Формальное определение цепочки символов в алфавите
V:
- цепочка в алфавите V;
если - цепочка в алфавитеV и а – символ этого алфавита, то а – цепочка в алфавите V;
- цепочка в алфавите V тогда и только тогда, когда она является таковой в силу утверждений 1) и 2).
Длиной цепочки
называется число составляющих ее символов (обозначается
||).
Конкатенацией (сцеплением) цепочек
и
называется цепочка
=
, в которой символы данных цепочек записаны друг за другом.
Для любой цепочки
справедливо утверждение
=
.
Степенью
n цепочки
называется конкатенация
n цепочек
(обозначается:
n).
Для любой цепочки
справедливы утверждения
0=
и
n=
n-1=
n-1 для
n1.
Реверсом (обращением) цепочки
называется цепочка
R,составленная из символов цепочки
, записанных в обратном порядке.
Пример 1. Пусть алфавит
V={
a,
b,
c,
d}, тогда для цепочек этого алфавита
=
abи
=
bcdбудет справедливо
||=2,
||=3,
=
abbcd,
2=
abab,
R=
dcb.
Обозначим через
V* множество, содержащее все цепочки в алфавите
V, включая пустую цепочку
, а через
V+ - множество, содержащее все цепочки в алфавите
V, исключая пустую цепочку
.
Формальным языком
L в алфавите
V называют некоторое подмножество множества
V*.
Пример 2. Пусть задан алфавит двоичных цифр
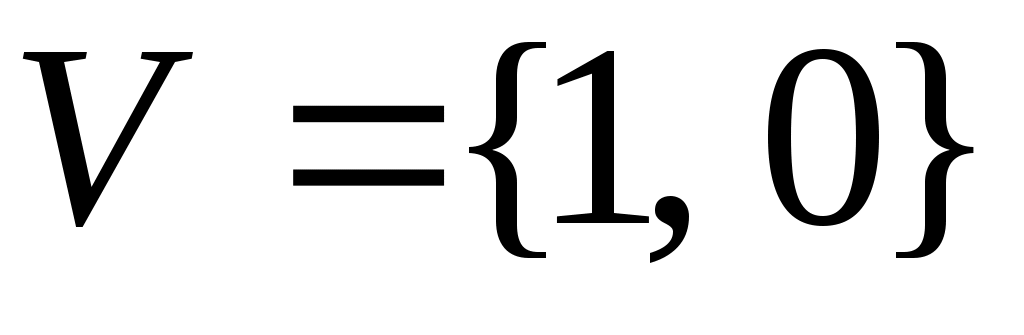
, тогда
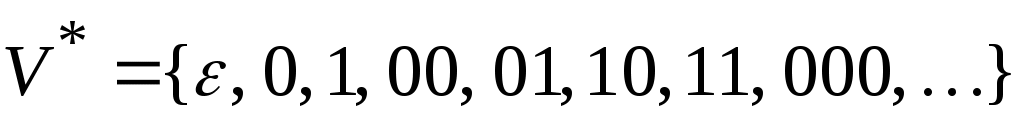
, а
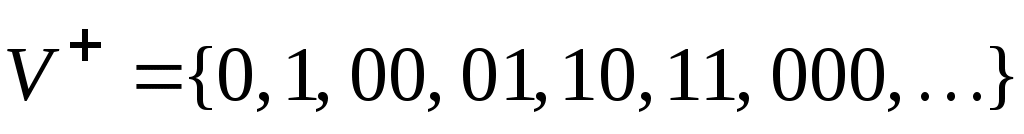
.
Задать язык
L в алфавите
V можно тремя способами:
перечислением всех допустимых цепочек языка (на языке множеств);
указанием способа порождения (генерации) цепочек языка (грамматики, формы Бэкуса-Наура и диаграммы Вирта);
определением метода распознавания цепочек языка (распознаватели).
Пример 3. Язык
Lв алфавите
, состоящий из пустой строки и всевозможных строк, каждая из которых содержит строку нулей и последующую строку единиц той же длины, можно описать с помощью формальной системы определения множеств как
L={0
n1
n |
n0}.
Формальная грамматика – это математическая система, определяющая язык посредством порождающих правил.
Формальной грамматикой называется четверка вида:
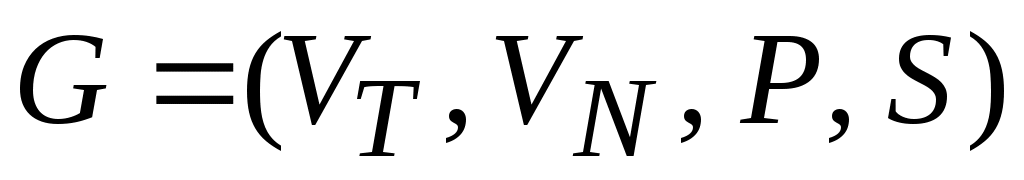
,
где
VN- конечное множество нетерминальных символов грамматики (обычно прописные латинские буквы);
VT - множество терминальных символов грамматики (обычно строчные латинские буквы, цифры и т.п.),
VT
VN =;
Р - множество правил вывода грамматики, являющееся конечным подмножеством множества (
VT
VN)
+ (
VT
VN)
*; элемент (
, ) множества
Р называется правилом вывода и записывается в виде
(читается: «из цепочки
выводится цепочка
»);
S - начальный символ грамматики,
S
VN.
Для записи правил вывода с одинаковыми левыми частями вида
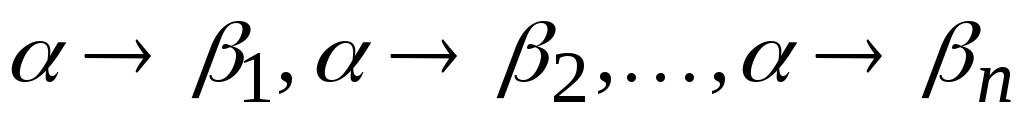
используется сокращенная форма записи
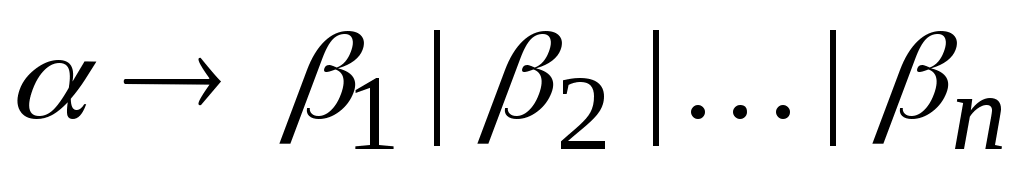
.
Грамматика
G1=({0, 1}, {
A,
S},
P1,
S), где множество
Р состоит из правил вида: 1)
S0
A1; 2)0
A00
A1;3)
A
.Цепочка
(
VT
VN)
* непосредственно выводима из цепочки
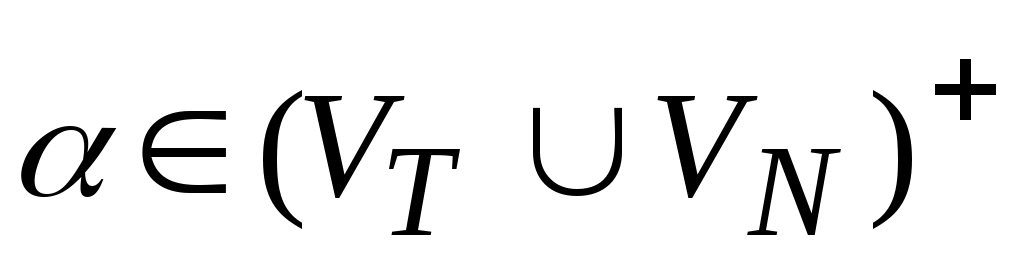
в грамматике
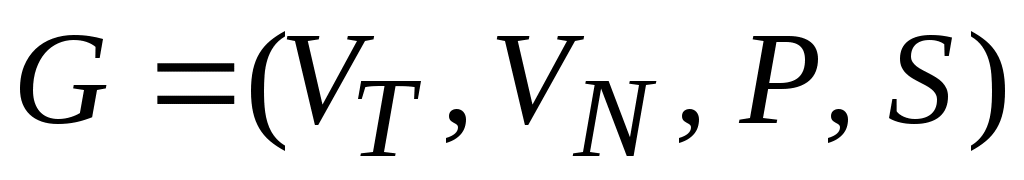
(обозначается:
), если
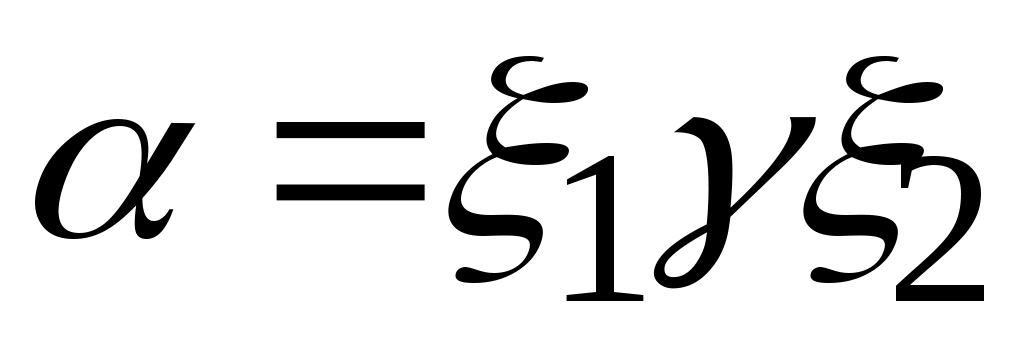
и
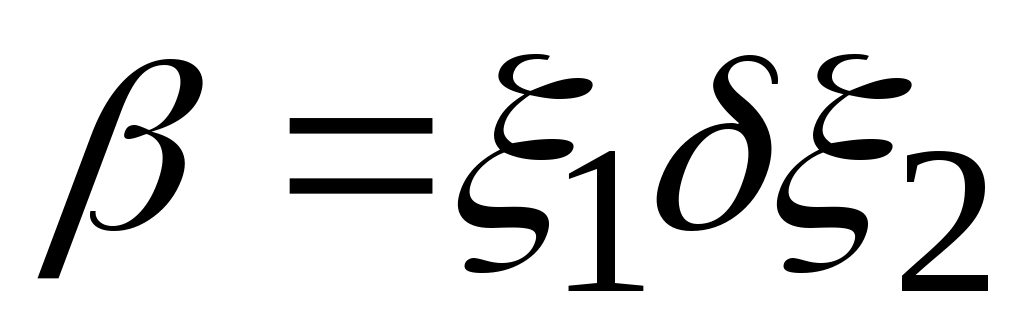
, где
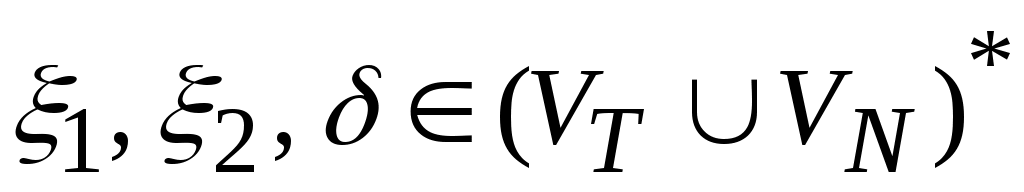
,
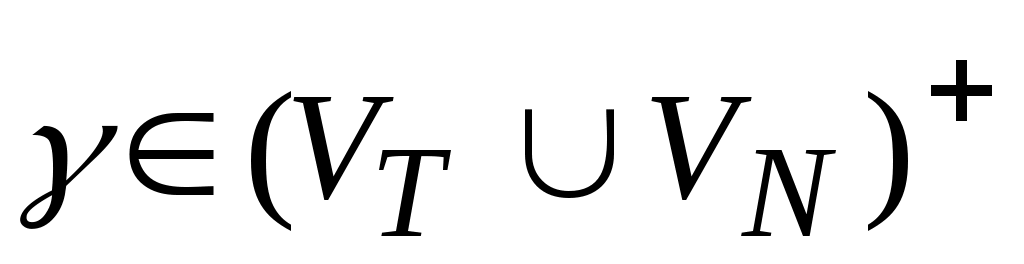
и правило вывода
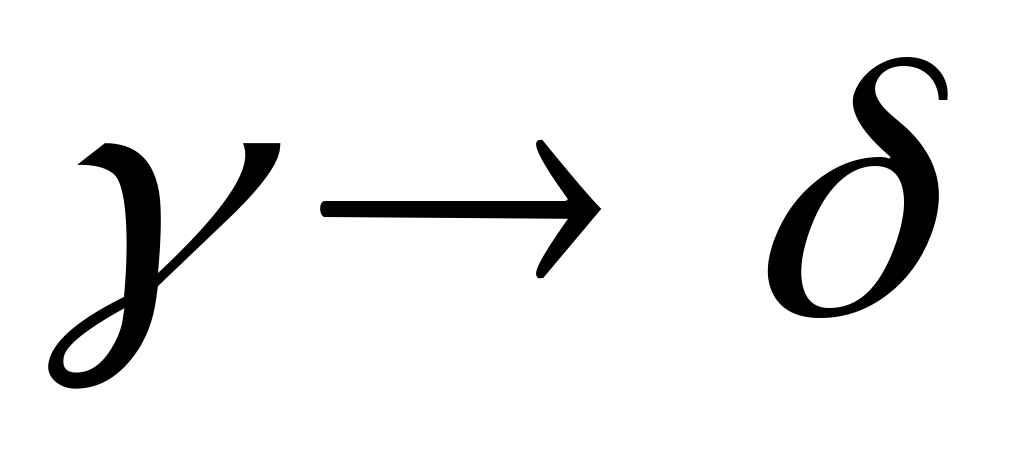
содержится во множестве
Р.
Цепочка
(
VT
VN)
* выводима из цепочки
в грамматике
(обозначается
*
), если существует последовательность цепочек
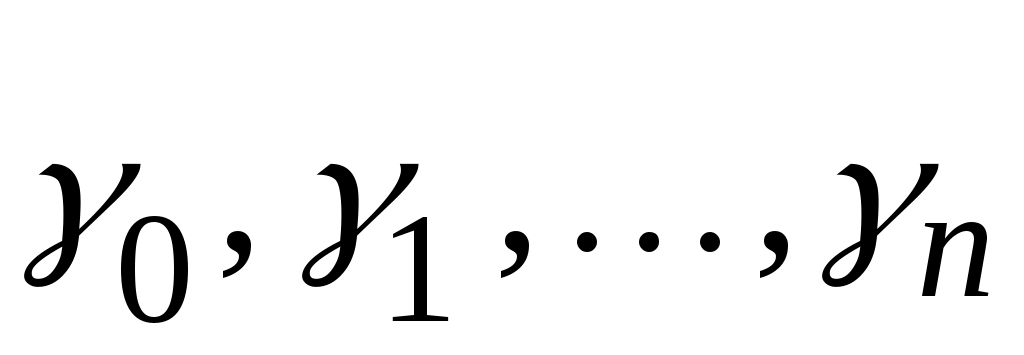
(
n0) такая, что
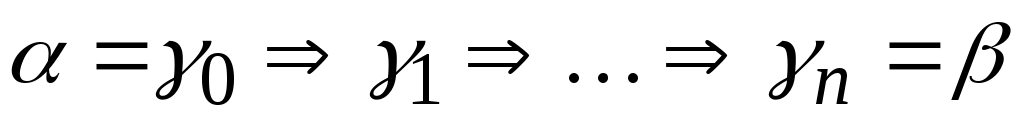
.
В грамматике
G1 S*000111, т.к. существует вывод
S0
A100
A11000
A111000111.
Языком, порожденным грамматикой
, называется множество всех цепочек в алфавите
VT, которые выводимы из начального символа грамматики
S c помощью правил множества
Р, т.е. множество

.
Для грамматики
G1 язык
L(
G1)
={0
n1
n |
n>0}.
Цепочка 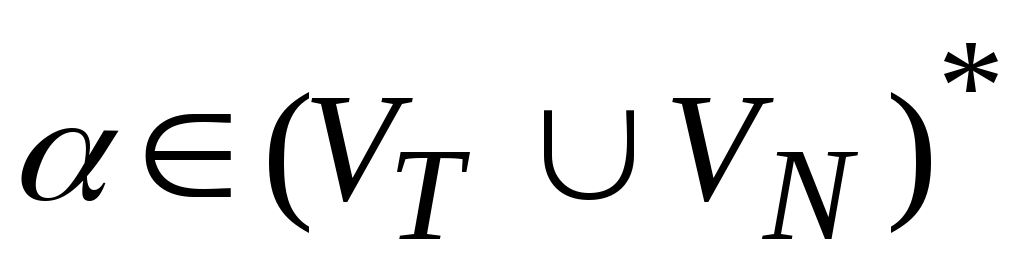 , для которой существует вывод S*, называется сентенциальной формой или сентенцией в грамматике .
, для которой существует вывод S*, называется сентенциальной формой или сентенцией в грамматике .
Языком, порожденным грамматикой
G называется множество терминальных сентенциальных форм грамматики.
Классификация грамматик в иерархии американского математика Хомского осуществляется по структуре правил вывода. В расширенной иерархии Хомского выделяется четыре типа грамматик.
Тип 0. Грамматика называется грамматикой типа 0 (грамматикой без ограничений или грамматикой с фразовой структурой), если на ее правила вывода не наложено никаких ограничений, кроме тех, которые указаны в определении грамматики.
Тип 1. Грамматика
называется контекстно-зависимой грамматикой (КЗ-грамматикой), если каждое правило вывода из множества
Р имеет вид
, где
(
VT
VN)
+,
(
VT
VN)
* и |
| |
|. Расширение допускает не более одного
-правила, т.е. правила вида
А
,
А
VN.
Тип 2. Грамматика
называется контекстно-свободной грамматикой (КС-грамматикой), если ее правила вывода имеют вид:

, где

и
 Тип 3.
Тип 3. Грамматика

называется регулярной грамматикой (Р-грамматикой) выровненной вправо, если ее правила вывода имеют вид
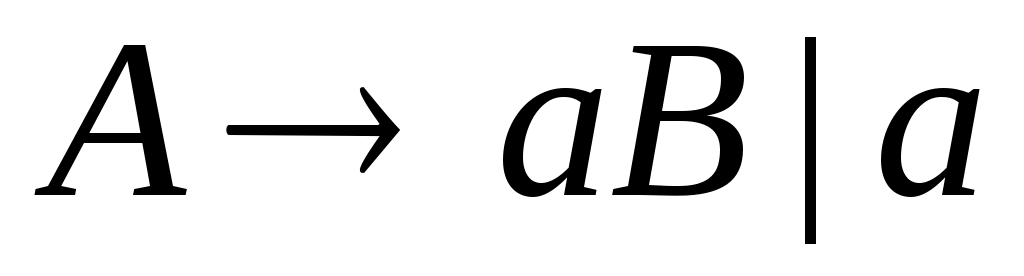
, где

.
Грамматика
называется регулярной грамматикой (Р-грамматикой) выровненной влево, если ее правила вывода имеют вид
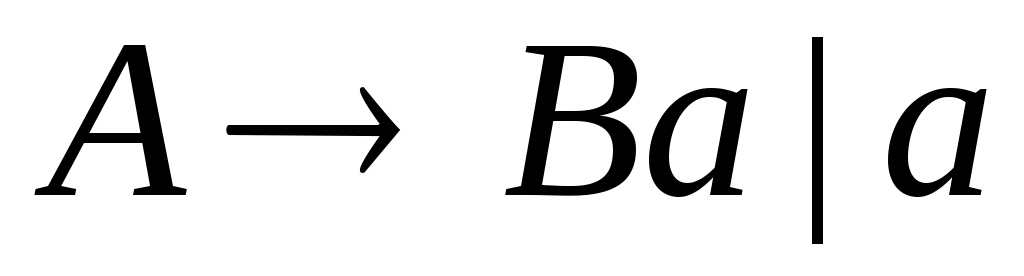
, где
.
Расширение допускает единственное -правило вида S, но в этом случае начальный символ грамматики S не должен встречаться в правых частях правил.
Язык
L(
G) называется языком типа
k, если его можно описать грамматикой типа
k, где
k – максимально возможный номер типа грамматики.
Язык вида
L={0
n1
n |
n>0} порождается КЗ-грамматикой (тип 1)
G1 (пример 1.4) и КС-грамматикой (тип 2)
G2= ({0, 1}, {
S},
P2,
S), где
множество правил вывода
P2 содержит правила вида
S 0
S1|01.
Так как не существует регулярной грамматики (тип 3), порождающей данный язык, то язык
L является языком типа 2 или КС-языком.
Примеры различных типов формальных языков и грамматик по классификации Хомского. Терминалы будем обозначать строчными символами, нетерминалы – прописными буквами, начальный символ грамматики – S.
а) Язык типа 0
L(
G)=
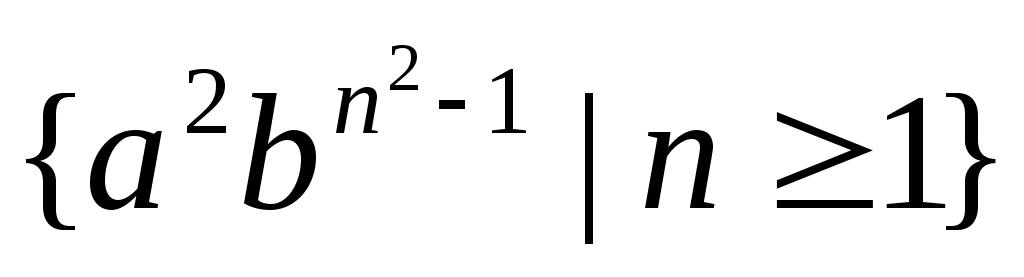
определяется грамматикой с правилами вывода:
1)
S
aaCFD; 2)
AD
D;
3)
F
AFB | AB;4)
Cb
bC;
5)
AB
bBA;6)
CB
C;
7)
Ab
bA;8)
bCD
.
б) Контекстно-зависимый язык
L(
G)={
anbncn |
n1} определяется грамматикой с правилами вывода:
1)
S
aSBC | aBC;2)
CB
BC;
3) aB ab; 4) bB bb;
5)
bC
bc;6)
cC
cc.
в) Контекстно-свободный язык
L(
G)={(
aс)
n(
cb)
n |
n>0} определяется грамматикой с правилами вывода:
1)
S
aQb | accb;
2)
Q
cSc.
г) Регулярный язык
L(
G)={
|
{
a, b}
+, где нет двух рядом стоящих а} определяется грамматикой с правилами вывода:
1)
S
A
| B;
2)
A
a | Ba;
3)
B
b | Bb | Ab.
Грамматики
G1 и
G2 называются эквивалентными, если они определяют один и тот же язык, т.е.
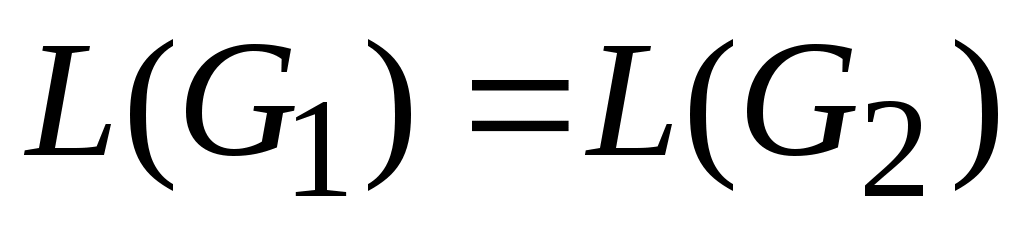
.
Грамматики
G1 и
G2 называются почти эквивалентными, если заданные ими языки различаются не более чем на пустую цепочку символов, т.е.
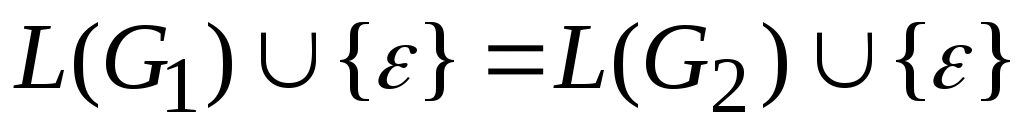
.
Для грамматики
G1 эквивалентной будет грамматика
G2 = ({0, 1}, {
S},
P3,
S), где
P2:
S 0
S1|01, т.к.
L(
G1)=
L(
G2)={0
n1
n |
n>0} (пример 1.7).
Почти эквивалентной для грамматики G1 будет грамматика G3 = ({0, 1}, {S}, P3, S), где множество правил вывода P3 содержит правила вида S 0S1 | , т.к. L(G3)= {0n1n | n0}.
Цепочки языка могут содержать метасимволы, имеющие особое назначение. Метаязык, предложенный Бэкусом и Науром (БНФ) использует следующие обозначения:
символ «::=» отделяет левую часть правила от правой (читается: «определяется как»);
нетерминалы обозначаются произвольной символьной строкой, заключенной в угловые скобки «<» и «>»;
терминалы - это символы, используемые в описываемом языке;
правило может определять порождение нескольких альтернативных цепочек, отделяемых друг от друга символом вертикальной черты «|» (читается: «или»).
Для повышения удобства и компактности описаний, в расширенных БНФ вводятся следующие дополнительные конструкции (метасимволы):
квадратные скобки «[» и «]» означают, что заключенная в них синтаксическая конструкция может отсутствовать;
фигурные скобки «{» и «}» означают повторение заключенной в них синтаксической конструкции ноль или более раз;
сочетание фигурных скобок и косой черты «{/» и «/}» используется для обозначения повторения один и более раз;
круглые скобки «(» и «)» используются для ограничения альтернативных конструкций;
кавычки используются в тех случаях, когда один из метасимволов нужно включить в цепочку обычным образом.
В метаязыке диаграмм Вирта используются графические примитивы.
При построении диаграмм учитывают следующие правила:
каждый графический элемент, соответствующий терминалу или нетерминалу, имеет по одному входу и выходу, которые обычно изображаются на противоположных сторонах;
каждому правилу соответствует своя графическая диаграмма, на которой терминалы и нетерминалы соединяются посредством дуг;
альтернативы в правилах задаются ветвлением дуг, а итерации - их слиянием;
должна быть одна входная дуга (располагается обычно слева или сверху), задающая начало правила и помеченная именем определяемого нетерминала, и одна выходная, задающая его конец (обычно располагается справа или снизу);
стрелки на дугах диаграмм обычно не ставятся, а направления связей отслеживаются движением от начальной дуги в соответствии с плавными изгибами промежуточных дуг и ветвлений.
 Скачать 1.59 Mb.
Скачать 1.59 Mb.