0 Заметки по Hibernate. Состояния персистентности New (Transient)
 Скачать 323.04 Kb. Скачать 323.04 Kb.
|

|
Заметки по Hibernate Состояния персистентности New (Transient) - по сути, любой экземпляр сущности, созданный оператором new. Такой объект не привязан к текущему контексту персистентности (к сессии и к кэшу первого уровня). Хибернейт не следит за состоянием этого объекта, и, если не перевести его в состояние persistent - не запишет его в базу по окончании транзакции. Важно запомнить, что если генерация id для сущности производится базой данных - объекты в состоянии Transient не должны содержать никаких значений в поле id Managed (Persistent) - в это состояние может попасть объект из абсолютно любого состояния. Что бы перевести объекты из состояния Transient в Persistenr - надо воспользоваться методом persist. Для перевода Detached объекта в это состояние - надо вызвать метод merge. И если ассоциированная с объектом запись была удалена, и объект находится в состоянии Removed - так же стоит вопсользоваться методом persist, чтобы снова сохранить данные в базу, а объект перевести в состояния Persist. Объект, находящийся в состоянии persist находится под наблюдением контекста персистентности. Любое изменение этого объекта в коде будет отображено в базе данных по окончании транзакции, или вызова методе flush. Объект в этом состоянии находится в кэше первого уровня, и экземпляр этого объекта может быть получен без обращения в базу в пределах одной транзакции. Detached - объект, который до этого был привязан к контексту персистентности, но теперь отделен от него. Отделение могло произойти по двум причинам: контекст персистентности был закрыт (закончилась тарзакция, закрылась сессия), либо объект был явно отделен методом detach или clear от ещё существующего контекста. Подобный объект имеет заполненное поле id, сгенерированное базой, но контекст персистентности больше не следит за изменением этого объекта. Что бы снова присоединить такой объект к контексту персистентности, и перевести его снова в Persistent надо вызвать метод merge, который сравнит состояние текущего detached объекта и данные из базы Removed - объект, ассоциированная с которым запись была удалена из базы. Такой объект так же не отслеживается контекстом персистентности и информация о нем больше не хранится в кэше первого уровня. Такой объект можно только сохранить в базу снова методом persist Удаление большого количества объектов В целях улучшения производительности для удаления большого количества объектов лучше всего использовать jpql или sql запрос, вместо последовательного удаления одного объекта за другим, используя методы entityManager или сессий хибернейта. Но у такого подхода есть и свои минусы: hibernate не будет знать, какие конкретно сущности, привязанные к контексту персистентности были обновлены, следовательно, hibernate не сможет реплицировать изменения в из базы в связанные с контекстом персистентности объекты. Те. сами объекты ника не изменятся, (соответственно и первоуровневый кэш будет неактуальным); Соответственно, перед тем, как выполнять запрос на удаление/изменение - сначала нужно убрать из контекста персистентности те объекты, которые были привязаны к контексту персистентности. Как этого добиться: Убедиться, что hibernate сбросил все накопленные в контексте персистентности изменения в базу данных, (хибернейт старается быть оптимизированным, и изменения сбрасываются базу только при необходимости) Удалить все сущности из контекста персистентности В контексте персистентности могут находиться объекты, которые ещё не связаны в базе. т.е. объекты, которые находятся в состояние Transient. А также прочие грязные объекты, которые требуют выполнения update стейтментов в базе. Если просто вызвать detach и отвязать все сущности от контекста персистентности - никакие изменения, сохраненные в этом контексте не будут направлены в базу. Поэтому сначала нужно явно вызвать метод flush и только после него detach. Либо, второй способ очистить контекст персистентности: вызвать метод clear. В отличии от detach, который убирает из контекста конкретный объект - clear очищает весь контекст персистентности; Разница между JoinColumn/JoinTable и mappedBy Все виды связей в jpa делятся ровно на два типа: двунаправленные и однонаправленные. Это значит, что моделировать связь мы можем либо на одной, либо на двух сторонах сразу. Характер связи и её направление не оказывает никакого воздействия на структуру таблиц в базе данных. Для двунаправленных связей мы обычно определяем: Сторону собственника Обратную ссылку (собственость) Аннотация JoinCoumn помогает нам описать ту колонку таблицы, которая используется для организации связи в таблицах бд. Атрибут mappedBy (аннотации ОпеТоМапу, например) используется для того чтобы определить ссылающуюся сторону (не сторона собственника) @JoinColumn - в связях вида 0ne2Many/Many20ne сторона, находящаяся в собственности обычно называется стороной “многих". Обычно, это сторона, которая держит внешний ключ. Эта аннотация, фактически, описывает физический (как в бд) маппинг на стороне ' многих”. В атрибут name этой аннотации дается название колонки, которая будет присоединена к таблице “многих” и которая будет заполняться значениями первичных ключей из таблицы-собственника. Таким образом - мы даём название для внешнего ключа. По факту - использование этой аннотации опционально, т.к. хибернейт, проанализировав сущность - поймет сам, что в таблице для этого класса нужно создать колонку, обозначающую внешний ключ, и даст ей соответствующее название “{name}_id”. mappedBy- атрибут размещаются на стороне собственника. С тех пор, как мы определили по средствам аннотации JoinColumn сторону “многих" - хибернейт знает, каким образом ему нужно организовать одностороннюю связь. Теперь, чтобы сделать связь двусторонней - всё что нам нужно, это определить сторону собственника. Атрибут mappedBy просто прописывается в аннотации Опе2Мапу и в качестве названия принимает название свойства (поля) объекта связанной сущности, посредством которой будет реализована эта связь. Мы должны указать настоящее физическое название поля, над которым поставим аннотацию JoinColumn. Подробнее про mappedBy. Этот атрибут говорит хибернейту что ключ для связи лежит на другой стороне. Это значит, что несмотря на то, что у нас есть две таблицы - только одна из них содержит ограничение на внешний ключ. Этот атрибут позволяет по-прежнему ссылаться из таблицы, которая не содержит ограничения на другую таблицу. Атрибут mappedBy тесно связан с аннотацией JoinColumn. Если применить атрибут mappedBy на одной стороне связи - хибернейт не станет создавать смежную таблицу. Резюмируя: аннотации JoinTable и JoinColumn при использовании с mappedBy с дефолтными значениями атрибутов, или с значениями атрибутов, которые бы повторяли дефолтные параметры, которые генерирует хибернейт без нашей помощи - являются просто декоративными и не несут никакого практического смысла. Эти аннотации по-настоящему используется только в тех случаях, когда нам требуется изменить название смежной таблицы или название колонок этой таблицы. Аннотация Transactional Эта аннотация должна находиться над методами сервисов, т.к. внутри этих методов содержится вся бизнес логика, которая включает в себя множество обращений в дао, каждый метод которого сам по себе является транзакционным. Т.е. на один метод в сервисе может быть открыто от 1 до гораздо большего числа транзакций. Там образом - хибернейт не может провести оптимизацию ленивым сбросом и вынужден все исполнять ровно так, как написано в наших методах. Связи OneToMany/ManyToOne Связь один ко многим является самым часто используемым типом связи в приложениях. Однако, этот тип связи не является очевидным и простым с точки зрения производительности. Есть довольно много подводных камней, которые стоит рассмотреть, прежде чем начать выстраивать архитектуру своего приложения. Рассмотрим один из распространенных способов организации связи один-ко-многим В данном примере используется аннотация @OneToMany и List на стороне сущности-собственника, объединяющий внутри себя все дочерние сущности. С точки зрения java программиста - довольно удобный вариант используя который можно легко осуществлять навигацию меищу дочерними сущностями и главной. Однако, с точки зрения дба и с точки зрения производительности подобный способ организации связи один-ко-многим является самым неэффективным. И вот почему: Хибернейт видит коллекцию дочерних сущностей и аннотацию ОпеТоМапу. По-умолчанию его поведение в этом случае будет таким: сгенерировать две таблицы для сущности-собственника и дочерней сущности. Сгенерировать смежную таблицу для связи таблицы дочерней сущности с таблицей сущности-собственника. Хибернейт не располагает данными о том, как конкретно мы хотим организовать эту связь, поэтому, он выбирает самую безотказную стратегию - использование смежной таблицы, (хотя с точки зрения дба такой подход больше напоминает связь многие-ко-многим). Почему это плохо: Мы имеем лишние накладные расходы в виде необходимости создания и поддержки третей таблицы. При вставке данных хибернейт выполняет insert не только в таблицу сущности-собственника и в таблицу дочерней сущности, но и в смежную таблицу. Что производит се+1 запросов, где се - одна запись в таблице дочерней сущности При удалении дочерней сущности хибернейт будет вынуищен сначала удалить все записи в смежной таблице (т.к. на данный момент хибернейт не располагает данными о том, как связаны записи в смежной таблице и ид дочерней сущности). И затем снова вставить оставшиеся (не удаленные) связи в эту таблицу. Как мы можем исправить эту ситуацию? Во-первых, для дальнейшего удобства использования кода - используем каскады и oprphanRemoval=true. Механизм работы с этим типом связи не поменяется, но код станет удобнее читать Во-вторых, попытаемся исправить ситуацию с удалением. Как было сказано выше - хибенейт не может определить, какую конкретно запись из смежной таблицы ему надо удалить, и помочь в этом может аннотация @OrderColumn, которая добавит в смежную таблицу индекс, ассоициированный с позицией элемента в коллекции у сущности-собственника @OrderColumn позволяет удалять объекты не задействуя лишние ресурсы базы данных. Однако, чем “левее:: в коллекции находится удаляемый элемент - тем больше записей в смежной таблице надо будет обновить. Если удалить первый элемент - то количество запросов с использованием OrderColumn и без использования этой аннотации сравняется. Правда мы больше не будем удалять и добавлять заново все записи, но нам придется эти записи обновлять. У этой проблемы есть ещё одно решение: использование Hash Set вместо ArrayList в качестве коллекции дочерних объектов. Ключевое отличие в том, что HashSet является множеством и работает на основании двух методов: equals и hascode (см. главу про переопределение этих методов). Используя эти два метода хибернейт может довольно легко определить ид дочерней сущности, по которой надо удалить запись в связанной таблице. На удаление одной сущности теперь будет направлен ровно два запрос в базу (удаление самой сущности и записи из смежной таблицы). Что мы имеем в итоге: дополнительный insert в смежную таблицу необходимость обновлять данные в смежной таблице при каждой операции с записью в дочерней таблице Дополнительную колонку в смежной таблице (если мы используем List) Всех вышеперечисленных проблем можно избежать, если мы просто уберем смежную таблицу, и будем хранить связь как колонку внешнего ключа в таблице дочерней сущности. До JPA 2.0 нам бы потребовалось полностью переносить связь на сторону дочерней сущности. Но в обновленной спецификации появилась возможность добавить аннотацию @JoinColumn прямо на список сущностей на стороне собственника. Что это дает: Больше нет необходимости использовать HashSet только для того, чтобы поддерживать связь позиции в коллекции с записью в базе. Мы можем больше не использовать третью смежную таблицу Количество запросов на добавление/удаление участников связи становится меньше. На добавление каждого участника связи отводится ровно два запроса (один из запросов вставляет данные в дочернюю таблицу, а второй делает set ownerjd в дочерней таблицу), как и на удаление. Однако, как мы увидим позже, количество запросов можно сократить вдвое. Рассмотрим способ организации связи один-ко-многим, когда id родительской сущности явно хранится на стороне дочерней сущности. Подобный способ организации связи один-ко-многим является самым эффективным из всех, т.к. он ближе всего по структуре к тому, как эта связь устроена внутри реляционной базы данных. Недостатки этого подхода в неудобстве использования кода. С одной стороны мы получаем самую лучшую производительность, с другой, мы лишаемся возможности использовать коллекцию дочерних элементов, имея ссылку на родительскую сущность. Теперь, вместо select + join fetch нам придется заводить отдельный метод в дао, который возвращает коллекцию дочерних элементов по идентификатору родителя. Возможно, это будет дополнительный запрос в нашей логике, но даже если так, подобная издержка перекрывается отсутствием се+1 запросов при работе с элементами связи. Возможно, если в нашем коде предусмотрено ну очень частое обращение к сущности родителя с необходимостью работы с дочерними сущностями.(но я убеоден, что при правильно написанной архитектуре такие случаи просто не могут возникать) В таком случае, конечно, было бы удобнее иметь коллекцию на стороне родительской сущности. Однако, как было показано выше - использование только коллекции на стороне собственника связи - является самым непроизводительным решением этой проблемы. Поэтому в ниже мы рассмотрим двустороннюю связь один-ко-многим. Рассмотрим самый простой способ реализации двусторонней связи один-ко-многим. На стороне родительской сущности заводим коллекцию дочерних сущностей, и отмечаем это поле аннотацией @ОпеТоМапу. На стороне дочерней сущности заводим ссылку на держателя связи аннотацие @МапуТоОпе. Однако, если мы в этом случае проблемы будут те же, что описывались в первых абзацах этой заметки: хибернейт создаст дополнительную таблицу для связи, а внешний ключ в таблице дочерней сущности будет проигнорирован. Таким образом, мы возвращаемся к тому, с чего начинали: дополнительной таблице, се+1 запросы на добавление/удаление, обновление смежной таблицы при удалении записи из таблицы дочерней сущности. Решения могут быть те же самые: @OrderColumn и HashSet. Однако, как и в рассматриваемом в первых абзацах случае - лучшим решением с точки зрения производительности будет по-прежнему решение, базирующееся на переносе связи на сторону дочерней сущности. Чтобы перенести тело связи из смежной таблицы в таблицу дочерней сущности на этот раз нам потребуется атрибут, указывающий на имя поля, которое хранит ссылку на объект родительской сущности внутри зависимой сущности - mappedBy. (Теперь мы избавились от всех лишних запросов. Но код добавления и удаление значительно вырос. Попробуем сделать его более компактным (ссылка на статью влада) (пример с паттерном) В описанном выше случае мы пользуемся каскадами и стратегией, при которой удаление из коллекции у сущности-собственника приводит к удалению записи из таблицы зависимой сущности. Хоть это и выглядит очень удобным - нужно быть всегда максимально осторожным при использовании подобных агрессивных стратегий. Если нет большой уверенности - буду ли нужны завтра удаленные данные или нет, то лучше оставить 'ручное” удаление и добавление сущностей и ограничить случаи применения каскадов. Как видно из примера выше двунаправленная связь не уступает в производительности на добавлении/удалении однонаправленной связи один-ко-многим. Почему же тогда именно однонаправленная связь, с использованием аннотации @МапуТоОпе была названа самой лучшей по производительности? - Все дело в гибкости. Рассмотрим несколько случаев: Необходимо ограничить количество объектов дочерней сущности при организации пагинации - мы можем попытаться задать размер для коллекции на стороне сущности-собственника - в таком случае, для всего приложения будет задан фиксированный размер загрузки, и то, что в одном месте может ускорить работу приложения - в другом месте вызовет ошибку. Единственный адекватный вариант - написать jpql/sql запрос с явным LIMIT, однако, тот же запрос можно выполнить и без использования коллекции на стороне сущности-собственника. Порядок выборки: та же история, что и с лимитом. Либо мы задаем единожды порядок для всего приложения на стороне сущности-собственника, либо признаем, что такая стратегия не будет являться эффективной и гибкой, и пишем запросы. Что равнозначно по удобству с использованием односторонней @МапуТоОпе связи. ManyToMany (many-to-many) Настройка каскадов этой связи немного сложнее т.к. связь по умолчанию является двунаправленной, и; более того, в этой связи зачастую невозможно выделить собственность и собственника, т.к. границы между ними сильно размыт. Получается картина, когда обе стороны могут передавать каскадные изменения друг на друга. Важно не использовать на связи ManyToMany CascadeType.AII, т.к. последний включает в себя каскад на Remove, а этот каскад заставляет удалять хибернейт данные не только из смежной таблицы, но и дальше, из таблицы сущности, которая привязана к данной. А за этим, если к этой сущности были привязаны ещё несколько других - произойдет и их удаление из базы load graph и fetch graph Единственное отличие между этими двумя пропертями в том, что fetch graph принудительно, вне зависимости от настроек в аннотациях сущности, делает загрузку абсолютно всех пропертей ленивыми, за исключением тех пропертей, что указаны в самом графе. Load graph так же принудительно загружает все перечисленные в нем проперти, но не трогает загрузку всех остальных пропертей, оставляя поведение по умолчанию. Решение п+1 Если подытожить, то решения п+1 проблемы следующие: Самое правильное решение - использовать JOIN FETCH и jpql на выборку сущности. Данное решение не поддерживает работу с нативными запросами, но работает любым видом ОпеТоМапу/МапуТоОпе связи. Использовать FetchMode. SUB SELECT и ленивую инициализацию. В этом случае, будет произведено два запроса: первый сделает выборку основной сущности, второй запрос отправится в базу после того, как мы обратимся к ленивому полю. Запрос будет один на получение всех связанных объектов. Данное решение не работает с нативными запросами и с полями, помеченными аннотацией @МапуТоОпе BatchSize будет действовать похожим на SubSelect образом, однако, вместо принудительной загрузки сразу всех связанных объектов мы можем явно задать количество коллекций, которое надо будет загрузить. Например, если код требует загрузки 6 коллекций, a BatchSize = 3, то мы получим 2 запроса в базу. Важно заметить, что механизм использования аннотации @BatchSize будет отличаться в зависимости от связи: При односторонней связи МапуТоОпе аннотация должна располагаться на родительской сущности При односторонней OneToMany связи аннотация BatchSize может быть расположена на коллекции дочерних элементов Использовать entityGraph. Не самое изящное решение для п+1 проблемы. Графы в основном нужны, когда требуется загрузить действительно большой детальный граф, те. когда нам нужно получить очень много связанной информации из базы, и такой большой запрос следует оптимизировать. Для п+1 не самое компактное решение, но тоже работает однако такое решение не подойдет при использовании нативных запросов. В случаях, когда мы имеем только нативный запрос, у нас всегда есть два варианта решения проблемы. Первый, базирующийся на jpa спецификации - использование аннотации @SqlResultSetMapping Эта аннотация больше подходит для нестандартного маппинга сущностей, но, в некоторых случаях, с помощью неё можно избавиться от п+1 проблемы Будет работать только с МапуТоОпе. Подход выше имеет значительные ограничения по области применения. Более того, он крайне неудобен в использовании. Альтернативой ему служат нативные инструменты хибернейта для мапинга sql запросов. Этот механизм не будет работать только в случае, если мы имеем связь ОпеТоМапу через третью смежную таблицу. Небольшое пояснение: addEntity - используется для добавления корневой сущности в запрос, те. сущности, относительно которой будет мапиться вся информация, add Join - метод, который как раз-таки говорит хибернейту, что к корневой сущности нужно явно добавить одно из её загруженных полей. Метод addEntity используется два раза. Сводная таблица решений п+1 проблемы и кейсов по ней на ОпеТоМапу 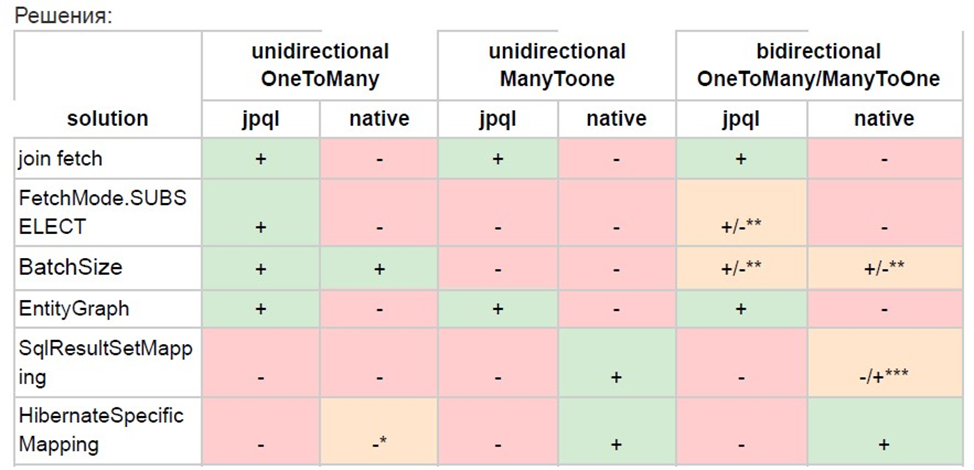 * - если не используем аннотацию JoinColumn и оставляем связанную третью таблицу ** - работает только при выборке собственника с коллекцией зависимых сущностей *** - работает только при выборке дочерней сущности с ссылкой на родительскую сущность Выводы: Лучшим вариантом решения п+1 проблемы для простых запросов (1-3 уровня вложенности связанных объектов) будет join fetch и jpql запрос. Следует придерживаться тактики, когда мы выбираем из jpql и нативного запроса jpql Если у нас имеется нативный запрос, и мы не заботимся о слабой связанности кода - то хорошим вариантом будет использование Hibernate Specific Mapping. В противном случае стоит использовать @SqlResultSetMapping В случаях, когда нам нужно получить по-настоящему много данных, и у нас jpql запрос - лучше всего использовать EntityGraph Если мы знаем примерное количество коллекций, которые будут использоваться в любом месте приложения - можно использовать @BatchSize |