Роль и место информационноаналитических систем
 Скачать 440.38 Kb. Скачать 440.38 Kb.
|

Для выработки и принятия соответствующих складывающейся обстановке решений необходима информация, которая должна удовлетворять требованиям полноты, достоверности, своевременности (актуальности), полезности. Основополагающую роль в подготовке принятия решений играет его обоснование по имеющейся у ЛПР информации. Её, как правило, получают из различных внутренних и внешних источников. В интересах выработки адекватного решения используются внутренние информационные ресурсы, которые складываются из отражения деятельности (функционирования) объекта в документах, других видах и способах сбора, обработки, хранения информации, а также внешние по отношению к объекту информационные ресурсы, например (если это предприятие) - корпорации, отрасли, региона, а также глобальные - из средств массовой информации, специальной литературы, всемирной информационной сети Internet и т.д. Одной из первостепенных задач при подготовке и принятии решений является анализ имеющейся в распоряжении ЛПР информации, который является фундаментом обоснования решения. Объемы информации, необходимой и используемой при принятии решений огромны. Информация характеризуется многоплановостью, сложностью отображаемых объектов и систем, а также связей между объектами, явлениями и процессами, скрытостью закономерностей. Эти обстоятельства вынуждают использовать имеющиеся в настоящее время весьма развитые программно-технические средства. Получили широкое распространение автоматизированные информационные системы, которые в последние годы чаще называют информационные системы, подразумевая, что без автоматизации их просто невозможно представить. Проблема анализа исходной информации для принятия решений оказалась настолько серьёзной, что появилось отдельное направление или вид информационных систем - информационно-аналитические системы (ИАС). под которыми понимают комплекс аппаратных, программных средств, информационных ресурсов, методик, которые используются для обеспечения автоматизации аналитических работ в целях обоснования принятия управленческих решений и других возможных применений. Аспекты проблемы анализа и их реализации в программных продуктах. Вся проблема аналитической подготовки принятия решений имеет три аспекта: • сбор и хранение необходимой для принятия решений информации; • собственно анализ, в том числе оперативный и интеллектуальный; • подготовка результатов оперативного и интеллектуального анализа для эффективного их восприятия потребителями и принятия на её основе адекватных решений. Аспект, касающийся сбора и хранения информации с сопутствующей доработкой, оформился в концепцию информационных хранилищ, т.е. сведения о деятельности предприятия или иного объекта деятельности накапливаются в течение длительного периода времени (годы) в информационном хранилище по определенным правилам. Они используются в различных временных режимах для анализа, как источник данных для разного рода отчетности и работы с партнерами (Reporting) и обоснования управленческих решений. Из-за большого объема информации и сложности проблему анализа разделили на
Имеются комплексные информационно-аналитические системы, выполняющие в той или иной степени функции в соответствии с рассмотренными аспектами. Как правило, все инструментальные средства, предназначенные для автоматизации аналитических работ, приспособлены для обработки многомерных массивов информации, имеют также возможность импорта/экспорта данных в другие операционные среды, развитые средства визуального двумерного (2D) и трехмерного (3D) представления информации. Модули, предназначенные для выполнения функций OLAPанализа, входят также и в состав интегрированных информационных систем (ИИС) (системы, выполняющие весь комплекс автоматизации работ в информационном пространстве экономического или какого-либо другого объекта). Наиболее развитые ИИС выполняют функции и оперативного и интеллектуального анализа. Пример обобщенного представления методологий обработки данных, начиная от интеграции разнородных источников данных и завершая использованием методов Data Mining для принятия управленческих решений.(рисунок пирамида)
Целевые программные продукты и ИИС весьма дороги и пока малодоступны для массового российского потребителя. Выходом из этого положения является использование редко применяемых на практике возможностей массовых программных инструментальных средств Excel, Mathcad, Stadia, Statistica и др. 3. Задачи систем поддержки принятия решений С появлением первых ЭВМ наступил этап информатизации разных сторон человеческой деятельности. Если раньше человек основное внимание уделял веществу, затем энергии то сегодня наступил этап осознания процессов, связанных с информацией. Вычислительная техника создавалась прежде всего для обработки данных. Cовременные вычислительные системы и компьютерные сети позволяют накапливать большие массивы данных для решения задач обработки и анализа. Cама по себе машинная форма представления данных содержит информацию, необходимую человеку, в скрытом виде, и для ее извлечения нужно использовать специальные методы анализа данных. Большой объем информации, с одной стороны, позволяет получить более точные расчеты и анализ, с другой - превращает поиск решений в сложную задачу. Для решения данной проблемы появился целый класс программных систем, призванных облегчить работу людей, выполняющих анализ (аналитиков) – СППР. Для выполнения анализа СППР должна накапливать информацию, обладая средствами ее ввода и хранения. Таким образом, можно выделить три основные задачи, решаемые в СППР:
СППР — это системы, обладающие средствами ввода, хранения и анализа данных, относящихся к определенной предметной области, с целью поиска решений. Ввод данных в СППР осуществляется либо автоматически от датчиков, характеризующих состояние среды или процесса, либо человеком-оператором. В первом случае данные накапливаются путем циклического опроса, либо по сигналу готовности, возникающему при появлении информации. Во втором случае СППР должны предоставлять пользователям удобные средства ввода данных, контролирующие корректность вводимых данных и выполняющие сопутствующие вычисления. Если ввод осуществляется одновременно несколькими операторами, то система должна решать проблемы параллельного доступа и модификации одних и тех же данных. Постоянное накопление данных приводит к непрерывному росту их объема- на СППР ложится задача обеспечить надежное хранение больших объемов данных. На СППР ложатся задачи предотвращения несанкционированного доступа, резервного хранения данных, архивирования и т. п. Основная задача СППР — предоставить аналитикам инструмент для выполнения анализа данных. Для пользования СППР аналитик должен обладать соответствующей квалификацией. Система не генерирует правильные решения, а только предоставляет аналитику данные в соответствующем виде (отчеты, таблицы, графики и т. п.) для изучения и анализа, именно поэтому такие системы обеспечивают выполнение функции поддержки принятия решений. По степени "интеллектуальности" обработки данных при анализе выделяют три класса задач анализа:
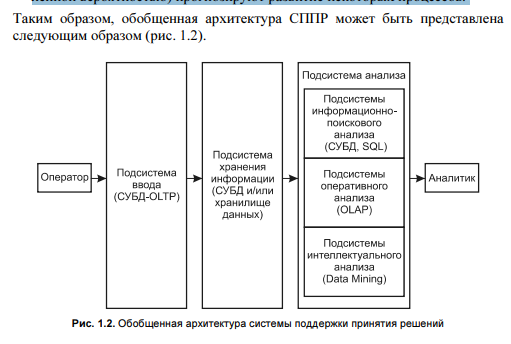 Подсистема ввода данных. В таких подсистемах, называемых OLTP (Online transaction processing), реализуется операционная (транзакционная) обработка данных. Для их реализации используют обычные системы управления базами данных (СУБД). Подсистема хранения. Для реализации данной подсистемы используют современные СУБД и концепцию хранилищ данных. Подсистема анализа. Данная подсистема может быть построена на основе:
4. Базы данных — основа СППР. База данных является моделью некоторой предметной области, состоящей из связанных между собой данных об объектах, их свойствах и характеристиках. Системы, предоставляющие средства работы с БД, называются СУБД, они не решают ни каких прикладных задач, а являются инструментом для разработки прикладных программ, использующих БД. иерархическая структура предполагала хранение данных в виде дерева. Это значительно упрощало создание и поддержку таких БД. Однако невозможность представить многие объекты реального мира в виде иерархии привела к использованию таких БД в сильно специализированных областях. Попыткой улучшить иерархическую структуру была сетевая структура БД, которая предполагает представление данных в виде сети. Работа с сетевыми БД представляет гораздо более сложный процесс, чем работа с иерархической БД, поэтому данная структура не нашла широкого применения на практике. Наиболее распространены в настоящее время реляционные БД. Такая структура хранения данных построена на взаимоотношении составляющих ее частей. Реляционный подход стал широко известен благодаря работам Е. Кодда в 1970 году. Кодд сформулировал следующие 12 правил для реляционной БД. 1. БД представляет собой набор таблиц. Таблицы хранят данные, сгруппированные в виде рядов и колонок. Ряд представляет собой набор значений, относящихся только к одному объекту, хранящемуся в таблице, и называется записью. Колонка представляет собой одну характеристику для всех объектов, хранящихся в таблице, и называется полем. Ячейка на пересечении ряда и колонки представляет собой значение характеристики, соответствующей колонке для элемента соответствующего ряда. 2. Данные доступны логически — реляционная модель не позволяет обращаться к данным физически, адресуя ячейки по номерам колонки и ряда. Доступ к данным возможен только через идентификаторы таблицы, колонки и ряда. Идентификаторами таблицы и колонки являются их имена. Они должны быть уникальны. Идентификатором ряда является первичный ключ — значения одной или нескольких колонок, однозначно идентифицирующих ряды. Если идентификация ряда осуществляется на основании значений нескольких колонок, то ключ называется составным. 3. NULL трактуется как неизвестное значение — если в ячейку таблицы значение не введено, то записывается NULL. Его нельзя путать с пустой строкой или со значением 0. 4.БД хранит два вида таблиц: пользовательские таблицы и системные таблицы. В пользовательских таблицах хранятся данные, введенные пользователем. В системных таблицах хранятся метаданные: описание таблиц (название, типы и размеры колонок), индексы, хранимые процедуры и др. 5. для управления реляционной БД должен использоваться единый язык. В настоящее время таким инструментом стал язык структурных запросов SQL. 6. СУБД не должна ограничивать пользователя только отображением таблиц, которые существуют. Пользователь должен иметь возможность строить виртуальные таблицы — представления (View). Представления являются динамическим объединением нескольких таблиц. Изменения данных в представлении должны автоматически переноситься на исходные таблицы (за исключением нередактируемых полей в представлении, например вычисляемых полей). 7. Должны поддерживаться операции реляционной 8. приложения, оперирующие с данными реляционных БД, не должны зависеть от физического хранения данных (от способа хранения, формата хранения и др.). 9. приложения, оперирующие с данными реляционных БД, не должны зависеть от организации связей между таблицами (логической организации). При изменении связей между таблицами не должны меняться ни сами таблицы, ни запросы к ним. 10.За целостность данных отвечает СУБД — под целостностью данных в общем случае понимается готовность БД к работе. Различают следующие типы целостности: • физическая целостность — сохранность информации на носителях и корректность форматов хранения данных; • логическая целостность — непротиворечивость и актуальность данных, хранящихся в БД 11.СУБД должна обеспечивать целостность данных при любых манипуляциях, производимых с ними. 12. реляционная БД может размещаться как на одном компьютере, так и на нескольких — распределенно. Пользователь должен иметь возможность связывать данные, находящиеся в разных таблицах и на разных узлах компьютерной сети. На практике в дополнение к перечисленным правилам существует требование минимизации объемов памяти, занимаемых БД. Это достигается проектированием такой структуры БД, при которой дублирование (избыточность) информации было бы минимальным. Для выполнения этого требования была разработана теория нормализации. Недостаток реляционной модели- не каждый тип информации можно представить в табличной форме, например изображения, музыку и др. Правда, в настоящее время для хранения такой информации в реляционных СУБД сделана попытка использовать специальные типы полей — BLOB (Binary Large OBjects). В них хранятся ссылки на соответствующую информацию, которая не включается в БД. Однако такой подход не позволяет оперировать информацией, не помещенной в базу данных, что ограничивает возможности по ее использованию.Для хранения такого вида информации предлагается использовать постреляционные модели в виде объектно-ориентированных структур хранения данных. 5)Концепция хранилища данных. В основе концепции ХД лежит идея разделения данных, используемых для оперативной обработки и для решения задач анализа. Это позволяет применять структуры данных, которые удовлетворяют требованиям их хранения с учетом использования в OLTP-системах и системах анализа. Такое разделение позволяет оптимизировать как структуры данных оперативного хранения (оперативные БД, файлы, электронные таблицы и т. п.) для выполнения операций ввода, модификации, удаления и поиска, так и структуры данных, используемые для анализа (для выполнения аналитических запросов). В СППР эти два типа данных называются соответственно оперативными источниками данных (ОИД) и хранилищем данных. Хранилище данных — предметно-ориентированный, интегрированный, неизменчивый, поддерживающий хронологию набор данных, организованный для целей поддержки принятия решений. свойства ХД: Предметная ориентация — является фундаментальным отличием ХД от ОИД. Разные ОИД могут содержать данные, описывающие одну и ту же предметную область с разных точек зрения (например, с точки зрения бухгалтерского учета, складского учета, планового отдела и т. п.). Решение, принятое на основе только одной точки зрения, может быть неэффективным или даже неверным. ХД позволяют интегрировать информацию, отражающую разные точки зрения на одну предметную область. Предметная ориентация позволяет также хранить в ХД только те данные, которые нужны для их анализа. Это существенно сокращает затраты на носители информации и повышает безопасность доступа к данным. Интеграция — ОИД, как правило, разрабатываются в разное время несколькими коллективами с собственным инструментарием. Это приводит к тому, что данные, отражающие один и тот же объект реального мира в разных системах, описывают его по-разному. Обязательная интеграция данных в ХД позволяет решить эту проблему, приведя данные к единому формату. Поддержка хронологии— данные в ОИД необходимы для выполнения над ними операций в текущий момент времени. Поэтому они могут не иметь привязки ко времени. Для анализа данных часто важно иметь возможность отслеживать хронологию изменений показателей предметной области. Поэтому все данные, хранящиеся в ХД, должны соответствовать последовательным интервалам времени. Неизменяемость — требования к ОИД накладывают ограничения на время хранения в них данных. Те данные, которые не нужны для оперативной обработки, как правило, удаляются из ОИД для уменьшения занимаемых ресурсов. Для анализа, наоборот, требуются данные за максимально больший период времени. Поэтому, в отличие от ОИД, данные в ХД после загрузки только читаются. Это позволяет существенно повысить скорость доступа к данным как за счет возможной избыточности хранящейся информации, так и за счет исключения операций модификации. При реализации в СППР концепции ХД данные из разных ОИД копируются в единое хранилище. Собранные данные приводятся к единому формату, согласовываются и обобщаются. Аналитические запросы адресуются к ХД Такая модель неизбежно приводит к дублированию информации в ОИД и в ХД( не превышает 1 %). 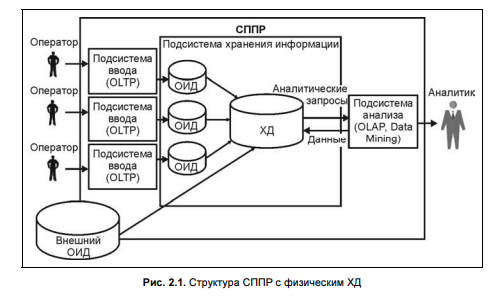 Избыточность информации можно свести к нулю, используя виртуальное ХД. В данном случае в отличие от классического (физического) ХД данные из ОИД не копируются в единое хранилище. Они извлекаются, преобразуются и интегрируются непосредственно при выполнении аналитических запросов в оперативной памяти компьютера. Фактически такие запросы напрямую адресуются к ОИД Основными достоинствами виртуального ХД являются: минимизация объема памяти, занимаемой на носителе информацией; работа с текущими, детализированными данными. |