Базы данных курсовая. ТБД_курсовая. Разработка бд для асу Московская доставка Курсовая работа Студента 4 курса дневного отделения группа Студент (подпись)
 Скачать 0.87 Mb. Скачать 0.87 Mb.
|

2.2.3 Объектно-ориентированная модель данныхВ объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы данных. Между записями и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования. Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное различие между ними состоит в методах манипулирования данными. Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма. Плюсы объектно-ориентированной модели: Возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки. Минусы объектно-ориентированной модели: Высокая понятийная сложность Неудобство обработки данных Низкая скорость выполнения запросов 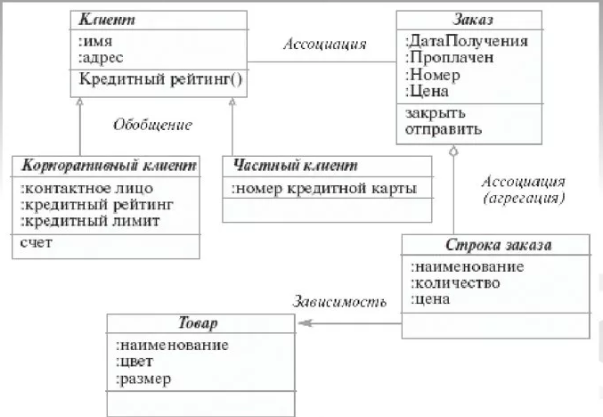 Пример объектно-ориентированной модели приведен на рисунке 7: Пример объектно-ориентированной модели приведен на рисунке 7:Рисунок 7 – Объектно-ориентированная модель данных 2.2.4 Реляционная модель данныхНедостатки иерархической и сетевой моделей привели к появлению новой, реляционной модели данных, созданной Коддом в 1970 году и вызвавшей всеобщий интерес. Реляционная модель была попыткой упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы. Реляционной называется база данных, в которой все данные, доступные пользователю, организованны в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами. Представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название "реляционная" происходит от английского relation - "отношение"). Реляционная СУБД также способна реализовать отношения предок/потомок, однако эти отношения представлены исключительно значениями данных, содержащихся в таблицах. Ограничения реляционной модели: Должны отсутствовать записи-дубликаты Столбцы реляционной таблицы поименованы, поэтому их порядок не важен. Порядок записей может быть произвольным Каждая запись уникальна и однозначно определяется значением ключа. Каждый элемент таблицы называется полем, может быть однозначно определен. В столбце записываются данные одного типа Недостатки традиционных реляционных моделей: Избыточность по полям (из-за создания связей) В качестве основного и, часто, единственного механизма, обеспечивающего быстрый поиск и выборку отдельных строк таблице (или в связанных через внешние ключи таблицах), обычно используются различные модификации индексов, основанных на B-деревьях. Такое решение оказывается эффективным только при обработке небольших групп записей и высокой интенсивности модификации данных в базах данных. П  ример реляционной модели приведен на рисунке 8: ример реляционной модели приведен на рисунке 8:Рисунок 8 – Реляционная модель данных 2.3 Логическое проектирование БД курьерской службы “Московская доставка”Рассмотрев все типы моделей данных, было принято решение, что для логического проектирования будет использоваться реляционная модель данных, т.к. она наиболее полно соответствует требованиям, предъявленным к разрабатываемой информационной системе: отсутствие дублируемой информации; поддержание целостности данных при вставке, удалении или изменении записей; возможность организации всех видов связи между отношениями 1:1, 1:M и M:M. В реляционной базе данных даталогическое проектирование приводит к разработке корректной схемы базы данных, т.е. такой схемы, в которой отсутствуют нежелательные зависимости между атрибутами. При этом можно использовать процесс проектирования с помощью декомпозиции, т.е. последовательно нормализовать схему отношений, тем самым накладывая ограничения и избавляясь от нежелательных зависимостей между атрибутами. В реляционных базах данных (РБД) даталогическое проектирование приводит к разработке схемы БД, т.е. совокупности схем отношений, адекватно моделирующих объекты ПО и семантических связей между ними. Основой анализа корректности схемы являются функциональные зависимости между атрибутами БД. В конце этого этапа должно быть получено описание схемы БД в терминах выбранной СУБД. Процесс разработки корректной схемы РБД и является даталогическим проектированием. Возможны 2-а способа: Декомпозиция (разбиение); Синтез; Для перехода от инфологической модели к реляционной существует специальный алгоритм: каждой сущности ставится в соответствие отношение; каждому атрибуту сущности ставится в соответствие соответствующий атрибут соответствующего отношения; первичный ключ сущности становится PK соответствующего отношения, при этом атрибуты, входящие в PK, обязательны для заполнения (NOT NULL); в каждое отношение, соответствующее подчинённой сущности, добавляется набор атрибутов основной сущности, являющийся в ней первичным ключом. В отношении, соответствующее подчинённой сущности эти атрибуты становятся FK (внешним ключом); по умолчанию, все атрибуты, не входящие в PK, необязательны; для отражения категоризации сущностей возможны несколько вариантов; все связи М:М должны быть раскрыты Воспользуемся данным алгоритмом и опишем каждую сущность инфологической модели: Клиенты: Идентификатор клиента – int, NOT NULL, PK Логин клиента – varchar(20), NOT NULL, UNIQUE Hash пароля клиента – varchar(50), NOT NULL, UNIQUE Имя клиента – varchar(45), NOT NULL, UNIQUE Тип клиента – varchar(20), NOT NULL Адрес клиента – varchar(45), NOT NULL Контактный номер – varchar(15), UNIQUE Электронный адрес – varchar(45), UNIQUE Курьеры: Идентификатор курьера – int, NOT NULL, PK Логин курьера – varchar(20), NOT NULL, UNIQUE Hash пароля курьера – varchar(50), NOT NULL, UNIQUE Имя курьера – varchar(45), NOT NULL, UNIQUE Дата рождения – date Паспортные данные – varchar(100), NOT NULL, UNIQUE Дата приема на работу – date, NOT NULL Контактный номер - varchar(15), NOT NULL, UNIQUE Менеджеры: Идентификатор менеджера – int, NOT NULL, PK Логин курьера – varchar(20), NOT NULL, UNIQUE Hash пароля курьера – varchar(50), NOT NULL, UNIQUE Имя курьера – varchar(45), NOT NULL, UNIQUE Дата рождения – date Паспортные данные – varchar(100), NOT NULL, UNIQUE Дата приема на работу – date, NOT NULL Контактный номер - varchar(15), NOT NULL, UNIQUE Заказы: Идентификатор заказа – int, NOT NULL, PK Идентификатор клиента– int, FK, NOT NULL Идентификатор курьера – int, FK, NOT NULL Дата доставки - date Метод оплаты – varchar(45), NOT NULL Идентификатор точки самовывоза– int, FK Идентификатор менеджера– int, FK, NOT NULL Количество по позиции: Идентификатор заказа – int, NOT NULL, PK Идентификатор товара– int, FK, NOT NULL Идентификатор заказа– int, FK, NOT NULL Количество – int, NOT NULL Товары: Идентификатор товара – int, PK, NOT NULL Название – varchar(45), NOT NULL, UNIQUE Цена – int, NOT NULL Описание– varchar(45) Точки самовывоза: Идентификатор точки – int, PK, NOT NULL Адрес точки – varchar(45), NOT NULL Склады: Идентификатор склада – int, PK, NOT NULL Адрес склада – varchar(45), NOT NULL Исходя из приведенных отношений, построим даталогическую схему БД (рисунок 9): 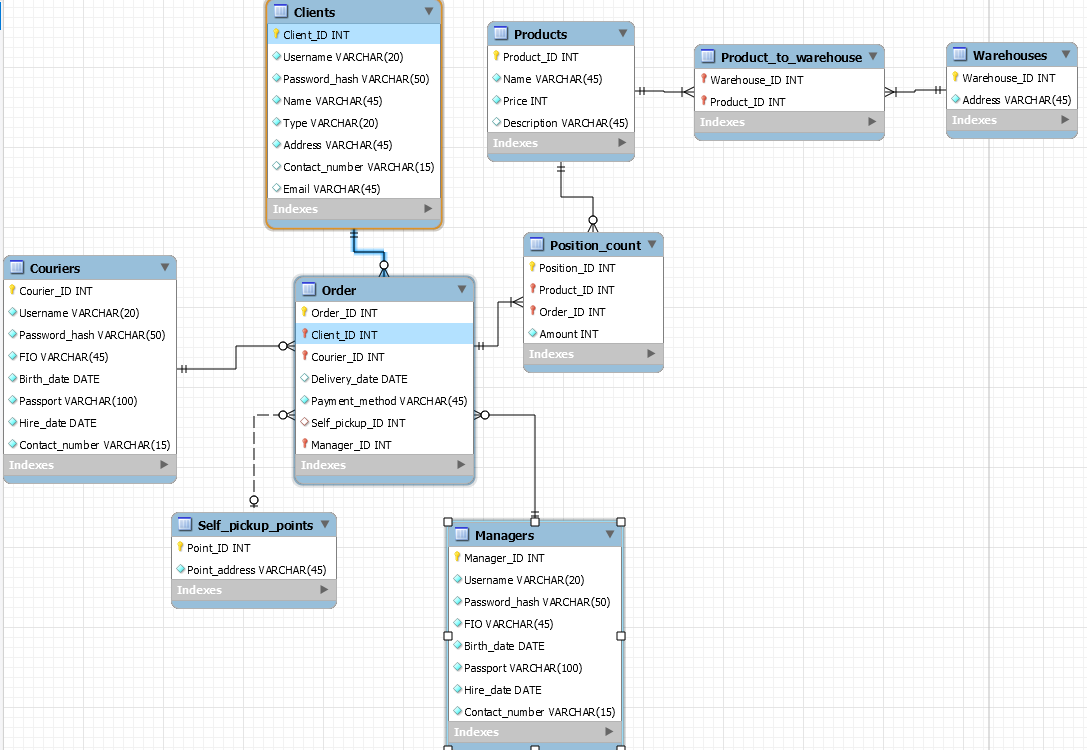 Рисунок 9 – Даталогическая схема БД |