Расчетно графическая работа сводный анализ нейронных систем распознавания аудио материалов
 Скачать 1.69 Mb. Скачать 1.69 Mb.
|

Анализ проблем и целейОпределение проблемыДля распознавания человеческой речи придумано множество сервисов. Они способны довольно качественно преобразовать в печатный текст фразы, записанные в виде звукового файла. Но ни одно из этих приложений не может сортировать разные звуки, захваченные микрофоном. Что именно было записано: человеческая речь, крики животных или музыка? Опишем проблему при помощи схемы «потребность – желание – проблема – цель». Таблица 1 Описание проблемы
Постановка целей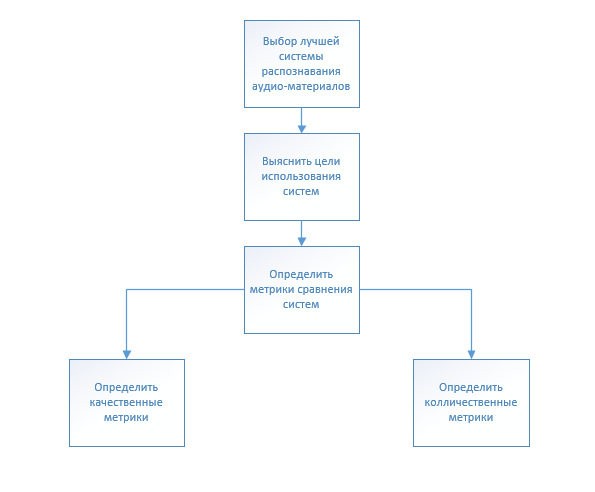 Рис. 1 Цели проведения исследования Для анализа систем, исходя из схемы целей, будем использовать две категории сравнения систем: количественные и качественные. Качественная метрика: Word Error Rate (WER) – количество ошибочных слов. Удобство использования. Количественные метрики: Количество пустых ответов. Пропускная способность. План исследованияТестирование производится на одних и тех же данных в формате wav (или просто PCM); Проведение запросов во все системы в 8 параллельных потоках; Расчет скорости делался отдельным небольшим прогоном без всяческой пред- или пост-обработки, чтобы не "загрязнять" метрики.; Считаем основную метрику –WER. На каждый домен тест аудио длился 1 час. Метрики считаются на нормализованных текстах (то есть без цифр, "как слышится, так и пишется"); Если у системы нет такого функционала, то мы нормализуем тексты самостоятельно. Все данные по умолчанию отправляются с родной частотой дискретизации (8 или 16 kHz); Теоретические аспекты области исследованияИстория развития систем распознавания речиДесять лет назад технологию speech recognition начали использовать для массовых коммерческих решений. Но распознавать речь так же хорошо, как люди, алгоритмы пока не могут. Им еще нужно научиться справляться с семантическими ошибками, различать контекст, определять акценты и работать быстрее. 1920 – 1930 года. Человеческая речь –это серия звуков. А звук –это совмещение волн, у которых две характеристики: амплитуда и частота. Первые попытки создать механизм, способный различать звуки, исследователи предпринимали в 1920-х. Никаких нейросетей и машинного обучения, только огромные аналоговые машины и идейные ученые. В 1927 году в США инженер Вестингаузовской электрической компании Рой Уэнсли создал робота «Телевокс» (рис. 2). Он распознавал речь благодаря собственным реле и камертонам. Все звуки разделялись на три тона, и за каждый отвечал свой камертон. В зависимости от того, какой камертон срабатывал, включалось определенное реле.  Рис. 2 Робот «Телевокс» со своим создателем. 1950 – 1960 года. Через 25 лет двое ученых из исследовательского центра Bell Labs создали машину Audrey. При условии правильной адаптации к динамику и пауз между словами, Audrey выдавала точность 97 – 99% и была способна распознать строки цифр от 1 до 9 (рис. 3). Машина трансформировала сказанные ей слова в электрические импульсы и сопоставляла их с имеющимися в ее памяти паттернами. После этого на панели управления подсвечивалась правильная цифра. Уникальная для своего времени Audrey впоследствии никак не использовалась: машина занимала почти всю комнату и потребляла уйму электроэнергии. Кроме того, она могла хорошо распознавать цифры, произносимые только одним человеком, поэтому коммерциализировать такое решение было почти невозможно. 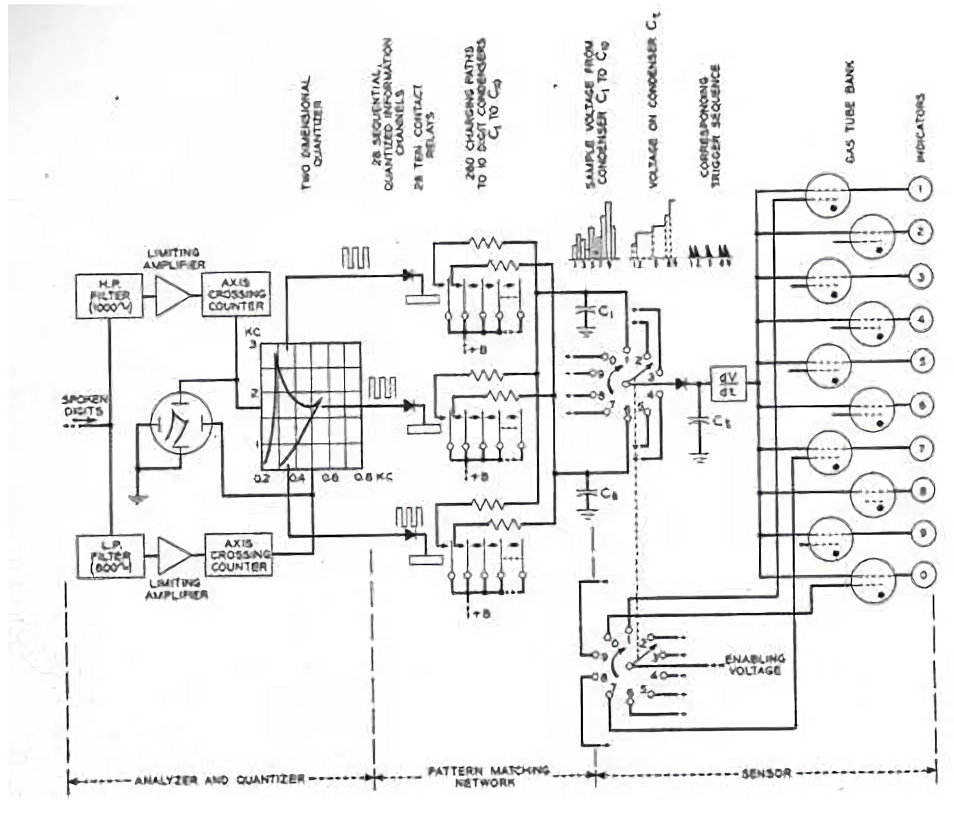 Рис. 3 Схема работы Audrey / Bell Labs. Через 10 лет, в 1962 году, IBM продемонстрировала их детище –систему "Shoebox", которая понимала 16 слов на английском. Лаборатории в США, Японии, Англии и СССР разработали еще несколько аппаратов, которые распознавали отдельные произнесенные звуки, расширив технологию распознавания речи поддержкой четырех гласных и девяти согласных звуков. Звучали они не очень хорошо, но эти первые попытки дали впечатляющий старт, особенно если учитывать, насколько примитивными были компьютеры того времени. 1970-е года. Системы распознавания речи сделали большие шаги в семидесятых благодаря интересу и спонсированию от министерства обороны США. Их программа DARPA Speech Understanding Research (SUR) с 1971 по 1976 год была одной из самой большой в истории распознавания речи, и помимо всего остального она отвечала за систему «Harpy» Университета Карнеги Меллона. «Harpy» понимала 1011 слов, что является средним словарным запасом трехлетнего ребенка. «Harpy» была значительной вехой, так как она представила более эффективный подход к поиску, называемый Beam search, «демонстрируя сеть возможных предложений с конечным числом состояний» ( Readings in Speech Recognition). 70-е годы также отмечены еще несколькими вехами в данной технологии, например, основанием первой коммерческой компании Threshold Technology, которая представила систему, которая могла интерпретировать различные голоса. 1980-е. В следующей декаде благодаря новым подходам и технологиям словарный запас подобных систем вырос с нескольких сотен до нескольких тысяч слов и имел потенциал распознавания неограниченного количества слов. Одной из причин был новый статистический метод, больше известный как скрытая марковская модель. Используя шаблоны для слов и звуковые паттерны, она рассматривала вероятность того, что неизвестные звуки могли быть словами. Эта база использовалась другими системами еще на протяжении двадцати лет С расширенным словарным запасом распознавание речи начало протаптывать себе дорожку в коммерческие приложения для бизнеса и специализированных отраслей, таких как медицина. Она даже вошла в дома обычных людей в 1987 году в виде куклы Worlds of Wonder's Julie doll, которые дети могли натренировать, чтобы она распознавала их голос. Хоть ПО по распознаванию могло распознавать до 5000 слов, как, например, программа Kurzweil text-to-speech, в них был огромный недостаток –эти программы поддерживали дискретную надиктовку, то есть вы должны были останавливаться после каждого слова, чтобы программа его обработала. 1990-е. В девяностые компьютеры наконец-то получили быстрые процессоры, и программы по распознаванию речи стали жизнеспособными. в 1990 году появилась первая общедоступная программа Dragon Dictate c ошеломляющей ценой 9000 долларов. Спустя семь лет вышла улучшенная версия –Dragon NaturallySpeaking. Приложение распознавало нормальную речь, поэтому вы могли говорить в обычном темпе около 100 слов в минуту. Но все равно, вы должны были тренировать программу в течении 45 минут перед использованием, и она имела все еще высокую цену в 695 долларов. Появление первого голосового портала VAL от BellSouth было в 1996 году. Это была первая интерактивная система распознавания речи, которая давала информацию, основываясь на том, что вы сказали в трубку телефона. VAL вымостила дорогу для всех неточных на то время голосовых меню, которые надоедали звонящим в следующие 15 лет. 2000-е. К 2001 году распознавание речи поднялось до 80-процентной точности, и прогресс технологии остановился. Системы распознавали работали отлично, когда языковая вселенная была ограниченной, но они до сих пор «догадывались» при помощи статистических моделей среди похожих слов, языковая вселенная росла вместе с ростом Интернета. Технология распознавания речи получила второе дыхание после одного важного события: появления приложения Google Voice Search для iPhone. Влияние этого приложения было значительным по двум причинам. Во-первых, телефоны и другие мобильные девайсы –это идеальные объекты для распознавания речи, и желание заменить крошечные экранные клавиатуры альтернативными методами ввода было очень велико. Во-вторых, у Google была возможность разгрузить этот процесс, используя свои облачные дата-центры, направив всю их мощь для крупномасштабного анализа данных для поиска совпадений между словами пользователей и огромного числа образцов голосовых запросов, которые они получали. Вкратце, узким местом распознавания речи всегда было доступность данных и возможность эффективной их обработки. Приложение же добавило к анализу данные миллиардов поисковых запросов, чтобы лучше предугадывать, что же вы сказали. В 2010 году Google добавил персональное распознавание в голосовой поиск телефонов под управлением Android. Программное обеспечение могло записывать голосовые запросы пользователей для построения более точной голосовой модели. Также компания добавила распознавание голоса в свой браузер Chrome в середине 2011 года. Помните, как мы начали с 10 слов и продвинулись до нескольких тысяч? Так вот система Google теперь позволяет распознать 230 миллиардов слов. |