ИТвСБ 99. Презентация Классификация информационных систем
 Скачать 2.36 Mb. Скачать 2.36 Mb.
|

|
Содержание 1. Теоретический вопрос: «Модель файлового сервера» 3 2. Презентация: «Классификация информационных систем» 10 3. Задание: Анализ статистических данных по Приморскому краю 16 Список литературы 21 1. Теоретический вопрос: «Модель файлового сервера»Управление крупными предприятиями, управление экономикой на уровне страны требуют участия в этом процессе достаточно крупных коллективов. Такие коллективы могут располагаться в различных районах города, в различных регионах страны и даже в различных странах. Для решения задач управления, обеспечивающих реализацию экономической стратегии, становятся важными и актуальными скорость и удобство обмена информацией, а также возможность тесного взаимодействия всех участвующих в процессе выработки управленческих решений. В эпоху централизованного использования ЭВМ с пакетной обработкой информации пользователи вычислительной техники предпочитали приобретать компьютеры, на которых можно было бы решать почти все классы их задач. Однако сложность решаемых задач обратно пропорциональна их количеству, и это приводило к неэффективному использованию вычислительной мощности ЭВМ при значительных материальных затратах. Нельзя не учитывать и тот факт, что доступ к ресурсам компьютеров был затруднен из-за существующей политики централизации вычислительных средств в одном месте. Принцип централизованной обработки данных не отвечал высоким требованиям к надежности процесса обработки, затруднял развитие систем и не мог обеспечить необходимые временные параметры при диалоговой обработке данных в многопользовательском режиме. Кратковременный выход из строя центральной ЭВМ приводил к роковым последствиям для системы в целом. 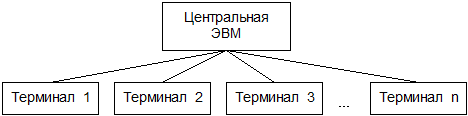 Рис. 1. Система централизованной обработки данных Появление персональных компьютеров потребовало нового подхода к организации систем обработки данных, к созданию новых информационных технологий. Возникло логически обоснованное требование перехода от использования отдельных ЭВМ в системах централизованной обработки данных к распределенной обработке данных (рис. 2). 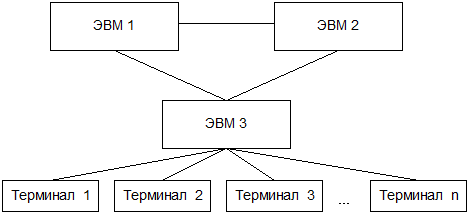 Рис. 2. Система распределенной обработки данных Системы распределенных вычислений появляются, прежде всего, по той причине, что в крупных автоматизированных информационных системах, построенных на основе корпоративных сетей, не всегда удается организовать централизованное размещение всех баз данных и СУБД на одном узле сети. Поэтому системы распределенных вычислений тесно связаны с системами управления распределенными базами данных. Распределенная база данных – это совокупность логически взаимосвязанных баз данных, распределенных в компьютерной сети. Система управления распределенной базой данных – это программная система, которая обеспечивает управление распределенной базой данных и прозрачность ее распределенности для пользователей. Распределенная база данных может объединять базы данных, поддерживающие любые модели (иерархические, сетевые, реляционные и объектно-ориентированные базы данных) в рамках единой глобальной схемы. Подобная конфигурация должна обеспечивать для всех приложений прозрачный доступ к любым данным независимо от их местоположения и формата. В обиходе СУБД, на основе которых создаются распределенные информационные системы, также характеризуют термином «распределенные СУБД», и, соответственно, используют термин «распределенные базы данных». Практическая реализация распределенных вычислений осуществляется через отступление от некоторых рассмотренных выше принципов создания и функционирования распределенных систем. В зависимости от того, какой принцип приносится в «жертву» (отсутствие центральной установки, непрерывность функционирования, согласованного состояния данных и др.) выделились несколько самостоятельных направлений в технологиях распределенных систем – технологии «Клиент-сервер», технологии реплицирования, технологии объектного связывания. Реальные распределенные информационные системы, как правило, построены на основе сочетания всех трех технологий, но в методическом плане их целесообразно рассмотреть отдельно. Модель удаленного управления данными также называется моделью файлового сервера (File Server, FS). В этой модели презентационная логика и бизнес-логика располагаются на клиенте. На сервере располагаются файлы с данными и поддерживается доступ к файлам. Функции управления информационными ресурсами в этой модели находятся на клиенте1. Распределение функций в этой модели представлено на рис. 3. В этой модели файлы базы данных хранятся на сервере, клиент обращается к серверу с файловыми командами, а механизм управления всеми информационными ресурсами, собственно база мета-данных, находится на клиенте. Достоинства этой модели в том, что мы уже имеем разделение монопольного приложения на два взаимодействующих процесса. При этом сервер (серверный процесс) может обслуживать множество клиентов, которые обращаются к нему с запросами. Собственно СУБД должна находиться в этой модели на клиенте. Каков алгоритм выполнения запроса клиента? Запрос клиента формулируется в командах ЯМД. СУБД переводит этот запрос в последовательность файловых команд. Каждая файловая команда вызывает перекачку блока информации на клиента, далее на клиенте СУБД анализирует полученную информацию, и если в полученном блоке не содержится ответ на запрос, то принимается решение о перекачке следующего блока информации и т. д. Перекачка информации с сервера на клиент производится до тех пор, пока не будет получен ответ на запрос клиента. Недостатки: - высокий сетевой трафик, который связан с передачей по сети множества блоков и файлов, необходимых приложению; - узкий спектр операций манипулирования с данными, который определяется только файловыми командами; - отсутствие адекватных средств безопасности доступа к данным (защита только на уровне файловой системы). Модель удаленного доступа к данным основана на учете специфики размещения и физического манипулирования данных во внешней памяти для реляционных СУБД. В RDA-модели компонент доступа к данным в СУБД полностью отделен от двух других компонентов (компонента представления и прикладного компонента) и размещается на сервере системы. Компонент доступа к данным реализуется в виде самостоятельной программной части СУБД, называемой SQL-сервером, и инсталлируется на вычислительной установке сервера системы. Функции SQL-сервера ограничиваются низкоуровневыми операциями по организации, размещению, хранению и манипулированию данными в дисковой памяти сервера. Иначе говоря, SQL-сервер играет роль машины данных. Взаимодействие серверных и клиентских процессов в модели 1:1. 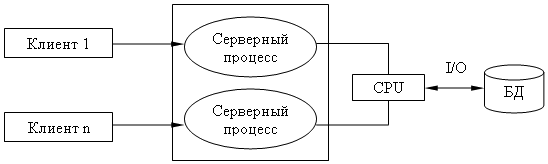 Рис. 3. Вышеперечисленные недостатки устраняются в модели (архитектуре) «систем с выделенным сервером», который способен обрабатывать запросы от многих клиентов. Сервер единственный обладает монополией на управление данными и взаимодействует одновременно со многими клиентами. Логически каждый клиент связан с сервером отдельной нитью (tread), или потоком, по которому пересылаются запросы. Такая архитектура получила название многопотоковой односерверной. Достоинства: - уменьшается нагрузка на ОС, возникающая при работе большого числа пользователей. Многопотоковая односерверная архитектура. Недостатки: Т.к. сервер может выполняться только на одном процессоре, возникает ограничение на применение СУБД для мультипроцессорных платформ. Например, если компьютер имеет 4 процессора, то СУБД с одним сервером использует только один из них, не загружая оставшиеся 3. В некоторых системах эта проблема решается вводом промежуточного диспетчера - архитектура виртуального сервера. Архитектура виртуального сервера. 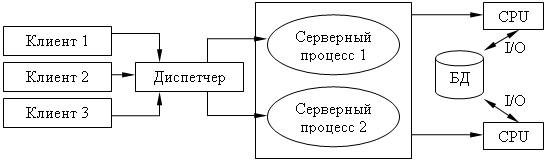 Рис. 4. В этой архитектуре клиент подключается не к реальному серверу, а к промежуточному звену (диспетчеру), который выполняет функции диспетчеризации запросов к актуальным сервера. Количество актуальных серверов может быть согласовано с количеством процессоров в системе. Недостатки: - невозможно направить запрос от конкретного клиента к конкретному серверу. - серверы становятся равноправными, т.е. нет возможности устанавливать приоритеты для обслуживания запросов. Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов БД, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Данная модель называется многонитевая мультисерверная архитектура. Она связана с вопросами распараллеливания выполнения одного пользовательского запроса несколькими серверными процессами. Многопотоковая мультисерверная архитектура. 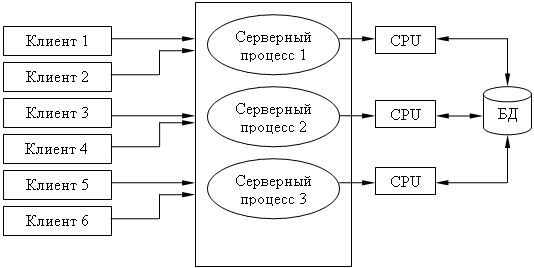 Рис. 5. Сервер приложений (англ. application server) - это программная платформа (software framework), предназначенная для эффективного исполнения процедур (программ, механических операций, скриптов), которые поддерживают построение приложений. Сервер приложений действует как набор компонентов, доступных разработчику программного обеспечения через API (Интерфейс прикладного программирования), который определен самой платформой. Для веб-приложений эти компоненты обычно работают на той же машине, где запущен веб-сервер. Их основная работа - обеспечивать создание динамических страниц. Однако современные серверы приложений нацелены гораздо больше не на то, чтобы генерировать веб-страницы, а на то, чтобы выполнять такие сервисы как кластеризация, отказоустойчивость и балансировка нагрузки, позволяя таким образом разработчикам сфокусироваться только на реализации бизнес-логики. Обычно этот термин относится к Java-серверам приложений. В этом случае сервер приложений ведет себя как расширенная виртуальная машина для запуска приложений, прозрачно управляя соединениями с базой данных с одной стороны и соединениями с веб-клиентом с другой. 2. Презентация: «Классификация информационных систем» 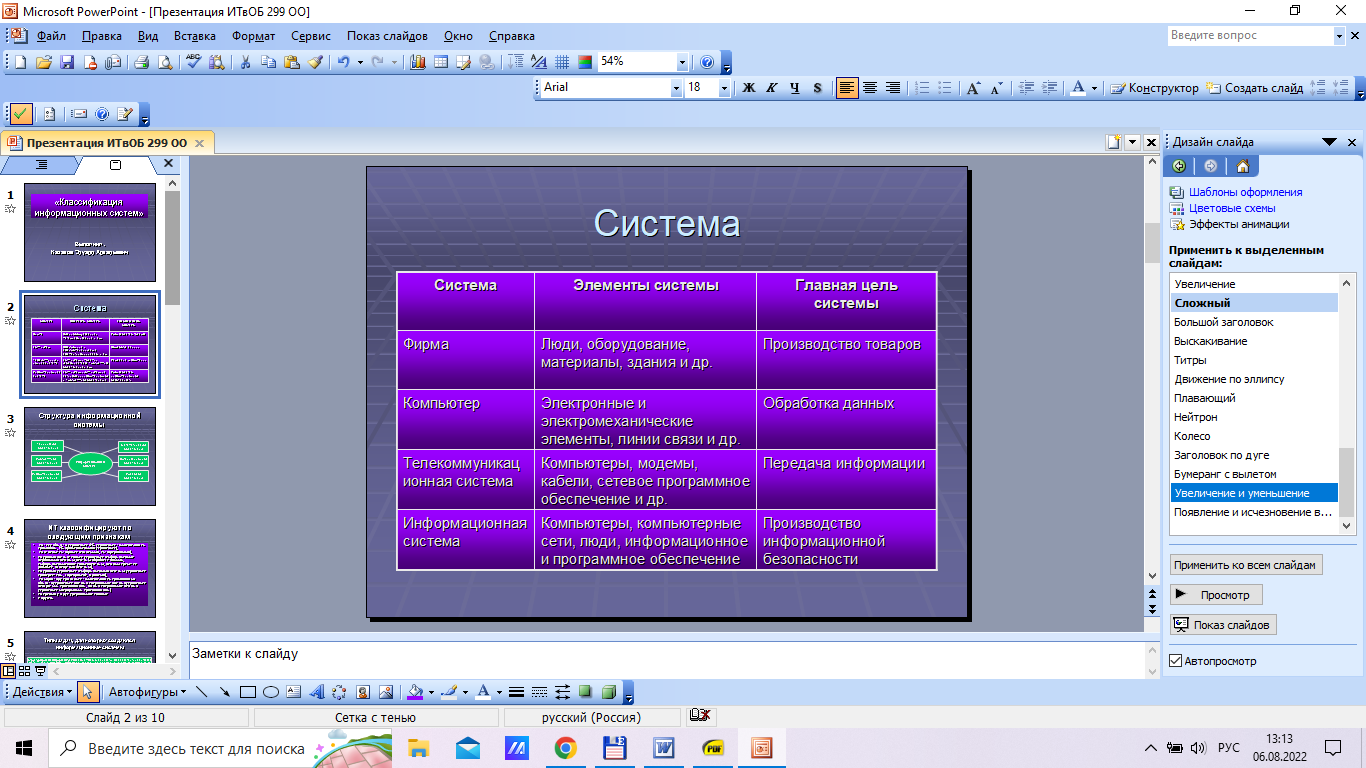 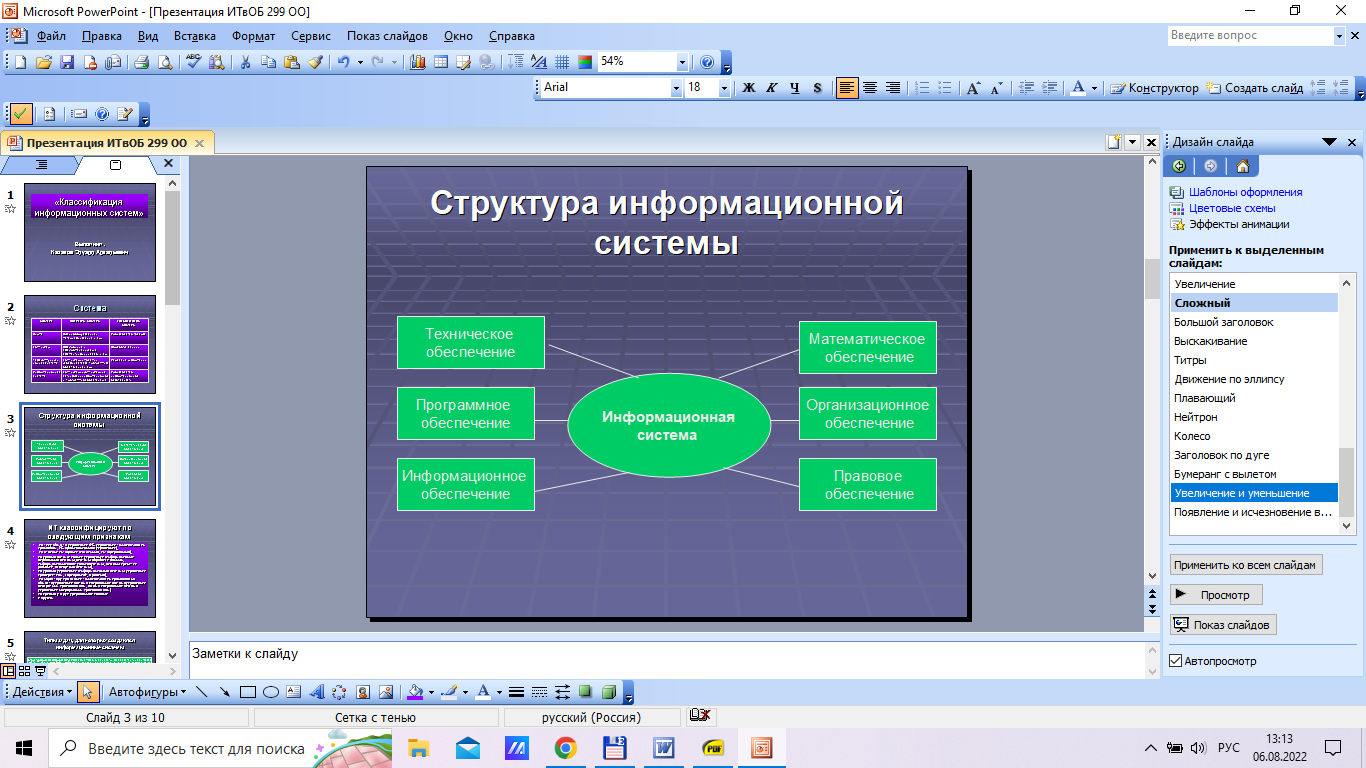 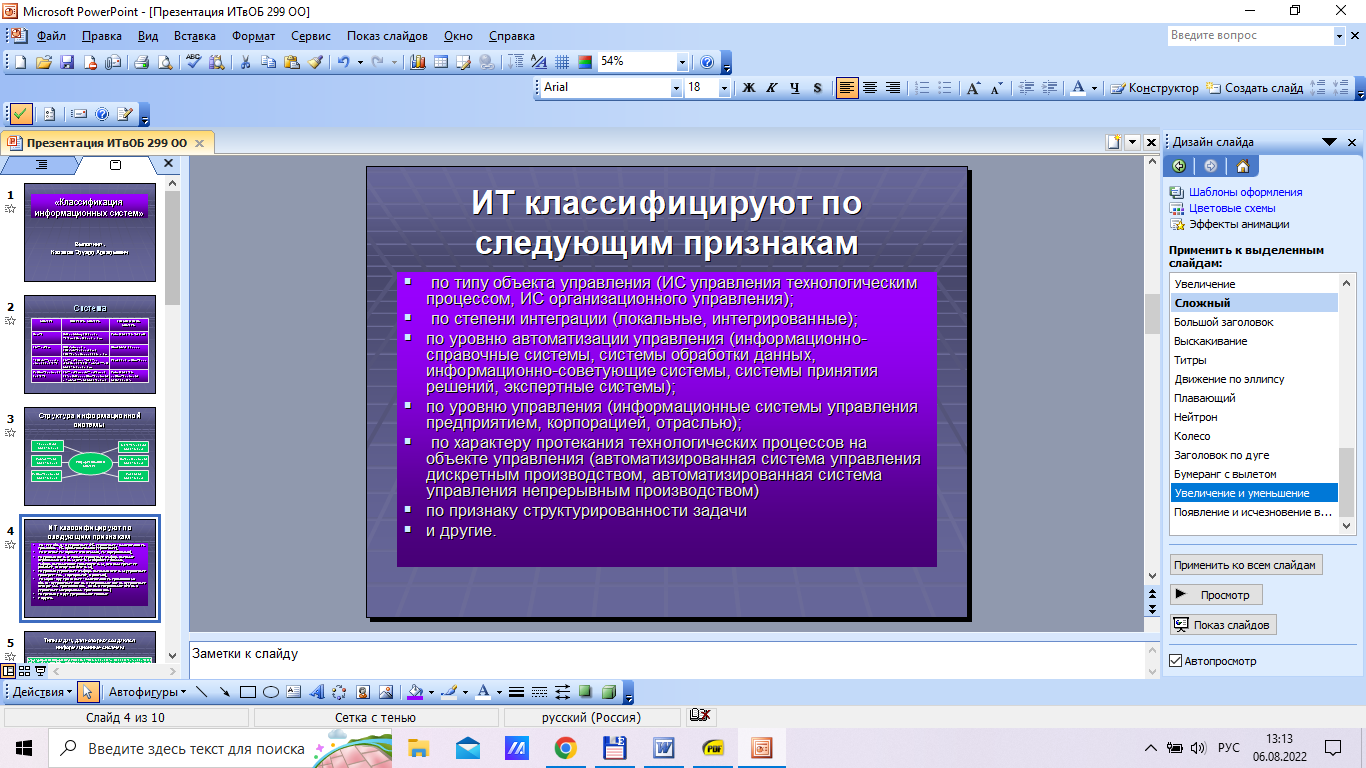 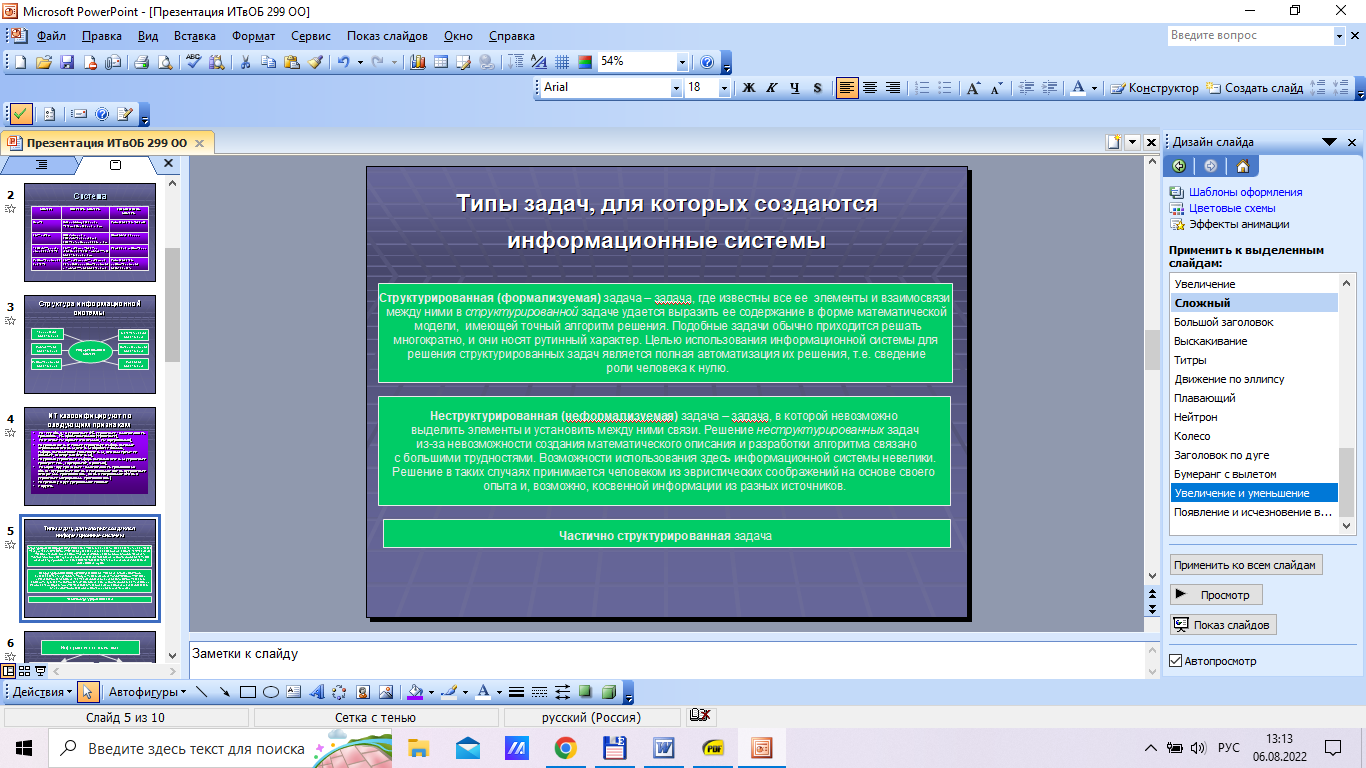 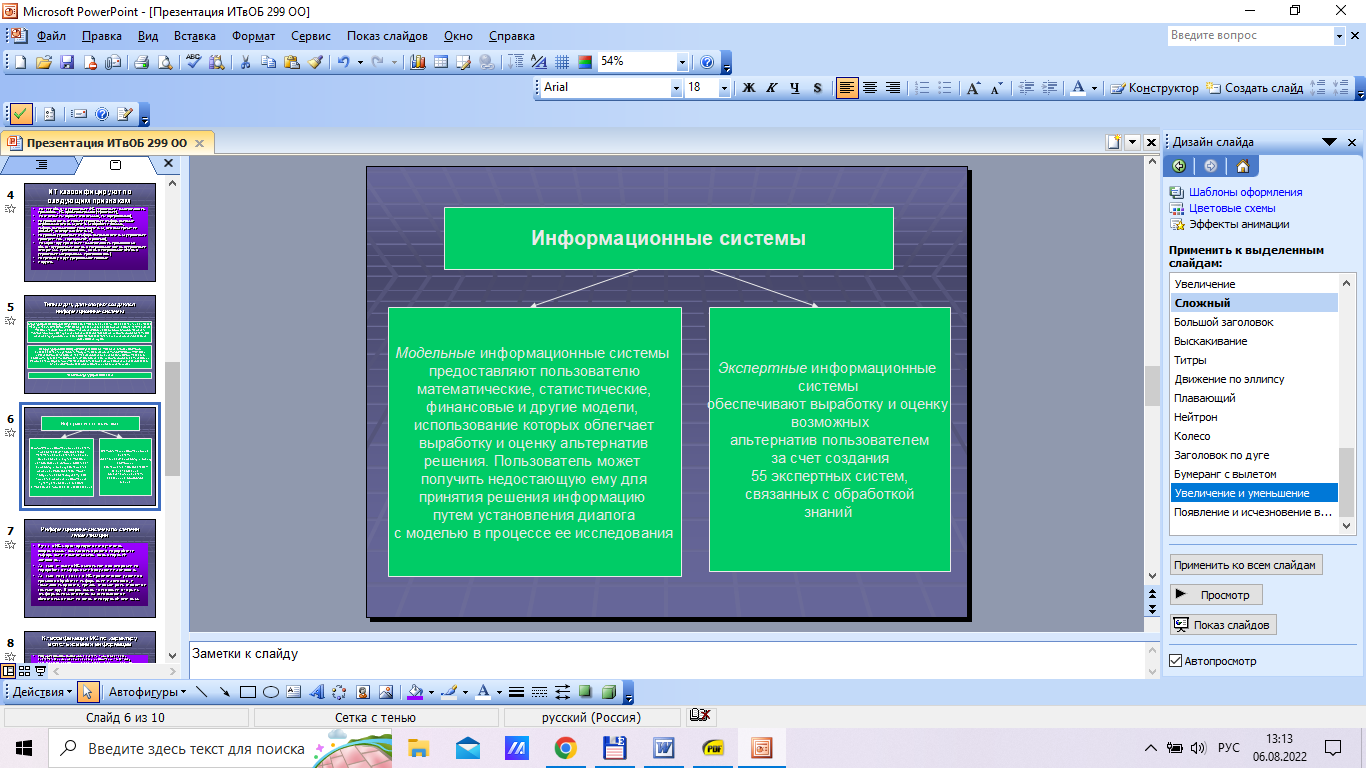 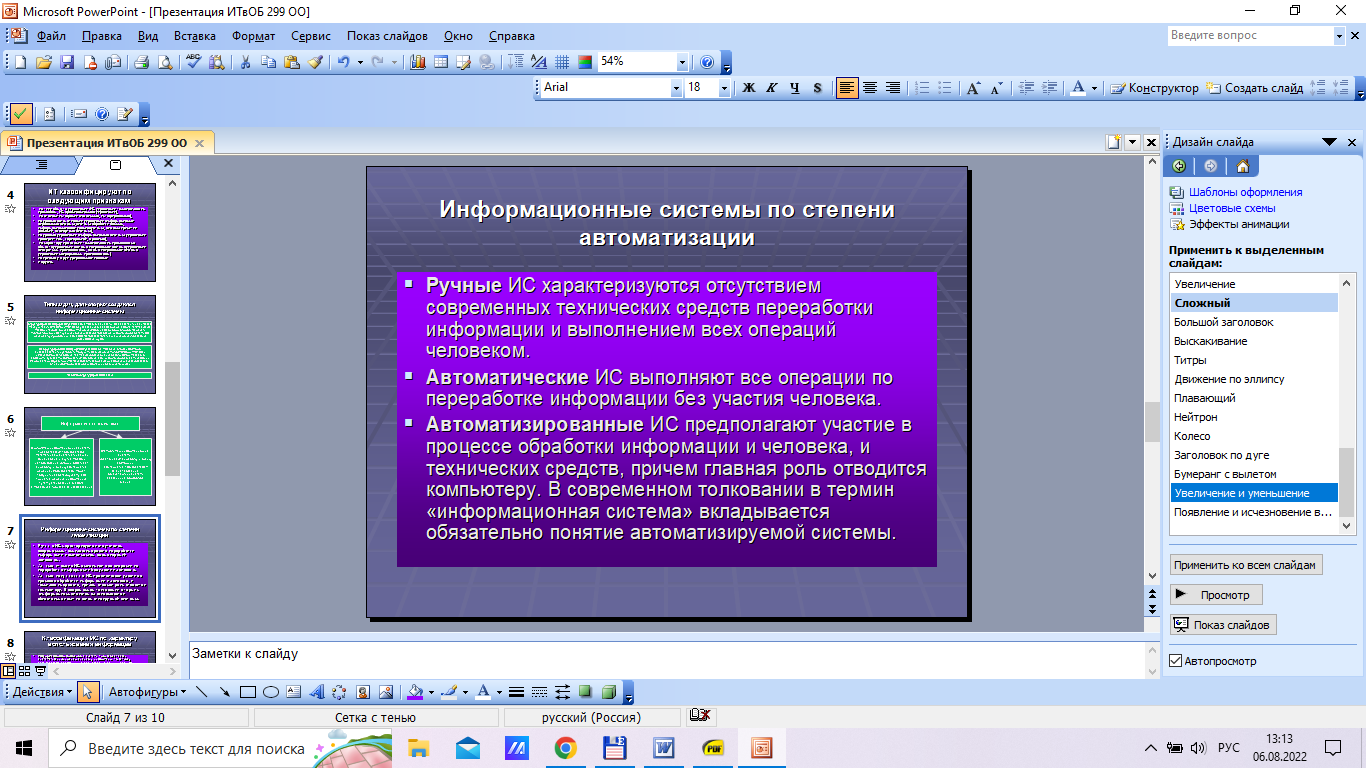 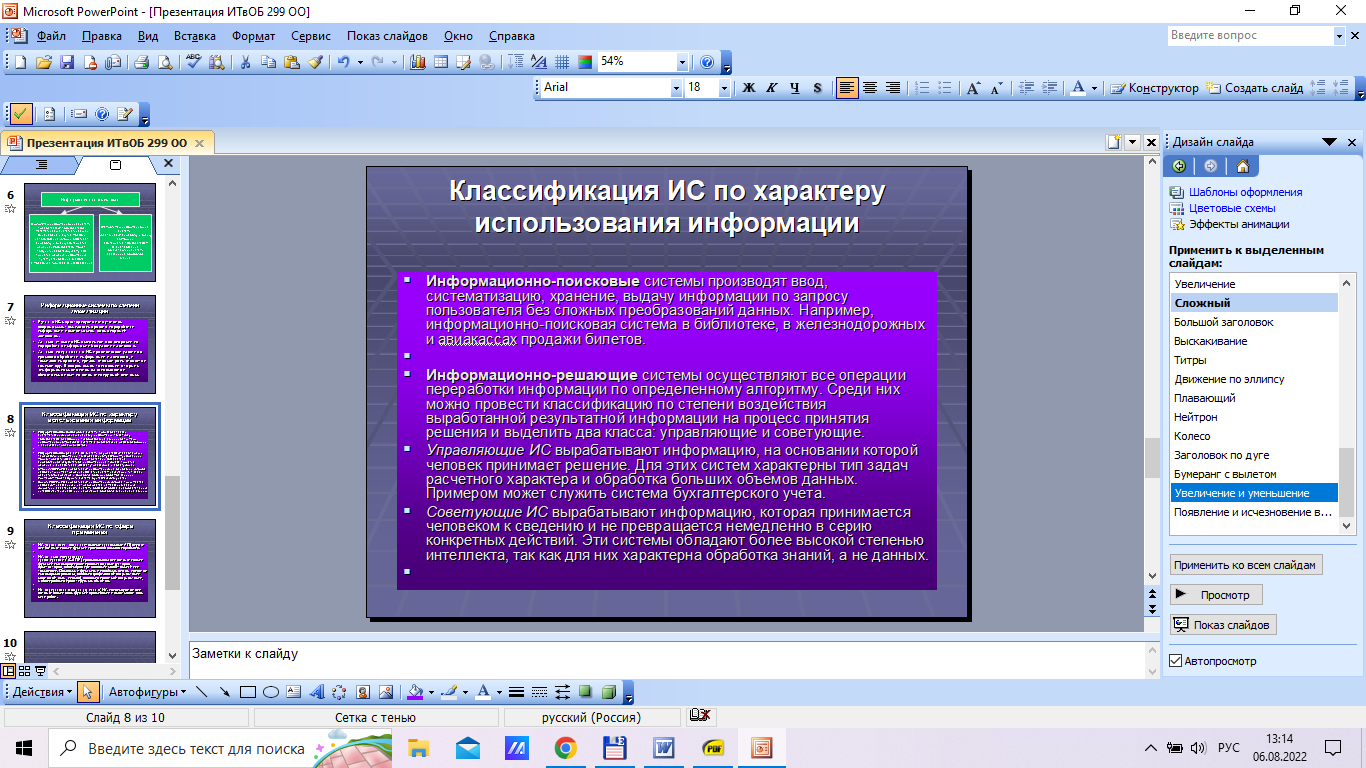 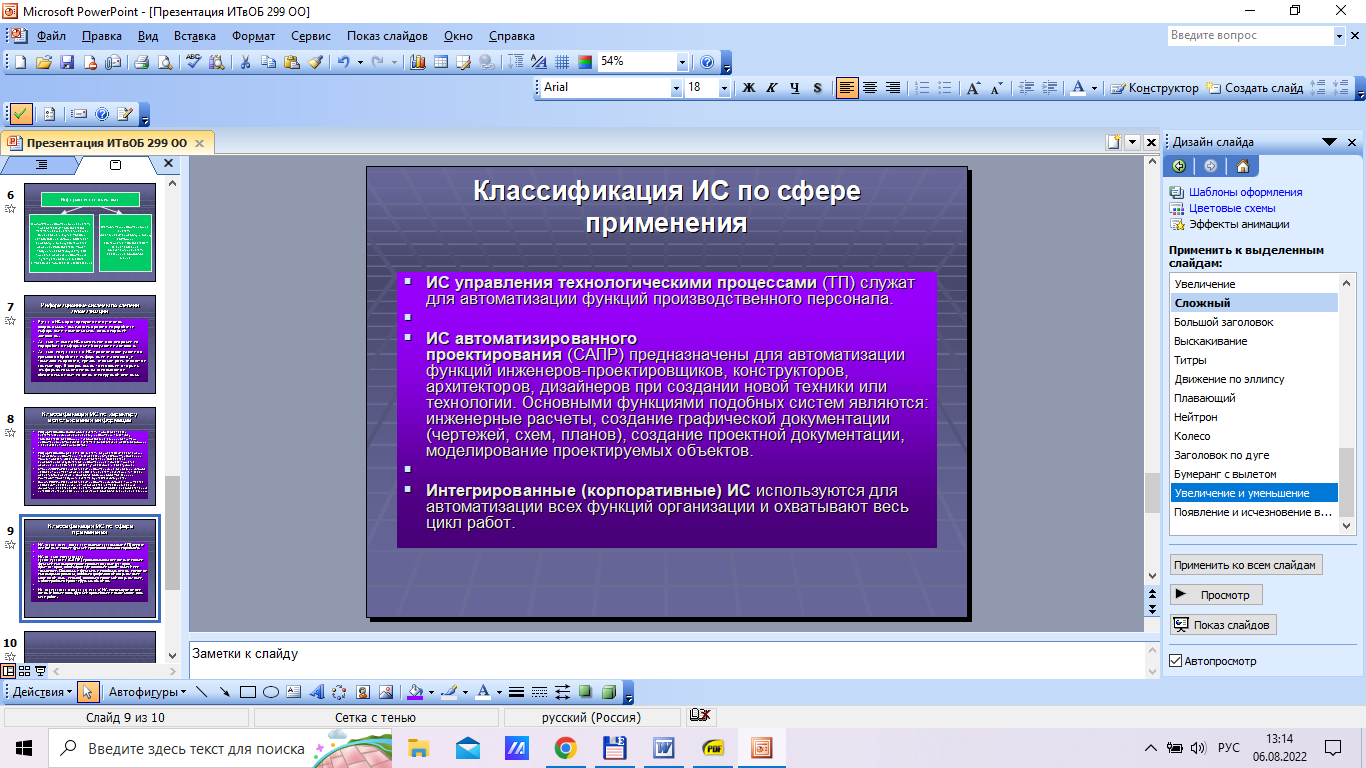  3. Задание: Анализ статистических данных по Приморскому краюПостроить интервальные вариационные ряды и гистограммы для исходных временных рядов (количество пожаров, данные о погибших и пострадавших при пожарах). Таблица 1 – Статистические данные по Приморскому краю
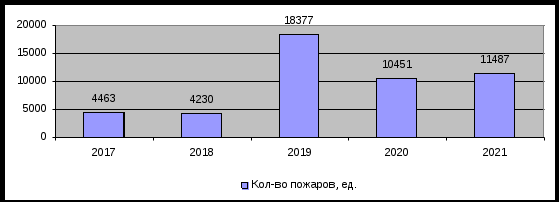 Рис. 6. Количество пожаров в Приморском крае за 2017-2020гг. 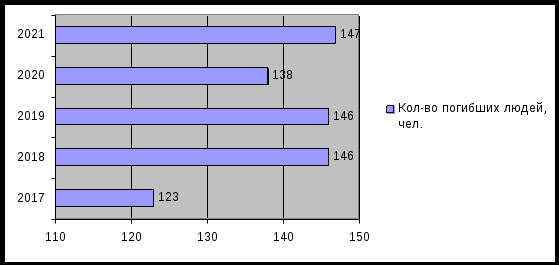 Рис. 7. Количество погибших в Приморском крае за 2017-2020гг. 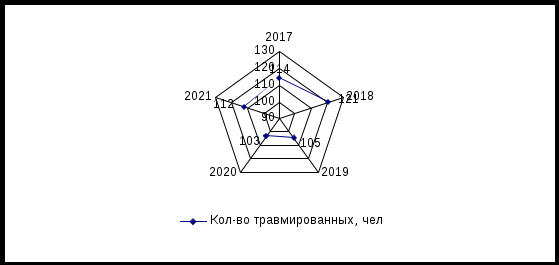 Рис. 8. Количество травмированных в Приморском крае за 2017-2020гг. 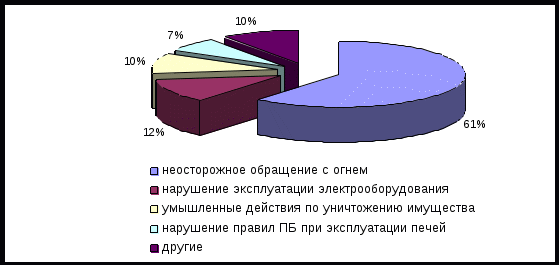 Рис. 9. Структура основных причин пожаров в Приморском крае в 2021 году 2. Найти основные числовые характеристики вариационного ряда (при необходимости использовать упрощающие формулы): 1) выборочное среднее xв; Таблица 2 – Выборочное среднее
Окончание таблицы 2
2) выборочную дисперсию D В (X); Дисперсия, вычисляемая по выборочным данным, называется выборочной дисперсией. 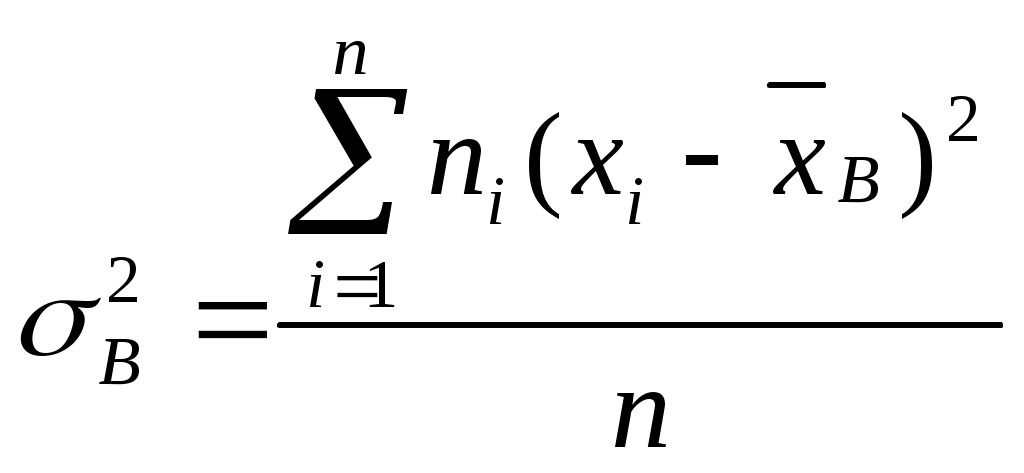 - выборочная дисперсия пожаров =86737405,6 - выборочная дисперсия погибших =12626 - выборочная дисперсия пострадавших =8142 3) выборочное среднее квадратическое отклонение Стандартным отклонением (средним квадратическим отклонением) называется корень квадратный из дисперсии: - выборочное среднее квадратическое отклонение пожаров √86737405,6=9313 - выборочное среднее квадратическое отклонение погибших √12626=36 - выборочное среднее квадратическое отклонение пострадавших √8142=90 4) моду М о ; Наиболее часто встречающееся значение ряда является модой, - количество пожаров 2019 (18377) - количество погибших 2021 (147) - количество пострадавших 2018 (121). 5) коэффициент вариации V; Коэффициент выражается в процентном отношении и вычисляется по формуле: - коэффициент вариации по количеству пожаров V=9313/2090*100=446% - коэффициент вариации по количеству погибших V=36/28*100=127% - коэффициент вариации по количеству пострадавших V=90/21*100=43% Если коэффициент вариации не превышает 10 %, то выборку можно считать однородной, т. е. полученной из одной генеральной совокупности. В нашем случае выборка неоднородна. 3. Построить прогнозную модель для временного ряда: количество пожаров. Используем для прогнозирования метод скользящей средней. Таблица 3
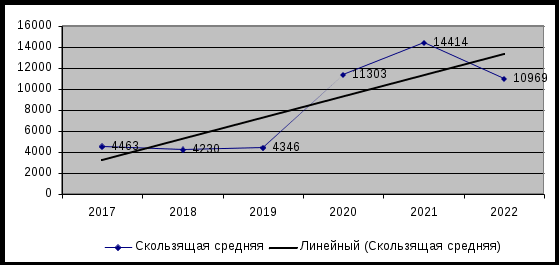 Рис. 10. Прогнозная модель для временного ряда (2022 г.) с трендом В соответствии с прогнозной моделью в Приморском крае в 2022 году ожидается примерно 10969 пожаров. Список литературы1. Гаврилов, М.В. Информатика и информационные технологии: Учебник для прикладного бакалавриата / М.В. Гаврилов, В.А. Климов. - Люберцы: Юрайт, 2019. - 383 c. 2. Грошев А. С., Закляков П. В. Информатика. Учебник. - М.: ДМК Пресс, 2019. - 674 с. 3. Кизбикенов, К. О. Прогнозирование и временные ряды [Электронный ресурс]: учебное пособие / К. О. Кизбикенов. – Барнаул : АлтГПУ, 2017. –115 с. 4. Модель удаленного управления данными. Модель файлового сервера [Электронный ресурс]. – Режим доступа: https://studopedia.ru/13_48483_model-udalennogo-upravleniya-dannimi-model-faylovogo-servera.html 5. Набиуллина С.Н. Информатика и ИКТ. Курс лекций. - М.: Лань, 2019. - 72 с. 6. Олифер, В. Г. Компьютерные сети: принципы, технологии, протоколы : учеб. пособие для высш. учеб. заведений. – 4-е изд.– СПб. : Питер, 2010. – 944 с. 7. Пожары и пожарная безопасность в 2021 году: статист. сб. - Балашиха: ФГБУ ВНИИПО МЧС России, 2022. - 114 с. 8. Распределённые технологии обработки и хранения данных [Электронный ресурс]. – Режим доступа: http://eor.dgu.ru/lectures_f/%D0%98%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0% %D0%BE%D0%B3%D0%B8%D0%B8/html 9. Софронова Н. В., Бельчусов А. А. Теория и методика обучения информатике. Учебное пособие. М.: Юрайт, 2020. 402 с. 10. Хуснутдинов, Р.Ш. Математическая статистика: Учебное пособие / Р.Ш. Хуснутдинов. - М.: Инфра-М, 2018. - 384 c. 1 Модель удаленного управления данными. Модель файлового сервера [Электронный ресурс]. – Режим доступа: https://studopedia.ru/13_48483_model-udalennogo-upravleniya-dannimi-model-faylovogo-servera.html | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||