|
|
1514295509_69768 ахпорот кидирув тизимлари. Se сервиси идирув тизимлари
Se сервиси – қидирув тизимлари
Режа:
1. SE сервиснинг вазифаси
2. Ҳужжатларнинг даража мезонлари
3. Асосий қидирув тизимлари
4. Яndex қидирув тизими
5. Google қидирув тизими
6. Rambler қидирув тизими
1. SE сервиснинг вазифаси
SE сервиси (Search Engine) – қидирув тизимлари – бу махсус Wебсайтлар, уларда фойдаланувчи берилган сўров бўйича шу сўровга мос келувчи сайтларга ҳавола (ссылка) олиши мумкин. 85% Интернет фойдаланувчилари керакли маҳсулотлар, хизматлар ва ахборотларни топиш мақсадида қидирув тизимларидан фойдаланадилар.
Қидирув тизимлари тематик каталоглардан фарқ қилади. Улар катта базага эга URL-адресларни ифодалайди, бунда улар автоматик равишда бу адреслар бўйича Web –саҳифаларга мурожаат қилади, саҳифаларнинг мазмунини ўрганиб чиқади, саҳифалардан калит сўзларни ёзиб олади ва шакллантиради (саҳифаларни индексациядайди). Бундан ташқари бу серверлар саҳифаларда барча учрайдиган ҳаволаларга мурожаат қилади ва янги саҳифага ўтаётиб худи шундай ишни бажаради. Ихтиёрий Webсаҳифа бошқа саҳифаларга бир неча ҳаволага эгадир, яъни бундай ишда қидирув тизими натижада Internet барча сайтларини айланиб чиқади. Қидирув тизими қуйидаги асосий компонентлардан иборат:
Ўргимчак (spider) – Web-саҳифаларни, фойдаланувчи браузери усулида юклаб олувчи дастур. Уларнинг фарқли томони шундаки, браузер сахифада бўлган ахборотларни акс эттиради ( текстли, графикли), ўргимчак эса визуал компонентларга эга эмас ва тўғридан-тўғри саҳифанинг html-тексти билан ишлайди ( кўриш учун браузерда «просмотр html-кода» қилиш мумкин)
Саёҳат қилувчи ўргимчак (crawler) – саҳифада мавжуд бўлган барча ҳаволаларни ( ссылки) акс эттирувчи дастур. Унинг вазифаси – ҳаволаларга асосланиб ёки олдиндан берилган адреслар рўйҳатидан келиб чиқиб, ўргимчак қаерга боришини аниқлаб беради. Краулер, топилган ҳаволалар бўйича қидирув тизимида номаълум бўлган янги ҳужжатлар қидирувини амалга оширади.
Индексатор (indexer) – саҳифани таркибий қисмларга бўлиб, уларни таҳлил қилувчи дастур. Саҳифанинг турли элементлари, яъни текст, сарлавҳа, таркибий ва услубий ўзига хосликлари, махсус хизмат html-теглари ва б., ажратиб олиниб таҳлил қилинади. index-файл таҳлил натижаси ҳисобланади.
Маълумотлар базаси (database) – бу юклаб олиш жараёнида қидирув тизимидан олинган барча index-файллар ва Web- саҳифалар таҳлили омбори (хранилище). Баъзида маълумотлар базасини қидирув тизими индекси дейилади.
Натижаларни бериш тизими (searchengineresultsengine) – саҳифаларни даражалаш билан шуғулланади. У қайси саҳифалар фойдаланувчи эҳтиёжини қондиради ва улар қандай тартибда сараланишини ҳал қилади. Бу қидирув тизимини даражалаш алгоритми асосида амалга оширилади. Қидирув тизимининг бу компоненти билан оптимизатор алоқада бўлади, у чиқариш пайтида сайт ҳолатини даражалаш натижаларига таъсир кўрсатувчи маълум бир факторлар ёрдамида яхшилашга ҳаракат қилади.
Web-сервер (Web – server) – фойдаланувчи ва қидирув тизимининг бошқа компонентлари орасидаги ўзаро муносабатни амалга оширувчи сервер. Одатда, серверда кириш майдонли html-саҳифа бор, унда фойдаланувчи ўзини қизиқтирган қидирув терминини бериши мумкин. Web-сервер ҳам фойдаланувчига html- саҳифа кўринишида натижаларни чиқариб беришга жавоб беради.
Қидирув механизмларнинг батафсил амалга ошириш бир-биридан фарқ қилиши мумкин. Масалан, spider+crawler+indexer боғлами қидирув роботи деб номланган ягона дастур кўринишида бажарилиши мумкин. У таниқли Web-саҳифаларни юклаб олади, уларни таҳлил қилади, ҳаволалар (ссылка) орқали янги ресурсларни излайди, уларни индекслайди ва маълумотлар базасига index-файл кўринишида киритади. Фойдаланувчи томонидан сўралаётган маълумотларни indexфайллардан чиқариб олувчи бошқа дастур орқали қидирув амалга оширилади. Бироқ барча қидирув тизимларига кўрсатиб ўтилган томонлар тегишлидир.
2. Ҳужжатларни даражалаш мезонлари
Қидирув тизимларида ҳужжатларга ҳаволалар сўровларга москелишига қараб сараланади (ранжируются). Қидирув беришида саҳифаларни саралаш учун текст мезонлари, ҳавола мезонлари, фойдаланиш баҳолари мезонлари қўлланилади.
Текст мезонлари сўровларда, матнларда, саҳифа сарлавҳасида сўзлар мослиги бўйича ҳужжат релевантлиги мезонларини аниқлаб беради.
Ҳужжат релевантлиги – ҳужжат мазмуни билан қидирув тизимининг аниқ сўровлари мос келишини акс эттирувчи кўрсаткич.
Қидирув тизимлари ҳужжатларнинг релевантлигини ҳисоблайди, саҳифада учрайдиган сўз ва сўз бирикмаларининг частота қаторини қуради. Ҳужжатларда қанчалик кўп учраса, фойдаланувчи сўровларига шунчалик кўп релевантлик олади.
Қидирув тизимлари ҳужжатлар Web-саҳифалари релевантлигининг камайиш тартиби 10-20 тадан қисмларга бўлиниб ҳаволаларни акс эттиради. Маркетинг тадқиқот маълумотлари натижаларига кўра 60% га яқин фойдаланувчилар қидирув натижаларининг биринчи саҳифаси билан ва 90% –га яқини биринчи учта саҳифа билан чегараланиб қолади. Бундан сайтпромоутинг бўйича мутахассислар учун вазифа келиб чиқади – сўровнинг қурилишидан қатъий назар Web-сайт саҳифалари қидирувнинг биринчи 10-20 натижасида туришига эришиш керак .
Ҳужжатларни саралаш асосий матн мезонлари 21.1.- жадвалда келтирилган.
1-жадвал Ҳужжатлар саралашни матнли мезонлари
-
Мезонлар
|
Саралаш мантиқи
|
Сўз «оғирлиги»
|
Ҳужжатда сўзни такрорлаш частотаси юқори бўлса, ҳужжатнинг даражаси юқори бўлади
|
Сўзларнинг ўзаро вазияти
|
Ибора ёки унга ўхшаш сўзларнинг тўлиқ мослигини ҳисобини олб бориш
(масалан,сўзларнинг бир-бирига яқинлиги ва тартиби)
|
Топилган матннинг ҳужжат бошига нисбатан ҳолати
|
Ҳужжатнинг бошланишига ахборот қанчалик яқин бўлса, унинг мазмуни юқори бўлади деб ҳисобланади.
|
Ажратилган фрагментлар ва сарлавҳаларда сўров
сўзларининг мавжудлиги
|
Ажратилган фрагментларда қидирилаётган матнларни топишнинг аҳамияти оддий матндагига нисбатан юқори ҳисобланади
|
Саҳифа мавзусининг сўров мавзуси билан мослиги
|
Сўров матнида бўлмаган, аммо сўров мавзусига мос келувчи сўзларни қидирувда қўллаш
|
Домен номи ёки файли билан калит сўзнинг мослиги
|
Қидирув машиналари саҳифаларга қўшимча «оғирлик» беради, уларда домен ёки файл номи калит сўз билан мос келади.
|
Қидирув сўровларининг каталог таърифи билан
мослиги
|
Агар қидирув сўровларининг сўзлари каталог таърифи билан мос бўлса, сайт юқори рейтинг олади.
|
Кам учрайдиган сўзларнинг аҳамияти
|
Қидирув сўзлари ҳужжатда қанча кам учраса, унинг аҳамияти ортиб боради
|
Матн фрагментларини баҳолаш аҳамиятини Г.Лун ишлаб чиққан. У матн фрагментларини қуйидаги ифода орқали баҳолашни таклиф
қилган: 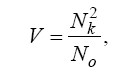
бу ерда: V – фрагмент аҳамияти; Nk – ушбу фрагментда калит сўзларнинг сони; NO – фрагментдаги сўзларнинг умумий сони.
Калит сўзларни аниқлаш тизими, одатда статистик частота таҳлилини қўллайди (В. Пурто методикаси). Агар:
F– матнда турли сўзлар учратйдиган частота;
P–фойдалиликнинг нисбий қиймати (муҳимлик);
C – сўзлар частотаси ва уларнинг фойдалилиги ўзаро нисбатини аниқловчи константа.
Шунда F (P) боғлиқлиги қуйидаги формула орқали аниқланади:
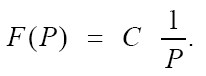
Берилган ҳолат частотанинг икки чегаравий аҳамияти мавжудлигини тахмин қилади:
қуйи чегарадан кам частотага эга сўзлар жуда камёб ҳисобланади (ҳужжат мазмунини акс эттиришга қодир эмас), юқори чегарадан ўтиб кетувчи частоталиклар эса умумий, маънавий юкланишга эга эмас деб ҳисобланади;
Бу икки чегара орасидаги частотага эга сўзлар эса берилган аниқ ҳужжат мазмунини ифодалайди.
Ҳавола критерияларига асосан ҳужжат цитата олиш индекси ҳисобидан сараланади.
Цитата олиш индекси – бу сайтнинг Интернетда машҳурлиги кўрсаткичи, қидирилаётган ресурсда бошқа сайтларга ҳаволаларнинг сони ва аҳамияти билан аниқланади. Сайтга ташқи ҳаволаларнинг умумий сони цитаталаш ҳисоблари учун критерийлар сифатида тўғри келмайди, чунки машҳур бўлмаган ресурсларга ҳаволаларнинг аҳамияти машҳур сайтлар ҳаволалари аҳамиятига қараганда жуда оз.
Цитаталаш индексини аниқлашда нафақат сайтга ташқи ҳаволалар сони эътиборга олинади, балки маълумотга ҳавола этилган ўз сайтларининг цитаталаш индексига эътибор берилади. Анча қимматли ҳаволалар – юқори цитатали сайтларнинг бош саҳифасида жойлашган ҳаволалар. Умумий ҳолатда Web- саҳифага ҳар бир тўғри ҳавола ҳажм бўйича цитаталашни кўпайтиради, ҳажм ҳавола қилинувчи саҳифага цитаталашга пропорционал ва акси ҳавола этилаётган саҳифада ҳаволалар умумий сонига пропорционал бўлади.
Ўз вақтида икки америкалик аспирантлар Сергей Бринва Ларри Пейдж 1997 йил Google қидирув машинасини асослаб берган, тармоқда ҳужжатлар бўйича фойдаланувчи ҳаракатини эмуляция қилувчи модель ишлаб чиқилган. Бундан тахмин қилинадики, тенг эҳтимолликка эга фойдаланувчи ҳужжатда мавжуд бўлган, айнан шу вақтда кўриб чиқаётган исталган ҳаволалар бўйича ўтиши мумкин. Шунингдек фойдаланувчининг аниқ ҳужжатга тушиш эҳтимоли бошқа ҳужжатлардан унга ҳавола этиладиганлар сонига ва ҳавола этилаётган ҳужжатларда фойдаланувчи бўлиш эҳтимоли ҳамда бу ҳужжат қанча чиқиш ҳаволаларига эга эканлигига боғлиқ. Бу эҳтимолик саҳифа нуфузи ёки даражаси кўрсаткичи сифатида қабул қилинган (PageRank):
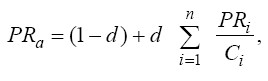
бу ерда: PR a– PageRank саҳифалар a; d – сўниш коэффициенти (шундай эҳтимолликни билдирадики, саҳифага кирган фойдаланувчи бу саҳифада бўлган бир ҳаволага ўтади, тармоқ бўйича саёҳат қилиб юрмайди), одатда 0,85 га тенг ўрнатилади; i – a саҳифага ҳаволаларни ўз ичига олувчи саҳифа(i 1дан n гача ўзгаради); PR i PageRank i саҳифаси, a саҳифага ҳавола этилади; Ci – i саҳифасида ҳаволаларнинг умумий сони; 1
/ C i -i саҳифасида бўлган фойдаланувчи кириши мумкин бўлган C i лар ичидан a саҳифасига ҳаволаларни танлаш эҳтимоллиги; d*PRi Ci «назарий
кириш» оқими, у i саҳифасидан a саҳифасига етиб боради(суммалаштириш a саҳифасига ҳавола этилувчи барча саҳифалар бўйича бўлади ); (1-d ) саҳифанинг минимал PageRank (фойдаланувчи мунтазам равишда бошланғич нуқта сифатида янги сайтни танлагани учун у нолга тенг эмас).
Кенг тарқалган янглишишлардан бири , PageRank ни ушбу формула орқали алоҳида олинган ҳужжат учун ҳисоблаб чиқариш мумкин, бунда PageRank нинг машхур белгиларидан унга ҳавола этилаётган ҳужжатлар қўлланилади. Бундай қилиш мумкин эмас. Қандайдир ҳужжатнинг PageRank ини ҳисоблаш учун қидирув базасидаги ҳар бир ҳужжат учун линия тенгламаларининг N тизимини тузиш керак , унда N – қидирув базасидаги ҳужжатлар сони. Барча ҳужжатлар учун PageRank белгиларинг суммаси 1 га тенг бўлган шартни бажаришда ( яъни фойдаланувчи исталган саҳифада бўлганлиги эҳтимоли мавжуд) , эркин аъзо (1 – d) ҳар бир тенгламага 1/N кўпайтмаси қўшилади. Бу тизим N номаълумларни ўз ичига олади. Уни ечиб, қидирув машинасига маълум бўлган ҳар бир ҳужжат учун PageRank белгисини оламиз.
Йирик қидирув машиналарининг қидирув базасида улкан миқдордаги ҳужжатлар сақланади. Тенглама тизимига мос келувчи матрица сийраклашишига қарамай, бу тизимнинг миқдорий ечими улкан ҳисоблаш қувватини талаб қилади. Шунинг учун қидирув тизими ҳисоблаш жараёнини баъзи фаразларни киритиб максимал даражада соддалаштиришга ҳаракат қилиши керак. Манна шу PageRank классик формуласини амалга оширишнинг аниқ ўзига хосликлари қидирув машиналарининг коммерция сирини ташкил қилади.
Фойдаланувчиларнинг баҳолаш мезонларига асосан саҳифаларни даражалаш учун қидирув чиқаришларида фойдаланувчилар томонидан саҳифалар сифатини баҳолаш тизими қўлланилади, улар маслаҳатларга асосланган: агар фойдаланувчи ҳавола бўйича ўтса, демак уни қизиқарли деб ҳисоблаган , агарда қидирув тизимининг саҳифасига узоқ вақт қайтмаса унинг кутганлари ўз тасдиғини топади.
Rambler қидирув тизими қидирув натижаларини даражалаганда қидирув сўровларига жавобда машҳурлик коэффициентини қўллайди, у охирги бир неча ҳафта давомида ушбу саҳифани кўриб чиққан фойдаланувчилар сони билан аниқланади. Берилган коэффициент, алгоритм PageRank сингари, тармоқ саҳифалари орасидаги гиперҳаволалар ҳисобига асосланган, бироқ буни амалга ошириш қўшимча равишда Top100 счетчигидан олинган саҳифаларга киришнинг реал маълумотларини қўллайди. «Классик» ҳавола алгоритмлари амалда фақат Web-мастер тармоғи фойдаланувчиларининг бир категорияси фикрини эътиборга олади. Ҳақиқатда, агар кўп сонли Web-мастерларга у ёки бу ресурс ёқса, улар унга ҳаволаларни жойлаштиради. Оддий фойдаланувчилар қоида бўйича саҳифа ва сайтлар яратиш билан шуғулланишмайди, шунинг учун уларнинг фикрини эътиборга олишнинг имкони йўқ. Top100 счетчиги машҳурлик коэффициентини ҳаққоний бўлишига мўлжалланган.
Бироқ, охирги пайтда Top100 счетчигидан олинган ҳужжатларни давомати ҳақидаги маълумотларга кўра, машҳурлик коэффициентига тобора камроқ таъсир кўрсатяпти, чунки счетчик баъзи сайт эгалари қўллайдиган оммавий айлантиришларга қаршилик кўрсатишга қодир эмаслар. Бунга мувофиқ холда, тармоқ саҳифалари орасидаги
гиперҳаволалар ҳисоби асосида ҳисоблаб чиқарилувчи ташкил этувчилар кўпроқ аҳамият касб этади.
Баён этилган мезонларга мувофиқ, сўровларга яқинлаштириб акс эттирилган ҳужжатлар релевантлигини аниқлаш жараёни формуласини қуйидагича тасаввур қилиш мумкин:
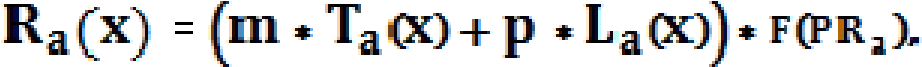
бу ерда: Ra (x) – a ҳужжатнинг xсўровга якуний мослиги;
Ta (x) – a ҳужжатнинг x сўровга ҳужжат матнининг релевантлиги
(код); La (x) – a ҳужжатнинг x сўровга бошқа ҳужжатлардан ҳаволаларни ҳисобга олган матннинг релевантлиги; PRa - a саҳифасининг PageRank ; F (PRa ) монотон камаймайдиган функция, ваҳоланки F(0) = 1 ва эътироф этиш мумкинки, F(PRa ) = (1+ q * PRa ); m, p, q– оғирлик коэффициентлари, улар қидирув тизимлари ишлаб чиқувчилари томонидан аниқланади.
Юқорида баён этилганларни эътиборга олиб, таъкидлаш мумкинки, саҳифа даражасини (рангини) ошириш учун тармоқдаги ҳужжатларнинг кўпчилик қисми унга мурожаат қилишига эришиш устида ишлаш керак. Буни турли усуллар билан амалга ошириш мумкин– бошқа сайтлар билан ҳаволалар алмашиниш йўли билан, каталоглардан рўйхатдан ўтиш ва турли тематик ресурслар орқали ва ҳ.к.
Идеал усул – ўз сайтини шундай қизиқарли ва ажойиб қилиш керакки, бошқа ресурс эгалари ўзлари унга ҳаволани қўйишни зарур деб ҳисобласин. Шуни унутмаслик керакки, ҳужжат даражасини (рангини) ҳисоблаганда ташқи ва ички ҳаволалар эътиборга олинади. Шунинг учун ақл билан қилинган перелинковка мавжуд ахборотлар нуқтаи назаридан энг муҳимлари даражани кўтариш имконини беради. Бу маънода энг муҳим ҳужжатлар албатта сайтнинг бош саҳифасидан ҳаволага эга бўлишлари шарт, у одатда сайтнинг барча саҳифалари орасида энг юқори даражага эга, бунинг натижасида сайтга кўпчилик ташқи ҳаволалари унга кўрсатади.
3. Асосий қидирув тизимлари
Ҳозирги кунда 3 та асосий халқаро қидирув тизимлари мавжуд: Google, Yahoo и MSN Search, улар ўз базалари ва қидирув алгоритмларига эга. Қолган қидирув тизимининг кўпчилиги у ёки бу кўринишда 3 та санаб ўтилганларни қўллайдилар. Масалан, AOL (search.aol.com) қидирув ва Mail.ru, Google базасини, AltaVista, Lycos ва AllTheWeb эса –Yahoo базасини қўллайдилар.
Рус тилидаги Internet доирасида ўттиздан ортиқ қидирув тизимлари фаолият юритади. 90% га яқин аудитория 3 та энг машҳур қидирув тизимларидан фойдаланади: Яndex, Google, Rambler (21.2-жадвал).
Керакли ҳужжатларни излаш учун аниқ қидирув тизимига мурожаат қилиш керак ва бир ёки бир неча сўздан иборат қидирув сўровини тузиш лозим. Сўровда тиниш белгилари ишлатилиши мумкин. Сўровлар тилининг нозик томонларига эътибор бермай, оддий сўровлар тузиш мумкин . Агар қидирув қаторига бир нечта сўзларни тиниш белгиларисиз ва мантиқий операторларсиз киритилса, бу сўзлар учраган барча ҳужжатлар топилади (бир- биридан чегараланган масофада). Бироқ қидирув тизимининг сўровлар тилини тўғри қўллаш ва билиш қидирувни тез ҳамда самарали амалга ошириш имконини беради.
2- жадвал Рус тилидаги Internet қидирув тизимлари
-
Қидирув тизими
|
Сервер
|
Аудитория хиссаси
|
Яndex
|
http://www.yandex.ru
|
до 67 %
|
Google
|
http://www.google.com
|
до 33 %
|
Rambler
|
http://search.rambler.ru
|
до 20 %
|
Поиск@Mail.ru
|
http://go.mail.ru
|
до 15 %
|
АПОРТ
|
http://www.aport.ru
|
до 10 %
|
MSN
|
http://search.msn.com
|
до 3 %
|
Nigma
|
http://nigma.ru/
|
до 3 %
|
Yahoo!
|
http://search.yahoo.com
|
менее 1 %
|
Altavista
|
http://www.altavista.com
|
менее 1 %
|
WebAlta
|
http://webalta.ru/
|
менее 1 %
|
Барча қидирув тизимлари сўровлар тилининг ўхшаш принципларини (тамойиллари) қўллайдилар. Ҳар бир қидирув тизими учун сўровлар тилининг тўлиқ ёзиб берилганига ҳаволаларни бош саҳифадан топиши мумкин. Сўровлар тилининг кўпчилигида оддий сўровдан ташқари қуйидаги операторларни бериши мумкин- ВА (AND), ЁКИ (OR), ЙЎҚ (NOT), метасимвол *, 5 тагача эркин символларни алмаштиради, коэффициент символлар + ва –, сўровда киритилаётган сўзларнинг аҳамиятини ошириб ёки камайтиришга хизмат қилади.
4. Яndex қидирув тизими
Яndex қидирув тизимига кириш (http://www.yandex.ru) 1997 йил яратилган. Қидирув нафақат Web- саҳифалар бўйича, балки маълумотларнинг махсус массивлари бўйича ҳам, яъни улар орасида етакчи ахборот агентликлари янгиликлари, Internet-магазин маҳсулотлари, WAP – сервер ресурслари орқали амалга оширилади.
Яndex Internet-ресурсларнинг хусусий каталогини қўллаб-қувватлайди, у Яndex'а (CY – Citation Yandex) цитаталаш индекси асосида шаклланади. Қандайдир Web-саҳифанинг CY си бу саҳифага ҳаволаларни ўз ичига олувчи бошқа саҳифалар сони билан ўлчанади . Ресурсларни баҳолашнинг бу усули тамоман оддий саҳифага кириш сонини ҳисоблашдан фарқ қилади.
Яndex оддий ва кенгайтирилган қидирув интерфейсларига эга, шунингдек қидирув натижаларини бериш форматини созлаш саҳифасига эга. У хусусий мантиқий операторларни белгилаш тизимини қўллайди,шунингдек кўп сонли қидирув функцияларини қувватлайди.
Яndex қидирув тизими уй саҳифасининг юқори қисмида калит сўзларни киритиш майдони жойлашган. (21.1-расм).
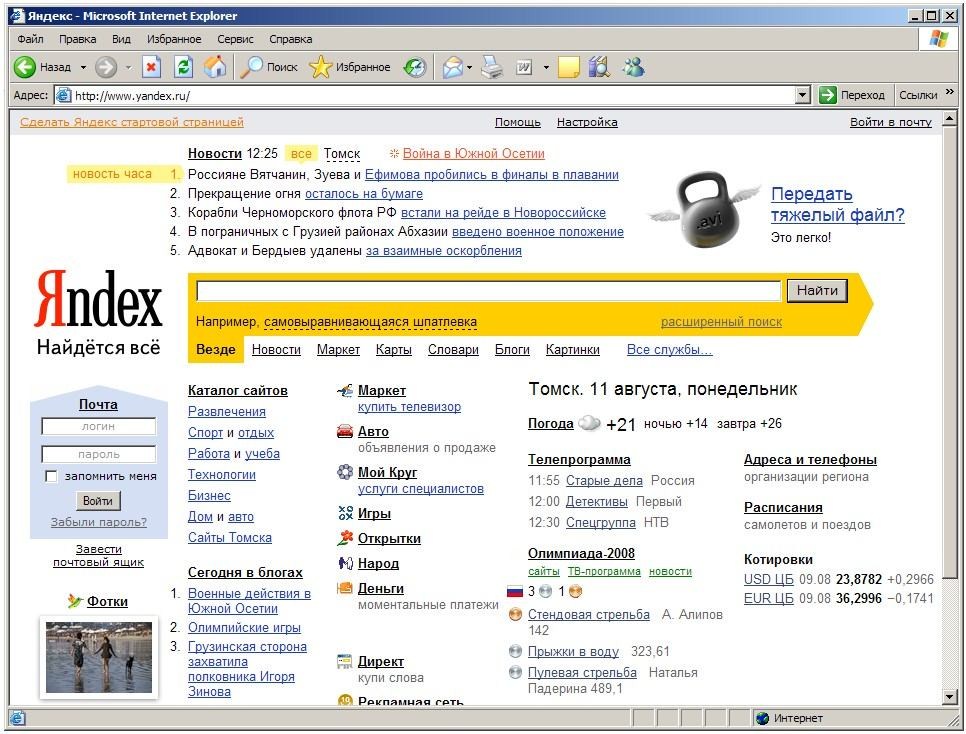
1.-расм. Яndex қидирув тизимининг уй саҳифаси.
Сукут бўйича сўров сўзлари OR оператори билан боғланади. Қидирув майдонининг қуйи қисмида сўровни шакллантиришга мисол келтирилган, у оддий қидирувда ҳар бир янги очилган саҳифада ўзгариб туради. Пастдаги селектор тугмалари қуйидаги соҳалар бўйича қидирувни чеклаш имконини беради: «Янгиликлар», «Маркет», «Хариталар», «Луғатлар», «Блоглар», «Суратлар».
Калит сўзларни излаш уларнинг морфологиясини ҳисобга олган ҳолда олиб борилади. Агар аниқ сўз шаклини қидириш керак бўлса, унинг олдида пробелсиз «!» белгиси қўйилади. Тизим сатрли ва ёзма ҳарфлар билан терилганларни фарқлайди. Қўштирноқ ичига олинган ибораларни ҳам қидиради. Калит сўздан олдин «+» ва «–» белгиларини қўйиш мумкин, улар мантиқий операторлар AND ва NOT ни ўрнини босади.
Яndex бир вақтда калит сўзлар орасида яқинлик даражасини белгиловчи хусусий мантиқий операторлар тизимини қўллайди. Мантиқий операторлар AND ва NOT «&» ва «» символлари билан ҳам белгиланади. Бу символни қўллаш ҳужжатнинг алоҳида гапида калит сўзлар бор ёки йўқлигини билдиради.
Гап даражасидан бутун ҳужжат даражасига кўтарилиш учун символ-операторни иккитага кўпайтириш керак. Масалан , && кутубхонанинг сўрови бўйича архивлар орасидаги масофани ҳисобга олмаган ҳолда иккала сўзни ўз ичига олувчи ҳужжатлар, & кутубхонанинг сўрови бўйича эса архивлар, икки сўздан иборат бир гап доирасида хужжатлар топилади.
Мантиқий оператор OR «|» символи ёрдамида киритилади ва ҳужжатнинг бутун матнни доирасида хизмат қилади. Мураккаб қидирув ёзишмаларини тузишда думалоқ қавслардан фойдаланиш мумкин.
«/» символи калит сўзлар орасидаги максимал масофани маълум сон билан чегаралайди. Масалан, /5 кутубхонанинг сўрови бўйича архивларда шундай ҳужжатлар топиладики, калит сўзлар орасидаги масофа 5 сўздан ошмайди. «/+» символлар комбинацияси масофани аниқ бериш имконига эга. /+2 кутубхонанинг сўрови бўйича архивларда «кутубхоналар, соҳа архивлари» иборалари бўлса, ҳужжатлар релевант бўлади.
Шунингдек html-ҳужжатларининг маълум доираларида қидириш учун қуйидаги махсус операторлар қўллаб-қувватланади:
$title –сарлавҳада;
$anchor –ҳаволалар матнида;
#keywords= – калит сўзларда («keywords» майдони);
#abstract= – тавсиф қидирувида («META» майдони);
#image= –тасвир файли номида;
#hint= – тасвирга имзода (иловада);
#link= – берилган URL-адресга ҳаволалар қидирувида; #url= – берилган сайтда (саҳифада) ҳужжатларни қидириш.
Яndex тизимининг кенгайтирилган қидирув интерфейси шаблондан иборат, шаблон калит сўзларни киритиш майдонидан, уларни жойлаштириш ва қўллаш тавсифлари, шунингдек топилган саҳифаларнинг тили, муддати ва формати бўйича ўзига хос хусусиятлардан иборат. (21.2-расм).
Қидирув натижалари ҳужжат сарлавҳаси кўринишида, унинг таърифи, URL-адреси, шунингдек ушбу ҳужжат тушувчи Internet- ресурслар List.ru каталоги рубрикаларига ҳаволалар кўринишида берилади. (21.3- расм).
Қидирув натижалари сўровга ҳужжатлар даражаси бўйича сараланади ва саҳифага 10 та ҳужжат бўйича берилади (21.4-расм).
Ҳужжат релевантлиги қатор омилларга боғлиқ: калит сўзларининг частота тавсифларидан, ҳужжат матнида уларнинг яқинлигидан, шунингдек фойдаланувчи мустақил бериши мумкин бўлган сўзнинг параметрларидан. Бунинг учун «:»символи ва маълум рақам ишлатилади. Масалан, «шаҳар архивлари» кутубхоналар бўйича:3 «шаҳар архивлари» ва “кутубхоналар” сўзларидан иборат ҳужжатлар топилади, ҳужжатда қанчалик кўп “кутубхоналар” сўзи учраса, у натижалар рўйхатининг бошларига яқин бўлади.
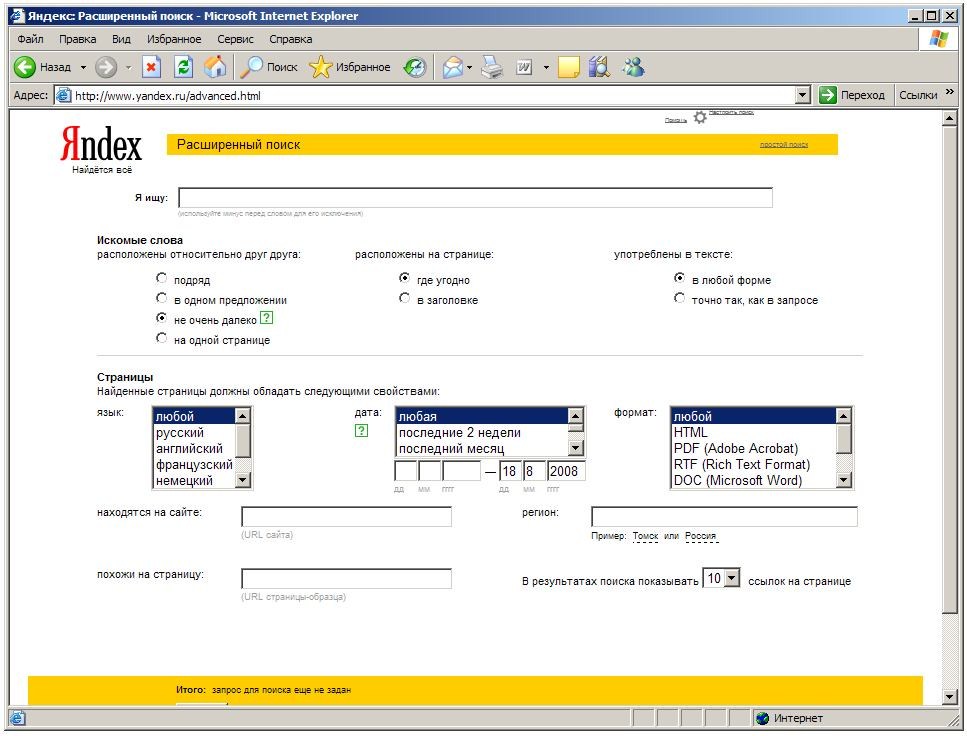
2.-расм. Яndex тизимининг кенгайтирилган қидирувли интерфейси.
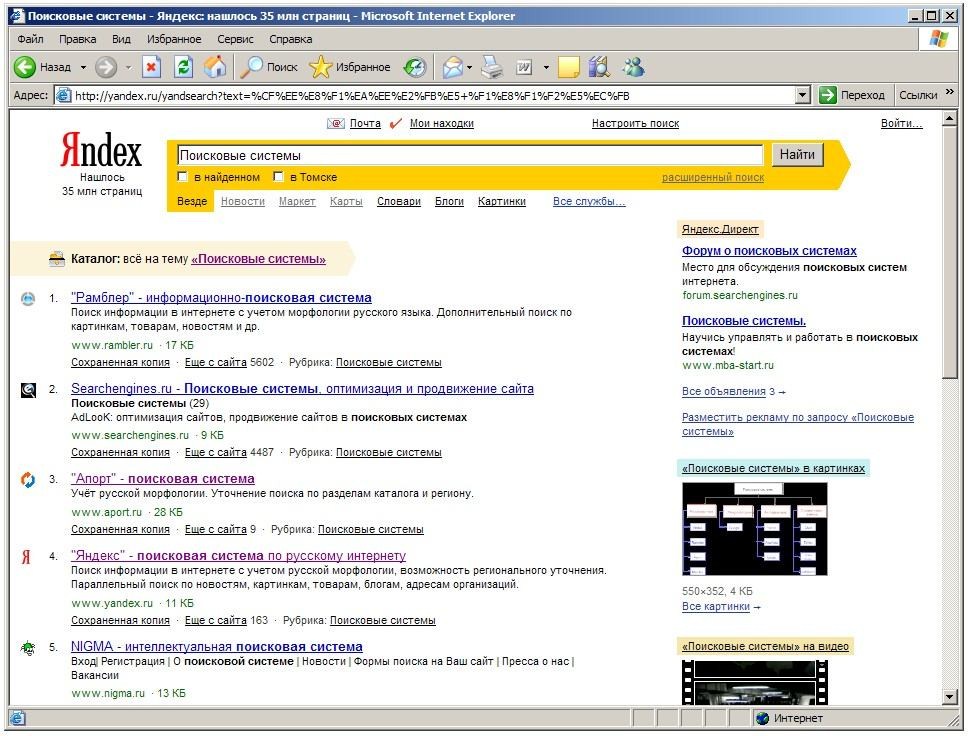
3.-расм. Яndex тизими қидирув натижалари.
Қўшимча имкониятлар қаторида фойдаланувчиларига такиф қилинувчи Яndex қидирув тизими деб қуйидагиларни айтиш мумкин: Internet-ресурслар каталоги билан интеграция List.ru, етук ахборот агентликлари янгиликлар ленталари бўйича қидирув, электрон магазинлари қидируви, россия WAP-ресурслари бўйича қидирув, шунингдек «Регионал Яndex» дастури.
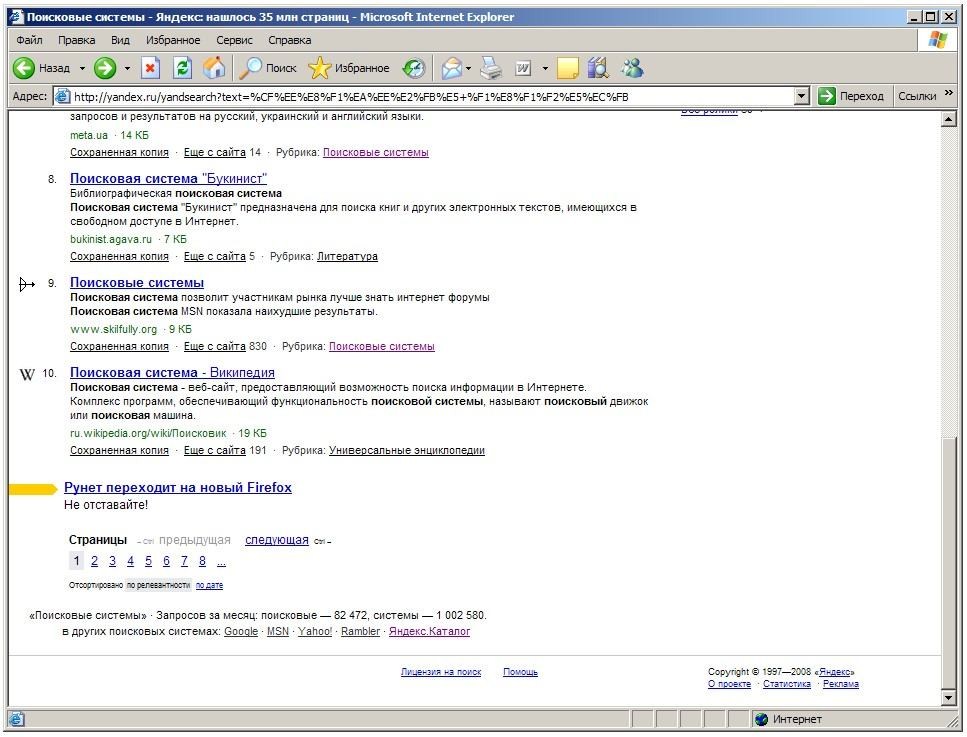
4.-расм. Яndex тизими қидирув натижаларини чиқариш шакли.
5. Google қидирув тизими
Google қидирув тизими (http://www.google.com) 1999 йили сентябрь ойида яратилган. Бугунги кунда база ҳажми 1 миллиарддан ошиқ ҳужжатдан иборат. Тизим фойдаланувчига оддий ва кенгайтирилган қидирув интерфейслари ва қидирувни олдиндан ўрнатиш саҳифасини яратишни таклиф қилади (21.5-расм).
5.-расм. Google қидирув тизимининг уй саҳифаси.
Google нинг фарқли томони , ҳужжатнинг релевантлик даражасини аниқловчи технология ушбу ресурсга бошқа манбалардан ҳаволалар таҳлили йўли билан аниқланади. Бу технология PageRankTM деб номланади. Қандайдир Web- саҳифага бошқа саҳифалардан ҳаволалар кўп бўлса, унинг Google базасида рейтинги юқори бўлади. Қидирув натижаларини беришда рўйхат бошида юқори рейтингга эга саҳифалар бўлади (бошқа тенг ташкил этувчилар).
Асосий базадан ташқари сўров БД RealNames ва Internet- ресурсов Google Web Directory сингари информацион массивлар каталогини қўллаб қайта ишланади.
Google ўзининг базасига бошқа қидирув тизимларига киришга рухсат беради, улар орасида машҳурлари Netscape's Search и Yahoo!.
Тизимнинг асосий афзаллиги бу - базанинг ҳажми, стоп-сўзлар кичик рўйхати ва агар у асосий адресдан ўчирилган бўлса Google базасидан ҳужжатлар нусхасини олиш имконияти хисобланади.
Google қидирув тизими оддий ва кенгайтирилган қидирув ни амалга оширади. Сўровни қайта ишлашда тизим сўзлар орасидаги пробелни мантиқий оператор AND сингари интерпретация қилади, бироқ операторнинг ўзи киритганини қўллаб-қувватламайди. Сўров қидирув майдонига киритилади. Ўнг томонда «кенгайтирилган қидирув» саҳифасига ҳаволалар ва қидирувни олдиндан ўрнатишни яратувчи саҳифа жойлашган: «Настройки»(созлаш) и «Языковые инструменты»( тил инструменти).
Агарда стоп-сўзларни қўллаб қидирув олиб бориш керак бўлса, унинг олдида «+» белгиси қўйилади. Тизим мантиқий оператор ОRни қўллашни қувватлайди. NOT оператори пробелсиз сўз олдида «–» белгисига ўзгартирилади. Ибора олдида «+» ва «–» белгиларини қўйиш мумкин.
Ибора бўйича қидирув қўллаб-қувватланади. Ибора қўштирноқ ичига олинади. Қўштирноқдан ташқари Google сўзларни боғлашга хизмат қилувчи қуйидаги тиниш белгиларини ҳисобга олади: дефислар, эгри чизиқлар, тенглик белгилари, апострофлар. Бу белгилар билан боғлиқ сўз қидирилганда ибора сифатида қабул қилинади.
Тизим морфологияни ҳисобга олган қидирувни, калит сўзлар қисмлари бўйича қидирувни қўллаб-қувватламайди ва сатрли ва ёзма ҳарфларни ажрата омайди.
Қидирув иборасини тузаётганда иккита махсус операторни қўллаш мумкин. link оператори: берилган URL га ҳаволали ҳужжатларни аниқлаш имконини беради. Масалан , link сўровига: www. nlr. ru уй саҳифасига ҳаволалар билан РМК (Россия миллий кутубхонаси) ҳужжатлар олинади. Бундай сўровни оддий калит сўзлар билан комбинациялаш мумкин эмас. site оператор: маълум web-сайтдан ҳужжатларни излаш доирасини торайтиради. Масалан , site сўрови бўйича: www. nlr. ru database РМК Webсайтида «database» сўзи бўлган ҳужжатлар топилади.
Кенгайтирилган қидирув саҳифа интерфейси фильтрлардан иборат шаблон кўринишида амалга оширилади (21.6-расм).
6.-расм. Google тизимини кенгайтирилган қидирув интерфейси.
Google қидирув тизими берилган ресурсга бошқа манбалар ҳаволаларини таҳлил қилиш йўли билан ҳужжат релевантлигини аниқлайди. Барча релевант ҳужжатлардан олинган қидирув натижаларини саралашда юқори рейтингли саҳифалар танлаб олинади ва рўйхат бошига жойлаштирилади.
Натижалар рўйхатидан олдин сўровлар бўйича топилган ҳужжатлар сони ва Google базасида сўровларни қайта ишлаш вақти кўрсатилади (21.7-расм).
Қидирув натижаларини чиқариш формати қуйидаги элементлардан ташкил топади (21.8-расм):
ҳужжат сарлавҳаси;
сўров сўзларининг тўқ шрифт билан берилган матндан парчалар;
meta майдонидан олинган ҳужжат тавсифи;
Google Web Directory каталоги мос бўлимига ҳаволалар;
саҳифа URL-адреси ;
топилган ҳужжатнинг килобайтлардаги ўлчови;
Googleбазасидаги ҳужжат нусхасига ҳавола;
берилганига релевант бўлган ҳужжатларни қидиришга бериш учун ҳавола;
агар бўлса, сўровга релевант сайтнинг бошқа саҳифалари.
7-расм. Google тизими қидирувининг натижалари.
Google фойдаланувчига тизим интерфейсини созлашнинг турли имкониятларини ва қидирув функцияларининг ўзини таклиф қилади. Уй саҳифасида қидирувни олдиндан ўрнатиш саҳифасига ҳавола бор: «Настройки» ва«Языковые инструменты». Google43 тилдаги интерфейсларни қўллаб-қувватлайди ва ҳар бир топилган ҳужжатни браузернинг янги ойнасида очишга рухсат беради. Фойдаланувчи ҳужжатлар излашни бир вақтнинг ўзида бир неча тилда бериши, қидирув натижалари сонини тартибга солиши, шунингдек норматив бўлмаган лексикани ўз ичига олган ҳужжатлар учун фильтрни ёқиши мумкин .Яратилган олдиндан ўрнатишларни браузер эслаб қолади ва улар ҳар бир қидирув сессиясида ўзгартирилгунига қадар ишлатилади.
8.-расм. Google тизимини қидирув натижаларини бериш формати.
6. Rambler қидирув тизими
Rambler қидирув тизимига кириш (http://www.rambler.ru) 1996 йил очилган. Бу биринчи Россия қидирув тизимларидан бири бўлиб, фаол ривожланмоқда. Тизимда бир вақтнинг ўзида бир неча роботдастурлардан фойдаланилади ва бир сонияда 5 га яқин фойдаланувчи сўровларини қайта ишлайди.
Rambler портал бўлиб, қидирув тизими, рейтинг-классификатор Rambler's Top100, шунингдек бир қатор бепул сервислар ва ахборот лойиҳаларни бирлаштиради. Портал ресурслари бир суткада 3,5 млн. киришларни рўйхатга олади. Энг қизиқарли лойиҳалардан «Rambler-Илмфан», «Интерфаол хариталар» ва «Луғатлар» лар саналади. Бундан ташқари фойдаланувчиларга ftp-серверларда ахборот қидириш имконияти берилади (http://ftpsearch.rambler.ru:8101/).
Ахборот қидириш учун калит сўзлардан иборат сўровлар уй саҳифасининг юқори қисмида жойлашган қидирув ойнасига киритилади (21.9-расм). Сукут бўйича мантиқий оператор «AND» қўлланилади.

9.-расм. Rambler қидирув тизимининг уй саҳифаси.
Тизим мантиқий оператор «AND» («&») ва «OR» («|») лардан фойдаланиб сўров тузишни қўллаб-қувватлайди. Мураккаб қидирув гвпини тузиш учун оператор ҳаракатини тартибга солувчи ярим думалоқ қавслар ишлатилади. Rambler ибора(фраза) бўйича қидирувни қўллайди. Ибора қўштирноқ ичига олинади. Морфологик шаклларни қидириш оператор «#»дан, бир илдизлилар эса «@»оператори билан берилади. Ўнгдан ва сўзнинг ўртасидан кесиб ташлаш қидирув функцияси қўллабқувватланади. «*» символиисталган миқдордаги ҳарфлар ўрнида қўлланади; «?»символибир номаълум символ ўрнида қўлланади.
Сўровни тузишда қуйидаги махсус операторлардан фойдаланиш мумкин:
$All –html- ҳужжатининг барча бўлимларида қидирув;
$URL –html- ҳужжатининг URL-адресидақидирув;
$Title – html- ҳужжатининг сарлавҳасида қидирув;
$Essence – html- ҳужжатининг аннотациясида қидирув;
Кенгайтирилган қидирув саҳифасининг интерфейси сўровни аниқлаш учун бир неча фильтрлардан иборат, калит сўзлар ва шаблонлар киритувчи майдонга эга ( 20-расм).
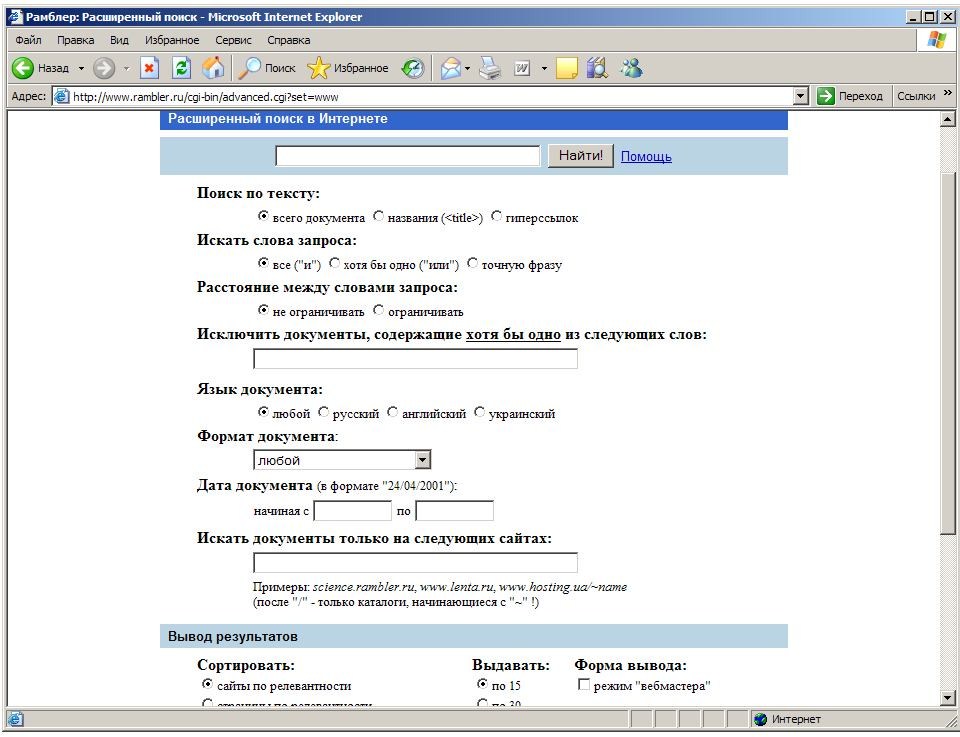
10.-расм. Rambler тизимининг кенгайтирилган интерфейси.
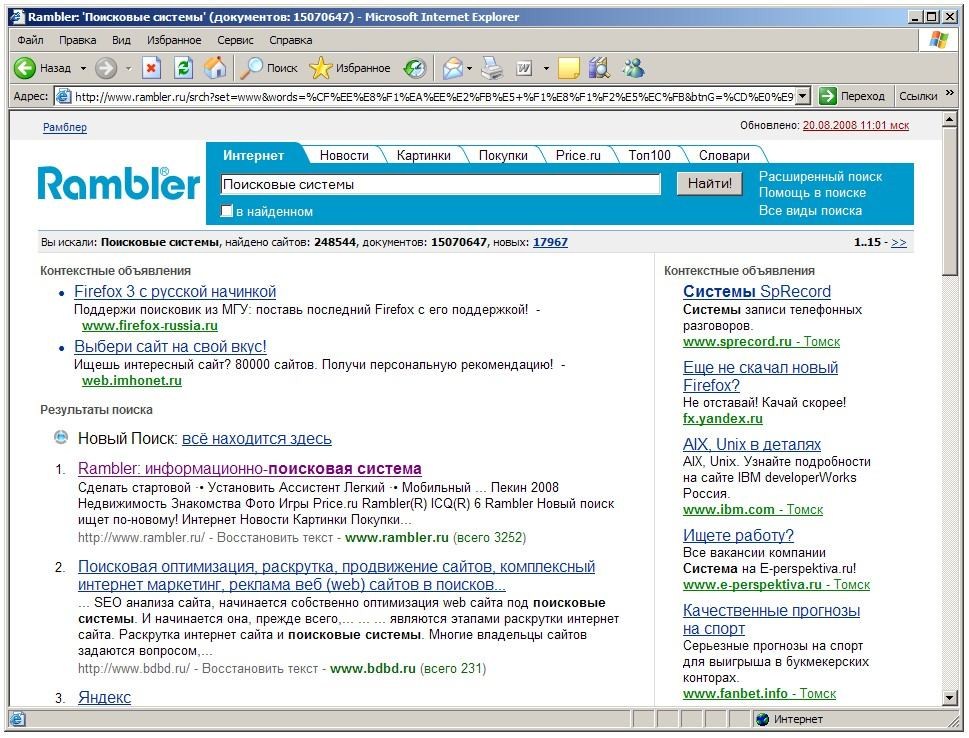
11.-расм. Rambler тизимини қидирув натижалари.
«Сўров сўзини излаш» опцияси мантиқий операторлар «AND» ва «OR» ни ўрнида қўлланувчи «все» ва «хотя бы одно» селектор тугмаларига эга. У ёки бу сўзлардан ташкил топган ҳужжатларни рад этиш учун «Исключить документы, содержащие хотя бы одно из следующих слов:» майдони тўлдирилиши керак. Тизим маълум вақт мобайнида яратилган ҳужжатларни излашни чегаралашга имкон беради. Қуйида саралаш параметрларини аниқлаш соҳаси ва қидирув натижаларини бериш жойлаштирилган.
Сукут бўйича топилган ҳужжатлар релевантлик даражаси бўйича сараланади. Ҳар бир саҳифада топилган ҳужжатларга 15 тадан 50 тагача ҳаволалар бўлиши мумкин (21.11-расм).
Қидирув натижаларини беришнинг тўлиқ формати қуўидаги элементлардан иборат : сайтнинг URL-адреси , ҳужжатнинг сарлавҳаси, калит сўзлари тўқ шрифт билан берилган саҳифа матнидан парчалар, ҳужжатнинг яратилиш ёки охирги янгиланиш муддати , бошқа қидирув тизимларига ҳаволалар (21.12-расм). Бундан ташқари , ушбу сайтда қанча топилган ҳужжатлар мавжудлиги ҳақидаги маълумот кўрсатилади.
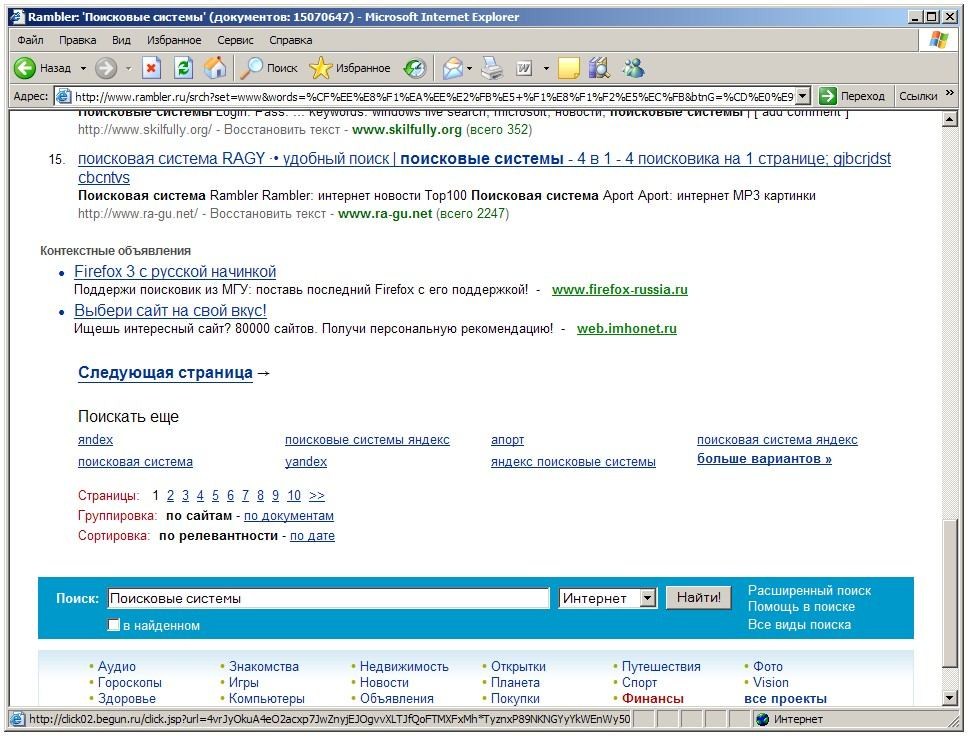
12.-расм. Rambler тизимини қидирув натижаларини бериш формати.
АДАБИЁТЛАРРЎЙХАТИ
1.ComputerNetworkingATopDownApproach. James. F. Kuross. Pearson Education 2013.
2.Олифер В.Г., Олифер Н.А. Компьютерные сети.Принципы, технологии, протоколы. 3-е изд. СПб.: Питер,2006- 958 с.
3.Арипов М. ва бошқалар. Ахборот технологиялари. Тошкент: Ношир, 2009368б.
4.Семенов Ю.А. Протоколы Интернет.М.: Горячая линия-Телеком,2001.-
1100 с.
5.Садчикова С.А. IP-ТЕЛЕФОНИЯ. Учебное пособие для студентов специальностей 5А522202, 5А522203, 5А522205, 5А522216. Ташкент. ТУИТ.2008 |
|
|
 Скачать 2.04 Mb.
Скачать 2.04 Mb.