Базы данных курсовая. ТБД_курсовая. Разработка бд для асу Московская доставка Курсовая работа Студента 4 курса дневного отделения группа Студент (подпись)
 Скачать 0.87 Mb. Скачать 0.87 Mb.
|

2.2 Обоснование выбора модели данныхПод даталогической моделью понимается модель, отражающая логические взаимосвязи между элементами данных безотносительно их содержания и физические организации. При этом даталогическая (или просто логическая) модель строится на основе инфологической модели конкретной предметной области, с учётом её особенностей. Существуют несколько типов даталогических моделей данных: сетевая модель; иерархическая модель; объектно-ориентированная модель; реляционная модель; Для того, чтобы создать даталогическую модель данных для информационной системы на основе инфологической, необходимо сначала выбрать один из ее типов, приведенных выше. Далее сделать выбор СУБД, в которой будет реализована БД, так как даталогическую модель строят в терминах конкретной СУБД. Рассмотрим каждый из типов даталогичской модели. 2.2.1 Иерархическая модельИерархическая модель данных — это модель данных, где используется представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней. Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами (в программировании применительно к структуре данных дерево устоялось название братья). Основными информационными единицами в иерархической модели данных являются сегмент и поле. Поле данных определяется как наименьшая неделимая единица данных, доступная пользователю. Для сегмента определяются тип сегмента и экземпляр сегмента. Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента — это поименованная совокупность входящих в него типов полей данных. Первую вершину называют корневой вершиной. Она удовлетворяет условиям: Иерархия начинается с корневой вершины. Каждая вершина соответствует одному или нескольким атрибутам. Hа уровнях с большим номером находятся зависимые вершины. Вершин предшествующего уровня является начальной для новых зависимых вершин. Каждая вершина, находящаяся на уровне i, соединена с одной и только одной вершиной уровня i-1, за исключением корневой вершины. Корневая вершина может быть связана с одной или несколькими зависимыми вершинами. Доступ к каждой вершине происходит через корневую по единственному пути Существует произвольное количество вершин каждого уровня. Иерархическая модель представляет собой связный неориентированный граф древовидной структуры, объединяющий сегменты. Иерархическая БД состоит из упорядоченного набора деревьев. Плюсы иерархической модели данных: Простота использования и построения Обеспечение определенного уровня независимости данных Простота оценки операционных характеристик Минусы иерархической модели данных: Отношение “многие ко многим” реализуется очень громоздко и приводит к появлению избыточности данных, что нежелательно на физическом уровне Иерархическая упорядоченность усложняет операции удаления и включения Доступ к любой вершине возможен только через корневую, что увеличивает время доступа П 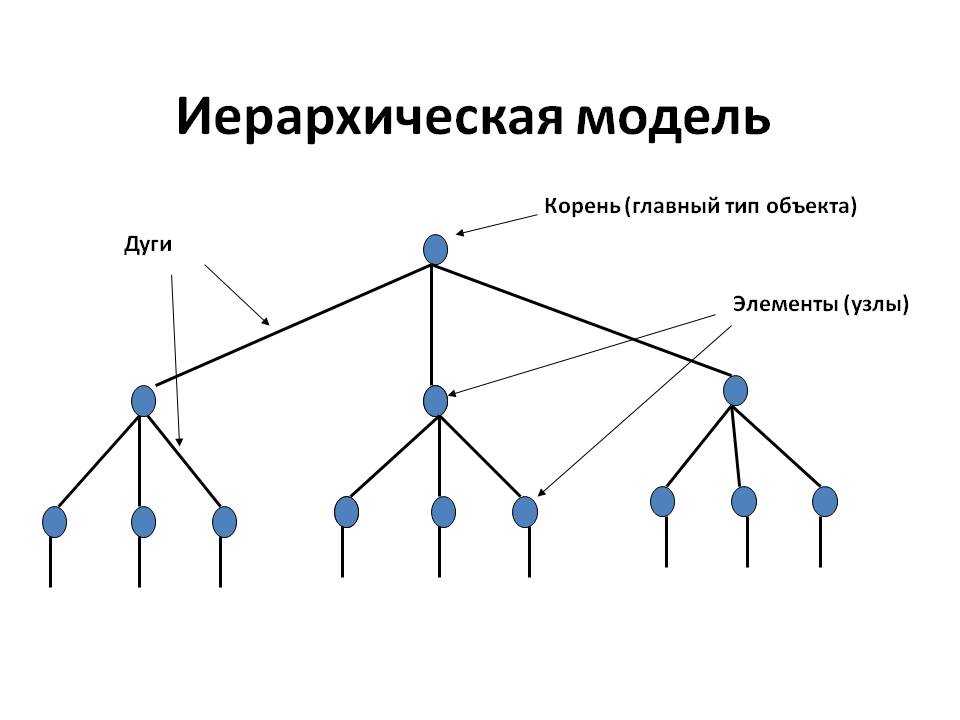 ример иерархической модели приведен на рисунке 5. ример иерархической модели приведен на рисунке 5.Рисунок 5 – Иерархическая модель данных 2.2.2 Сетевая модель данныхСетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных. Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков. Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями. Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия: каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L; каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L Плюсы сетевой модели данных: Возможность эффективной реализации по показателям затрат памяти и оперативности Минусы сетевой модели данных: Высокая сложность и жесткость схемы БД Не является полностью независимой П 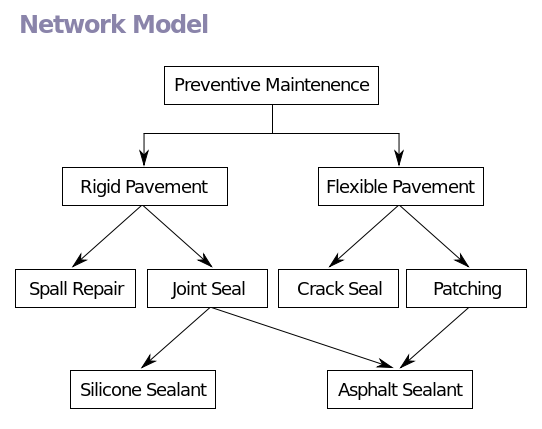 ример сетевой модели приведен на рисунке 6: ример сетевой модели приведен на рисунке 6:Рисунок 6 – Сетевая модель данных |