Образец. 33425_Образец_оформления. Содержание 3 Алгоритмы планирования 12
 Скачать 1.18 Mb. Скачать 1.18 Mb.
|

2 РАЗРАБОТКА АЛГОРИТМА РАБОТЫ С ПРОЦЕССАМИ2.1 Структура, обоснование, описаниеИзвестна статистическая модель кэша StatCache, которая основывается на трассе обращений приложения к памяти и позволяет вычислить вероятность промаха для полностью ассоциативного кэша со случайной политикой замещения. Для большей части приложений сетевой обработки данных случайная политика замещения является одним из наиболее эффективных алгоритмов вытеснения записей в кэше, что позволяет пренебречь этим ограничением. Полностью ассоциативный кэш, имеет наибольшую эффективность, поэтому его использование в моделировании также является обоснованным. Методика расчета StatCache основывается на понятии «расстояния повторного использования». Оперативная память компьютера делится на блоки, равные длине строки кэша. Для каждой операции обращения к памяти вычисляется номер блока, с которым она взаимодействует. Расстояние повторного использования определяется как количество инструкций доступа к ОЗУ между обращениями к одному и тому же блоку памяти (рисунок 9). 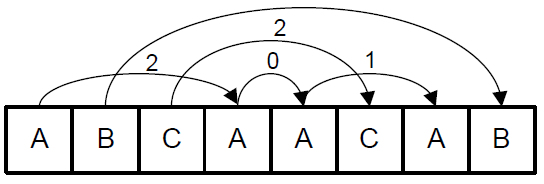 Рисунок 9 – Расстояние повторного использования для блоков памяти A, B и C Учитывая, что рассматривается полностью ассоциативный кэш со случайной политикой замещения, то вероятность того, что запись не будет замещена после первого промаха равна 1–1/L, где L — число строк в кэше. Для n промахов вероятность того, что запись останется в кэше равна (1–1/L)n. Таким образом, вероятность того, что строка кэша будет замещена после n промахов равна (формула 1): Для каждого обращения к памяти определим случайную величину Xi, которая равна 1, если произошел промах и 0 иначе. Также определим вероятность промаха при i–м обращении к памяти pi, которое выражается как математическое ожидание величины Xi: pi=M(Xi). Пусть A(i) — расстояние повторного использования для i–го обращения, тогда предыдущий доступ к этому же блоку оперативной памяти осуществлялся на (i – A(i) – 1)–м обращении. По формуле 2 общее число промахов кэша на этом интервале равно: Используя функцию, можно оценить вероятность промаха pi как (формула 3): Просуммировав обе части выражения от 1 до N, по формуле 4, получим: 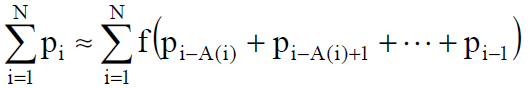 , (4) , (4)Выражение 4 определяет взаимодействие между всеми pi, но содержит слишком много неизвестных, что делает невозможным вычисление общей вероятности промаха для всего журнала обращений. Поэтому предположим, что общая вероятность промаха R не изменяется на протяжении всей работы приложения. Согласно формуле 5, отсюда следует, что: Заменим j на A(i) (формула 6): Подставив уравнение 6 в выражение 4 получим (формула 7): Система имитационного моделирования SimpleScalar предоставляет возможность генерации журнала изменений состояния конвейера процессора. Из журнала конвейера доступна информация о последовательности и адресах выполняемых команд, но отсутствует информация об эффективных адресах используемых блоков памяти, есть лишь имена базовых регистров и регистров смещения, в которых эти адреса хранятся. Для получения информации об используемых блоках памяти авторы дополнили функциональность SimpleScalar двумя новыми возможностями: ведение журналов обращений к памяти за данными и инструкциями с выводом физических адресов, к которым происходит обращение. Оба журнала имеют одинаковый формат. Каждая запись состоит из трех полей: тип обращения (принимает значения «l» – чтение или «s» – запись), размер запрашиваемого блока в байтах и адрес в ОЗУ, по которому производится обращение, записанный в десятичной системе счисления. Вероятность промаха кэша данных для приложений Frag и Antnet представлена на рисунке 10. 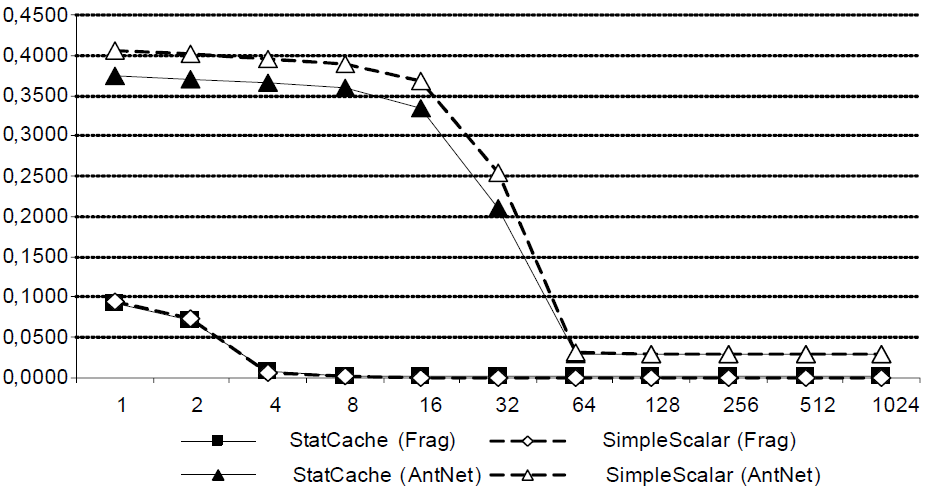 Рисунок 10 – Вероятность промаха кэша данных для приложений Frag и Antnet Журналы, полученные единожды, могут впоследствии многократно использоваться для анализа вероятности промахов кэшей разных размеров и обладающих различными длинами строк. Таким образом, исключается необходимость выполнения имитационного моделирования для каждой исследуемой структуры процессора. |