Практическая работа 1. 2 Описание проектирования базы данных 2 практическая работа 2 10
 Скачать 2.52 Mb. Скачать 2.52 Mb.
|

|
Часть 1. Создание таблиц 3.4. Теоретические сведения 3.4.1. Логическая структура и физическая реализация баз данных MS SQL Server Данные в сервере SQL Server хранятся в базах данных. Структуру баз данных необходимо рассматривать на двух уровнях: логическом и физическом. Логическая структура базы данных определяет структуру таблиц, взаимосвязи между ними, список пользователей, хранимые процедуры, правила, умолчания и другие объекты базы данных. Физическая структура базы данных включает в себя описание файлов и групп файлов базы данных, журнала транзакций, первоначальный размер файлов, шаг прироста базы данных, ее максимальный размер, параметры конфигурации и другие физические характеристики. Все логические компоненты базы данных SQL Server называются объектами и подразделяются на 11 типов. Для объектов можно устанавливать различные правила доступа со стороны пользователей. Функциональное назначение объектов базы данных сервера SQL Server можно кратко определить следующим образом: Table - таблица, представляющая собой матрицу из строк и столбцов. Каждая строка (или запись) состоит из значений атрибутов конкретного объекта. Столбец (или поле записи) содержит совокупность атрибутов рассматриваемых объектов некоторой предметной области. Некоторые столбцы таблицы могут быть вычисляемыми. В этих случаях для них задается расчетная формула. User-defined data type - пользовательский тип данных, создаваемый на основе системных. Имя нового типа должно быть уникальным в пределах владельца. 3.View - представление, являющееся виртуальной таблицей, содержимое которой определяется запросом. Эта таблица не содержит данных, а только их представляет, возможно из нескольких таблиц. Данные из представления не сохраняются в базе данных. Физически представление реализуется в виде запроса SELECT. Представления используются в следующих случаях: Для ограничения доступа пользователей к определенным строкам таблицы; Для ограничения доступа пользователей к определенным столбцам таблицы; Для представления данных столбцов разных таблиц в виде одного объекта; Для просмотра информации, получающейся в результате преобразования данных столбцов. 4.Stored procedure - хранимая процедура, представляющая собой группу команд Transact-SQL, объединенных в один модуль. Каждая хранимая процедура имеет уникальное , в пределах базы данных, имя, по которому она вызывается. Хранимая процедура может вызывать другие хранимые процедуры. В состав SQL Server входит большое количество встроенных процедур, которые называются системными и имена которых начинаются с префикса sp_. 5.Trigger - триггер, представляющий собой специальную хранимую процедуру, автоматически запускаемую при добавлении, изменении или удалении данных из таблицы. Триггеры делятся на три категории: UPDATE TRIGGER - триггеры изменения; INSEART TRIGGER - триггеры вставки; DELETE TRIGGER - триггеры удаления. Действия, выполняемые в одном триггере, могут вызвать другие триггеры (вложенные триггеры). 6.Index - индекс, представляющий собой структуру, связанную с таблицей или представлением и предназначенную для ускорения поиска информации в этой таблице или представлении. Индекс определяется для одного или нескольких столбцов, называемых индексированными столбцами. Индекс содержит отсортированные значения индексированного столбца или столбцов со ссылкой на соответствующую строку исходной таблицы или представления. Алгоритмы поиска в отсортированных данных гораздо эффективнее, чем в неотсортированных. 7.Rule - правило, используемое для ограничения значений, хранимых в столбце таблицы или в пользовательском типе данных. Одно и тоже правило может связываться с множеством столбцов различных таблиц и пользовательских типов данных только в текущей базе данных. Правило создается командой CREATE RULE и связывается с объектом базы данных с помощью процедуры spbindrule. Правила оставлены в Transact-SQL для совместимости со старыми версиями сервера. 8.Constraint - ограничение целостности, представляющее собой механизм, обеспечивающий автоматический контроль соответствия данных установленным условиям, или ограничениям целостности. Ограничения целостности имеют приоритет над триггерами, правилами и значениями по умолчанию. Имеется пять ограничений целостности, различающихся по функциональности и области применения: NULL - действует на уровне столбца и пользовательского типа данных и либо разрешает (NULL), либо запрещает (NOT NULL) хранение значений NULL. CHECK - действует на уровне столбца и ограничивает диапазон значений, которые могут быть сохранены в столбце, путем проверки логического условия для вводимых данных. При вводе или изменении данных вводимое значение подставляется в условие. Если полученный результат TRUE, то изменения данных принимаются, иначе - отвергаются и генерируется сообщение об ошибке. Для одного столбца можно задать несколько ограничений типа CHECK (проверок): CONSTRAINT humanavance CHECK (human_ avance BEETWEEN 0 and 700)). UNIQUE - действует на уровне столбца и гарантирует уникальность в столбце вводимых значений. В отличии от ограничения PRIMARY KEY, это ограничение допускает хранение значений NULL. PRIMARY KEY - действует на уровне столбца или таблицы и гарантирует уникальность в пределах таблицы первичного ключа, состоящего из одного или нескольких столбцов. Ни для одного из столбцов ключа не должно быть установлено свойство NULL. Когда используется один столбец, то для него необходимо также задать свойство UNIQUE. В таблице создается только один первичный ключ. При его выборе надо учитывать требования удобства и функциональности. FOREIGN KEY - действует на уровне таблицы и связывается с одним из кандидатов на первичный ключ в другой таблице. Таблица, в которой определен внешний ключ с помощью этого ограничения, называется зависимой, а таблица с кандидатом на первичный ключ - главной. В зависимую таблицу нельзя вставить строку, если внешний ключ не имеет соответствующего значения в главной таблице. Из главной таблицы нельзя удалить строку, если с ней связана хотя бы одна строка в зависимой таблице. Формат задания ограничения таков: FOREIGN KEY REFERENCES имя главной таблицы (кандидат на первичный ключ или ее ключ). 9.Default - умолчание, представляющее собой значение, которое будет присвоено элементу столбца таблицы при вставке строки (записи), если в команде вставки явно не указано значение для этого столбца. Умолчаниями могут быть константы, а также встроенные функции и математические выражения, возвращающие конкретные значения. Создание умолчания выполняется командой CREATE DEFAULT, а удалить само умолчание командой DROP DEFAULT. 10.Function - функция, представляющая собой программный модуль, выполняющий некоторые часто используемые действия над данными и возвращающий значение какого-либо типа. Имя функции, осуществляющее ее вызов, может указываться в любом выражении языка Transact-SQL. Встроенные функции (built-in functions) являются составной частью среды программирования сервера, выполняют заранее предопределенную последовательность команд и не могут изменяться пользователем: COUNT, SUM, MIN, MAX и т. д. Функции пользователя (user_ defind function) создаются пользователем по правилам языка Transact-SQL для реализации разрабатываемых алгоритмов. Каждая копия, или экземпляр сервера SQL Server имеет 4 системных базы данных с именами master, msdb, tempdb и model, а также несколько созданных администратором пользовательских баз данных. Набор системных баз постоянен и не может быть изменен. Обращаться к этим базам напрямую запрещено. Обращаться к ним можно только с помощью специально разработанных интерфейсов: С помощью системных хранимых процедур; С помощью интегрированной среды Enterprice Manager; Используя программные интерфейсы Transact-SQL (API). При соединении с экземпляром сервера организуется связь с конкретной базой данных на сервере. Эта база данных называется текущей. Она определяется для каждого пользователя системным администратором. Пользователь может переключаться на другую базу, используя команду USE < имя базы данных> или функции API для изменения текущей базы данных. SQL Server позволяет соединить базы данных от одной копии сервера и подсоединить к другой, а затем восстановить подсоединение к прежней копии. Все базы данных SQL Server, как системные, так и пользовательские, физически организованы одинаково. Каждая база данных хранится в отдельных файлах. В отдельном файле хранится журнал транзакций, создаваемому автоматически для каждой базы данных. Это повышает надежность системы. Если произойдет сбой и файлы базы данных будут повреждены, то можно восстановить базу данных из резервной копии, а затем восстановить сделанные изменения из журнала транзакций, который останется не поврежденным. Таким образом, каждая база данных имеет, минимум, два файла: один для базы данных и один для журнала транзакций. Эти файлы имеют различную структуру и при работе с ними применяются разные правила. Основная единица хранения данных на уровне файла базы данных – это страница, которая участвует в операциях ввода-вывода как единое целое даже тогда, когда требуется всего одна строка. Размер страницы равен 8 Кбайт. Файл журнала транзакций не имеет страниц и экстентов. Он содержит только последовательность записей транзакций, выполняемых в базе данных. Каждая страница файла базы данных имеет объем 8192 байт. Первые 96 байт страницы отводятся под заголовок, в котором хранится системная информация: тип страницы, объем свободного места на странице, идентификационный номер таблицы или индекса - владельца страниц: Имеется шесть типов страниц: 1.Data. В страницах этого типа хранятся собственно данные, исключая данные типа text, ntext и image. 2.Index. Страницы этого типа используются для хранения информации об индексированных таблицах. 3.Text/Image. В страницах этого типа хранятся данные типа text, ntext и image. 4.Global Allocation Map (GAM). В страницах данного типа хранится информация об использовании экстентов (групп страниц). Экстент состоит из 8 страниц (64 Кбайт). 5.Page Free Space. В страницах этого типа хранится информация о свободном пространстве на страницах. 6.Index Allocation Map (IAM). Страницы этого типа хранят информацию об экстентах, используемых таблицами или индексами. Более сложные базы данных имеют несколько файлов для данных и для транзакций. В этом случае они объединяются в группы для упрощения администрирования базы данных. Любой из таких файлов может располагаться на отдельном диске. Многофайловая база данных имеет в своем составе файлы следующих типов: Primary (*.mdf) - основной файл, который содержит системную информацию о самой базе данных и ее объектах. В этом файле размещаются системные таблицы и описание объектов базы данных. Здесь могут храниться и данные. В базе данных такой файл только один и его наличие в базе обязательно. Secondary (*.ndf) - вторичный файл, который используется только для хранения данных не содержит системной информации. Он может отсутствовать в базе данных. Если задано несколько файлов этого типа, то они могут быть организованны в группы и распределены по разным физическим дискам. Transaction Log (*.ldf) - файл журнала транзакций. Можно использовать несколько таких файлов для ускорения операций ввода-вывода, так как транзакции записываются параллельно во все файлы. Каждый файл, используемый в базе данных, имеет два имени: Logical File Name - логическое имя файла, которое используется в командах Transact-SQL при ссылке на конкретный файл; OS File Name - имя файла в операционной системе, которое используется в операционной системе. Для каждого файла базы данных можно задать свойство автоматического роста и шаг прироста в мегабайтах или в процентах от первоначального роста, а также максимальный размер, до которого возможен рост файла. SQL-Server 2000 обеспечивает создание групп следующих трех типов: Primary File Group - основная группа файлов, которая включает первичный файл все файлы, не включенные в другие группы. База данных может иметь только одну основную группу файлов. 3.4.1. Таблицы (Tables) Microsoft SQL Server – реляционная СУБД, поэтому все данные в Sql хранятся в виде двумерных таблиц со строками и столбцами. Строки называются кортежами или записями, а столбцы – доменами или полями. В этой практической работе рассматриваются способы создания таблиц. Основные ограничения, которым должны удовлетворять таблицы: 1. Каждый столбец в таблице имеет уникальное имя. 2. Все данные в столбце должны быть одного типа. 3. Порядок строк и столбцов в таблице не имеет значения. 4. В таблице не может быть двух одинаковых строк. 3.4.2. Индексы Microsoft SQL Server (как и другие реляционные СУБД) хранит записи в таблицах в неупорядоченном виде. Записи, добавляемые в таблицу одна за другой, не обязательно окажутся "рядом". Данные, извлекаемые из таблицы, также не имеют какого-либо порядка, кроме того, который явно указан в запросе на выборку информации. Индекс – это упорядоченный указатель на записи таблицы. Индекс состоит из пар значений "значение поля" – "физическое расположение записи", поэтому по значению поля (или полей), входящего в индекс, при помощи индекса можно быстро найти место в таблице, где располагается запись, содержащая это значение. Устройство индексов на физическом уровне для нас совершенно не имеет значения. Важно только знать, что создание индексов может привести к значительному ускорению процессов поиска и сортировки. Не следует создавать индекс на поля с ограниченным набором значений – например, на поле, хранящие пол человека, которое содержит только два значения – "м" и "ж". Использование индексов имеется два отрицательных последствия: Для индексов дополнительно тратится дисковое пространство. Наличие индексов замедляет модификацию данных в таблице. 3.5. Ход работы Выполнение операций создания таблиц и индексов в диалоговом режиме. Откройте среду SQL Server Management Studio, выполните соединение с сервером, откройте созданную базу данных University в пр.раб. №2. 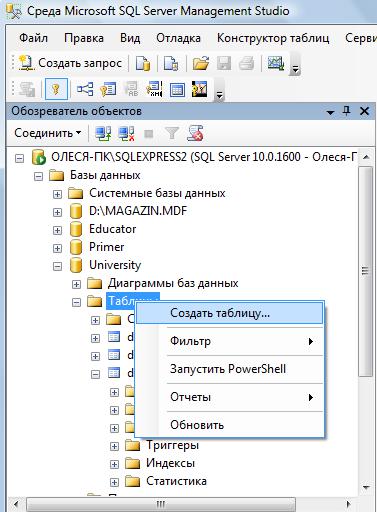 Для создания таблицы в диалоговом режиме, нажмите в окне "Обозревателя объектов" правую клавишу мыши на узле "Tables" (Таблицы) или на одной из имеющихся таблиц и в открывшемся меню выберите команду "New Table…(Создать таблицу)" (рис. 1). В результате откроется окно создания таблицы (рис. 2). Для создания таблицы в диалоговом режиме, нажмите в окне "Обозревателя объектов" правую клавишу мыши на узле "Tables" (Таблицы) или на одной из имеющихся таблиц и в открывшемся меню выберите команду "New Table…(Создать таблицу)" (рис. 1). В результате откроется окно создания таблицы (рис. 2).Рис. 1. Окно "Проводник" с перечнем таблиц 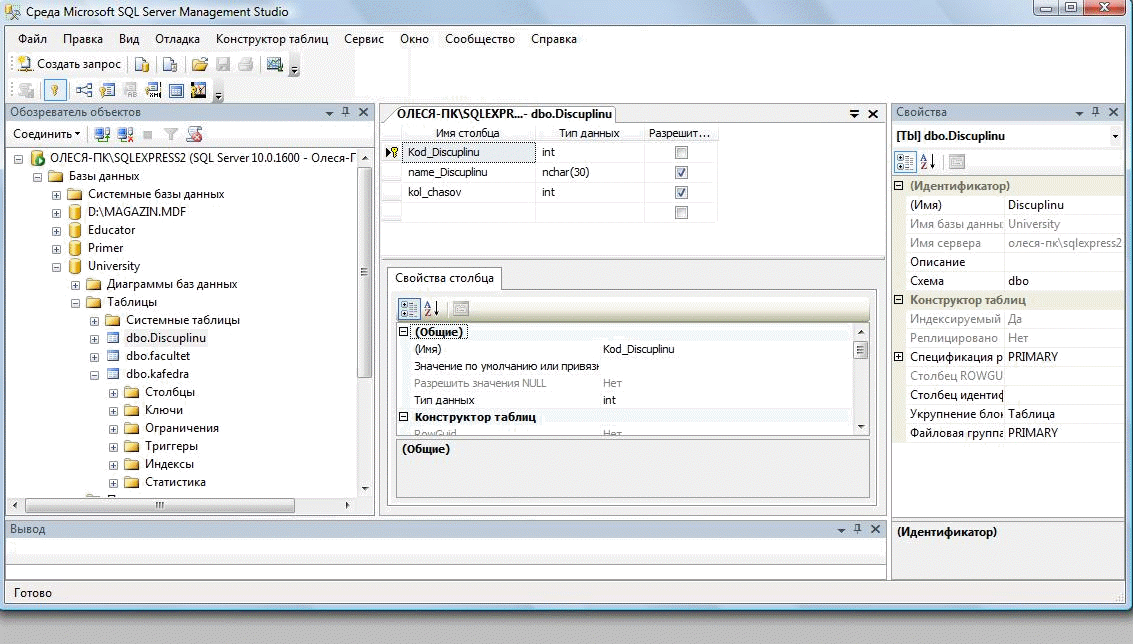 Рис. 2. Окно формирования таблицы в диалоговом режиме Рис. 2. Окно формирования таблицы в диалоговом режимеСетка в средней части окна содержит сведения о полях таблицы. Чтобы добавить поле в таблицу, следует нажать правую клавишу и выбрать из контекстного меню [Вставить столбец]. колонке "Имя столбца" вводится имя создаваемого поля, в колонке "Тип данных" выбирается тип данных. Чтобы задать полю ограничение "NOT NULL" достаточно установить флажок в колонке "Разрешить значения NULL (пустые значения)". Чтобы присвоить полю статус первичного ключа необходимо в колонке ПК щелкнуть правой клавишей мыши и выбрать из контекстного меню Создать первичный ключ. Дополнительные свойства можно настраивать с помощью окна Свойства столбца, которое находится внизу рабочей области. Самостоятельно Создайте новую таблицу, хранящую информацию о всех факультетах в университете. Присвойте ей имя – Facultet. Добавьте поля Kod_faculteta (уникальный номер факультета, тип – целый int, первичный ключ, автоинкремент), Name_faculteta (название факультета, тип текстовый - varchar, длина 255 символов, не допускается пустых значений), Fio_Decana (ФИО декана факультета, тип – текстовый varchar), Nomer_komnatu (номер комнаты деканата, тип – символьный varchar(допускается запись 134-2, где 134 – номер комнаты, а 2 – номер корпуса)), Tel_decanata (телефон деканата, тип – длинное целое число bigint с точностью в 10 символов, значение по умолчанию ‘999999’,ограничение на значение меньше ‘1 000 000’). Примечание. 1). Для того, чтобы сделать автоприращение ключевого поля kod_faculteta измените в дополнительных свойствах столбца свойство – Спецификация идентификатора: 2). Для того, чтобы добавить проверочное ограничение на столбец Tel_decanata , выделите его и правой клавишей из меню выберите Проверочные ограничения. В появившемся окне нажмите кнопку Добавить. Будет создано ограничение под именем по умолчанию, для которого необходимо создать выражение вычисления ограничения на вводимые значения выбранного поля. В нашем случае ограничение на значение меньше ‘1 000 000’ будет иметь вид  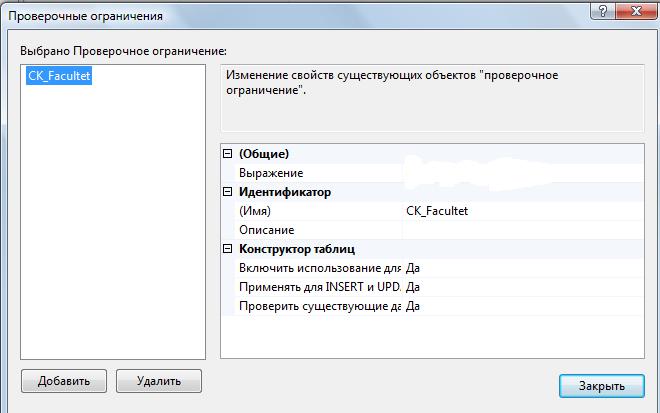 Tel_decanata< 1 000 000. Tel_decanata< 1 000 000.После введения данных о всех полях таблицы следует нажать кнопку [Сохранить] на панели инструментов. Создадим для данной таблицы индексы (для других таблиц создавать индексы не нужно!!). Для этого выберите из контекстного меню "Индексы и ключи" (рис. 4). 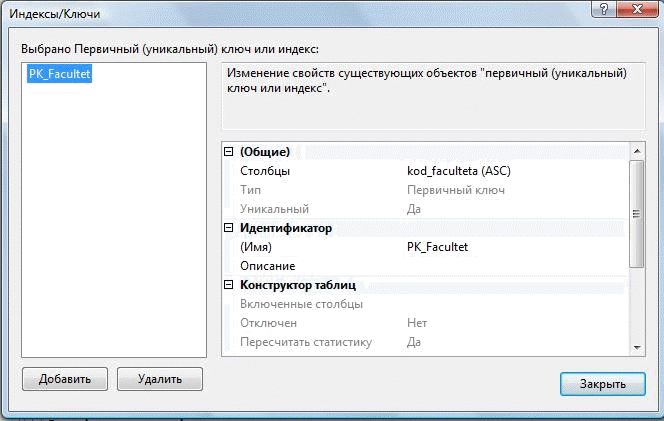 В нашем случае для первичного ключа автоматически присваивается уникальный индекс по возрастанию, см. рис.4. В нашем случае для первичного ключа автоматически присваивается уникальный индекс по возрастанию, см. рис.4.Рис. 4. Окно просмотра и редактирования индексов Мастер позволяет просматривать, редактировать, создавать и удалять индексы. Для создания индекса выполните следующие действия: Нажмите в этой сетке клавишу [Добавить]. В результате будет вставлена новая строка. Задайте в колонке "имя" имя индекса – My_Index_Facultet. Нажмите кнопку Если создается уникальный индекс, то изменяется свойство в колонке "Уникальный" . Чтобы создать индекс нажмите кнопку сохранить. После создания индекса его можно в любой момент изменить, если изменить параметры индекса и снова нажать кнопку Сохранить. Для заполнения таблиц данными вначале выделите таблицу в окне проводника и из контекстного меню выберите Изменить первые 200 строк. Вид окна представлен на рис. 17. 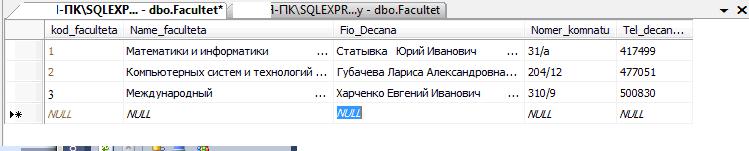 Рис. 5. Диалог создания записей в таблице Введите самостоятельно три записи. Для добавления новой записи воспользуйтесь кнопкой перехода После ввода данных нажмите на панели кнопку о подтверждении изменения данных Примечание. При вводе данных в поле kod_faculteta заполнять числами не нужно, они будут добавлены автоматически согласно формуле инкремента. При вводе данных в поле tel_decanata значение можно оставить не заполненным. В результате выполнения sql-кода поле будет заполнено значением по-умолчанию. При вводе данных в поле tel_decanata значение более 1 000 000 будет отображаться ошибка ввода связанной с проверочным ограничением. Самостоятельно создайте новую таблицу, присвойте ей имя Kafedra. Добавьте следующие поля в таблицу: Kod_kafedru (уникальный номер кафедры, тип – целый, первичный ключ, автоинкремент), kod_faculteta (номер факультета, к которому принадлежит кафедра, тип – целый, не допускается пустых значений), Name_kafedru (название кафедры, тип текстовый, длина 50 символов, не допускается пустых значений), Fio_zavkaf (ФИО заведующего кафедрой, тип – текстовый), Nomer_komnatu (номер комнаты кафедры, тип – числовой, num_korpusa (номер корпуса, тип – числовой, с ограничением – номер корпуса может быть, только от 1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 12), Tel_kafedru (телефон кафедры, тип – текстовый). Примечание. Для создания ограничений для столбца num_korpusa используйте в выражении функцию IN (‘знач1’,’знач2’, ..,’значn’) Создадим связь между двумя таблицами Факультет и Кафедра. Между данными таблицами можно установить связь «один-ко-многим», так как на одном факультете может быть несколько кафедр. Например, к факультету Математики информатики относятся кафедры Информатики, Компьютерные сети и системы, Прикладной математики и Математического анализа. Чтобы создать связь «один-ко-многим» необходимо вызвать в окне редактирования таблицы Кафедра каскадное меню и выбрать Отношения первичным ключом kod_faculteta внешней таблицы Факультет. 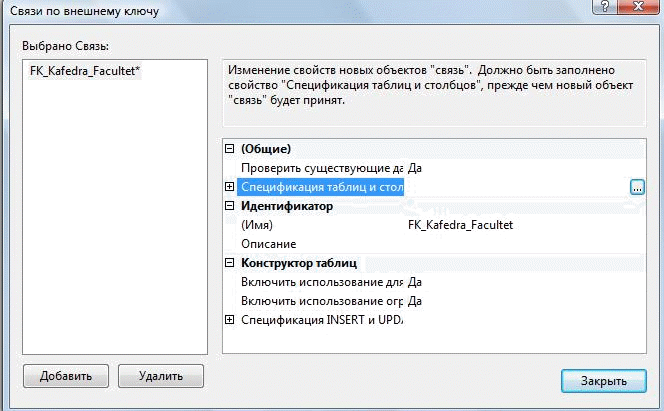 Для этого в появившемся окне Связи по внешнему (см. рис. 18) перейдите на поле Спецификация таблиц и столбцов и нажмите кнопку напротив Для этого в появившемся окне Связи по внешнему (см. рис. 18) перейдите на поле Спецификация таблиц и столбцов и нажмите кнопку напротив Рис. 6. Диалог создания внешних ключей Вам будет открыто диалоговое окно создания Внешних ключей (рис. 19), где имя связи по умолчанию присвоенное внешнему ключу можете оставить без изменения. Выберите в качестве таблицы первичного ключа – Facultet и поле kod_faculteta. Выберите в качестве таблицы внешнего ключа – Kafedra и поле kod_faculteta. Нажмите Ок и вернитесь в предыдущее окно. 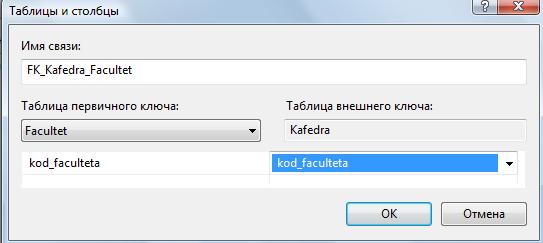 Рис. 7. Создание Внешних ключей Установите правила удаления и обновления данных. Для этого перейдите на поле Спецификации INSERT и UPDATE и выберите правило каскадного удаления и обновления. Сохраните таблицу. После подтверждения операции у вас в таблице Кафедра появится внешний ключ по полю kod_faculteta. Для этого в окне проводника выберите в таблице Кафедра элемент Ключи и вы увидите первичный ключ и внешний ключ.  Введите самостоятельно название кафедр и их реквизиты на все созданные факультеты. Для добавления новой записи воспользуйтесь кнопкой перехода  После ввода данных нажмите на панели кнопку о подтверждении Для визуального отображения связей между таблицами воспользуйтесь средством Диаграммы базы данных, добавьте две созданных вами таблицы в проект и сохраните получившийся результат под именем Diagram_BD. 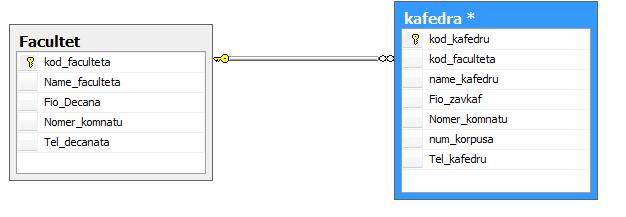 ПРАКТИЧЕСКАЯ РАБОТА №4 ВВЕДЕНИЕ В ЯЗЫК SQL. СОЗДАНИЕ ТАБЛИЦ И ОГРАНИЧЕНИЙ НА SQL 4.1. Цель практической работы Изучение структурированного языка запросов Transact - SQL, являющегося основой системы программирования SQL Server, и приобретение навыков применение инструментальных средств разработки и программирования объектов создаваемых баз данных. Изучить SQL-операторы для работы с таблицами и индексами. Изучить sql-команды для создания, изменения и удаления таблиц. Изучить используемые в SQL Server типы ограничений. Изучить SQL-операторы для работы с ограничениями. 4.2. Исходные данные Исходными данными является индивидуальное задание и результат предыдущих практических работ. 4.3. Используемые программы Программа " SQL Server Management Studio " и установленный сервер Microsoft SQL Server . Выполнение операций над таблицами, помощью языка SQL 4.4. Теоретические сведения индексами и ограничениями с 4.4.1.Основы программирования на Transact - SQL Система программирования SQL Server относится к классу командно- интерпретирующих систем сверхвысокого уровня. Единицами действий системы являются команды, исполняемые в режиме интерпретации сразу же по мере их поступления в сервер. Основой этой системы программирования является проблемно-ориентированный структурированный язык запросов (Structured Query Language) Transact - SQL, который расширяется и развивает возможности стандарта ANSI SQL - 92. Transact - SQL включает следующие средства: данные различного типа баз данных и переменных; константы, стандартные и ограниченные идентификаторы; арифметические и логические выражения, включающие следующие операнды: константы, переменные, имена столбцов таблиц, функции, подзапросы и условные выражения, а также выражения, взятые в круглые скобки; SQL - команды для создания, изменения и удаления баз данных и их объектов, а также для определения запросов на ввод, обработку и извлечение данных; управляющие программные структуры, определяющие условия и порядок выполнения команд в заданной последовательности или пакете команд; встроенные (системные) и определяемые пользователем функции; встроенные (системные) и определяемые пользователем хранимые процедуры. системе могут храниться, помимо функций и процедур, последовательности (пакеты) команд, которые называются скриптами. Если скрипт описывает процесс создания базы данных, или каких-либо ее объектов, то такой скрипт называется сценарием. Сценарии позволяют переносить структуру базы данных от одного сервера к другому, а также структуру таблиц и других объектов в различные базы данных. Скрипты хранятся в текстовых файлах. Функции и хранимые процедуры баз данных позволяют уменьшить объем запросов, передаваемых от клиента к серверу, что повышает общую производительность системы. Наличие исходного кода для этих объектов позволяет упростить сопровождение программных комплексов и внесение изменений в них. Обычно все бизнес-правила и алгоритмы обработки данных реализуются на сервере баз данных и доступны конечному пользователю в виде набора функций и хранимых процедур, которые и представляют интерфейс обработки данных. Для обеспечения целостности данных, а также в целях безопасности, приложению обычно не предоставляется прямой доступ к данным. Вся работа ведется с помощью указанного интерфейса. Подобный подход делает весьма простым изменение алгоритмов обработки данных и обеспечивает возможность расширения системы без внесения изменений в само приложение. Достаточно изменить хранимую процедуру на сервере баз данных, и сделанные изменения тотчас станут доступными всем пользователям сети. В языке Transact - SQL имеются следующие виды констант: битовые: 0 и 1; логические: FALSE и TRUE; бинарные в шестнадцатеричном представлении: 0*9E70DA; 4. символьные: 'ABC'; "ABC" (если QUOTEDIDENTIFIER = OFF); N 'ABC' (Unicode); N "ABC" (Unicode); целые: 1; 2; 175; с фиксированной точкой: 12.35; - 16.753; с плавающей точкой: 1.75Е5; 3.84Е - 3; для даты: " April 15.2003"; "4/15/2003"; "20031207"; для времени: 14:30; 14:30:20:999; 4am; 4pm; денежные: $100;?200; 2.15. Комментарии в языке бывают двух типов: сточные, начинающиеся с двух символов минуса - и блочные, заключаемые символами /* и */. Все объекты базы данных должны иметь имена, которые используются в командах для ссылки на эти объекты. Любой объект базы данных должен быть уникально идентифицирован. Помимо программных имен сервер автоматически генерирует внутренние уникальные имена для идентификации объектов баз данных, например, PK Table X 014543FA. Программные имена задаются идентификаторами двух типов: стандартными идентификаторами: Table X; Key Col; ограниченными идентификаторами: [My Table]; [Order]; "My Table"; "Order" (если QUOTEDIDENTIFIER = ON). Длина идентификатора - от 1 до 128 символов. Идентификатором не может быть какое-либо зарезервированное ключевое слово языка. Стандартный идентификатор в качестве первого символа может иметь любую латинскую или русскую букву, знаки #, ##, @, @@ и знак подчеркивания _. Последующими знаками, помимо указанных, могут быть еще и десятичные цифры. Ограниченные идентификаторы могут включать и другие символы, в том числе зарезервированные слова. В этом случае они должны заключаться в квадратные скобки или двойные кавычки. соответствии с идеологией SQL Server каждый объект создается определенным пользователем и принадлежит той или иной базе данных. В свою очередь база данных расположена на конкретном сервере. Из имен объекта, пользователя, базы данных и сервера создается полное имя (complete name) или полностью определенное имя (full qualified name), записываемое в следующем виде: [[[server.].[database].[owner_name].] objectname Варианты обращения к объектам базы данных: A.B.C.D; A.B..D; A..C.D; A..D; B.C.D; B..D; C.D; D Чтобы сослаться на конкретный столбец таблицы или представления, необходимо в полном имени указать пятый элемент: А.В.C.E. Операторами выражения могут быть унарные (+ и - ), бинарные арифметические операторы (+, -, *, % ), оператор присваивания (=), строковая операция конкатенации (+), операторы сравнения (=, >, <, <=, >=, =, != или <>, !<, !>), логические операторы (NOT, AND, OR, ALL, ANY, BETWEEN, EXIST, IN, LIKE, SOME ) и битовые операторы (&, |, ^). Константы, переменные, операнды и выражения используются при записи команд программирования функций и хранимых процедур, которые, все вместе взятые, составляют основную часть системы программирования SQL Server и определяют ее выразительную мощь. Команды позволяют создавать, модифицировать и удалять базы данных и их объекты, формировать сложные запросы на ввод, обработку и извлечение данных из баз знаний, выполнять функции администрирования и обслуживания баз данных. Функции и хранимые процедуры реализуют разнообразные алгоритмы обработки данных или выполнение служебных функций сервера. При формировании запросов очень часто используются специальные логические операторы, синтаксис которых записывают следующим образом: 1. Выражение {= | < > | ! = | > | >= | ! >|, = | !<} ALL подзапрос. Здесь скалярное выражение вычисляется и сравнивается с каждым значением, возвращаемым подзапросом. Если сравнение дает истину для всех возвращаемых подзапросом значений, то этот оператор возвращает истину. Если вместо ALL записать SOME или ANY, то результатом будет истина, если хотя в одной строке будет выполняться заданное сравнение. Выражение [NOT] BETWEEN Н Выражение AND В Выражение возвращает истину, когда значение выражения лежит в диапазоне значений Н выражения и В Выражения (или не лежит). Оператор EXISTS (подзапрос) возвращает значение истина, если подзапрос возвращает хотя бы одну строку. Выражение [NOT] IN (подзапрос \ выражение [,.. n]) возвращает значение истина, если значение левого выражения совпадает с одним из значений подзапроса или списка значений правых выражений (или не совпадает). Выражение [NOT] LIKE шаблон [ESCAPE знак] дает истину, если значение выражения соответствует или не соответствует шаблону, в котором "%" означает любое количество произвольных символов, "_" - один произвольный символ, "[символы]" - один из указанных в скобках, "[символы]" - все символы, кроме указанных. Знак после слова ESCAPE позволяет указать, что следующий за ним знак шаблона не является управляющим знаком шаблона, т.е. знаком "%", "_" и т.д., а представляет обычный знак строки. |