Роль и место информационноаналитических систем
 Скачать 440.38 Kb. Скачать 440.38 Kb.
|

|
6)Организация ХД. Все данные в ХД делятся на три основные категории
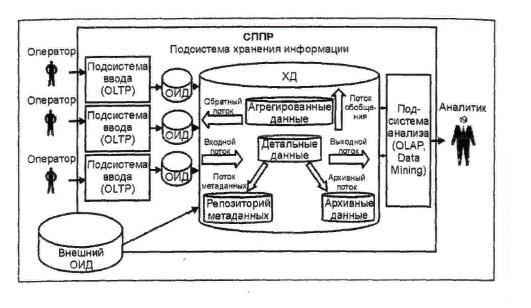 Архитектура ХД Детальными являются данные, переносимые непосредственно из ОИД. Они соответствуют элементарным событиям, фиксируемым OLTP-системами (на пример, продажи, эксперименты и др.). Принято разделять все данные на из мерения и факты. Измерениями называются наборы Данных, необходимые для описания событий (например, города, товары, люди и т. п.). Фактами на зываются данные, отражающие сущность события (например, количество проданного товара, результаты экспериментов и т. п.). Фактические данные могут быть представлены в виде числовых или категориальных значений. В процессе эксплуатации ХД необходимость в ряде детальных данных может снизиться. Ненужные детальные данные могут храниться в архивах в сжатом виде на более емких накопителях с более медленным доступом (например, на магнитных лентах). Данные в архиве остаются доступными для обработки и анализа. Регулярно используемые для анализа данные должны храниться на накопителях с быстрым доступом (например, на жестких дисках). На основании детальных данных могут быть получены агрегированные (обобщенные) данные. Для удобства работы с ХД необходима информация о содержащихся в нем данных. Такая информация называется метаданными (данные о данных). Они должны отвечать на следующие во просы — что, кто, где, как, когда и почему? Так как метаданные играют важную роль в процессе работы с ХД, то к ним должен быть обеспечен удобный доступ. Для этого они сохраняются в репозитории метаданных с удобным для пользователя интерфейсом. 7. Очистка данных. Одной из важных задач, решаемых при переносе данных в ХД, является их очистка. данные загружаются постоянно из различных ис точников, поэтому вероятность попадания "грязных данных" весьма высока, с другой — ХД используются для принятия решений и "грязные данные" мо гут стать причиной принятия неверных решений. Таким образом, процедура очистки является обязательной при переносе данных из ОИД в ХД. Основные проблемы очистки данных можно классифицировать по следующим уровням:
При очистке данных не все проблемы могут быть решены. На самом деле не все данные нужно очищать. Как уже отмечалось, процесс очистки требует больших затрат, поэтому те данные, достоверность которых не влияет на процесс принятия решений, могут оста ваться неочищенными. В целом, очистка данных включает несколько этапов:
1.Для выявления подлежащих удалению ви дов ошибок и несоответствий необходим подробный анализ данных. Наряду с ручной проверкой следует использовать аналитические программы. 2. В зависимости от числа источников данных, степени их неоднородности и загрязненности, они могут требовать достаточно обширного преобразования и очистки. Первые шаги по очистке данных могут скорректировать проблемы отдельных источников данных и подготовить данные для интеграции. Дальнейшие шаги должны быть направлены на интеграцию данных и устранение проблем множественных источников. На этом этапе необходимо выработать общие правила преобразования, часть из которых должна быть представлена в виде программных средств очистки. 3. Корректность и эффективность правил очистки данных должны тестироваться и оцениваться, например, н копиях данных источника. Это необходимо для выяснения необходимости корректировки правил с целью их улучшения или исправления ошибок. Этапы определения правил и их тестирование могут выполняться итерационно несколько раз, например, из-за того, что некоторые ошибки становятся заметны только после определенных преобразований. 4. На этом этапе выполняются преобразования в соответствии с определенными ранее правилами. Очистка выполняется в два приема. Сначала устраняются проблемы, связанные с отдельны ми источниками данных, а за тем — проблемы множества БД. После того как ошибки отдельных источников удалены, очищенные данные должны заменить загрязненные данные в исходных ОИД. Это необходимо для повышения качества данных в ОИД и исключения затрат на очистку при повторном использовании. После завершения преобразований над данными из отдельных источников можно приступать к их интеграции. Очищенные данные сохраняются в ХД и могут использоваться для анализа и принятия на их основе решений 8. Многомерная модель данных. В процессе принятия решений пользователь генерирует некоторые гипотезы. Для превращения их в законченные решения эти гипотезы должны быть проверены. Проверка гипотез осуществляется на основании информации об анализируемой предметной области. Как правило, наиболее удобным способом представления такой информации для человека является зависимость между некоторыми параметрами. Число таких параметров может изменяться в широких пределах. Недостатки реляционной модели- в первую очередь невозможность "объединять, просматривать и анализировать данные с точки зрения множественности измерений. Измерение — это последовательность значений одного из анализируемых параметров. Множественность измерений предполагает представление данных в виде многомерной модели. По измерениям в многомерной модели откладывают параметры, относящиеся к анализируемой предметной области. Одновременный анализ по нескольким измерениям определяется как многомерный анализ. Каждое измерение может быть представлено в виде иерархической структуры. 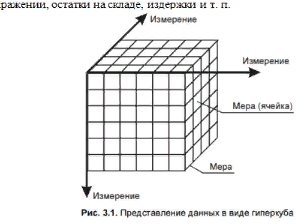 На пересечениях осей измерений распологаются данные колличественно характерезующие анализируемые факты-меры. Таким образом многомерную модель данных можно представить в виде гиперкуба,рёбрами являются измерения,а ячейки-меры. Операции над гиперкубом. Срез - формирование подмножества многомерного массива данных, соответствующего единственному значению одного или нескольких элементов измерений, не входящих в это подмножество. 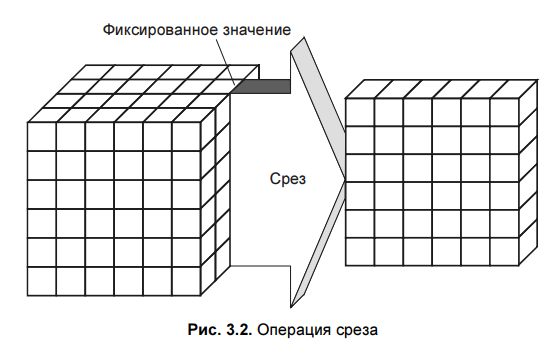 Вращение-изменение расположения измерений, представленных в отчете или на отображаемой странице. Например, операция вращения может заключаться в перестановке местами строк и столбцов таблицы или перемещении интересующих измерений в столбцы или строки создаваемого отчета, что позволяет придавать ему желаемый вид. 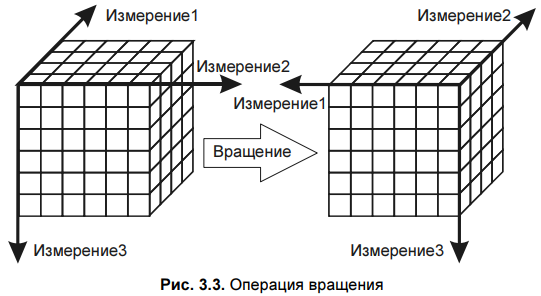 Консолидация и детализация-операции, которые определяют переход вверх по направлению от детального (down) представления данных к агрегированному (up) и наоборот, соответственно. 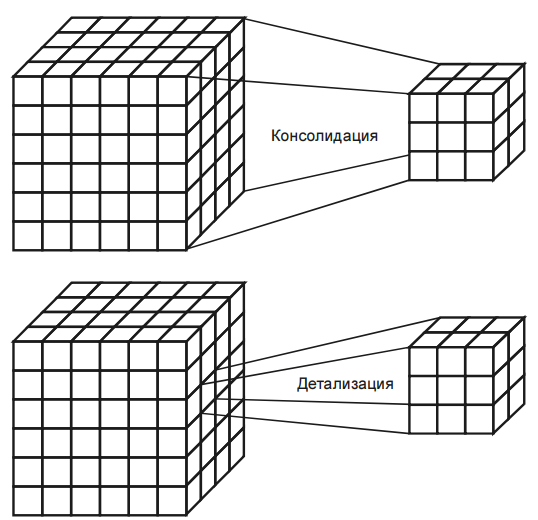 9. Концептуальное многомерное представление OLAP - систем. OLAP- технология оперативной аналитической обработки данных, использующая методы и средства для сбора, хранения и анализа многомерных данных в целях поддержки процессов принятия решений. Цель OLAP-анализа — проверка возникающих гипотиз. OLAP это сводные отчеты в разнообразных разрезах, создаваемых за считанные секунды самим пользователем по мере надобности и имеющие наглядную форму (таблицы, графики, диаграммы и т.д.). На сегодняшний день в состав мощных СУБД входят специальные компоненты технологии многомерного анализа OLAP. Они позволяют хранить и обрабатывать многомерную информацию на том же сервере баз данных, где находится реляционное хранилище. Технология OLAP дает возможность быстро менять взгляд на данные в зависимости от выбранных параметров и обеспечивает лицу, принимающему решения, полный обзор ситуации в бизнесе с его собственной Далее перечислены 12 правил, изложенных Коддом и определяющих OLAP: 1. Многомерность. OLAP-система на концептуальном уровне должна представлять данные в виде многомерной модели, что упрощает процессы анализа и восприятия информации. 2. Прозрачность. OLAP-система должна скрывать от пользователя реальную реализацию многомерной модели, способ организации, источники, средства обработки и хранения. 3. Доступность. OLAP-система должна предоставлять пользователю единую, согласованную и целостную модель данных, обеспечивая доступ к данным независимо от того, как и где они хранятся. 4. Постоянная производительность при разработке отчетов. Производительность OLAP-систем не должна значительно уменьшаться при увеличении количества измерений, по которым выполняется анализ. 5. Клиент-серверная архитектура. OLAP-система должна быть способна работать в среде "клиент-сервер", т. к. большинство данных, которые сегодня требуется подвергать оперативной аналитической обработке, хранятся распределенно. 6. Равноправие измерений. OLAP-система должна поддерживать многомерную модель, в которой все измерения равноправны. При необходимости дополнительные характеристики могут быть предоставлены отдельным измерениям, но такая возможность должна быть у любого измерения. 7. Динамическое управление разреженными матрицами. OLAP-система должна обеспечивать оптимальную обработку разреженных матриц. Скорость доступа должна сохраняться вне зависимости от расположения ячеек данных и быть постоянной величиной для моделей, имеющих разное число измерений и различную степень разреженности данных. 8. Поддержка многопользовательского режима. При этом возможны как чтение, так и запись данных, поэтому система должна обеспечивать их целостность и безопасность. 9. Неограниченные перекрестные операции. OLAP-система должна обеспечивать сохранение функциональных отношений, описанных с помощью определенного формального языка между ячейками гиперкуба при выполнении любых операций. Система должна самостоятельно (автоматически) выполнять преобразование установленных отношений, не требуя от пользователя их переопределения. 10. Интуитивная манипуляция данными. OLAP-система должна предоставлять способ выполнения операций над гиперкубом без необходимости пользователю совершать множество действий с интерфейсом. Измерения, определенные в аналитической модели, должны содержать всю необходимую информацию для выполнения вышеуказанных операций. 11. Гибкие возможности получения отчетов. OLAP-система должна поддерживать различные способы визуализации данных, т. е. средства формирования отчетов должны представлять синтезируемые данные или информацию, следующую из модели данных, в ее любой возможной ориентации 12. Неограниченная размерность и число уровней агрегации. Исследование о возможном числе необходимых измерений, требующихся в аналитической модели, показало, что одновременно могут использоваться до 19 измерений. Отсюда вытекает настоятельная рекомендация, чтобы аналитический инструмент мог одновременно предоставить хотя бы 15, а предпочтительнее — и 20 измерений. Более того, каждое из общих измерений не должно быть ограничено по числу определяемых пользователем-аналитиком уровней агрегации и путей консолидации. 10. Архитектура OLAP - систем. OLAP-система включает в себя два основных компонента: - OLAP-сервер - обеспечивает хранение данных, выполнение над ними необходимых операций и формирование многомерной модели на концептуальном уровне. В настоящее время OLAP-серверы объединяют с ХД или ВД; - OLAP-клиент - представляет пользователю интерфейс к многомерной модели данных, обеспечивая его возможностью удобно манипулировать данными для выполнения задач анализа. OLAP-серверы скрывают от конечного пользователя способ реализации многомерной модели. Они формируют гиперкуб, с которым пользователи посредством OLAP-клиента выполняют все необходимые манипуляции, анализируя данные. Между тем способ реализации очень важен, т. к. от него зависят такие характеристики, как производительность и занимаемые ресурсы. Выделяют три основных способа реализации: - MOLAP — многомерный (multivariate) OLAP. Для реализации многомерной модели используют многомерные БД; - ROLAP — реляционный (relational) OLAP. Для реализации многомерной модели используют реляционные БД; - HOLAP — гибридный (hybrid) OLAP. Для реализации многомерной модели используют и многомерные, и реляционные БД. 11. Базовые понятия и основные задачи интеллектуального анализа данных. Целью интеллектуального анализа данных является обнаружение неявных закономерностей в наборах данных. Data Mining – исследование и обнаружение «машиной» (алгоритмами, средствами искусственного интеллекта) в сырых данных скрытых знаний, которые ранее не были известны, нетривиальны, практически полезны, доступны для интерпретации. Важное положение Data Mining — нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные регулярности в данных, составляющие так называемые скрытые знания. 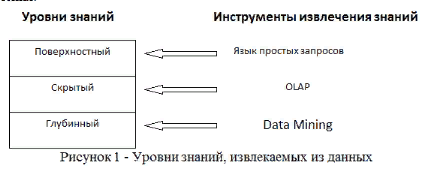 Учитывая разнообразие форм представления данных, используемых алгоритмов и сфер применения, интеллектуальный анализ данных может проводиться с помощью программных продуктов следующих классов: – специализированных «коробочных» программных продуктов для интеллектуального анализа; – математических пакетов; – электронных таблиц (и различного рода надстроек над ними); – средств интегрированных в системы управления базами данных (СУБД); – других программных продуктов В настоящее время интенсивно разрабатываются методы автоматического извлечения знаний из накопленных фактов, хранящихся в различных базах данных. Это концепция, зародившаяся в 1989 г., лежит в основе двух современных технологий анализа данных Data Mining и KDD – Knowledge Discovery in Databases, которые на русский язык переводятся как «добыча (раскопка) данных» и «извлечение знаний из баз данных». Knowledge Discovery in Database (KDD) — процесс получения из данных знаний в виде зависимостей, правил и моделей позволяющих моделирование и прогнозирование различных процессов. 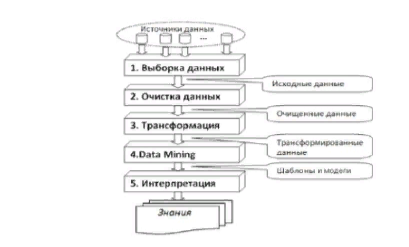 Кратко рассмотрим каждый этап. 1 этап. Выборка данных. Этот этап заключается в подготовке набора данных, в том числе из различных источников, выбора значимых параметров 2 этап. Очистка данных. Реальные данные для анализа редко бывают хорошего качества. Поэтому для эффективного применения методов Data Mining следует обратить серьезное внимание на вопросы предобработки данных. 3 этап. Трансформация данных. Этот шаг необходим для тех методов, которые требуют, чтобы исходные данные были в каком-то определенном виде. Дело в том, что различные алгоритмы анализа требуют специальным образом подготовленные данные. Например, для прогнозирования необходимо преобразовать временной ряд при помощи скользящего окна или вычисление агрегируемых показателей. К задачам трансформации данных относятся: скользящее окно, приведение типов, выделение временных интервалов, преобразование непрерывных значений в дискретные и наоборот, сортировка, группировка и прочее. 4 этап. Data Mining. На этом этапе строятся модели, в которых применяются различные алгоритмы для нахождения знаний. Это нейронные сети, деревья решений, алгоритмы кластеризации и установления ассоциаций 5 этап. Интерпретация. На данном этапе осуществляется применение пользователем полученных моделей (знаний) в бизнес приложениях. Для оценки качества полученной модели нужно использовать как формальные методы, так и знания аналитика. Именно аналитик может сказать, насколько применима полученная модель к реальным данным. Полученные модели являются, по сути, формализованными знаниями эксперта, а следовательно, их можно тиражировать. В этом заключается самое главное преимущество KDD. Т.е. построенную одним человеком модель могут применять другие, без необходимости понимания методик, при помощи которой эти модели построены. Найденные знания должны быть использованы на новых данных с некоторой степенью достоверности. ИАД — это процесс поддержки принятия решений, основанный на поиске в данных скрытых закономерностей, то есть извлечения информации, которая может быть охарактеризована как знания. В общем случае процесс ИАД состоит из трех стадий: выявление закономерностей (свободный поиск); использование выявленных закономерностей для предсказания неизвестных значений (прогностическое моделирование); анализ исключений, предназначенный для выявления и толкования аномалий в найденных закономерностях. 12. Набор данных и их атрибутов. В широком понимании данные представляют собой факты, текст, графики, картинки, звуки, аналоговые или цифровые видео-сегменты. Данные могут быть получены в результате измерений, экспериментов, арифметических и логических операций. Данные должны быть представлены в форме, пригодной для хранения, передачи и обработки. Иными словами, данные – это необработанный материал, предоставляемый поставщиками данных и используемый потребителями для формирования информации на основе данных. Набор данных может быть представлен двухмерной таблицей. При анализе данных, как правило, нет возможности рассмотреть всю интересующую нас совокупность объектов. Вполне достаточно рассмотреть некоторую часть всей совокупности, то есть выборку, и получить интересующую нас информацию на ее основе. Измерение – процесс присвоения чисел характеристикам изучаемых объектов согласно определенному правилу. В процессе подготовки данных измеряется не сам объект, а его характеристики. Шкала – правило, в соответствии с которым объектам присваиваются числа. Многие инструменты Data Mining при импорте данных из других источников предлагают выбрать тип шкалы для каждой переменной и/или выбрать тип данных для входных и выходных переменных (символьные и числовые, дискретные и непрерывные). Переменные могут являться числовыми данными либо символьными. Числовые данные, в свою очередь, могут быть дискретными и непрерывными. Дискретные данные являются значениями признака, общее число которых конечно либо бесконечно, но может быть подсчитано при помощи натуральных чисел от одного до бесконечности. Непрерывные данные – данные, значения которых могут принимать какое угодно значение в некотором интервале. Измерение непрерывных данных предполагает большую точность. Пример непрерывных данных: температура, высота, вес, длина и т.д Наиболее часто встречаются данные, состоящие из записей. Примеры таких наборов данных: табличные данные, матричные данные, документальные данные, транзакционные или операционные. Табличные данные – данные, состоящие из записей, каждая из которых состоит из фиксированного набора атрибутов. Транзакционные данные представляют собой особый тип данных, где каждая запись, являющаяся транзакцией, включает набор значений. Большинство инструментов Data Mining позволяет импортировать данные из различных источников, а также экспортировать результирующие данные в различные форматы. |