Практикум по дисциплине Архитектура и организация компьютерных систем Форма обучения очная
 Скачать 1.85 Mb. Скачать 1.85 Mb.
|

|
Тема: Вспомогательные микросхемы для СМПУ. Цель: Изучить вспомогательные микросхемы и системные локальные шины. Задание: Описать набор микросхем или chipset. Ознакомиться с работой системных локальных шин. Оформить отчет. Теоретические сведения Чипсет (chipset) в буквальном переводе означает набор микросхем. Чипсет, который также называют набором системной логики, - это одна или чаще две микросхемы (чипы), предназначенные для организации взаимодействия между процессором, памятью, портами ввода-вывода и остальными компонентами компьютера. На заре развития компьютерной техники для организации взаимодействия между отдельными элементами ПК использовались десятки отдельных микросхем, что, конечно же, было крайне неудобно. И только с появлением процессора i486 отдельные микросхемы стали объединять в одну-две большие микросхемы, которые и получили название чипсета (рис. 16.1.) 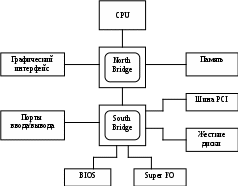 Рис. 16.1. Схема классического двухмостового чипсета С появлением шины PCI отдельные микросхемы чипсета стали называть мостами. Так появились устоявшиеся термины: северный мост (North Bridge) и южный мост (South Bridge) чипсета. Северный мост непосредственно соединяется с процессором, а южный мост соединяются с северным. В некоторых случаях производители объединятют северный и южный мосты в одну микросхему. Если чипсет – это всего одна микросхема, то такое решение называют одночиповым, а сели две – двухмостовой схемой. Северный мост чипсета традиционно содержит контроллер памяти (за исключением чипсетов для процессоров с архитектурой AMD 64), контроллер графической шины (AGP или PCI Express x16), интерфейс взаимодействия с южным мостом и интерфейс взаимодействия с процессором. В некоторых случаях северный мост чипсета может содержать дополнительные линии PCI Express x1 для организации взаимодействия с картами расширения, имеющими соответствующий интерфейс. На южный мост чипсета возлагается функция организации взаимодействия с устройствами ввода-вывода. Южный мост содержит контроллеры жестких дисков (SATA и/или PATA). USB-контроллер, сетевой контроллер (только МАС-уровень), контроллер PCI-шины и PCI-Express шины, контроллер прерывания и DMA-контроллер. Кроме того, в южный мост обычно встраивается звуковой контроллер. Также южный мост соединяется с еще двумя важными микросхемам на материнской плате: микросхемой ROM-памяти BIOS и микросхемой Super I/O, отвечающей за последовательные и параллельные порты и флоппи-дисковод. Для соединения северного и южного мостов друг с другом используется специальная выделенная шина, причем разные производители используют для этого разные шины (с различной пропускной способностью): Intel: DMI (Direct Media Interface); Uli: HyperTransport; VIA: V-Link; SiS: MuTIOL; ATI: HyperTransport, PCI Express; NVidia: HyperTransport. Чипсет является основой любой материнской платы. Фактически функциональность материнской платы и ее производительность на 90% определяется именно чипсетом. От него зависят поддерживаемый тип процессора, тип памяти, а также функциональные возможности по подключению периферийных устройств. Выбор чипсетов на сегодняшний день крайне богат. И если процессоры выпускают только две копмании, то чипсеты производят и Intel, и Uli, и VIA, и SiS, и ATI, и NVidia. Различают системную и локальную шины. Системную шину можно упрощенно представить как совокупность сигнальных линий, объединенных по их назначению (данные, адреса, управляемые структуры), которые также имеют вполне назначенные электрические характеристики и протоколы передачи информации, под протоколом передачи информации понимают правила, ее определенные. Основной обязанностью системной шины является передача информации между процессором (или процессорами) и остальными электронными компонентами компьютера, по этой шине осуществляется не только передача информации, тем не менее и адресация устройств, а также происходит обмен специальными служебными сигналами. Для понятности представим системную шину в виде магистрали, шоссе и т.п. Компоненты компьютера: процессор, оперативная память, звуковая карта - это перерабатывающие сырье (информацию) заводы, располагаемые по обеим сторонам шоссе на назначенных расстояниях друг от друга, здесь магистраль является связующей нитью между вкалывающими работниками. Грузовыми автомобилями (электрические импульсы для системных плат) производится транспортировка материала. Сначала главному заводу (процессору), затем по мере переработки всем остальным, продукт посредством магистрали (или шины) поставляется запрашивающему узлу рабочей цепи. Принцип адресации в системной шине аналогичен привязке определенного адреса одному из заводов, поэтому для осуществления доставки информационного сырья требуется также и указание местоположения (адреса) пункта назначения плюс несходные управляемые структуры. Используемые шины отличаются по разрядности (количеству передаваемых бит в единицу времени), способу передачи сигнала (последовательные или параллельные), пропускной способности, количеству и типу поддерживаемых устройств, а также протоколу работы. Параллельность передачи информации заключается в том, что данные по шине пересылаются одновременно по нескольким каналам, в качестве примера можно привести интерфейс для принтеров, представленный в материнских платах LPT-портом (спецификация разъема), при последовательном способе данные передаются поочередно конечными пакетами, что снижает скорость передачи информации, за единицу времени пересылается малое ее количество. Однако последовательный принцип отправки данных пригодней. Высокие тактовые частоты работы существующих систем приводят к всемогущим потерям при соблюдении параллельности, что снижает КПД, пропускная способность шины характеризуется количеством информации, передаваемым шиной за единицу времени. Как правило, шины ПК можно представить в виде некой иерархической структуры - шинной архитектуры. Особенностью ПК недалекого прошлого было наличие шины ISA, унаследованной от самых основных моделей IBM PC. Кроме нее распространены шины EISA, MCA, VLB, PCI, PCMCIA (CardBus), AGP и др. Шины могут быть синхронными (осуществляющими передачу данных только по тактовым импульсам) и асинхронными (осуществляющими передачу данных в произвольные моменты времени), а также использовать различные схемы арбитража (то есть способа совместного использования шины несколькими устройствами). Задания для самостоятельного выполнения Провести сравнительный анализ чипсетов производительности Intel, Uli, VIA, SiS, ATI и NVidia. На макете материнской платы указать расположение чипсета (северного и южного мостов). Указать фирму-производителя и особенности работы. Проанализировать и провести сравнительную характеристику системных шин двух и более ПК. Лабораторная работа №17 (2 часа) Тема: Системные локальные шины. Цель: Ознакомиться с передачей информации по шине, за управление передачи которой отвечает одно из подключенных к ней устройств или специально выделенный для этого узел называемый атрибутом шины. Задание: Шина ISA. Шина EISA. Составить отчет. Теоретические сведения ISABus(Industry Standard Architecture) — шина расширения, применявшаяся с первых моделей PC и ставшая промышленным стандартом. В компьютере XT применялась шина с разрядностью данных 8 бит и адреса — 20 бит. В компьютерах AT шину расширили до 16 бит данных и 24 бит адреса. Конструктивно шина выполнена в виде двух щелевых разъемов (слотов) с шагом выводов 2,54 мм (0,1 дюйма), вид которых изображен на рис. 17.1. Подмножество ISA-8 использует только 62-контактный слот (ряды А, В), в ISA-16 применяется дополнительный 36-контактный слот (ряды С, D). Шина обеспечивает своим абонентам возможность отображения 8- или 16-6итных регистров на пространство ввода/вывода и памяти. Диапазон адресов памяти ограничен областью UMA, но для шины ISA-16 специальными опциями BIOS Setup может быть разрешено и пространство в области между 15-м и 16-м мегабайтом памяти (правда, при этом компьютер не сможет использовать более 15 Мбайт ОЗУ). Диапазон адресов ввода/вывода сверху ограничен количеством используемых для дешифрации бит адреса, нижняя граница ограничена областью адресов 0—FFh, зарезервированных под устройств системной платы. В PC была принята 10-битная адресация ввода/вывода, при которой линии адреса А[15:10] устройствами игнорировались. Таким образом, диапазон адресов устройств шины ISA ограничивается областью 100h—3FFH то есть всего 758 адресов 8-битных регистров. На некоторые области этих адресов претендуют и системные устройства. Впоследствии стали применять и 12-битную адресацию (диапазон 100h—FFFh), но при ее использовании всегда необходимо учитывать возможность присутствия на шине и старых 10-битных адаптеров, которые «отзовутся» на адрес с подходящими ему битами А[9:0] во всей допустимой области 12-битного адреса четыре раза. 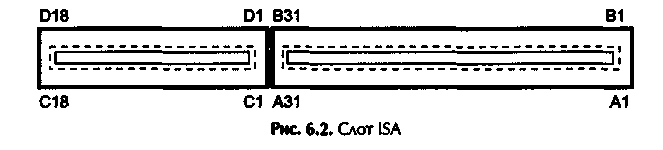 Рис. 17.1. Слот ISA В распоряжении абонентов шины ISA-8 может быть до 6 линий запроcов прерываний IRQ/с, для IS А-16 их число достигает И. Заметим, что при конфигурировании BIOS Setup часть из этих запросов могут отобрать устройства системной платы или шина PCI. Абоненты шины могут использовать до трех 8-битных каналов DMA, a 16-битной шине могут быть доступными еще три 16-битных канала. Сигналы 16-битных каналов могут использоваться и для получения прямого управлении шиной устройством Bus-Master. При этом канал DMA используется для обеспечения арбитража управления шиной, а адаптер Bus-Master формирует все адресные и управляющие сигналы шины, не забывая передать управлении шиной процессору не более, чем через 15 микросекунд (чтобы не нарушить регенерацию памяти). Все перечисленные ресурсы системной шины должны быть бесконфликтно распределены между абонентами. Бесконфликтность подразумевает следующее: Каждый абонент должен при операциях чтения управлять шиной данных (выдавать информацию) только по своим адресам или по обращению к используемому им каналу DMA. Области адресов для чтения не должны пересекаться. «Подсматривать» не ему адресованные операции записи не возбраняется. Назначенную линию запроса прерывания IRQx или прямого доступа DMM абонент должен держать на низком уровне в пассивном состоянии и переводить в высокий уровень для активации запроса. Неиспользуемыми линиями запросов абонент управлять не имеет права, они должны быть электрически откоммутированы или подключаться к буферу, находящемуся в третьем состоянии. Одной линией запроса может пользоваться только одно устройство. Такая нелепость (с точки зрения схемотехники ТТЛ) была допущена в первых PC и в дань (жертву) совместимости старательно тиражируется уже много лет. Задача распределения ресурсов в старых адаптерах решалась с помощью джамперов, затем появились программно конфигурируемые устройства, которые вытесняются автоматически конфигурируемыми платами РпР. С появлением 32-битных процессоров делались попытки расширения разрядности шины, но все 32-битные шины ISA не являются стандартизованными, кроме шины EISA. EISABus(Extended ISA) — жестко стандартизованное расширение ISA до 32 бит. Конструктивное исполнение обеспечивает совместимость с ней и обычных ISA-адаптеров (рис. 18.1). Узкие дополнительные контакты расширения (ряды Е, F, G, Н) расположены между ламелями разъема ISA и ниже ламелей А, В, С, D таким образом, что адаптер ISA, не имеющий дополнительных ключевых прорезей в краевом разъеме, не достает до них. Установка карт EISA в слоты ISA недопустима, поскольку ее специфические цепи попадут на контакты цепей ISA, в результате чего системная плата окажется неработоспособной (к счастью, «без дыма»). 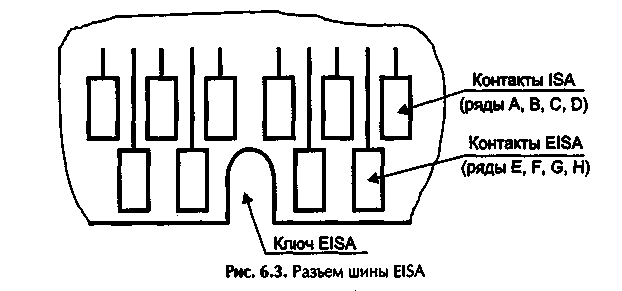 Рис. 17.2. Разъем шины EISA Расширение шины касается не только увеличения разрядности данных и адреса: для режимов EISA используются дополнительные управляющие сигналы, обеспечивающие возможность применения более эффективных режимов передачи. В обычном (не пакетном) режиме передачи за каждую пару тактов может быть передано до 32 бит данных (один такт на фазу адреса, один — на фазу данных). Максимальную производительность шины реализует пакетный режим (Burst Mode) — скоростной режим пересылки пакетов данных без указания текущего адреса внутри пакета. В пакете очередные данные могут передаваться в каждом такте шины, длина пакета может достигать 1024 байт. Шина предусматривает и более производительные режимы DMA, при которых скорость обмена может достигать 33 Мбайт/с. Линии запросов прерываний допускают разделяемое использование, причем сохраняется и совместимость с ISA-картами: каждая линия запроса может программироваться на чувствительность как по перепаду (как в ISA), так и по низкому уровню. Шина допускает потребление каждой картой расширения мощности до 45 Вт, но это не означает, что мощность блока питания для системной платы на 8 слотов должна быт» более 360 Вт — полную мощность, пожалуй, не потребляет ни один из адаптеров. Многие решения EISA уходят корнями в МСА-шину PS/2. Каждый слот (максимум — 8) и системная плата имеют селективное разрешение адресации ввода/вывода и отдельные линии запроса и подтверждения управления шиной. Арбитраж запросов выполняет устройство ISP(Integrated System Peripheral). Приоритеты (в порядке убывания): регенерация, DMA, CPU, Bus-Master Обязательной принадлежностью системной платы с шиной EISA является энергонезависимая память конфигурации NVRAM, в которой хранится информация об устройствах EISA для каждого слота. Формат записей стандартизован, для модификации конфигурационной информации применяется специальная утилита ECU(EISA Configuration Utility). Архитектура позволяет при использовании программно-конфигурируемых адаптеров автоматически разрешать конфликты использования системных ресурсов программным путем, но отличие от спецификации PnP EISA не допускает динамического реконфигурирования. Все изменения конфигурации возможны только в режиме конфигурирования, после выхода из которого необходима перезагрузка компьютера. Изолированный доступ к портам ввода/вывода каждой карты во время конфигурирования обеспечивается просто: сигнал AEN, разрешающий декодирования адреса в цикле ввода/вывода, на каждый слот приходит по отдельной линии AENx, в это время программно-управляемой. Таким образом, можно по отдельности обращаться и к обычным картам ISA, но из этого нельзя извлечь особой выгоды, поскольку карты ISA не поддерживают обмена конфигурационной информацией, предусмотренного шиной EISA. На некоторых идеях конфигурирования EISA выросла спецификация РпР для шины ISA (формат конфигурационных записей ESCD во многом напоминает NVRAM EISA). EISA — дорогая, но оправдывающая себя архитектура, применяющаяся в многозадачных системах, на файл-серверах и везде, где требуется высокоэффективное расширение шины ввода/вывода. Перед шиной PCI у нее есть некоторое преимущество в количестве слотов, которое для одной шины PCI не превышает четырех, а у EISA может достигать восьми. Задания для самостоятельного выполнения Провести сравнительную характеристику шин ISA и EISA. Лабораторная работа №18 (2 часа) Тема: Архитектура современного ЭВМ. Цель: Освоить на практике архитектуру современного ЭВМ. Задание: Изучить характеристики процессора с расширением ММХ. Выполнить внутреннее кэширование обращения к памяти. Выполнить разгон и торможение процессора Pentium используя различные варианты разгона. Составить отчет. Теоретические сведения Расширение MMX Расширение MMX ориентировано на мультимедийное 2D, 3D графическое и коммуникационное применение. В процессорах с расширением ММХ одновременно обрабатываются несколько элементов данных за одну инструкцию, используются новые типы 64 битных упакованных данных. Упакованные байты - 8 байт, упакованные слова - 4 слова, упакованные двойные слова - 2 двойных слова, учетверенное слово - одно слово. Эти типы данных обрабатываются в регистрах ММХ0 - ММХ7, располагающихся в стеке 80 битных регистров сопроцессора. Как и регистры сопроцессора - они не могут использоваться для адресации памяти. Технология ММХ поддерживает арифметику с насыщением, ее отличие в том, что при возникновении переполнения в результате фиксируются максимально возможные значения для используемого типа данных, а перенос игнорируется, при антипереполнении фиксируются минимально возможные значения, граничные значения определяются типом и разрядностью переменных. В системе команд технология ММХ требует 57 дополнительных инструкций, позволяющих одновременно обрабатывать несколько единиц данных. Они делятся на следующие группы: арифметические, сравнения элементов данных на равенство или по величине, преобразование форматов логические над 64 битными операндами, сдвиги логические и арифметические. Пересылки данных между регистрами или памятью, очистка ММХ. Инструкции ММХ не влияют на флаги условий, регистры ММХ адресуются физически. Инструкции ММХ не порождают новых исключений, исключения при их выполнении могут возникать только при нарушении ММХ при обращении к памяти. Инструкции ММХ доступны из любого режима микропроцессора, при выполнении задач надо следить за ....... Совпадение режимов ММХ и сопроцессора накладывает ......., частое чередование которых может снизить производительность, из- за необходимости сохранения и восстановления большого контекста сопроцессора. Внутренний КЭШ Внутреннее кэширование обращения к памяти применяются начиная с 486-го микропроцессора. В 486-ых и Pentium-ах есть внутреннее кэширование первого уровня, а Pentium PRO и II есть и вторичное кэширование. Микропроцессорный КЭШ могут иметь, как раздельный тип данных так и общий ..... Для внутреннего КЭШа используется наборно-ассоциативная архитектура. Строки в КЭШ памяти выделяются только при чтении, метод записи в ранних 486 - сквозная запись, в поздних моделях возможно переключение на обратную запись. Работу внутренней КЭШ памяти характеризуют следующие процессы: обслуживание работ микропроцессора на обращение к памяти, выделение и замещение строк для кэширования физической памяти, обеспечение согласованности данных внутреннего КЭШа и оперативной памяти, управление кэшированием. Любой внутренний запрос микропроцессора на обращение к памяти направляется во внутренний КЭШ. Теги четырех строк набора, который обслуживает данный адрес, сравниваются со старшими битами запрошенного физического адреса. Если адресуемая область есть в строке КЭШ памяти (КЭШ попадание) запрос на чтение обслуживается КЭШем, запрос на запись модифицирует данную строку и в зависимости от метода записи либо сразу выводит на внешнюю шину, либо позже при обратной. При КЭШ промахе запрос на запись направляется только на внешнюю шину. Запрос на чтение при КЭШ промахе обслуживает следующим образом, если он относится к кэшируемой области памяти выполняется цикл заполнения целой строки КЭШа, то есть все байты читаются из оперативной памяти и помещаются в одну из строк набора КЭШа обслуживающего данный адрес. Если затребованные данные не укладываются в данной строке заполняется и соседняя. Внутренний запрос микропроцессора на данные удовлетворяется сразу, как только затребованные данные считываются из ОЗУ, то есть заполнение строки до конца может параллелиться с обработкой полученных данных. Если в наборе есть свободная строка то заполняется именно она, при отсутствии свободных строк в наборе замещается строка, к которой дольше всех не было обращений (алгоритм псевдо LRU). Таким образом выделение и замещение строк выполняется только для КЭШ промахов чтения, при промахах записи заполнение строк не производится. Управлять кэшированием можно только на этапе заполнения строк. Кроме того существует возможность их аннулирования, то есть объявление их недостоверными и очистка всей КЭШ памяти. Очистка внутренней КЭШ памяти при сквозной записи осуществляется внешним сигналом и инструкциями аннулирования. Аннулирование строк выполняется внешними схемами, оно необходимо в системах у которых в оперативную память запись может производить не только микропроцессор, но и другие контроллеры шины. В этом случае требуются специальные средства для поддержания согласованности данных во всех степенях памяти: в первичном и вторичном КЭШе и динамическом ОЗУ. Аннулирование строки микропроцессор выполняет в любом состоянии. Управление заполнением КЭШа возможно и на аппаратном, и на программном уровнях. Микропроцессор позволяет кэшировать любую область физической памяти. Программно можно управлять кэшируемостью каждой страницы памяти, так как в адресном пространстве есть области, для которых кэширование специально недоступно или метод программной записи непригоден. Кэширование принято запускать, например для выполнения однократно выполняемого участка программы с тем, чтобы из КЭШа не вытеснялись более часто используемые фрагменты. Синхронизация Основной тактовый генератор системной платы вырабатывает высокостабильную опорную частоту, которая используется для синхронизации процессора, системной шины и шин ввода вывода. Стандартные частоты генератора 4,77; 6; 8; 10; 12; 16; 20; 25; 33,3; 40; 50; 60; 66,6; 75; 83; 100; 125 МГц. При наличии переключателя Turbo компьютер с процессором 286, 386 частота выбирается из пары частот. В процессорах 486 и старше частота фиксирована, а переключатель Turbo может отключать кэширование или включать режим прерывистой синхронизации. Так как быстродействие различных компонентов компьютеров существенно различается, применяется деление опорной частоты для синхронизации шин ввода вывода и внутреннее умножение частоты в процессорах. Различают следующие частоты: Host Bus - частота системной шины (внешняя частота шины процессора). Она является опорной для всех других и устанавливается джемперами с перемычками. Микропроцессоры Pentium используют частоты от 50 до 125 МГц. Частоты 75 МГц и выше требуют высокие технологии изготовления системных плат, чипсетов и микросхем обрамления; CPU Clock - внутренняя частота процессора на которой работает его вычислительное ядро, для ее получения применяется внутреннее умножение частоты на 1,5; 2; 2,5; 3; 3,5; 4 и некоторые другие значения. Коэффициент умножения задается с помощью джемперов на системной плате, которые заземляют определенные выводы микропроцессора. Трактовка управляющих сигналов при этом зависит от марки модели процессора; PCI Bus Clock - это частота шины PCX, которая должна составлять 25; 33,3 МГц. Обычно она обеспечивается делением Host Bus Clock на 2 или на 3. Оптимальная частота для процессоров 5 и 6 поколений 66,6 МГц; VLB Bus Clock - это частота шины VBL определяемая аналогично предыдущей; ISA Bus Clock - это частота шины ISA, которая должна быть близка к 8 МГЦ. Она обычно задается в BIOS Setup через коэффициент деления системной шины. Разгон и торможение процессора Фирмы производители гарантируют стабильную длительную работу на заявляемых частотах при опорном питающем напряжении. При снижении питающего напряжения уменьшается рассеиваемая мощность и допустимая частота синхронизации. Повышение тактовой частоты увеличивает потребляемую мощность, но для обеспечения стабильной работы внутренней логики требуются некоторые повышения питающего напряжения. Возможность выбора внешней частоты синхронизации и внутреннего коэффициента умножения процессора создает иллюзию возможности разгона процессора. Здесь есть следующие варианты: подъем входной частоты с 60 до 66,66 МГц для которого конфигурирование самого процессора не изменяется, однако процессоры с частотой ядра 100; 133; 166 Мгц таким способом не разгонятся; увеличение коэффициента умножения который воспринимается даже процессорами с частотой ядра 75 МГц, однако коэффициент 2,5 воспринимают только процессоры начиная со стопинга С; комбинированные изменения коэффициента умножения и внешней частоты. Эти изменения могут производиться в пределах штатной спецификации. На системных платах предназначенных не только для процессоров Intel возможны и более радикальные варианты на которые идут для повышения в основном производительности шины PCI. Это дает эффект на конкретных приложениях. Фирма Intel отказалась от повышения внешней частоты до 75 МГц, так как это не дает принципиального роста пропускной способности. Эффект от разгона процессора теряется за счет относительно медленной памяти, так как при переходе на более высокую частоту системной шины BIOS совместно с чипсетом увеличивает число тактов ожидания в циклах памяти. Варианты разгона Pentium Pentium 100 до 120, 133; 133 до 150, 166; 166 до 180, 200. При экспериментах с разгоном не следует сразу повышать питающее напряжение, необходимо после повышения частоты постоянно следить за степенью нагрева процессора и радиатора стабилизатора напряжения. Проверкой работы системы может служить длительная активная работа в многозадачном режиме с каким-либо тяжелым приложением. Следует иметь в виду, что фирма производитель ставит маркировку частоты исходя из обоснованных критериев качества и надежности, не забывая про получение прибыли. Логическая структура диска Большинство винчестеров и гибких дисков имеют сходно логический формат. Под логическим форматом понимается, что на диске резервируется определенные области для хранения служебной информации необходимой операционной системе для работы с этим устройством. Процесс создания и заполнения таких областей называется логическим форматированием. На каждом диске существуют следующие области: загрузочная запись или сектор BR; две (одна) таблицы размещения файлов FAT; корневого каталога RD; область данных DA. Структура BR (бутсектора) Хранится в логическом секторе 0. В нем содержится некоторая информация о диске и программа IPL2. Первый байт этого сектора это код команды безусловного перехода JMP (E9) с последующим 16 битным смещением, либо код короткого перехода (EB) с 8 битным смещением и третьим байтом NOP (90) на программу IPL2. Заканчивается сектор сигнатурой AASS. После команды JMP идет 8 битное поле для имени и версии OEM. Здесь заполняется ACSII строка с маркой и версией используемой информационной системой и наименование пакета. Главный компонент сектора BR это юлок параметров BIOS (BPB). Эта структура данных содержит тип носителя, количество используемых байт на сектор и секторов на кластер, количество копий FAT и другую информацию. Последний элемент сектора это программа IPL2. Контрольные вопросы: Проанализируйте процесс кэширования памяти. Что, по-вашему, происходит с памятью в этот момент? Укажите размер кэш-памяти Вашего ПК. Расскажите логическую структуру дискапамяти, ее основные компоненты. Продемонстрируйте работу жесткого диска на макете. Как Вы понимаете процесс разгона процессора? Лабораторная работа №19 (2 часа) |