Разработка компилятора модельного языка. Отчет. Пояснительная записка гоу огу 230105. 60. 11. 06 O руководитель работы Ишакова Е. Н. " " 2011г. Исполнитель
 Скачать 1.59 Mb. Скачать 1.59 Mb.
|

Операции языка:<операции_группы_отношения>:: = < > | = | < | <= | > | >= <операции_группы_сложения>:: = + | - | or <операции_группы_умножения>::= * | / | and <унарная_операция>::= not Выражения языка задаются правилами: <выражение>::= <операнд>{<операции_группы_отношения> <операнд>} <операнд>::= <слагаемое> {<операции_группы_сложения> <слагаемое>} <слагаемое>::= <множитель> {<операции_группы_умножения> <множитель>} <множитель>::= <идентификатор> | <число> | <логическая_константа> <унарная_операция> <множитель> | «(»<выражение>«)» <число>::= <целое> | <действительное> <логическая_константа>::= true | false Правила, определяющие идентификатор, букву и цифру:<идентификатор>::= <буква> {<буква> | <цифра>} <буква>::= A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T |U | V | W | X | Y | Z | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z <цифра>::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 Правила, определяющие целые числа: <целое>::= <двоичное> | <восьмеричное> | <десятичное> | <шестнадцатеричное> <двоичное>::= {/ 0 | 1 /} (B | b) <восьмеричное>::= {/ 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 /} (O | o) <десятичное>::= {/ <цифра> /} [D | d] <шестнадцатеричное>::= <цифра> {<цифра> | A | B | C | D | E | F | a | b | c | d | e | f} (H | h) Правила, описывающие действительные числа: <действительное>::= <числовая_строка> <порядок> | [<числовая_строка>] . <числовая_строка> [порядок] <числовая_строка>::= {/ <цифра> /} <порядок>::= ( E | e )[+ | -] <числовая_строка> <программа>::= «{» {/ (<описание> | <оператор>) ; /} «}» <описание>::= {<идентификатор> {, <идентификатор> } : <тип> ;} <тип>::= integer | real | Boolean Правило, определяющее оператор программы (пятая цифра варианта).<оператор>::= <составной> | <присваивания> | <условный> | <фиксированного_цикла> | <условного_цикла> | <ввода> | <вывода> <составной>::= “[“<оператор> { ( : | перевод строки) <оператор> }”]” <присваивания>::= <идентификатор> as <выражение> <условный>::= if <выражение> then <оператор> [ else <оператор>] <фиксированного_цикла>::= for <присваивания> to <выражение> do <оператор> <условного_цикла>::= while <выражение> do <оператор> <ввода>::= read «(»<идентификатор> {, <идентификатор> } «)» <вывода>::= write «(»<выражение> {, <выражение> } «)» Признак начала комментария /* Признак конца комментария */ 2.2 Формальные грамматики Опишем синтаксис модельного языка М с помощью формальных грамматик. Грамматика будет иметь правила вывода вида. P1 { Prog1; } Prog1 Prog2 | Prog1 ; Prog2 Prog2 Opis1 | Oper1 Opis1 Ident1 Type1 Type1 integer | real | Boolean Ident Buk | IdentBuk|IdentNum Ident1Ident|Ident1,Ident Buk a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z Num 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 Oper1 Sost | Pris | Uslov | FixC | UslovC | Input | Output Sost [ Sost1 ] Sost1 Oper1|Sost1:Oper1|Sost1←┘Oper1 Pris Idenr as Viraj Uslov if Viraj then Oper1 | if Viraj then Oper1 else Oper1 FixC for Pris to Viraj do Oper1 UslovC while Virag do Oper1 Input read ( Ident1 ) Output write ( Viraj1 ) Viraj1 Viraj | Viraj1,Viraj Viraj Opernd | Viraj Otnosh Opernd Otnosh <> | = | < | <= | > | >= Opernd Slag | Opernd Slojenie Slag Slag Mnojit | Slag Umnoj Mnojit Mnojit Ident | Chislo | LogConst Unarop Mnojit | ( Viraj ) Chislo Celoe | Deist LogConst true | false Slojenie + | - | or Umnoj * | / | and Unarop not Celoe Bin | Oct | Dec | Hex Bin Bin1B | Bin1b Bin1 0 | 1 | 0Bin1 | 1Bin1 Oct Oct1O | Oct1o Oct1 Oct2 | Oct1Oct2 Oct2 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 Dec Dec1D | Dec1d Dec1 Num | Dec1Num Hex NumHex1H | NumHex1h Hex1 Hex2 | Hex1Hex2 Hex2 Num | A | B | C | D | E | F | a | b | c | d | e | f Nustr Num | NustrNum Deist Nustr Porad | Nustr.Nustr Porad | Nustr Porad | Nustr.Nustr | .Nustr Porad E Nustr | E+Nustr | e+Nustr | E-Nustr | e-Nustr 2.3 Диаграммы Вирта Описание синтаксиса модельного языка М с помощью диаграмм Вирта представлено на рисунке 1. 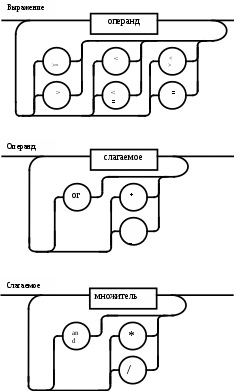 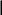   целое 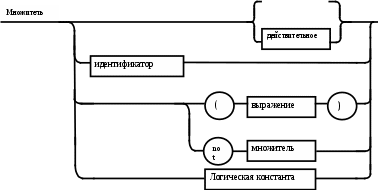 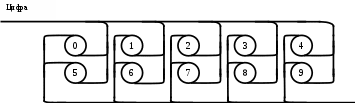 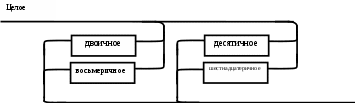  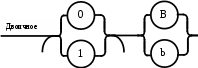 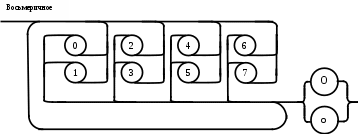 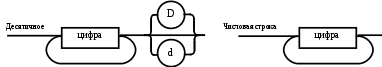 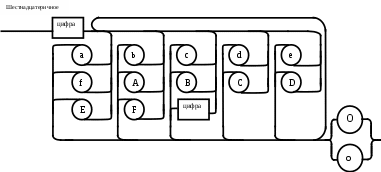  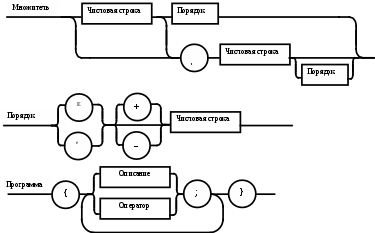  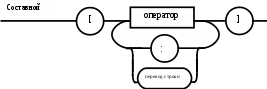 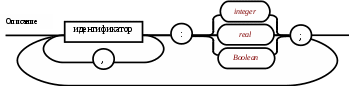 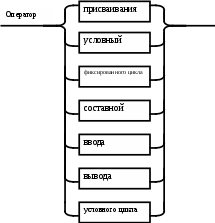      выражение оператор оператор    Условный    присваивания выражение  оператор Фиксированного цикла   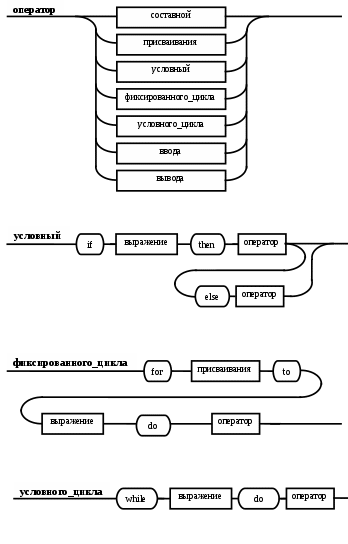 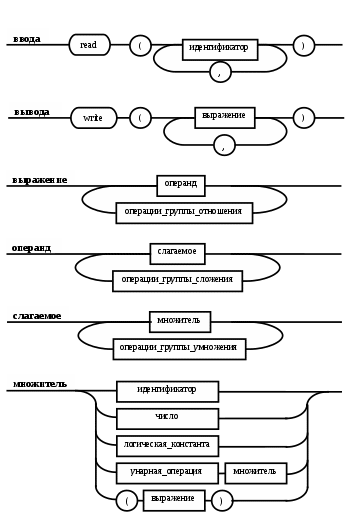 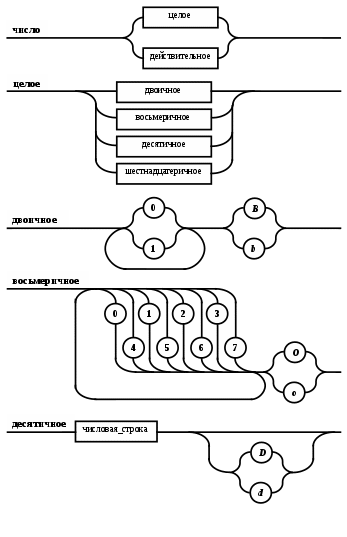 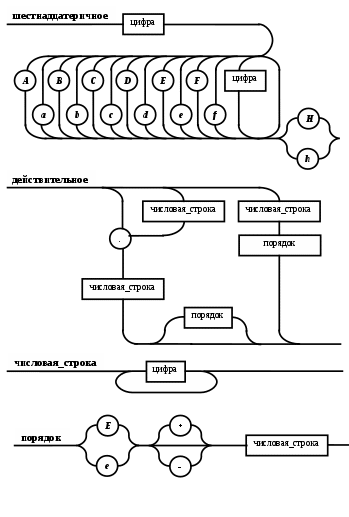 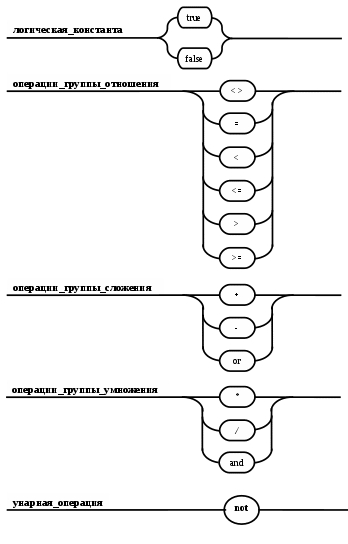 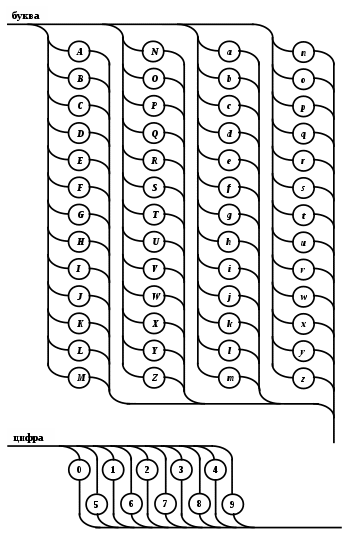 3 Спецификация основных процедур и функций 3.1 Лексический анализатор Лексический анализатор (ЛА) – это первый этап процесса компиляции, на котором символы, составляющие исходную программу, группируются в отдельные минимальные единицы текста, несущие смысловую нагрузку – лексемы. Задача лексического анализа - выделить лексемы и преобразовать их к виду, удобному для последующей обработки. ЛА использует регулярные грамматики. ЛА необязательный этап компиляции, но желательный по следующим причинам: 1) замена идентификаторов, констант, ограничителей и служебных слов лексемами делает программу более удобной для дальнейшей обработки; 2) ЛА уменьшает длину программы, устраняя из ее исходного представления несущественные пробелы и комментарии; 3) если будет изменена кодировка в исходном представлении программы, то это отразится только на ЛА. В процедурных языках лексемы обычно делятся на классы: служебные слова; ограничители; числа; идентификаторы. Каждая лексема представляет собой пару чисел вида (n, k), где n – номер таблицы лексем, k - номер лексемы в таблице. Входные данные ЛА - текст транслируемой программы на входном языке. Выходные данные ЛА - списковая структура, содержащая лексемы в числовом представлении. Для модельного языка М таблица служебных слов 1: 1. if 2. then 3. else 4. for 5. to 6. do 7. true 8. false 9. while 10. read 11. write 12. and 13. not 14. real 15. boolean 16. integer 17. as 18. or Таблица ограничителей 2: 1. ; 2. { 3. } 4. , 5. ( 6. ) 7. : 8. \n 9. . 10. /* 11. */ 12. <> 13. = 14. < 15. <= 16. > 17. >= 18. + 19. - 20. * 21. / Таблицы идентификаторов (3), целых чисел (4) и вещественных чисел (5) формируются в ходе лексического анализа. Опишем результаты работы лексического анализатора для модельного языка М. Входные данные ЛА: { i,n,f:integer; read(n); } Выходные данные ЛА: (2;2)(3;1)(2;4)(3;2)(2;4)(3;3)(2;7)(1;16)(2;1)(1;10)(2,5)(3;2)(2,6)(2;1)(2;3) Анализ текста проводится путем разбора по регулярным грамматикам и опирается на способ разбора по диаграмме состояний, снабженной дополнительными пометками-действиями. Смысл конструкции: если текущим является состояние А и очередной входной символ совпадает с Для удобства разбора вводится дополнительное состояние диаграммы ER, попадание в которое соответствует появлению ошибки в алгоритме разбора. Переход по дуге, не помеченной ни одним символом, осуществляется по любому другому символу, кроме тех, которыми помечены все другие дуги, выходящие из данного состояния. Алгоритм. Разбор цепочек символов по ДС с действиями Шаг 1. Объявляем текущим начальное состояние в диаграмме состояний H. Шаг 2. До тех пор, пока не будет достигнуто состояние ER или конечное состояние диаграммы состояний, считываем очередной символ анализируемой строки и переходим из текущего состояния диаграммы состояний в другое по дуге, помеченной этим символом, выполняя при этом соответствующие действия. Состояние, в которое попадаем, становится текущим. Таблица 3 - Спецификация основных процедур и функций лексического анализатора
Диаграмма состояний с действиями для модельного языка 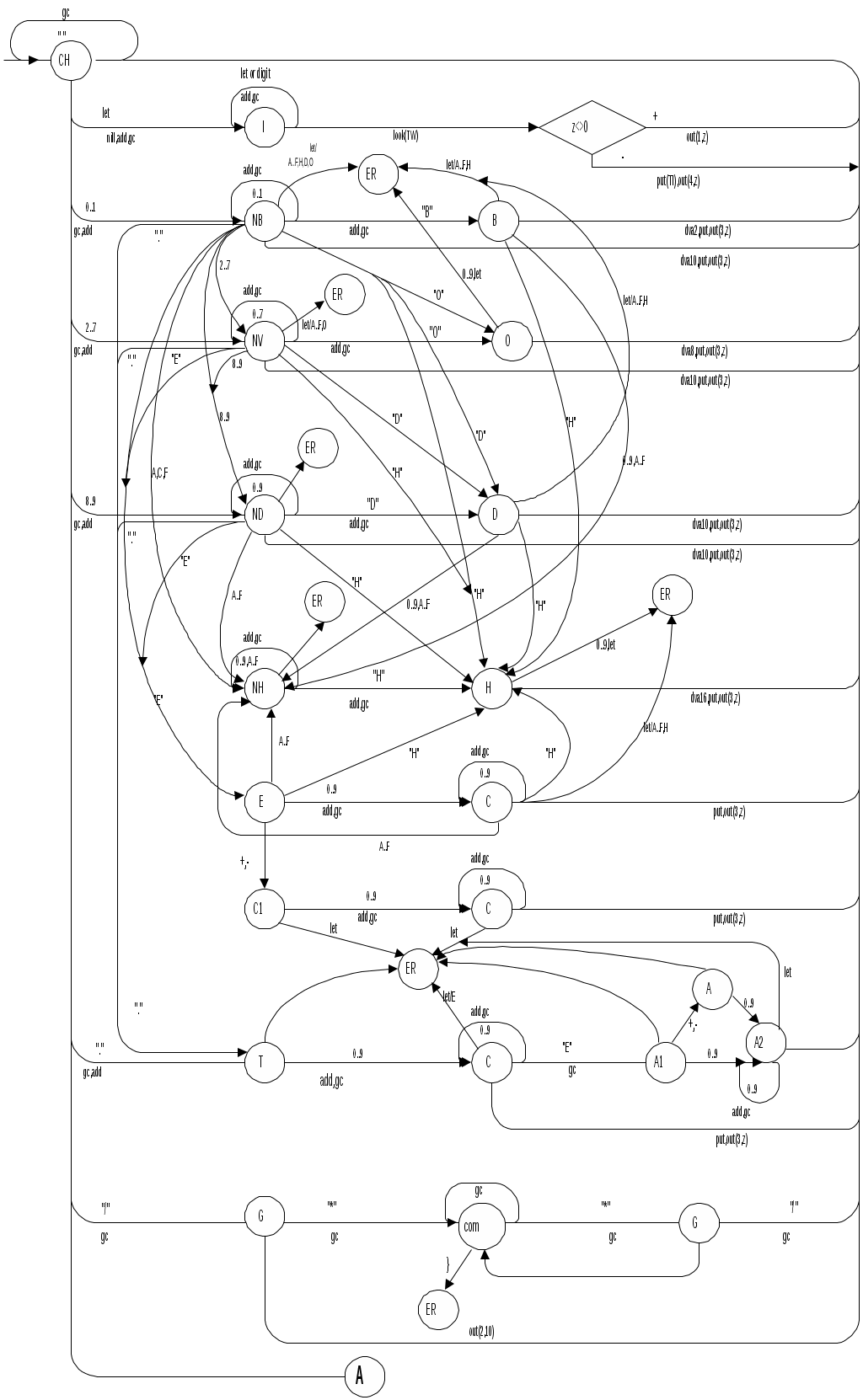 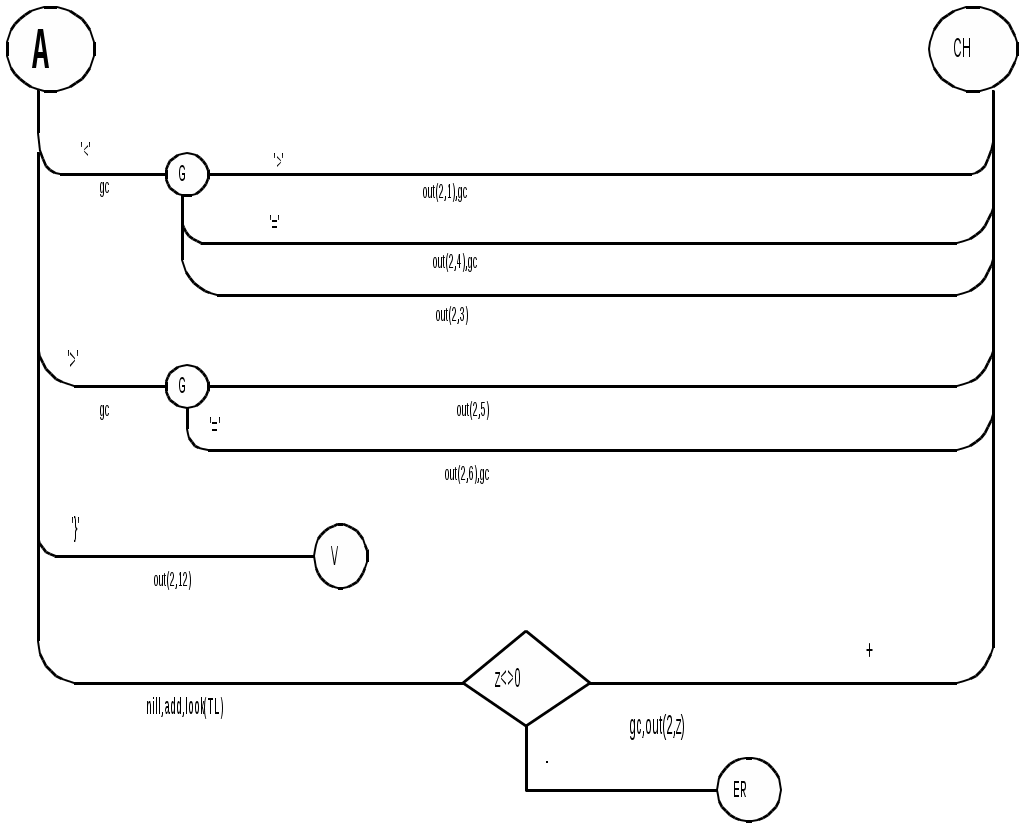 Рисунок 1 – Диаграмма состояний с действиями для модельного языка М 3.2 Синтаксический анализатор Задача синтаксического анализатора - провести разбор текста программы, сопоставив его с эталоном, данным в описании языка. Для синтаксического разбора используются контекстно-свободные грамматики (КС-грамматики). Один из эффективных методов синтаксического анализа – метод рекурсивного спуска. В основе метода рекурсивного спуска лежит левосторонний разбор строки языка. Исходной сентенциальной формой является начальный символ грамматики, а целевой – заданная строка языка. На каждом шаге разбора правило грамматики применяется к самому левому нетерминалу сентенции. Данный процесс соответствует построению дерева разбора цепочки сверху вниз (от корня к листьям). Метод рекурсивного спуска реализует разбор цепочки сверху вниз следующим образом. Для каждого нетерминального символа грамматики создается своя процедура, носящая его имя. Задача этой процедуры – начиная с указанного места исходной цепочки, найти подцепочку, которая выводится из этого нетерминала. Если такую подцепочку считать не удается, то процедура завершает свою работу вызовом процедуры обработки ошибок, которая выдает сообщение о том, что цепочка не принадлежит языку грамматики и останавливает разбор. Если подцепочку удалось найти, то работа процедуры считается нормально завершенной и осуществляется возврат в точку вызова. Тело каждой такой процедуры составляется непосредственно по правилам вывода соответствующего нетерминала, при этом терминалы распознаются самой процедурой, а нетерминалам соответствуют вызовы процедур, носящих их имена. Входные данные – файл лексем в числовом представлении. Выходные данные – заключение о синтаксической правильности программы или сообщение об имеющихся ошибках. Таблица 4 - Спецификация основных процедур и функций синтаксического анализатора
3.3 Семантический анализатор В ходе семантического анализа проверяются отдельные правила записи исходных программ, которые не описываются КС-грамматикой. Эти правила носят контекстно-зависимый характер, их называют семантическими соглашениями или контекстными условиями. Рассмотрим пример построения семантического анализатора для программы на модельном языке М. Соблюдение контекстных условий для языка М предполагает три типа проверок: 1) обработка описаний; 2) анализ выражений; 3) проверка правильности операторов. В оптимизированном варианте синтаксический и семантический анализаторы совмещены и осуществляются параллельно. Поэтому процедуры семантического анализатора будем внедрять в ранее разработанные процедуры синтаксического анализатора. Вход: файл лексем в числовом представлении. Выход: заключение о семантической правильности программы или о типе обнаруженной семантической ошибки. Обработка описаний. Задача обработки описаний – проверить, все ли переменные программы описаны правильно и только один раз. Таблица идентификаторов, введенная на этапе лексического анализа, расширяется, приобретая вид таблицы 1. Анализ выражений. Задача анализа выражений – проверить описаны ли переменные, встречающиеся в выражениях, и соответствуют ли типы операндов друг другу и типу операции. Эти задачи решаются следующим образом. Вводится таблица двуместных операций (таблица 2) и стек, в который в соответствии с разбором выражения B заносятся типы операндов и знак операции. После семантической проверки в стеке оставляется только тип результата операции. В результате разбора всего выражения в стеке остается тип этого выражения. Проверка правильности операторов Задачи проверки правильности операторов: 1) выяснить, все ли переменные, встречающиеся в операторах, описаны; 2) установить соответствие типов в операторе присваивания слева и справа от символа «as»; 3) определить, является ли выражение E в операторах условия и цикла булевым. Задача решается проверкой типов в соответствующих местах программы. Таблица 5 - Спецификация основных процедур и функций семантического анализатора
3.4 Генерации внутреннего представления программы В ПОЛИЗе операнды записаны слева направо в порядке использования. Знаки операций следуют таким образом, что знаку операции непосредственно предшествуют его операнды. Пример 1: Для выражения в обычной (инфиксной записи) a*(b+c)-(d-e)/f ПОЛИЗ будет иметь вид: abc+*de-f/-. Справедливы следующие формальные определения. Определение: Если B является единственным операндом, то ПОЛИЗ выражения B – это этот операнд. Определение: ПОЛИЗ выражения B1 B2, где - знак бинарной операции, B1 и B2 – операнды для , является запись Определение: ПОЛИЗ выражения B, где - знак унарной операции, а B – операнд , есть запись Определение: ПОЛИЗ выражения (B) есть ПОЛИЗ выражения B. |