Расчетно графическая работа сводный анализ нейронных систем распознавания аудио материалов
 Скачать 1.69 Mb. Скачать 1.69 Mb.
|

Подготовка данных для систем распознавания речиДля систем распознавания речи можно выделить несколько типов данных. В следующей таблице перечислены допустимые типы данных, ситуации использования каждого типа данных и их рекомендуемое количество. Для создания модели требуется не каждый тип данных. Требования к данным зависят от того, тестируете ли вы модель или обучаете ее. Таблица 2 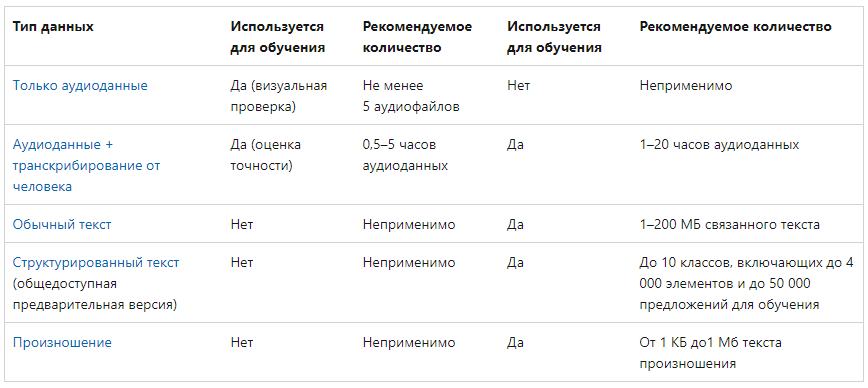 Перед тем как предпринимать попытки распознавания речи, нужно выполнить предварительную обработку речевого сигнала. В ходе этой обработки следует удалить шумы и посторонние сигналы, частотный спектр которых находится вне спектра человеческой речи. Отфильтрованный звуковой сигнал нужно оцифровать, выполнив аналого-цифровое преобразование. Этот этап обработки мы тоже уже обсуждали ранее. Всю предварительную обработку звукового сигнала можно сделать при помощи стандартного звукового адаптера, установленного в компьютере. Дополнительная цифровая обработка звукового сигнала (например, частотная фильтрация) может выполняться центральным процессором компьютера. Таким образом, при использовании современных персональных компьютеров системы распознавания речи не требуют для своей работы какого-либо специального аппаратного обеспечения. Важным этапом предварительной обработки входного сигнала является нормализация уровня сигнала. Это позволяет уменьшить погрешности распознавания, связанные с тем, что диктор может произносить слова с разным уровнем громкости. Заметим, однако, что если входной звуковой сигнал имеет слишком малый уровень громкости, то после нормализации может появиться шум. Поэтому для успешной работы системы распознавания речи необходимо отрегулировать оптимальным образом чувствительность микрофона. Чрезмерная чувствительность может привести к нелинейным искажениям сигнала и, как следствие, к увеличению погрешности распознавания речи. Описание процесса распознавания речиРассмотрим простейшую схему распознавания отдельно произносимых слов речи (рис. 11). 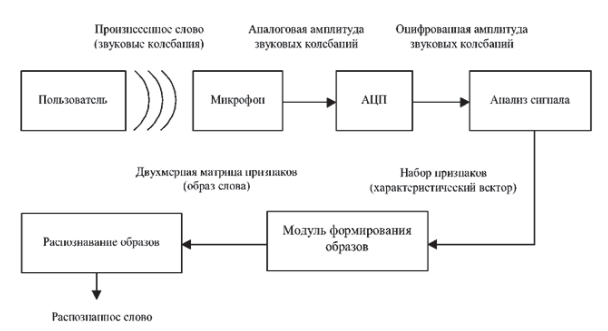 Рис. 11 Схема распознавания отдельно произносимых слов речи Процесс распознавания в этом случае можно разделить на три этапа. На первом этапе акустический препроцессор преобразует входной речевой сигнал в последовательность векторов признаков или акустических векторов, извлекаемых через фиксированные промежутки времени. Как правило, эти векторы содержат спектральные или кепстральные коэффициенты, характеризующие короткие отрезки речевого сигнала. На втором этапе векторы сравниваются с эталонами, содержащимися в моделях слов, и вычисляются их локальные метрики или меры соответствия (в общем случае сравниваются речевые сегменты, представленные несколькими векторами признаков). На третьем этапе эти метрики используются для временного выравнивания последовательностей векторов признаков с последовательностями эталонов, образующими модели слов, и вычисляются меры соответствия для слов. Временное выравнивание используется для компенсации изменений в скорости произнесения. После выполнения всех этих операций распознаватель выбирает слово, для которого мера соответствия максимальна. При распознавании слитной речи локальные метрики, полученные на втором этапе вычислений, используются для временного выравнивания и определения мер соответствия для отдельных предложений или высказываний. В схеме распознавания, изображенной на рис.1, НС наиболее успешно используются на второй стадии вычислений при расчете локальных метрик. Для статистических распознавателей с непрерывным наблюдением данные метрики являются монотонными функциями функций правдоподобия векторов признаков. Распознаватели речи с дискретным наблюдением сначала выполняют векторное квантование и присваивают каждому вектору признаков определенный символ из кодовой книги. Затем на основе этих символов с помощью специальных таблиц, содержащих вероятности наблюдения символов для каждого эталонного вектора, вычисляются локальные метрики. Такие вычисления могут быть выполнены однослойными перцептронами (рисунок 12), состоящими из линейных узлов, число которых равно числу эталонов. Число входов такого перцептрона должно быть равным числу возможных символов. 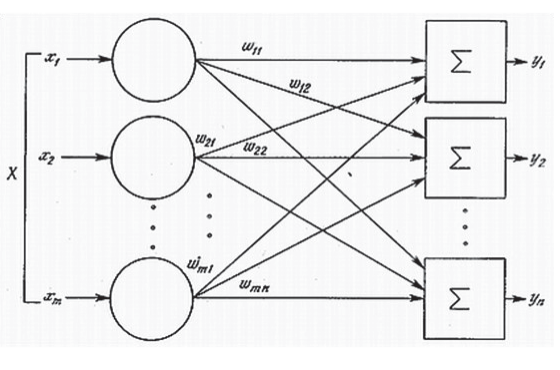 Рис. 12 Однослойный перцептрон Векторное квантование может быть выполнено с помощью сети, подобной карте признаков Кохонена (рисунок 13). Т акая сеть представляет собой двумерный массив узлов кодовой книги, содержащий по одному узлу на каждый возможный символ. Каждый узел вычисляет евклидово расстояние между входным вектором сети и соответствующим эталоном, представленным весами узла, после чего выбирается узел с наименьшим евклидовым расстоянием. Веса дан- SCIENCE TIME 32 ной сети вычисляются с помощью алгоритма Кохонена, его модификаций или с помощью любого другого традиционного алгоритма векторного квантования, использующего в качестве метрики евклидово расстояние (например, с помощью алгоритма к-средних). 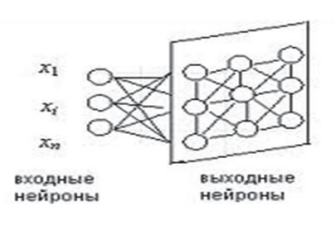 Рис. 13 Нейронная сеть Кохонена Многослойные нейронные сети (рисунок 14) также могут быть использованы для снижения размерности векторов признаков, извлекаемых препроцессором на начальном этапе распознавания. Такая НС имеет столько же выходов, сколько и входов, и один или более слоев скрытых узлов. При обучении НС ее веса подбираются так, чтобы она могла воспроизводить на выходе любой входной вектор через небольшой слой скрытых узлов. Выходы этих узлов после обучения сети могут быть использованы в качестве входных векторов меньшей размерности для дальнейшей обработки и распознавания речи. В случае использоваться НС для классификации статических образов фонем, слогов и небольших словарей изолированных слов в качестве входного образа может быть выбран вектор признаков, характеризующий стационарный участок ее реализации. 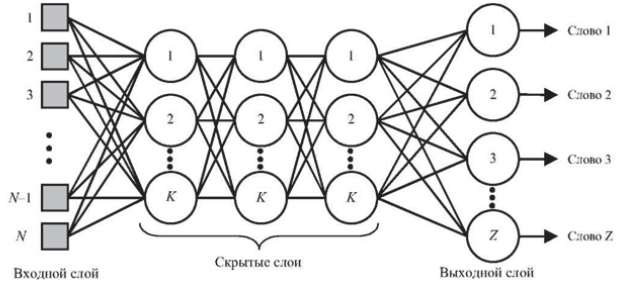 Рис. 14 Структура многослойной нейронной сети для распознавания речи Особый интерес вызывают динамические нейросетевые классификаторы, разработанные специально для распознавания речи и включающие в свой состав короткие временные задержки и узлы, выполняющие временное интегрирование, или рекуррентные связи. Обычно такие классификаторы мало чувствительны к небольшим временным сдвигам обучающих и контрольных выборок и, следовательно, не требуют для высококачественной работы точной сегментации речевых данных. Использование динамических сетей при распознавании речи позволяет преодолеть основные недостатки, присущие статическим сетям, и, как показывают экспериментальные исследования, приводит к превосходному качеству распознавания для акустически схожих слов, согласных и гласных. Нейронная сеть с временными задержками (НСВЗ) представляет собой многослойный перцептрон, узлы которого модифицированы введением временных задержек. Узел, имеющий N задержек τ, 2τ,…,Nτ , показан на рис.7. Он суммирует взятые в N+1 последовательных моментов времени J своих входов, умноженных на соответствующие весовые коэффициенты, вычитает порог и вычисляет нелинейную функцию F полученного результата. Архитектура трехслойной НСВЗ, предложенной для распознавания трех фонем (или трех классов фонем), показана на рис. 16 (на нем показаны связи только для одного выходного узла). На рис. 16 показано, что обработка сетью входной последовательности акустических векторов эквивалентна прохождению окон временных задержек над образами узлов нижнего уровня. На самом нижнем уровне эти образы состоят из сенсорного входа, т е акустических векторов Узлы скрытых слоев сети представляют собой движущиеся детекторы признаков и способны обнаруживать требуемые образы в любом месте входных последовательностей. Благодаря тому, что выходные узлы имеют равные веса связей со вторым слоем, любые моменты времени для таких детекторов являются равноправными. Это делает сеть инвариантной к временным сдвигам обучающих и контрольных образцов фонем (для случая, когда эти сдвиги не столь велики, чтобы важные ключевые признаки оказывались за пределами входной последовательности сети). Простая структура делает НСВЗ подходящей для стандартизованной СБИС-реализации с загружаемыми извне весами. 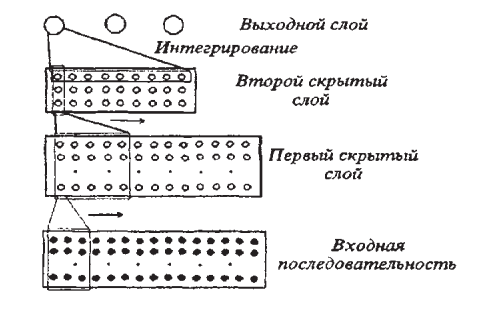 Рис. 16 Архитектура нейронной сети с временными задержками |