РК2. Литвинов Д.Р. ПЗ, РК-2. Российский государственный социальный университет Факультет информационных технологий Практическое задание 2 по дисциплине Интеллектуальные информационные системы
 Скачать 259.42 Kb. Скачать 259.42 Kb.
|

Практическое задание 2 по дисциплине «Интеллектуальные информационные системы» Системы распознавания визуальных образов
Москва 2022 1. Особенности CuneiForm позиционируется как система преобразования электронных копий бумажных документов и графических файлов в редактируемый вид с возможностью сохранения структуры и гарнитуры шрифтов оригинального документа в автоматическом или полуавтоматическом режиме. Система включает в себя две программы для одиночной и пакетной обработки электронных документов. CuneiForm — Шрифтонезависимая система. 2. История развития В 1993 году Cognitive Technologies заключила OEM-контракт с канадской корпорацией Corel Corporation, по которому библиотека распознавания Cognitive встроена в популярный издательский пакет Corel Draw 3.0 (и последующие версии). В 1996 году выпущена версия OCR CuneiForm '96, в которой впервые в мире применены алгоритмы адаптивного распознавания. Адаптивное распознавание — метод, основанный на комбинации двух видов алгоритмов распознавания печатных символов: шрифтового (multifont) и шрифтонезависимого (omnifont). Система генерирует внутренний шрифт для каждого вводимого документа, основываясь на хорошо пропечатанных символах, то есть используется динамическая настройка (адаптация) на конкретные входные символы. Таким образом, метод совмещает универсальность и технологичность бесшрифтового подхода и высокую точность распознавания шрифтового, что позволяет кардинальным образом повысить качество распознавания. В 1997 году в системе CuneiForm впервые применены технологии, основанные на нейронных сетях. Алгоритмы, использующие нейронные сети для распознавания символов, строятся следующим образом. Поступающее на распознавание изображение символа (растр) приводится к некоторому стандартному размеру (нормализуется). Значения яркости в узлах нормализованного растра используются в качестве входных параметров нейронной сети. Число выходных параметров нейронной сети равняется числу распознаваемых символов. Результатом распознавания является символ, которому соответствует наибольшее из значений выходного вектора нейронной сети. В 1999 году разработан механизм воссоздания формы исходного документа «What you scan is what you get». Он позволяет придать документу его исходную форму, добиваясь того, чтобы каждый фрагмент находился на нужном месте. Особенно это касается документов со сложной топологией: многоколончатые тексты с заголовками, аннотациями, графическими иллюстрациями, таблицами, и т. д. Плюсы: — распознавание текста на 20 самых популярных языках мира (английский и русский само собой входит в это число); — огромная поддержка различных печатных шрифтов; — проверка по словарю распознанного текста; — возможность сохранения результаты работы в нескольких вариантах; — сохранение структуры документа; — отличная поддержка и распознавание таблиц. Минусы: — не поддерживает слишком большие документы и файлы (более 400 dpi); — не поддерживает на прямую некоторые типы сканеров (ну это не страшно, в комплект к драйверам сканера идет и спец. программа для сканирования); — дизайн не блещет (но кому он нужен, если программа в полной мере решит задачу). 3. Пример распознавания текста 1) Открываем требуемую картинку в программе CuineForm (файл/открыть или «Cntrl+O»). 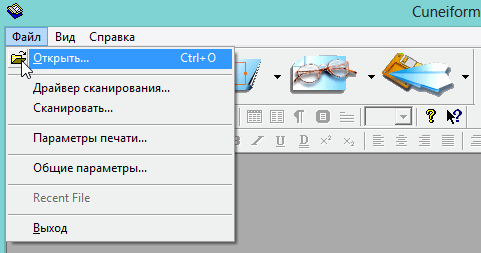 2) Чтобы приступить к распознаванию — нужно сначала выделить различные области: текста, картинок, таблиц и пр. В программе Cuneiform это можно сделать не только вручную, но и автоматически! Для этого щелкните по кнопке «разметка» в верхней панели окна. 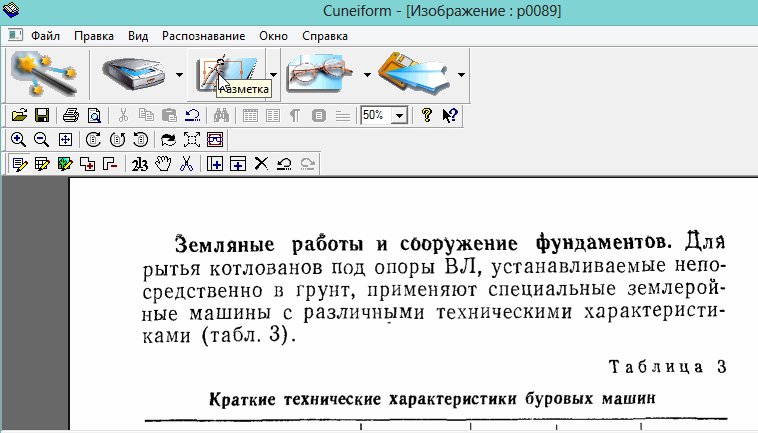 3) Спустя 10-15 сек. программа автоматически подсветит все области различными цветами. Например, область текста выделяется синим цветом. 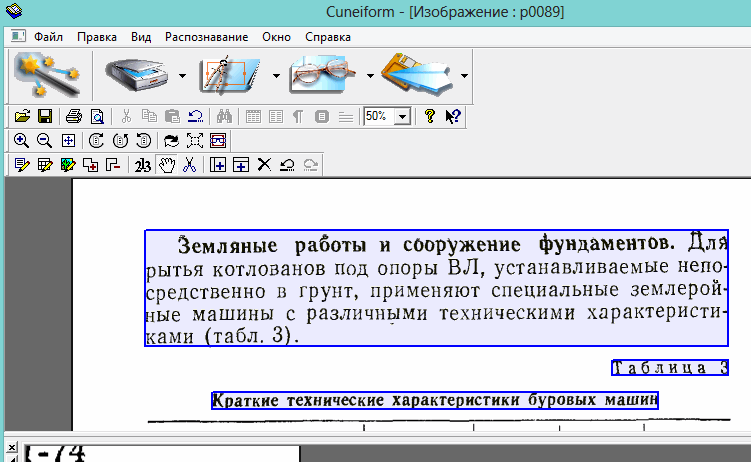 4) Так же можно воспользоваться и ручной. Для этого есть панель инструментов (см. картинку ниже), благодаря которой можно выделить: текст, таблицу, картинку. Передвинуть, увеличить/уменьшить начальное изображение, подрезать края. 5) После того, как все области были размечены, можно приступить к распознаванию. Для этого просто щелкните по одноименной кнопке. 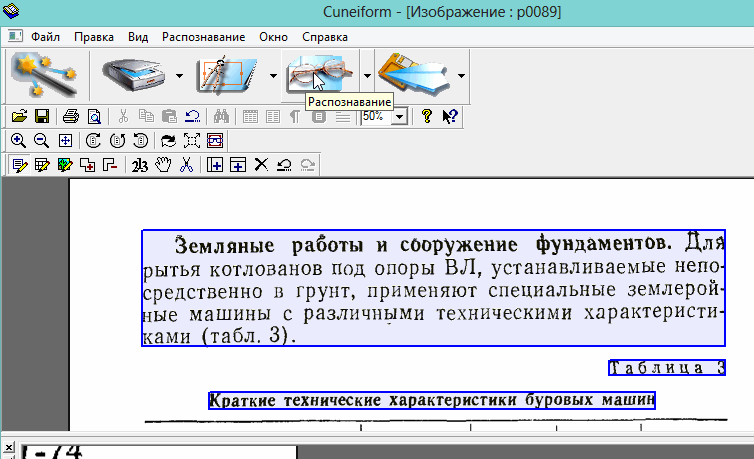 6) Буквально через 10-20 сек. перед вами откроется документ в Microsoft Word с распознанным текстом. 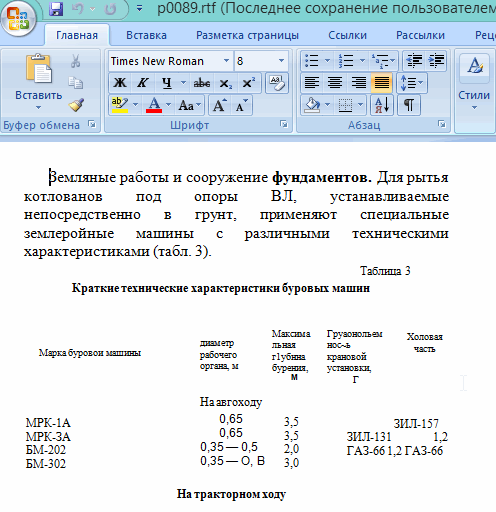 3. Пакетное распознавание текста Эта функция программы может пригодится, когда вам нужно распознать не одну картинку, а сразу несколько. Ярлык для запуска пакетного распознавания, обычно, находится в меню «пуск». 1) После открытия программы, вам нужно создать новый пакет, либо открыть ранее сохраненный. В нашем примере — создадим новый. 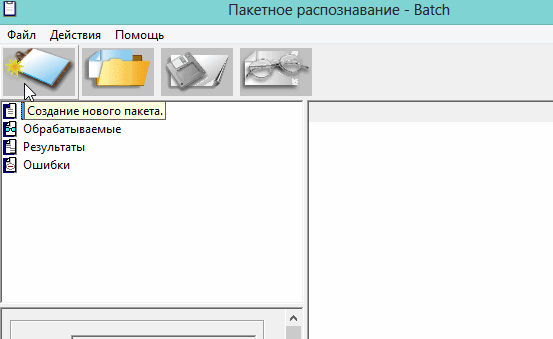 2) в следующем шаге даем ему название. 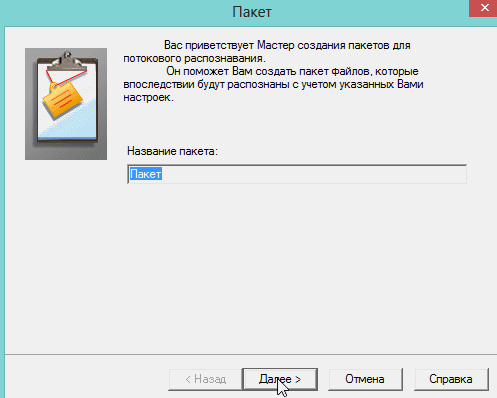 3) Далее выбираете язык документа (русско-английский), указываете, есть ли в вашем отсканированном материале картинки и таблицы. 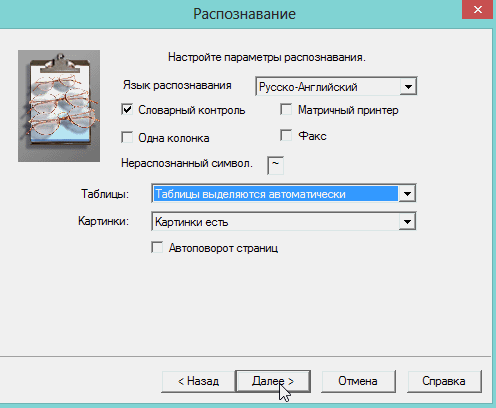 4) Теперь нужно указать папку, в которой расположены файлы для распознавания. 5) Следующий шаг не важен- выбираете что делать с исходными файлами, после распознавания. Рекомендую выбрать галочку «ничего не делать». 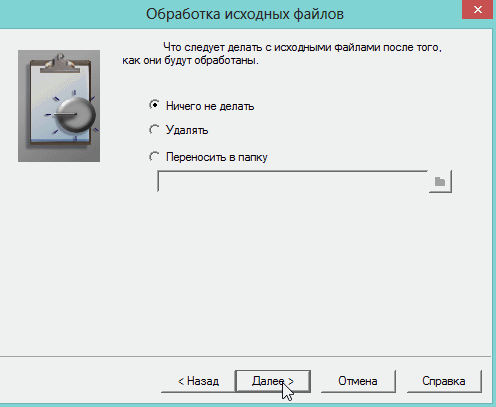 6) Осталось лишь выбрать формат, в котором будет сохранен распознанный документ. Есть несколько вариантов: — rtf — файл из документа word, открывается всеми популярными офисами (в том числе и бесплатными, ссылка на программы); — txt — текстовый формат, в нем можно сохранить только текст, картинки и таблицы нельзя; — htm — гипертекстовая страничка, удобно, если вы сканируете и распознаете файлы для сайта. Его и выберем в нашем примере. 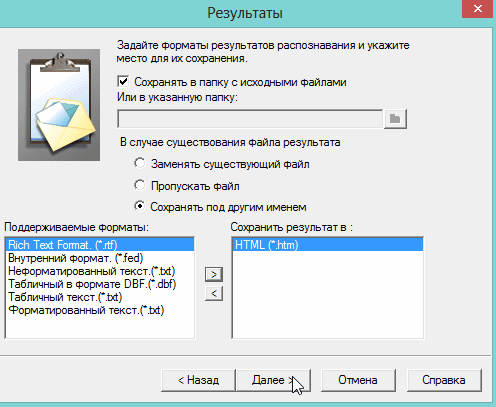 7) После нажатия кнопки «готово» запустится процесс обработки вашего проекта. 8) После распознания перед вами появится вкладка с файлами htm. Если щелкнуть по такому файлу запуститься браузер, где вы сможете увидеть результаты. |
