лаб 2 отипис готовая. лаб 2 ОТИПИС готовая. Разработка алгоритмов и программ для моделирования информационных подсистем
 Скачать 375.01 Kb. Скачать 375.01 Kb.
|

|
Министерство образования и науки Республики Казахстан Карагандинский технический университет Кафедра ИВС Лабораторная работа №2 Дисциплина: «Основы теории информационных процессов и систем» Тема: «Разработка алгоритмов и программ для моделирования информационных подсистем» Выполнила: студент группы ИС-21-2 Орманова Е.Е. Проверила: Ашимбекова А.М. Караганда 2021 Тема:Разработка алгоритмов и программ для моделирования информационных подсистем Цель:составление алгоритмов и программ для моделирования информационных подсистем Задание: Составить по блок схеме программу на алгоритмическом языке для решения доставленной задачи. Описание входных данных LAM-интенсивность потока необработанных документов на входе системы обработки информации; MUO-интенснвность обработки документов в каждом канале; ΜUΙ-интенсивность изъятия документов из фонда; KD-интенсивность обращения каждого внешнего пользователя с запросом; М-число внешних пользователей; LP-среднее количество первичных информационных документов, выдаваемых на каждый запрос; GАМ-среднее время задержки внешним пользователем документа при его получении;
Листинг программы import math def step(a,b): return math.exp(math.log(a) * b) Lam = int(input("Введите интенсивность потока необработанных документов на входе системы обработки информации ")) Muo = int(input("Введите интенснвность обработки документов в каждом канале ")) Mui = float(input("Введите интенсивность изъятия документов из фонда")) Kd = int(input("Введите интенсивность обращения каждого внешнего пользователя с запросом ")) M = int(input("Введите число внешних пользователей ")) Lp = int(input("Введите среднее количество первичных информационных документов, выдаваемых на каждый запрос ")) Gam = int(input("Введите среднее время задержки внешним пользователем документа при его получении ")) print("Lam =", Lam, " Muo =", Muo) Ksi = Lam / Muo N = 1 while Ksi >= 1: N = N + 1 Ksi = Ksi / N print("Число каналов обработки информации, необходимое для стационарного режима работы = ", N) K = Lam / Muo print("Cpeднee число занятых каналов обработки информации = ", K) Pn = step(Lam / Muo, N) / step(2.718, Lam / Muo) Kv = 2 while Kv < N: Pn = Pn / Kv Kv += 1 Rr = 1 / step(2.718, Lam / Muo) Kv = 1 while Kv < N: Rn = step(Lam / Muo, Kv) / step(2.718, Lam / Muo) i = 1 while i < Kv: Rn = Rn / i i += 1 Rr += Rn Kv += 1 Pn = Pn / (Rr + Pn * Ksi / (1 - Ksi)) Ir = Pn * Ksi / step((1 - Ksi), 2) print("Cpeднee число необработанных документов, находящихся в очереди на обработку ", Ir) D = Ir * ((1 + Ksi) / (1 - Ksi) - Ir) print("Дисперсия числа документов в очереди = ", D) G = math.sqrt(D) print("Среднee квадратическое отклонение числа документов в очереди = ", G) L = Ir + K print("Cpeднee число документов, находящихся в системе обработки информации = ", L) Tot = Ir / Lam * 365 * 24 * 60 print("Среднее время нахождения документа в очереди на обработку = ", Tot) Tob = 1 / Muo * 365 * 24 * 60 print("Среднее время нахождения документа на обработке = ", Tob) T = Tot + Tob print("Cpeднee время нахождения документа в системе обработки информации = ", T) print("Muo = ", Muo) D = Lam / Mui print("Дисперсия при стационарном режиме = ", D) Ist = Lam / Mui print("Числo документов в фонде в установившемся режиме = ", Ist) G = math.sqrt(D) print("Cpeднee квадратическое отклонение числа хранимых в фонде документов = ", G) Var = math.sqrt(Mui / Lam) print("Коэффициент вариации числа хранимых в фонде документов = ", Var) Ksi = Lp * N * Kd print("Интенсивность выдачи документов из фонда на запросы внешних пользователей = ", Ksi) print("Gam = ", Gam) D = Ksi * Gam print("Дисперсия в стационарном режиме = ", D) D = D / M print("Дисперсия в стационарном режиме = ", D)  Результат работы программы   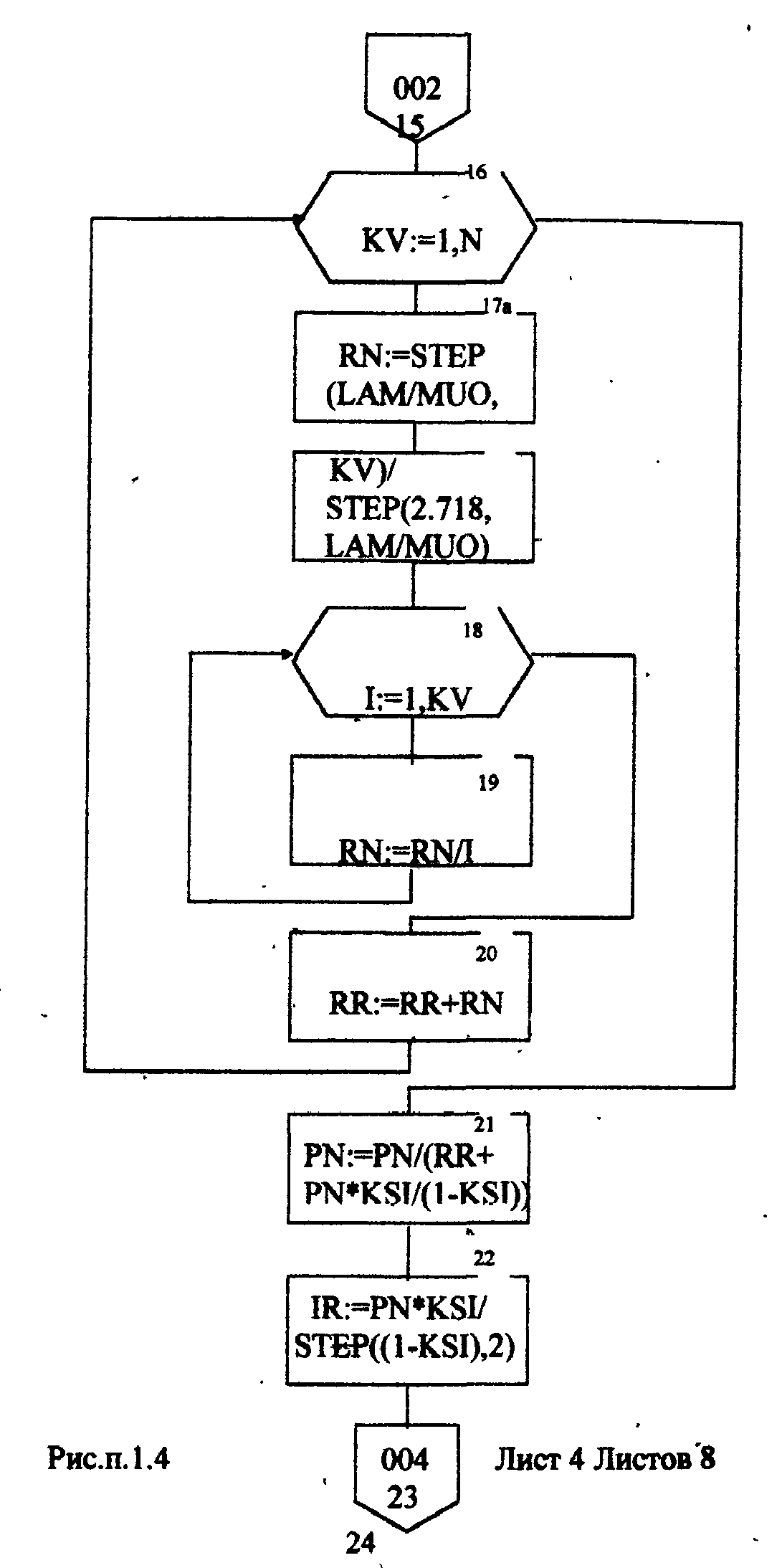    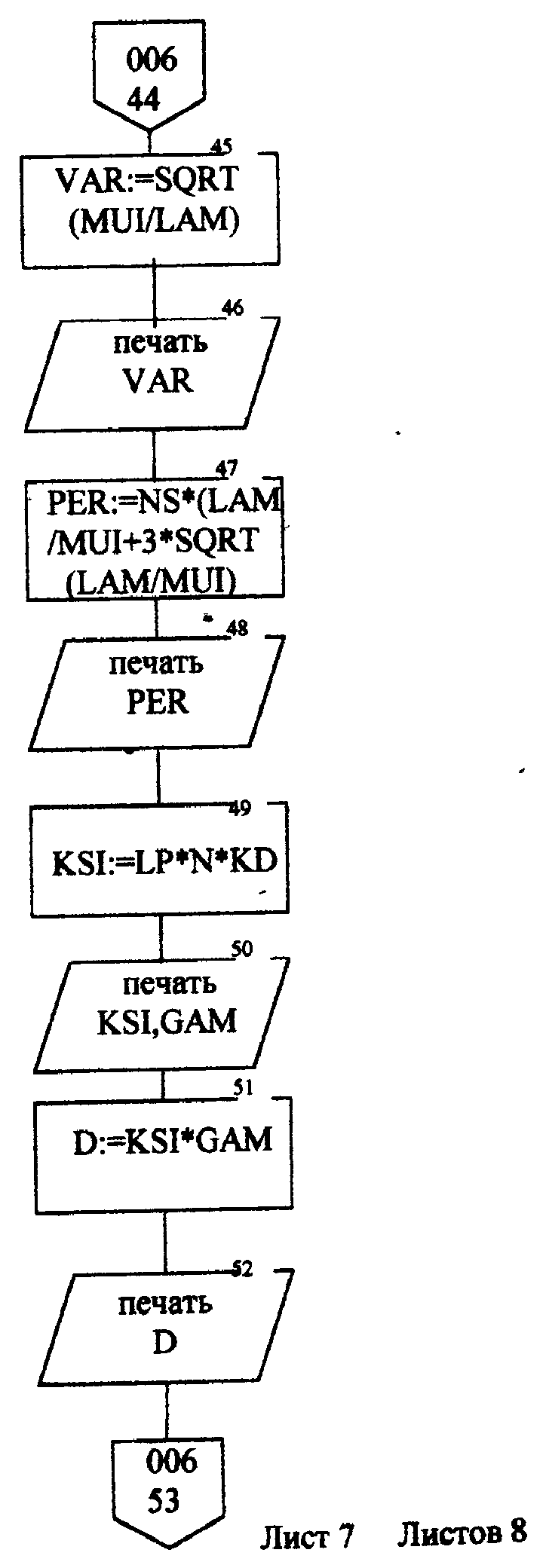  Контрольные вопросы: 1.Параметры пуассоновского потока. Особенности стационарного режима работы.Пуассоновский поток — это ординарный поток без последствия. По закону Пуассона вероятность того, что за интервал времени (t0, t0 + τ) произойдет m событий: 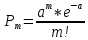 , где а — параметр Пуассона. , где а — параметр Пуассона.  . Если λ(t) = const(t), то это стационарный поток Пуассона (простейший). В этом случае a = λ · t. Если λ = var(t), то это нестационарный поток Пуассона. Стационарный поток существует только при . Если λ(t) = const(t), то это стационарный поток Пуассона (простейший). В этом случае a = λ · t. Если λ = var(t), то это нестационарный поток Пуассона. Стационарный поток существует только при здесь λ - интенсивность потоков необработанных документов; μ -интенсивность обработки документов в каждом канале; η - число каналов обработки. 2.Время переходного процесса системы обслуживания. Длительность переходного процесса в системе характеризует её быстродействие, а его характер определяет качество системы. За количественную характеристику длительности переходного процесса принимают время, необходимое выходному сигналу системы для того, чтобы приблизиться к своему установившемуся значению.| 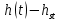 | ≤ϵ, где | ≤ϵ, где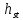 — установившееся значение; ϵ — наперёд заданное положительное число. — установившееся значение; ϵ — наперёд заданное положительное число.3. Особенности математической модели процесса накопления информации. Назначение технологического процесса накопления данных состоит в создании, хранении и поддержании в актуальном состоянии информационного фонда, необходимого для выполнения функциональных задач системы управления. Хранение и накопление информации осуществляется в информационных базах в виде информационных массивов, где данные располагаются по установленному в процессе проектирования порядку.С хранением и накоплением непосредственно связан поиск данных, т. е. выборка нужных данных из хранимой информации, включая поиск информации, подлежащей корректировке или замене. Процедура поиска информации выполняется автоматически на основе составленного пользователем или компьютерной системой запроса на нужную информацию. Указанные функции, выполняемые в процессе накопления данных, реализуются по алгоритмам, разработанным на основе соответствующих математических моделей.Процесс накопления данных состоит из ряда основных процедур, таких, как выбор хранимых данных, хранение данных, их актуализация и извлечение. Если интенсивность изъятия, одного документа μ есть величина постоянная, то это означает, что каждый принятый на хранение документ будет находиться в базах данных случайное время Т, распределенное по показательному закону с математическим ожиданием:  . .4.Особенности математической модели режима работы информационного фонда с точки зрения пользователя. Обозначим величиной λn интенсивность обращения каждого из m внешних пользователей в банк данных с запросами.· На каждый запрос в среднем выдается k первичных информационных документов (ПИД). В этом случае интенсивность выдачи документов из фонда на запросы m внешних пользователей будет  . .Обозначим среднее время задержки внешним пользователем ПИД при его получении величиной  (в это время можно включать и время копирования ПИД), тогда интенсивность возврата внешним пользователем каждого взятого по запросу ПИД будет равна γ. (в это время можно включать и время копирования ПИД), тогда интенсивность возврата внешним пользователем каждого взятого по запросу ПИД будет равна γ.Среднее время ожидания возврата ПИД затребованного внешним пользователем в фонде, будет определятся по формуле  Если среднее время ожидания возврата ПИД является неприемлемым для внешних пользователей, то необходимо вводить копирование всех ПИД при их выдаче или иметь копии всех ПИД. 5.Среднее число документов в подсистеме обработки документов. Среднее число документов, находящихся в системе обработки документов 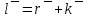 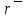 - среднее число необработанных документов, находящихся на очереди в обработку, - среднее число необработанных документов, находящихся на очереди в обработку,  - среднее число занятых каналов обработки информации. - среднее число занятых каналов обработки информации.6.Среднее время нахождения документа в системе обработки информации. Среднее время нахождения документа в системе обработки информации 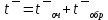 - среднее время нахождения документа на обработке. - среднее время нахождения документа на обработке.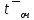 - среднее время нахождения документа в очереди на обработку, - среднее время нахождения документа в очереди на обработку,  7.Параметры, определяющие потребное количество персонала фонда.  . m - число документов в фонде в установившемся режиме, n - количество сотрудников, необходимое для хранения одного документа. . m - число документов в фонде в установившемся режиме, n - количество сотрудников, необходимое для хранения одного документа.8.Параметры, определяющие среднее число документов у каждого пользователя в режиме работы фонда с точки зрения пользователя. Среднее число документов у каждого пользователя. 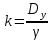 . Dy - дисперсия и среднее квадратическое отклонение числа выдаваемых документов. -среднее время задержки внешним пользователем документа. . Dy - дисперсия и среднее квадратическое отклонение числа выдаваемых документов. -среднее время задержки внешним пользователем документа.9.Интенсивность выдачи документов из фонда на запросы внешних пользователей. Интенсивность выдачи документов из фонда на запросы внешних пользователей ,здесь λn -среднее число документов выдаваемых на запрос; k - интесивность обращения каждого из внешних пользователей в фонд с запросами. m - число документов в фонде в установившемся режиме.  |