Реферат. Реферат(тема 6). Реферат По дисциплине Информатика По теме Как работают кодировки текста
 Скачать 68.54 Kb. Скачать 68.54 Kb.
|

|
МИНОБРНАУКИ РОССИИ Санкт-Петербургский государственный электротехнический университет «ЛЭТИ» им. В.И. Ульянова (Ленина) Кафедра автоматики и процессов управления Реферат По дисциплине: Информатика По теме: «Как работают кодировки текста» Студенты: Группа: Проверил: Санкт-Петербург Содержание: Введение –3 Как устроена таблица символов – 3 Появление таблицы символов Unicode – 4 UTF-8 – 4 UTF-16 – 5 Заключение – 5 список литературы – 6 Введение Кодирование информации – это процесс формирования определенного представления информации. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Обычно каждый образ при кодировании представляется отдельным знаком. Знак, в свою очередь – это элемент конечного множества отличных друг от друга элементов. На компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определённым числом, а при выводе на внешнее устройство для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символа. Как правило, все числа в компьютере представляются в двоичной системе счисления, поскольку при этом устройства для их обработки получаются более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере. Как устроена таблица символов Для примера будет показана таблица символов ASCII. 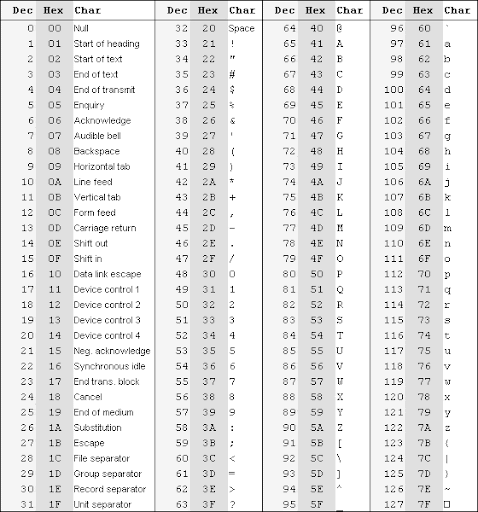 В подобных таблицах обычно используется 3 столбца: номер символа в десятичной системе счисления, символа в шестнадцатеричной системе счисления, представление самого символа. Как известно, компьютеры обрабатывают информацию в двоичной системе, но писать номер символа в двоичной системе в этой таблице слишком громоздко, поэтому в таблицах используют шестнадцатеричный номер. Катже его используют из-за лёгкого перевода числа из двоичной в шестнадцатеричную и наоборот. Появление таблицы символов Unicode Одна из основополагающих кодировок ASCII была восьмибитной, это означает, что каждый символ закодирован восемью битами и кодировка содержит 256 символов(28=256). Первые 128 символов были отданы под символы латинского алфавита, управляющие и грамматические символы. Остальные 128 отводились под национальные языки. На основе этого появилось огромная перечень национальных кодировок. При таком раскладе текст, напечатанный на одном языке определенной национальной кодировки, при отправке на компьютер с другой кодировкой отображает непонятные символы. Именно это было причиной создания таблицы символов Unicode. Она состоит из 1 114 112 позиций и разделена на 17 блоков по 65 536 символов. Каждый блок содержит свою группу символов. Большинство блоков ещё не заполнены. Таким образом появилась всеобъемлющая таблица, в которой зашифрованы все символы, которые могут понадобиться пользователю. Но при этом разные символы стали кодироваться разным количеством байт. Для решения этой проблемы используются юникод-кодировки, такие как UTF-8 и UTF-16. UTF-8 UTF-8 является юникод-кодировкой переменной длины, с помощью которой можно представить любой символ юникода. Структурной единицей этой кодировки является байт. Кодировка переменной длины означает то, что один символ может кодироваться разным количеством байт. Работает она следующим образом: первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. Если первый бит нулевой, то для кодирования символа используется один байт. Если первый бит ненулевой то символ кодируется несколькими байтами. Для двухбайтных символов первые 3 бита должны быть 110, для трёх-байтных - 1110 и для четырехбайтных -11110. UTF-16 UTF-16 также является кодировкой переменной длины. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. Таким образом символы в UTF-16 кодируются либо 2, либо 4 байтами. Двухбайтных символов может быть 65 535 (216), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами). Для кодирования символов за пределами базового диапазона юникода потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее. Для этого необходимо знать, что такое суррогатная пара. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатеричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара. Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно: из кода символа вычесть 10000(шестнадцатеричное). в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит. ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде). следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар). после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат. десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй. Заключение Возможно, данная тема уже не так актуальна как раньше и не требует понимания обычных пользователей пк, но она касается почти всех современных людей. Без кодировки текста пользователь не мог бы так легко и быстро воспринимать информацию, полученную из электронного устройства. Список литературы Кузьмин И.В., Кедрус В.А. – Основы теории информации и кодирования Д.М. Златопольский – Простейшие методы шифрования текста |