл-сервер и клиент-сервер Файл-серверные приложения По всей видимости, организация информационных систем на основе использования выделенных файл-серверов все еще является наиболее распространенной в связи с наличием большого количества персональных компьютеров разного уровня развитости и сравнительной дешевизны связывания PC в локальные сети. Чем привлекает такая организация не очень опытных в области системного программирования разработчиков информационных систем? Скорее всего, тем, что при опоре на файл-серверные архитектуры сохраняется автономность прикладного (и большей части системного) программного обеспечения, работающего на каждой PC сети. Фактически, компоненты информационной системы, выполняемые на разных PC, взаимодействуют только за счет наличия общего хранилища файлов, которое хранится на файл-сервере. В классическом случае в каждой PC дублируются не только прикладные программы, но и средства управления базами данных. Файл-сервер представляет собой разделяемое всеми PC комплекса расширение дисковой памяти. Не останавливаясь подробно на имеющихся на сегодняшнем рынке перспективных инструментальных средствах разработки файл-серверных приложений и не приводя анализа тенденций развития соответствующих технологий (этому посвящается третья часть курса), мы кратко перечислим основные достоинства и недостатки файл-серверных архитектур. Конечно, основным достоинством является простота организации. Проектировщики и разработчики информационной системы находятся в привычных и комфортных условиях IBM PC в среде MS-DOS, Windows или какого-либо облегченного варианта Windows NT. Имеются удобные и развитые средства разработки графического пользовательского интерфейса, простые в использовании средства разработки систем баз данных и/или СУБД. Но во многом эта простота является кажущейся. (Как гласит русская пословица, "Простота хуже воровства", а здесь мы, как правило, имеем простоту на основе воровства программных продуктов для PC.) 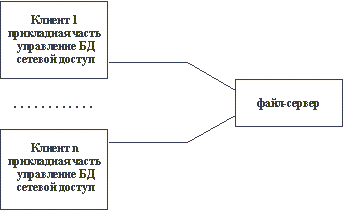 Классическое представление информационной системы в архитектуре "файл-сервер" Во-первых, информационной системе предстоит работать с базой данных. Следовательно, эта база данных должна быть спроектирована. Почему-то часто разработчики файл-серверных приложений считают, что по причине простоты средств управления базами данных проблемой проектирования базы данных можно пренебречь. Конечно, это неправильно. База данных есть база данных. Чем качественнее она спроектирована, тем больше шансов впоследствии эффективно использовать информационную систему. Естественно, сложность проектирования базы данных определяется объективной сложностью моделируемой предметной области. Но, собственно, из чего должно следовать, что файл-серверные приложения пригодны только в простых предметных областях? Во-вторых, как мы неоднократно подчеркивали в первой части курса, необходимыми требованиями к базе данных информационной системы являются поддержание ее целостного состояния и гарантированная надежность хранения информации. Минимальными условиями, при соблюдении которых можно удовлетворить эти требования, являются: наличие транзакционного управления, хранение избыточных данных (например, с применением методов журнализации), возможность формулировать ограничения целостности и проверять их соблюдение. В принципе, файл-серверная организация, как она показана на, не противоречит соблюдению отмеченных условий. В качестве примера системы, соблюдающей выполнение этих условий, но основанной на файл-серверной архитектуре, можно привести популярный в прошлом "сервер баз данных" Informix SE. Длинноезамечание: Для сохранения четкости дальнейшего изложения нам необходимо несколько уточнить терминологию. Мы недаром написали "сервер баз данных" в кавычках применительно к СУБД Informix SE. При использовании этой системы копия программного обеспечения СУБД поддерживалась для каждого инициированного пользователем сеанса работы с СУБД. Грубо говоря, для каждого пользовательского процесса, взаимодействующего с базой данных создавался служебный процесс СУБД, который выполнялся на том же процессоре, что и пользовательский процесс (т.е. на стороне клиента). Каждый из этих служебных процессов вел себя фактически так, как если бы был единственным представителем СУБД. Вся синхронизация возможной параллельной работы с базой данных производилась на уровне файлов внешней памяти, содержащих базу данных. Условимся впредь называть такие СУБД не серверами баз данных, а системами управления базами данных, основанными на файл-серверной архитектуре (СУБД-ФС). Под истинным сервером баз данных мы будем понимать программное образование, привязанное к соответствующей базе (базам) данных, существующее, вообще говоря, независимо от существования пользовательских (клиентских) процессов и выполняемое, вообще говоря (хотя и не обязательно) на выделенной аппаратуре (мы намеренно используем не очень конкретные термины "программное образование" и "выделенная аппаратура", потому что их конкретное воплощение различается в разных серверах баз данных). Истинные серверы баз данных существенно сложнее по организации, чем СУБД-ФС, на зато обеспечивают более тонкое и эффективное управление базами данных. Везде далее в этом курсе при употреблении термина "сервер баз данных" мы будем иметь в виду истинные серверы баз данных. Но с другой стороны, в большинстве персональных СУБД эти условия не выполняются даже с помощью грубых приемов. В лучшем случае удается частично восполнить недостатки на уровне прикладных программ. В третьих, интерфейс развитых серверов баз данных основан на использовании высокоуровневого языка баз данных SQL, что позволяет использовать сетевой трафик между клиентом и сервером баз данных только в полезных целях (от клиента к серверу в основном пересылаются операторы языка SQL, от сервера к клиенту - результаты выполнения операторов). В файл-серверной организации клиент работает с удаленными файлами, что вызывает существенную перегрузку трафика (поскольку СУБД-ФС работает на стороне клиента, то для выборки полезных данных в общем случае необходимо просмотреть на стороне клиента весь соответствующий файл целиком). В целом, в файл-серверной архитектуре мы имеем "толстого" клиента и очень "тонкий" сервер в том смысле, что почти вся работа выполняется на стороне клиента, а от сервера требуется только достаточная емкость дисковой памяти. 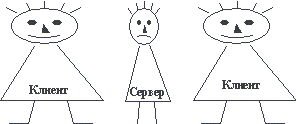 "Толстый" клиент и "тонкий" сервер в файл-серверной архитектуре Краткие выводы. Простое, работающее с небольшими объемами информации и рассчитанное на применение в однопользовательском режиме, файл-серверное приложение можно спроектировать, разработать и отладить очень быстро. Очень часто для небольшой компании для ведения, например, кадрового учета достаточно иметь изолированную систему, работающую на отдельно стоящем PC. Конечно, и в этом случае требуется большая аккуратность конечных пользователей (или администраторов, наличие которых в этом случае сомнительно) для надежного хранения и поддержания целостного состояния данных. Однако, в уже ненамного более сложных случаях (например, при организации информационной системы поддержки проекта, выполняемого группой) файл-серверные архитектуры становятся недостаточными. Клиент-серверные приложения Под клиент-серверным приложением мы будем понимать информационную систему, основанную на использовании серверов баз данных (см. длинное замечание в конце раздела 2.1). Общее представление информационной системы в архитектуре "клиент-сервер" показано на. На стороне клиента выполняется код приложения, в который обязательно входят компоненты, поддерживающие интерфейс с конечным пользователем, производящие отчеты, выполняющие другие специфичные для приложения функции (пока нас не будет занимать, как строится код приложения). Клиентская часть приложения взаимодействует с клиентской частью программного обеспечения управления базами данных, которая, фактически, является индивидуальным представителем СУБД для приложения. (Здесь опять проявляются недостатки в терминологии. Обычно, когда компания объявляет о выпуске очередного сервера баз данных, то неявно понимается, что имеется и клиентская составляющая этого продукта. Сочетание "клиентская часть сервера баз данных" кажется несколько странным, но нам придется пользоваться именно этим термином.) 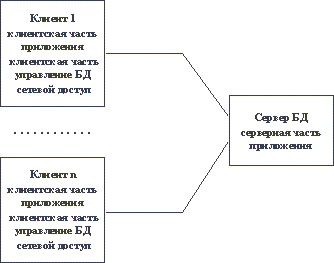 Общее представление информационной системы в архитектуре "клиент-сервер" Заметим, что интерфейс между клиентской частью приложения и клиентской частью сервера баз данных, как правило, основан на использовании языка SQL. Поэтому такие функции, как, например, предварительная обработка форм, предназначенных для запросов к базе данных, или формирование результирующих отчетов выполняются в коде приложения. Наконец, клиентская часть сервера баз данных, используя средства сетевого доступа, обращается к серверу баз данных, передавая ему текст оператора языка SQL. Здесь необходимо сделать еще два замечания. Обычно компании, производящие развитые серверы баз данных, стремятся к тому, чтобы обеспечить возможность использования своих продуктов не только в стандартных на сегодняшний день TCP/IP-ориентированных сетях, но в сетях, основанных на других протоколах (например, SNA или IPX/SPX). Поэтому при организации сетевых взаимодействий между клиентской и серверной частями СУБД часто используются не стандартные средства высокого уровня (например, механизмы программных гнезд или вызовов удаленных процедур), а собственные функционально подобные средства, менее зависящие от особенностей сетевых транспортных протоколов. Когда мы говорим об интерфейсе на основе языка SQL, нужно отдавать себе отчет в том, что несмотря на титанические усилия по стандартизации этого языка, нет такой реализации, в которой стандартные средства языка не были бы расширены. Необдуманное использование расширений языка приводит к полной зависимости приложения от конкретного производителя сервера баз данных. Мы остановимся на этих вопросах более подробно в четвертой части курса. Посмотрим теперь, что же происходит на стороне сервера баз данных. В продуктах практически всех компаний сервер получает от клиента текст оператора на языке SQL. Сервер производит компиляцию полученного оператора. Не будем здесь останавливаться на том, какой целевой язык используется конкретным компилятором; в разных реализациях применяются различные подходы (примеры см. в части 4). Главное, что в любом случае на основе информации, содержащейся в таблицах-каталогах базы данных производится преобразование непроцедурного представления оператора в некоторую процедуру его выполнения. Далее (если компиляция завершилась успешно) происходит выполнение оператора. Мы снова не будем обсуждать технические детали, поскольку они различаются в реализациях. Рассмотрим возможные действия операторов SQL. Оператор может относиться к классу операторов определения (или создания) объектов базы данных (точнее и правильнее было бы говорить про элементы схемы базы данных или про объекты метабазы данных). В частности, могут определяться домены, таблицы, ограничения целостности, триггеры, привилегии пользователей, хранимые процедуры. В любом случае, при выполнении оператора создания элемента схемы базы данных соответствующая информация помещается в таблицы-каталоги базы данных (в таблицы метабазы данных). Ограничения целостности обычно сохраняются в метабазе данных прямо в текстовом представлении. Для действий, определенных в триггерах, и хранимых процедур вырабатывается и сохраняется в таблицах-каталогах процедурный выполняемый код. Заметим, что ограничения целостности, триггеры и хранимые процедуры являются, в некотором смысле, представителями приложения в поддерживаемой сервером базе данных; они составляют основу серверной части приложения (см. ниже). При выполнении операторов выборки данных на основе содержимого затрагиваемых запросом таблиц и, возможно, с использованием поддерживаемых в базе данных индексов формируется результирующий набор данных (мы намеренно не используем здесь термин "результирующая таблица", поскольку в зависимости от конкретного вида оператора результат может быть упорядоченным, а таблицы, т.е. отношения неупорядочены по определению). Серверная часть СУБД пересылает результат клиентской части, и окончательная обработка производится уже в клиентской части приложения. При выполнении операторов модификации содержимого базы данных (INSERT, UPDATE, DELETE) проверяется, что не будут нарушены определенные к этому моменту ограничения целостности (те, которые относятся к классу немедленно проверяемых), после чего выполняется соответствующее действие (сопровождаемое модификацией всех соответствующих индексов и журнализацией изменений). Далее сервер проверяет, не затрагивает ли данное изменение условие срабатывания какого-либо триггера, и если такой триггер обнаруживается, выполняет процедуру его действия. Эта процедура может включать дополнительные операторы модификации базы данных, которые могут вызвать срабатывание других триггеров и т.д. Можно считать, что те действия, которые выполняются на сервере баз данных при проверке удовлетворенности ограничений целостности и при срабатывании триггеров, представляют собой действия серверной части приложения. При выполнении операторов модификации схемы базы данных (добавления или удаления столбцов существующих таблиц, изменения типа данных существующего столбца существующей таблицы и т.д.) также могут срабатывать триггеры, т.е., другими словами, может выполняться серверная часть приложения. Аналогично, триггеры могут срабатывать при уничтожении объектов схемы базы данных (доменов, таблиц, ограничений целостности и т.д.). Особый класс операторов языка SQL составляют операторы вызова ранее определенных и сохраненных в базе данных хранимых процедур. Если хранимая процедура определяется с помощью достаточно развитого языка, включающего и непроцедурные операторы SQL, и чисто процедурные конструкции (например, языка PL/SQL компании Oracle), то в такую процедуру можно поместить серьезную часть приложения, которое при выполнении оператора вызова процедуры будет выполняться на стороне сервера, а не на стороне клиента. При выполнении оператора завершения транзакции сервер должен проверить соблюдение всех, так называемых, отложенных ограничений целостности (к таким ограничениям относятся ограничения, накладываемые на содержимое таблицы базы целиком или на несколько таблиц одновременно; например, суммарная зарплата сотрудников отдела 999 не должна превышать 150 млн. руб.). Снова к проверке отложенных ограничений целостности можно относиться как к выполнению серверной части приложения. Как видно, в клиент-серверной организации клиенты могут являться достаточно "тонкими", а сервер должен быть "толстым" настолько, чтобы быть в состоянии удовлетворить потребности всех клиентов  "Тонкий" клиент и "толстый" сервер в клиент-серверной архитектуре С другой стороны, разработчики и пользователи информационных систем, основанных на архитектуре "клиент-сервер", часто бывают неудовлетворены постоянно существующими сетевыми накладными расходами, которые следуют из потребности обращаться от клиента к серверу с каждым очередным запросом. На практике распространена ситуация, когда для эффективной работы отдельной клиентской составляющей информационной системы в действительности требуется только небольшая часть общей базы данных. Это приводит к идее поддержки локального кэша общей базы данных на стороне каждого клиента. Фактически, концепция локального кэширования базы данных является частным случаем концепции реплицированных (или, как иногда их называют в русскоязычной литературе, тиражированных) баз данных. Как и в общем случае, для поддержки локального кэша базы данных программное обеспечение рабочих станций должно содержать компонент управления базами данных - упрощенный вариант сервера баз данных, который, например, может не обеспечивать многопользовательский режим доступа. Отдельной проблемой является обеспечение согласованности (когерентности) кэшей и общей базы данных. Здесь возможны различные решения - от автоматической поддержки согласованности за счет средств базового программного обеспечения управления базами данных до полного перекладывания этой задачи на прикладной уровень. В любом случае, клиенты становятся более толстыми при том, что сервер тоньше не делается.  "Потолстевший" клиент и "толстый" сервер в клиент-серверной архитектуре с поддержкой локального кэша на стороне клиентов Сформулируем некоторые предварительные выводы. Архитектура "клиент-сервер" на первый взгляд кажется гораздо более дорогой, чем архитектура "файл-сервер". Требуется более мощная аппаратура (по крайней мере, для сервера) и существенно более развитые средства управления базами данных. Однако, это верно лишь частично. Громадным преимуществом клиент-серверной архитектуры является ее масштабируемость и вообще способность к развитию. При проектировании информационной системы, основанной на этой архитектуре, большее внимание следует обращать на грамотность общих решений. Технические средства пилотной версии могут быть минимальными (например, в качестве аппаратной основы сервера баз данных может использоваться одна из рабочих станций). После создания пилотной версии нужно провести дополнительную исследовательскую работу, чтобы выяснить узкие места системы. Только после этого необходимо принимать решение о выборе аппаратуры сервера, которая будет использоваться на практике. Увеличение масштабов информационной системы не порождает принципиальных проблем. Обычным решением является замена аппаратуры сервера (и, может быть, аппаратуры рабочих станций, если требуется переход к локальному кэшированию баз данных). В любом случае практически не затрагивается прикладная часть информационной системы. В идеале, которого, конечно же не бывает, информационная система продолжает нормально функционировать после смены аппаратуры. |