Статья на Хабре Используем nftables в Red Hat Enterprise Linux 8 Технические требования
 Скачать 0.63 Mb. Скачать 0.63 Mb.
|

|
Подготовка стенда Средствами системы виртуализации создадим отдельную виртуальную сеть (VMnet), которую назовем «Custom11». Ранее созданный шаблон виртуальной машины растиражируем в 5 отдельных экземпляров: FW, User1, User2, Server1, Server2. К виртуальной машине FW добавим второй виртуальный сетевой адаптер, который соединим с сетью «Custom11». Ее первый сетевой адаптер должен быть подключен к виртуальной сети «NAT». Сетевые адаптеры машин User1 и User2 подключим к «Custom11», а сетевые адаптеры Server1, Server2 подключим к «NAT». Редактируя файлы /etc/network/interfaces, назначим всем виртуальным машинам статические IP-адреса, а также шлюзы (GW) и DNS-сервера в соответствии со схемой лабораторного стенда. В качестве шлюзов по умолчанию для Host1 и Host2 будет 192.168.0.40, для Server1 и Server2 172.30.0.40, а для FW 172.30.0.2 На виртуальной машине FW активируем функции маршрутизации IPv4 трафика. Для этого в файле /etc/sysctl.conf раскомментируем строку net.ipv4.ip_forward=1. Сделать это можно с помощью заклинания: sed '/net.ipv4.ip_forward=1/s/^#//' -i /etc/sysctl.conf Проверим стенд. Host1 и Host2 должны иметь возможность «пингануть» Server1, Server2 и FW и наоборот. FW должен иметь возможность «пингануть» любой из узлов сети. Ход выполнения работы Полную настройку брандмауэра мы уже рассматривали в предыдущей задаче. Поэтому здесь мы направим внимание на конфигурационный файл /etc/nftables.conf. Причем мы также опустим вопросы защиты самого FW, поскольку они будут точно такими же, как и в предыдущей задаче, и сосредоточимся лишь на фильтрации транзитного трафика. Анализируя матрицу доступа можно предположить, что User1 является рядовым работником, и ему требуется доступ по http ко всем серверам. Назовем такой доступ ролью «all_web». Для User2 требуется предоставить доступ ко всем серверам по SSH, вероятно он системный администратор. Обозначим такой доступ ролью «all_ssh». Обоим пользователям требуется доступ к DNS-серверу — это будет роль «DNS». Наиболее простым способом создать в nftables ролевую систему разграничения доступа будет применение правил, где в качестве аргументов используются списки (sets), содержащие конкретные параметры предоставления доступа. В нашем случае для каждой роли нужно создать два списка: наименование роли_users и наименование роли_servers. В первый список будут добавляться IP-адреса пользователей, во второй — IP-адреса серверов, а также протоколы и доступные порты. После создания списков для каждой роли создадим правило, разрешающее установку соединений ip saddr @название роли_users ip daddr. meta l4proto. th dport @название роли_servers accept. Трафик по инициированным соединения, как обычно, будет проходить с помощью правила ct state established,related accept. Итоговый конфигурационный файл (/etc/nftables.conf), решающий поставленную задачу будет выглядеть следующим образом: #!/usr/sbin/nft -f flush ruleset table ip firewall { set all_web_users { type ipv4_addr flags interval elements = { 192.168.0.101 } } set all_web_servers { type ipv4_addr . inet_proto . inet_service flags interval elements = { 172.30.0.101-172.30.0.102 . tcp . 80 } } set all_ssh_users { type ipv4_addr flags interval elements = { 192.168.0.102 } } set all_ssh_servers { type ipv4_addr . inet_proto . inet_service flags interval elements = { 172.30.0.101-172.30.0.102 . tcp . 22 } } set DNS_users { type ipv4_addr flags interval elements = { 192.168.0.101, 192.168.0.102 } } set DNS_servers { type ipv4_addr . inet_proto . inet_service flags interval elements = { 172.30.0.2 . udp . 53 } } chain fw_forward { type filter hook forward priority filter; policy drop; ct state established,related accept ip saddr @all_web_users ip daddr . meta l4proto . th dport @all_web_servers accept ip saddr @all_ssh_users ip daddr . meta l4proto . th dport @all_ssh_servers accept ip saddr @DNS_users ip daddr . meta l4proto . th dport @DNS_servers accept } } Примечание. После настройки всех правил вы столкнетесь с одной проблемой: DNS на User1 и User2 работать не будет. Это не баг, это методическая фича. Проблема в том, что DNS-сервер работает на виртуальном маршрутизаторе, который ничего не знает о пользовательской сети 192.168.0.0/24, из-за этого ответы на запросы не доходят до адресатов. Этой проблемой хотелось показать реальные сложности, возникающие при сегментации уже работающих сетей с помощью разделения их на IP-подсети. На предприятиях со сложившейся инфраструктурой, но низким уровнем зрелости IT внедрить подобные меры защиты крайне сложно, а учитывая user resistance, практически невозможно. Но проблема все же имеет решение, и мы поговорим о нем прямо сейчас. Типовой сценарий: сегментирование локальной сети коммутатором с функцией брандмауэра Данный подход к межсетевому экранированию имеет множество названий: коммутатор с функцией брандмауэра, «stealth firewall», «transparent firewall» и др. Суть, однако, заключается в том, что сегментируемая сеть сохраняет свою IP-адресацию, а разделение происходит путем установки коммутатора в разрыв между будущими сегментами. Причем коммутатор фильтрует трафик как обычный межсетевой экран — на основании данных со всех инкапсулированных протоколов (L2, L3, L4, L7), а не только данных с протоколов канального уровня (L2), как в случае с обычным коммутатором. Сетевые интерфейсы коммутатора не имеют IP-адресов (за исключением тех, что используются для управления). Соответственно, данное устройство не видимо для других сетевых узлов (за исключением случаев, когда используются специфические протоколы, например OSPF). Поэтому коммутатор с функцией брандмауэра часто называют прозрачный межсетевой экран — stealth firewall. Применение фильтрующих коммутаторов имеет несколько неоспоримых преимуществ: Внедрение устройства не требует выделения IP-подсетей и, как следствие, перенастройки таблиц маршрутизации роутеров и сетевых стеков узлов. Устройство очень просто внедрить и очень просто изъять из сети в случае его поломки. Основной недостаток данной технологии, как ни странно, является прямым следствием ее основного достоинства: сегментирование сети без разделения ее на IP-подсети не позволяет ограничивать широковещательный трафик, что негативным образом сказывается на производительности сетей и усиливает негативные последствия от атак типа широковещательный шторм (broadcast flood), отравления кэша ARP (ARP-poisoning), подмены DHCP (Rogue DHCP Server) и других. Практическая работа: провести сегментирование сети без разделения ее на IP-подсети Описание стенда Используемый лабораторный стенд (Рисунок 5) очень похож на предыдущий, за исключением того, что все машины здесь находятся в одной IP-подсети. Для того, чтобы машины UserX и ServerX не могли связаться между собой напрямую, а использовали для связи FW, их разделили по виртуальным сетям «Custom11» и «NAT». 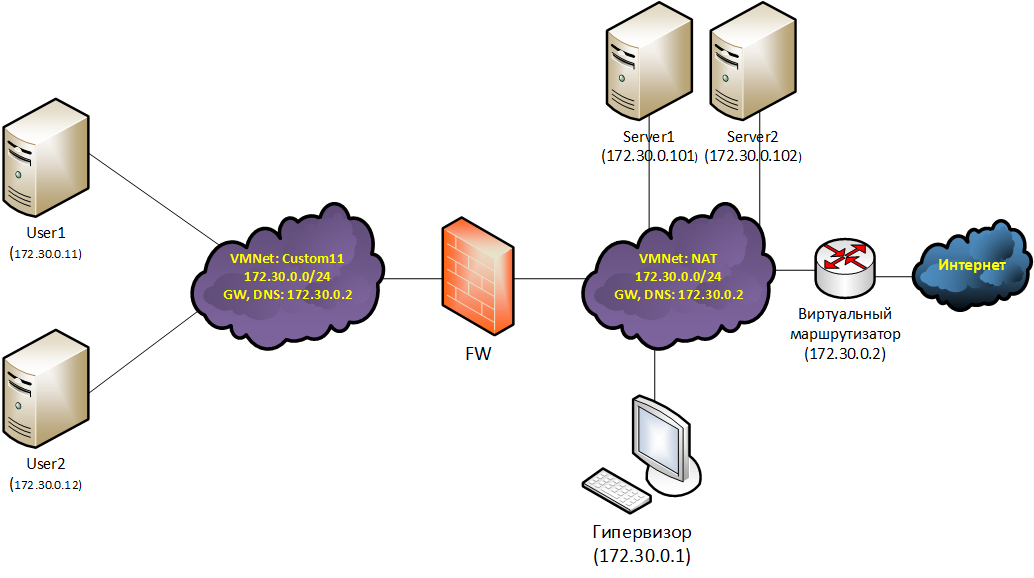 (Рисунок 5) Задача Настроить разграничение трафика в соответствии с матрицей доступа из предыдущей задачи. Подготовка стенда Внося изменения в файлы /etc/network/interfaces, назначим статические адреса всем узлам сети. Для организации работы FW в режиме коммутатора установим на него пакет bridge-utils: pt install bridge-utils Затем на узле FW сконфигурируем коммутатор, объединив в мост (bridge) все сетевые порты. Для этого файл /etc/network/interfaces заполним следующим образом: auto lo iface lo inet loopback iface ens33 inet static iface ens36 inet static auto br0 iface br0 inet manual bridge_ports ens33 ens36 Проверим стенд. Все узлы, кроме FW, должны «пинговаться» между собой. DNS, кстати, тоже должен работать. Ход выполнения работы Как и в предыдущей задаче рассмотрим только файл с правилами межсетевого экранирования /etc/nftables.conf. Скорее всего при беглом осмотре вы даже не заметите в нем различий по сравнению с таким же файлом из предыдущей задачи. #!/usr/sbin/nft -f flush ruleset table bridge firewall { set all_web_users { type ipv4_addr flags interval elements = { 172.30.0.11 } } set all_web_servers { type ipv4_addr . inet_proto . inet_service flags interval elements = { 172.30.0.101-172.30.0.102 . tcp . 80 } } set all_ssh_users { type ipv4_addr flags interval elements = { 172.30.0.12 } } set all_ssh_servers { type ipv4_addr . inet_proto . inet_service flags interval elements = { 172.30.0.101-172.30.0.102 . tcp . 22 } } set DNS_users { type ipv4_addr flags interval elements = { 172.30.0.11, 172.30.0.12 } } set DNS_servers { type ipv4_addr . inet_proto . inet_service flags interval elements = { 172.30.0.2 . udp . 53 } } chain fw_forward { type filter hook forward priority filter; policy drop ether type arp accept ct state established,related accept ip saddr @all_web_users ip daddr . meta l4proto . th dport @all_web_servers accept ip saddr @all_ssh_users ip daddr . meta l4proto . th dport @all_ssh_servers accept ip saddr @DNS_users ip daddr . meta l4proto . th dport @DNS_servers accept } } Основные отличия в том, что тип таблицы firewall изменился с ip на bridge, поменялись адреса в списках *_users (так как изменились соответствующие адреса машин), и к правилам фильтрации мы добавили разрешение прохождения ARP трафика. Проект OneButtonFirewall Можно ли сделать межсетевой экран, не требующий конфигурирования? Если можно, то что он будет уметь? Давайте разбираться. Мы с вами рассмотрели несколько схем разграничения трафика. Есть ли среди них та, что не требует конфигурирования, то есть указания IP-адресов или портов, на основании которых производится фильтрация трафика? Конечно, есть, и эта схема первая в списке. Теперь возникает второй вопрос: рассмотренная схема относится к защите рабочих станций, как с ее помощью построить межсетевой экран для защиты сегмента сети? Тут тоже нет ничего сложного. Один сегмент сети, подключенный к брандмауэру, будем считать внутренним (защищаемым), а второй внешним (от которого защищаем). Тогда правила фильтрации преобразуются в следующие: Запрещен транзит трафика из внешнего сегмента во внутренний, кроме того, что относится к уже установленным соединениям. Разрешен транзит любого трафика из внутреннего сегмента во внешний сегмент. Теперь надо решить, как отличить внутренний сегмент от внешнего, и как сделать, чтобы при внедрении межсетевого экрана не требовалось переконфигурировать узлы сети. Отличать сегменты можно по сетевым интерфейсам межсетевого экрана, к которым они подключены, а ответом на второй вопрос будет использование технологии фильтрации с помощью коммутатора. В итоге получаем своеобразный IP-диод, который в зависимости от подключения сегментов сети к своим интерфейсам пропускает соединения только в одну сторону. Стоит сегменты переподключить к другим портам, и направление сетевых соединений изменится на противоположное. Осталась одна проблема – широковещательный трафик. Раньше, когда мы рассматривали фильтрацию с помощью коммутатора, мы не обращали на него внимание, и по факту он был запрещен, кроме разве что ARP. Это, конечно, безопасно, но для универсального межсетевого экрана не подходит, поскольку ломает работу множества протоколов, базирующихся на широковещательных посылках, и первыми такими протоколами будут протоколы ОС Windows, отвечающие за отрисовку сетевого окружения. В результате тетенька бухгалтерша, сидящая за подобным брандмауэром, издаст злобный писк, что пропали все ее сетевые папки, и что вы вообще бесполезный вредитель. Нам такого не надо, поэтому, скрипя сердцем, разрешим транзит всего широковещательного трафика. Ну, вроде бы все учли… ан нет. В ходе эксплуатации OneButtonFirewall всплыла проблема, откуда не ждали – получение IP-адреса от DHCP-сервера, находящегося во внешнем сегменте. ОС Windows получает IP-адреса по DHCP сугубо на широковещательных рассылках, и текущих правил фильтрации ей полностью хватает. Linux же идет своим путем. При получении адреса на конечном этапе DHCP-сервер посылает клиенту адресный (unicast) пакет по UDP 68, и, чтобы тот достиг адресата, в правилах фильтрации нужно сделать соответствующее исключение. Практическая работа: защитить сегмент сети с помощью межсетевого экрана, построенного по технологии OneButtonFirewall Описание стенда Давайте теперь соберем лабораторный стенд (Рисунок 6) и отработаем на нем наши идеи. Тут мы даже немного усложним задачу. У FW будет не два интерфейса: один внутренний и один внешний, а четыре: один внешний и три внутренних. Все узлы, подключенные к внутренним интерфейсам, будем считать внутренним сегментом и фильтровать трафик между этими узлами не будем. Как вы увидите дальше, количество внутренних интерфейсов не имеет значения, но внешний может быть только один. 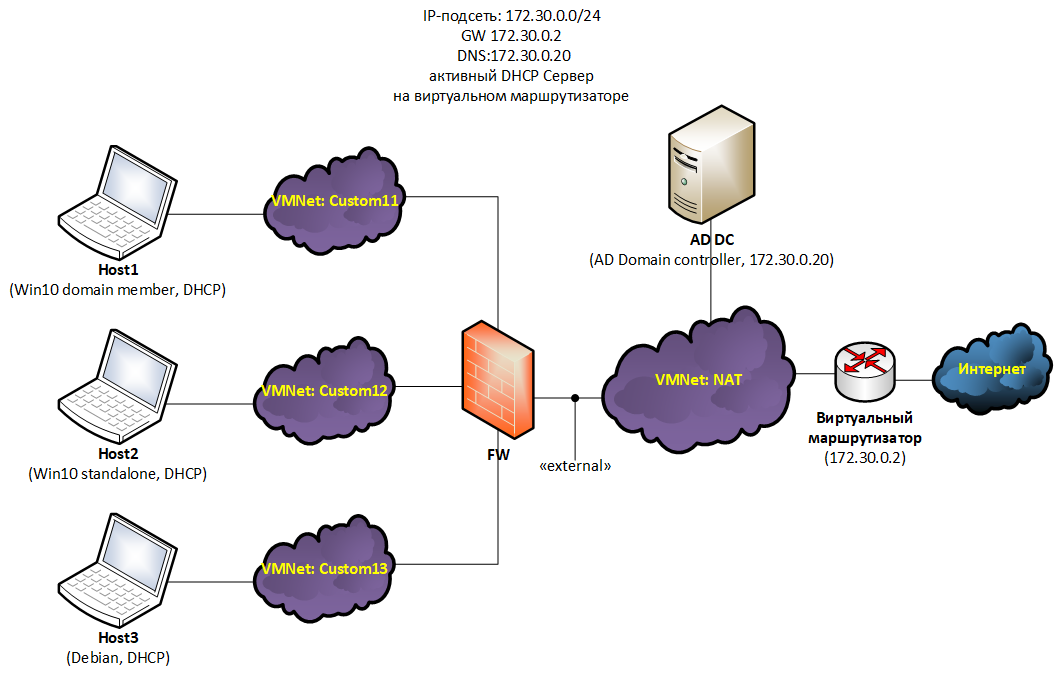 Рисунок 6 В этом примере для наглядности мы моделируем классическую корпоративную сеть на базе ОС Windows. Host1 – это Windows 10, подключенный к домену Active Directory, контроллер которого (ADDC) расположен во внешней сети. Host2 – Windows 10, не подключенная к домену, а Host3 – наша шаблонная машина на базе Debian. Все HostX получают IP-адреса по DHCP от виртуального маршрутизатора. Для моделирования наших идей с помощью средств виртуализации каждый узел внутренней сети подключим через отдельную виртуальную сеть к FW. Как и прошлый раз мы делаем это для того, чтобы весь трафик между узлами HostX и узлами внешней сети шел через FW. Задача Защитить узлы HosX от несанкционированных подключений. Подготовка стенда На узле FW установим 4 сетевых интерфейса. Для наглядности с помощью средств виртуализации изменим на них MAC-адреса (Рисунок 7): 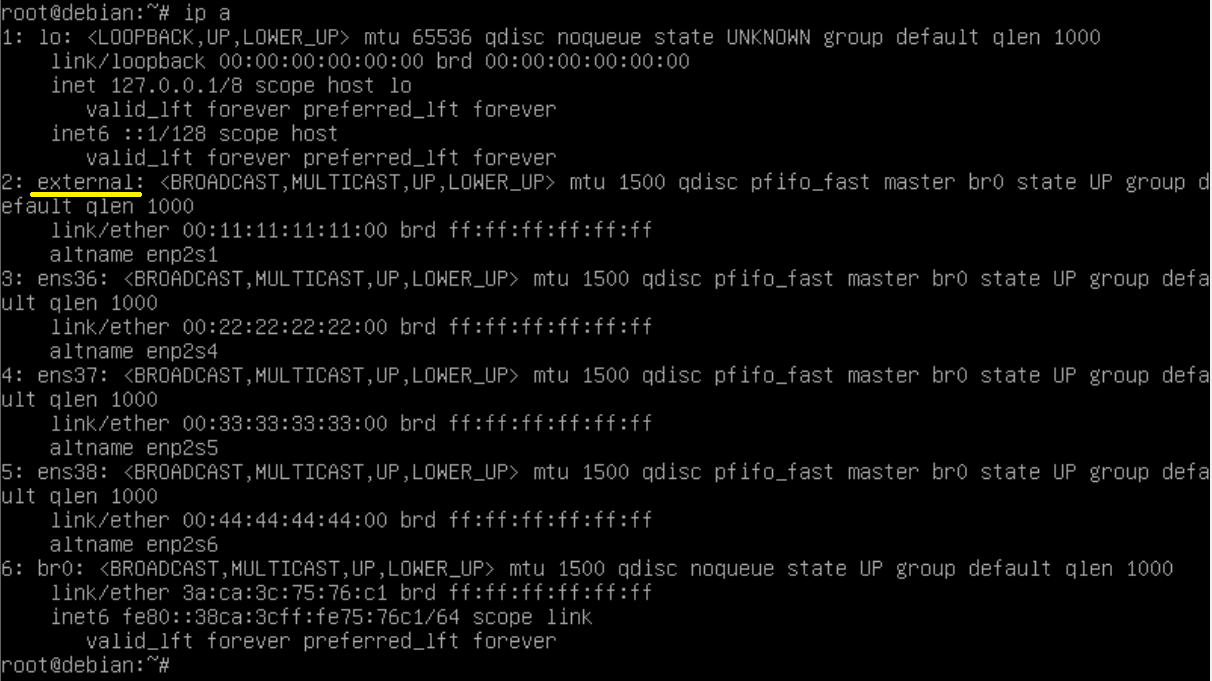 Рисунок 7 Один из интерфейсов с MAC-адресом 00:11:11:11:11:00, подключенный к «NAT», переименуем в «external» (Рисунок 7). Для этого создадим файл /etc/systemd/network/10-set-external-name.link и заполним его следующим содержанием: # /etc/systemd/network/10-set-internal1-name.link [Match] MACAddress=00:11:11:11:11:00 [Link] Name=external Как и при решении прошлой задачи установим на узел FW пакет bridge-utils. Сделаем из FW коммутатор. Для этого в файл /etc/network/interfaces запишем следующее содержание:
|
