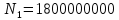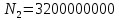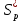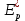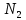Параллельное вычисление суммы числового ряда
 Скачать 72.93 Kb. Скачать 72.93 Kb.
|

|
Федеральное государственное бюджетное образовательное учреждение высшего образования "Уфимский государственный авиационный технический университет" Кафедра Высокопроизводительных вычислительных технологий и систем Дисциплина: Основы суперкомпьютерных технологий и параллельное программирование. Отчет по лабораторной работе № 1 Тема: «Параллельное вычисление суммы числового ряда»
Уфа 2021 Цель: Для многопроцессорных вычислительных систем с распределенной памятью на примере задачи параллельного вычисления суммы числового ряда научиться программно реализовывать простейшие параллельные вычислительные алгоритмы и проводить анализ их эффективности. Теоретический материал: MPI - это стандарт на программный инструментарий для обеспечения связи между ветвями параллельного приложения. MPI предоставляет программисту единый механизм взаимодействия ветвей внутри параллельного приложения независимо от машинной архитектуры (однопроцессорные / многопроцессорные с общей/раздельной памятью), взаимного расположения ветвей (на одном процессоре / на разных) и API операционной системы. Параллельное приложение состоит из нескольких ветвей, или процессов, или задач, выполняющихся одновременно. Процессы обмениваются друг с другом данными в виде сообщений. Особенность MPI: понятие области связи (communication domains). При запуске приложения все процессы помещаются в создаваемую для приложения общую область связи. При необходимости они могут создавать новые области связи на базе существующих. Все области связи имеют независимую друг от друга нумерацию процессов. Программе пользователя в распоряжение предоставляется коммуникатор - описатель области связи. В исходных текстах примеров для MPI часто используется идентификатор MPI_COMM_WORLD. Это название коммуникатора, создаваемого библиотекой автоматически. Он описывает стартовую область связи, объединяющую все процессы приложения. Вариант №9 Задание: Требуется вычислить сумму числового ряда: 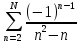 В распоряжении - МВС с P процессорами (ядрами). Создать параллельную версию написанной ранее программы вычисления суммы ряда с использованием базовых функций MPI. В программе предусмотреть следующее: Ввод-вывод данных должен осуществляться только через нулевой процесс, который рассылает остальным процессам число членов ряда, введенное через аргумент командной строки. Перед рассылкой фиксируется время начала выполнения параллельного участка программы. Каждый процесс определяет количество членов, которое он суммирует. Для этого вычисляется 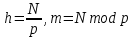 Если остаток равен нулю, то каждый процесс суммирует одинаковое количество членов ряда. Если количество членов ряда не кратно числу процессов, то остаток от деления равномерно распределяется между всеми процессами. Каждый процесс считает сумму, отведенной ему части ряда, и после окончания расчета пересылает ее нулевому процессу. д) Нулевой процесс находит искомую сумму, как сумму своей частичной суммы и всех присланных. Фиксируется время окончания параллельного участка программы и результаты выводятся на экран (сумма ряда и затраченное время). Описание скрипта/программы/конфигурационного файла: Выберем 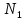 и и 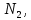 чтобы время работы программы при чтобы время работы программы при 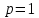 составляло порядка 150 и 300 секунд соответственно. Время работы параллельного участка кода занесем в таблицу: составляло порядка 150 и 300 секунд соответственно. Время работы параллельного участка кода занесем в таблицу:
Вычислим ускорение и эффективность при использовании p процессов по следующим формулам: 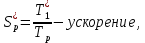 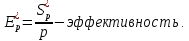 Построим графики зависимостей ускорения и эффективности от числа процессов при различном числе членов ряда.
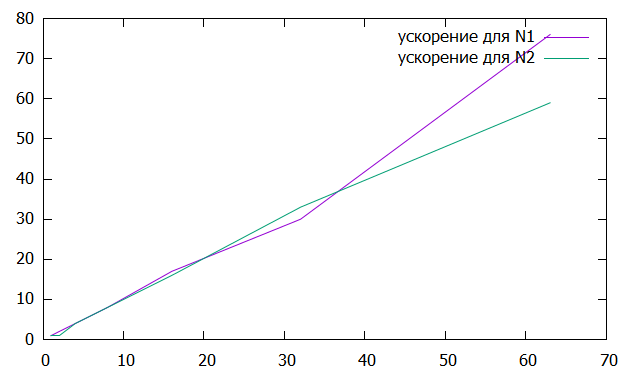 Рисунок 1 – График зависимости ускорения от числа процессов 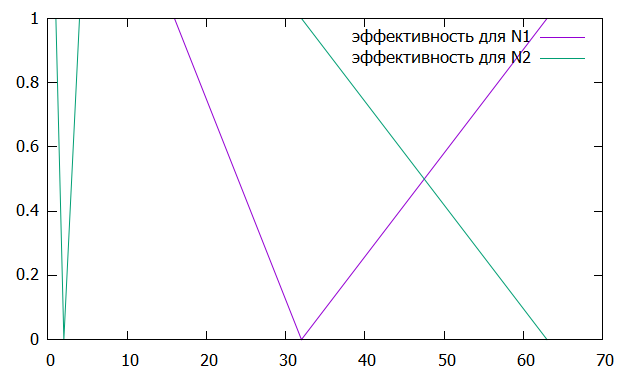 Рисунок 2 – График зависимости эффективности от числа процессов Из рисунков можно заметить, что ускорение увеличивается, а эффективность иногда падает. Вывод: В ходе лабораторной работы для многопроцессорных вычислительных систем с распределенной памятью на примере задачи параллельного вычисления суммы числового ряда были программно реализованы простейшие параллельные вычислительные алгоритмы и проведены анализы их эффективности. Было выявлено что чем больше количество процессов, тем быстрее работает программа. Приложение 1 #include "mpi.h" #include #include #include double function(unsigned long long n) { return pow(-1.0, (double)n - 1.0) / ((double)n * (double)n - (double)n); } int main(int argc, char* argv[]) { int MyID, NumProc, ierror; double tstart, tfinish; MPI_Status status; ierror = MPI_Init(&argc, &argv); if (ierror != MPI_SUCCESS) { printf("MPI initialization error!\n"); } MPI_Comm_size(MPI_COMM_WORLD, &NumProc); MPI_Comm_rank(MPI_COMM_WORLD, &MyID); unsigned long long N; unsigned long long h, m; if (MyID == 0) { N = atoll(argv[1]); } MPI_Barrier(MPI_COMM_WORLD); tstart = MPI_Wtime(); if (MyID == 0) { for (int i = 1; i < NumProc; i++) { MPI_Send(&N, 1, MPI_UNSIGNED_LONG_LONG, i, i + 777, MPI_COMM_WORLD); } } if (MyID > 0) { MPI_Recv(&N, 1, MPI_UNSIGNED_LONG_LONG, 0, MyID + 777, MPI_COMM_WORLD, &status); } h = (N - 1) / NumProc; m = (N - 1) % NumProc; double sum = 0.0; double result = 0.0; for (unsigned long long k = 0; k < h; k++) { sum += function(k * NumProc + MyID + 2); } if (MyID < m) { sum += function(h * NumProc + MyID + 2); } if (MyID == 0) { result += sum; for (int i = 1; i < NumProc; i++) { MPI_Recv(&sum, 1, MPI_DOUBLE, i, i + 1554, MPI_COMM_WORLD, &status); result += sum; } } if (MyID > 0) { MPI_Send(&sum, 1, MPI_DOUBLE, 0, MyID + 1554, MPI_COMM_WORLD); } MPI_Barrier(MPI_COMM_WORLD); tfinish = MPI_Wtime() - tstart; if (MyID == 0) { fprintf(stdout, "Sum: %lf\n", result); fprintf(stdout, "Time: %lf\n", tfinish); } MPI_Finalize(); return 0; } | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
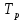 , c
, c