сиа. Создадим долгосрочные прогнозы показателей сельского хозяйства К. Создадим долгосрочные прогнозы показателей сельского хозяйства Курской области с применением линейной регрессии
 Скачать 216.18 Kb. Скачать 216.18 Kb.
|

|
Создадим долгосрочные прогнозы показателей сельского хозяйства Курской области с применением линейной регрессии. Для анализа выберем следующие показатели: Растениеводство и животноводство. На первом этапе сделаем прогноз по показателю Растениеводство, а именно пшеница озимая и посевные площади. Данные взяты с источника Государственной службы Федеральной статистики. Таблица 1 - Статистические данные по показателю Растениеводство
Построение модели линейной регрессии, оценивание значимости модели и параметров средствами Excel (инструмент Регрессия в пакете Анализ данных): 1. Выбор команды Сервис => Анализ данных (В Excel на вкладке Данные => команда Анализ данных). 2. В диалоговом окне Анализ данных выбор инструмента Регрессия, а затем кнопка ОК. 3. В диалоговом окне Регрессия в поле Входной интервал Y ввод адреса одного диапазона ячеек, который представляет зависимую переменную. В поле Входной интервал X ввод адреса диапазона, который содержит значения независимых переменных. Таблица 2 - Оценивание значимости модели
Таблица 3 – Вывод результатов
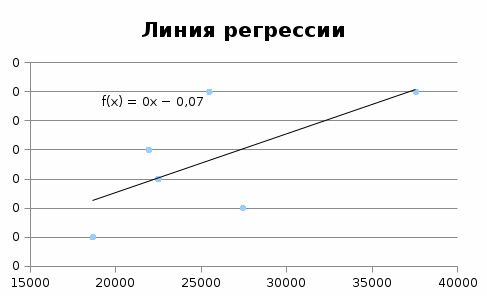 Рисунок 1- Линия регрессии Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,414 или около 41,4%. Это не приемлемый уровень качества. Зависимость менее 0,5 является плохой. Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это площади посевные, при всех остальных факторах равных нулю. Значение равно -0,074. Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества пшеницы озимой от посевных площадей. Коэффициент 1,00845E-05 считается низким показателем влияния. Спрогнозируем показатели пшеница озимая с помощью Ехсел с помощью функции Тенденция. Далее спрогнозируем показатели посевные площади с помощью уравнения у= 1,00845E-05х-0,0747 подставляя значения пшеницы озимой. Таблица 4 - Прогноз показателей растениеводство на 2023-2030 гг.
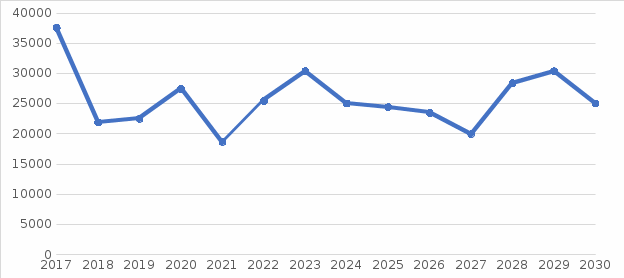 Рисунок 2 - Прогноз показателя пшеница озимая до 2030 г. 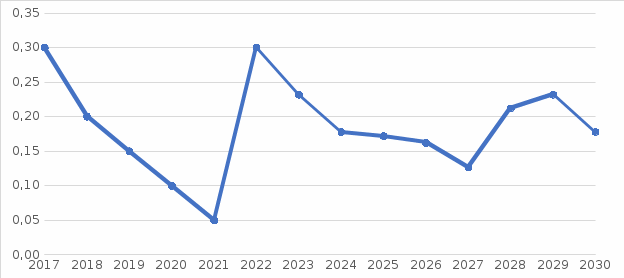 Рисунок 3 - Прогноз показателя посевные площади до 2030 г. На первом этапе сделаем прогноз по показателю Животноводство, а именно Произведено скота и птицы. Данные взяты с источника Государственной службы Федеральной статистики. Таблица 5 - Статистические данные по показателю Животноводство
Построение модели линейной регрессии, оценивание значимости модели и параметров средствами Excel (инструмент Регрессия в пакете Анализ данных): 1. Выбор команды Сервис => Анализ данных (В Excel на вкладке Данные => команда Анализ данных). 2. В диалоговом окне Анализ данных выбор инструмента Регрессия, а затем кнопка ОК. 3. В диалоговом окне Регрессия в поле Входной интервал Y ввод адреса одного диапазона ячеек, который представляет зависимую переменную. В поле Входной интервал X ввод адреса диапазона, который содержит значения независимых переменных. Таблица 6 - Оценивание значимости модели
Таблица 7 – Вывод результатов
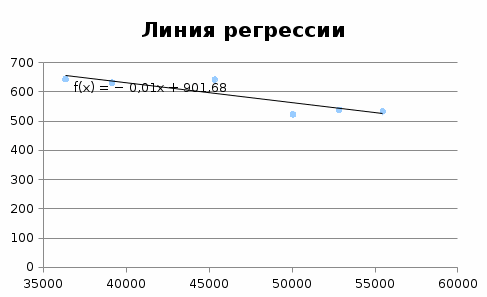 Рисунок 4- Линия регрессии Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,76 или около 76%. Это приемлемый уровень качества. Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это произведено скота и птицы, при всех остальных факторах равных нулю. Значение равно 901,68. Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества пшеницы озимой от посевных площадей. Коэффициент -0,006794848 считается низким показателем влияния. Спрогнозируем показатели свекла сахарная с помощью Ехсел с помощью функции Тенденция. Далее спрогнозируем показатели посевные площади с помощью уравнения у= -0,0068х+901,68 подставляя значения свеклы сахарной. Таблица 8 - Прогноз показателей животноводство на 2023-2030 гг.
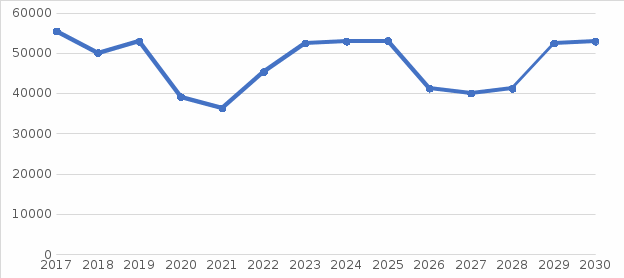 Рисунок 5 - Прогноз показателя свекла сахарная до 2030 г. 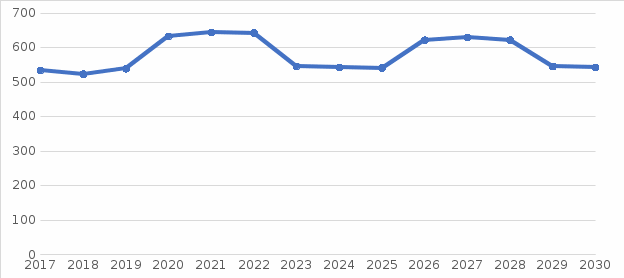 Рисунок 6 - Прогноз показателя произведено скота и птицы до 2030 г. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||