Управление данными, синергия 3 семестр, шпаргалка, краткое содержание учебника. Управление данными 3 сем. Управление данными
 Скачать 0.55 Mb. Скачать 0.55 Mb.
|

|
Управление транзакциями - способность управлять различными операциями над данными, которые выполняются внутри реляционной СУБД. Команды: COMMIT - для сохранения изменений. ROLLBACK - для отмены изменений. SAVEPOINT - для установки особых точек возврата ()куда в дальнейшем можеть быть произведен откат, отката всей транзакции не происходит): SAVEPOINT имя_точки_сохранения Для отмены действия группы транзакций, ограниченных точками сохранения: ROLLBACK TO имя_точки_сохранения Управление транзакциями в среде MS SQL Server. Виды определения транзакций: Явное. Автоматическое (каждая команда рассматривается как отдельная транзакция). Команда для установки режима автоматического определения транзакций: SET IMPLICIT_TRANSACTIONS OFF Подразумеваемое (неявное). Команда: SET IMPLICIT_TRANSACTIONS ON Явные транзакции. Требуют, чтобы пользователь указал начало и конец транзакции, используя команды: Начало транзакции - в журнале транзакций фиксир. первонач. значения изменяемых данных и момент начала транзакции. BEGIN TRAN[SACTION] [имя_транзакции | @имя_переменной_транзакции [WITH MARK [‘описание_транзакции’]]] Конец транзакции - фиксирует все изменения, сделанные в транзакции, в журнале помечается, что изменения зафиксированы и транзакция завершена. COMMIT [TRAN[SACTION] [имя_транзакции | @имя_переменной_транзакции]] Создание внутри транзакции точки сохранения. SAVE TRAN[SACTION] {имя_точки_сохранеия | @имя_переменной_точки_сохранения} Прерывание транзакции. ROLLBACK [TRAN[SACTION] [имя_транзакции | @имя_переменной_транзакции | имя_точки_сохранения |@имя_переменной_точки_сохранения]] Функция @@TRANCOUNT возвращает количество активных транзакций. Функция @@NESTLEVEL возвращает уровень вложенности транзакций. Вложенные транзакции - выполнение которых инициируется из тела уже активной транзакции. Только когда все транзакции на всех уровнях завершены успешно, происходит фиксация всех сделанных изменений в результате успешного завершения транзакции верхнего уровня. Блокировки в среде MS SQL Server Управление блокировками. Работу по установке, снятию и разрешению конфликтов выполняет менеджер блокировки. Типы блокировок: коллективные блокировки, блокировка обновления, монопольная блокировка, блокировка массивного обновления, блокировки намерений, блокировка диапазона ключей, блокировка схемы (метаданных, описывающих структуру объекта). “Мертвые” блокировки (тупиковые) характерны для многопользовательских систем. Возникает, когда две транзакции блокируют два блока данных и для завершения любой из них нужен доступ к данным, заблокированным ранее другой транзакцией. Уровни изоляции SQL Server. Уровень изоляции определяет степень независимости транзакций друг от друга. Команда установления уровня изоляции: SET TRANSACTION ISOLATION LEVEL { READ COMMITTED | READ UNCOMMITTED | REPEATABLE READ | SERIALIZABLE } READ UNCOMMITED - незавершенное чтение, или допустимо черновое чтение. Низший уровень изоляции 0. Команда: SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED READ COMMITED - завершенное чтение, при котором отсутствует черновое, “грязное” чтение. Установлен по умолчанию. Команда: SET TRANSACTION ISOLATION LEVEL READ COMMITTED REPEATABLE READ - повторяющееся чтение. Возможно возникновение фантомов. Команда: SET TRANSACTION ISOLATION LEVEL REPEATABLE READ SERIALIZABLE - сериализуемость. Чтение запрещено до завершения транзакции. Макс уровень изоляции. Команда: SET TRANSACTION ISOLATION LEVEL SERIALIZABLE В каждый момент времени возможен только один уровень изоляции. Тема 6. Информационные хранилища и склады данных Хранилища данных. Хранилище данных - предметно-ориентированный, интегрированный, привязанный ко времени и неизменяемый набор данных, предназначенный для поддержки принятия решений. OLAP - для описания модели представления данных и технологии их обработки в хранилищах данных. Применяется многомерное представление агрегированных данных. OLAP и OLTP. Характеристики и отличия
Правила Кодда для OLAP систем. Правила: 1. Концептуальное многомерное представление. 2. Прозрачность. 3. Доступность. 4. Постоянная производительность при разработке отсчетов. 5. Клиент-серверная архитектура. 6. Общая многомерность. 7. Динамическое управление разреженными матрицами. 8. Многопользовательская поддержка. 9. Неограниченные перекрестные операции. 10. Интуитивная манипуляция данными. 11. Гибкие возможности получения отсчетов. 12. Неограниченная размерность и число уровней агрегации. Основные элементы и операции OLAP. В основе лежит понятие гиперкуба или многомерного куба данных, в ячейках которого хранятся анализируемые данные. Факт - числовая величина, которая располагается в ячейках гиперкуба. Измерение - множество объектов одного или нескольких типов, организованных в виде иерархической структуры и обеспечивающих информационный контекст числового показателя. Ячейка - атомарная структура куба, соответствующая полному набору конкретных значений измерений. Иерархия - группировка объектов одного измерения в объекты более высокого уровня. Базовые операции: поворот, проекция (значения в ячейках, лежащих на оси проекции, суммируются по нек. предопред. закону), раскрытие (drill-down - значение измерения заменяется совок. значений из след. уровня иерархии измерения), свертка (roll-up\drill-up), сечение (slice-and-dice). Типы OLAP. Способы хранения данных: MOLAP - детальные и агрегированные данные хранятся в многомерной БД. ROLAP - позволяют представлять данные, хранимые в классической реляционной базе, в многомерное форме или в плоских локальных таблицах на файл-сервере, обеспечивая преобразование информации в многомерную модель через промежуточный слой метаданных. HOLAP - детальные данные остаются в той же реляционной БД, где они изначально находились, агрегатные данные хранятся в многомерной БД. Схема звезда - схема реляционной БД, служащая для поддержки многомерного представления содержащихся в ней данных. Денормализованная таблица фактов и денормализованные таблицы измерений. Схема снежинка - схема реляционной БД, служащая для поддержки многомерного представления содержащихся в ней данных, явл. разновид. схемы типа звезда. Денормализованная таблица фактов и нормализованные таблицы измерений. Склады данных. Склад данных - логически интегрированный источник данных для систем поддержки принятия решений (DSS) и информационных систем руководителя (EIS). Принципы: предметная ориентация, средства интеграции, постоянство данных, хронологизм данных. Архитектуры хранилищ данных Централизованное хранилище данных с ETL. ETL - средства извлечения, преобразования и загрузки данных. Средства ETL извлекают данные из источников, во взаимодействии со средствами ведения метаданных и нормативно справочной информации (НСИ) преобразуют их к требуемым форматам и загружают в репозиторий данных. 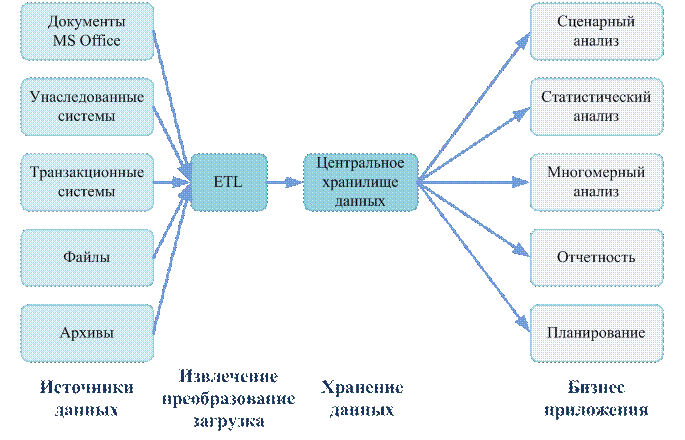 Централизованное хранилище данных с ELT. ELT - средства извлечения, преобразования и загрузки данных. 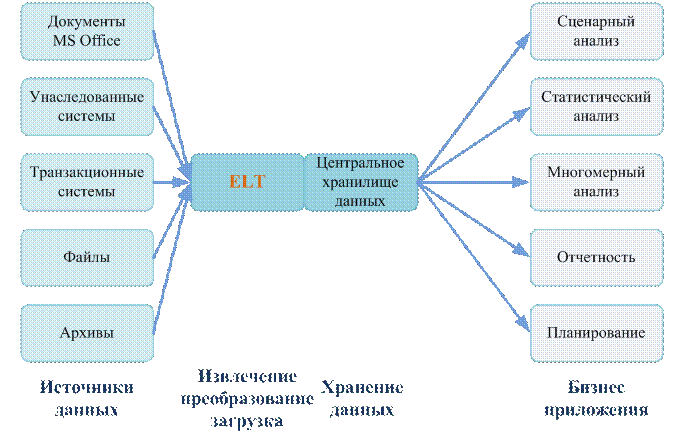 Централизованное ХД с ОСД. ОСД - оперативный склад данных (для того, чтобы сократить время задержки между поступлением информации из ETL и аналитическими системами). Данные из ОСД предназначены для принятия тактических решений.  Расширенная модель ХД с витринами данных. Витрины данных содержат информацию, предназначенную для выделенной группы пользователей.  Централизованная ETL с параллельными хранилищами и витринами данных. ETL является центром, вокруг которого строится вся архитектура КХД (корпоративное хранилище данных). 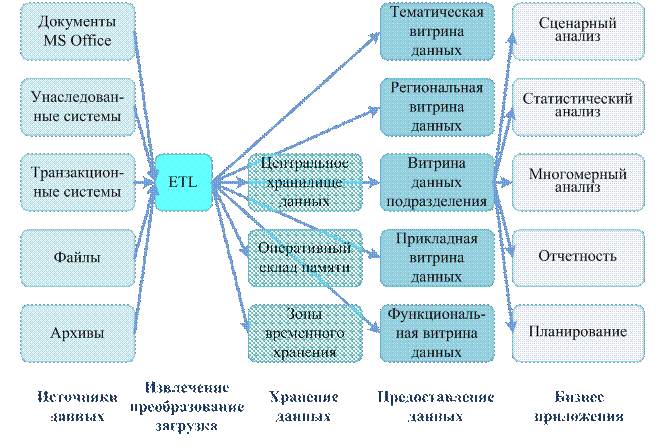 Хранилище с накоплением данных в витринах.  Хранилище данных с интеграционной шиной. Интеграционная шина лежит в основе СОА (сервис-ориентированная архитектура), предназначена для интеграции веб-сервисов и приложений.  Рекомендованная архитектура КХД. Полные, точные, воспроизводимые данные, защищенность и надежность хранения данных, доступность данных в необходимом объеме, единое смысловое пространство, отсутствие конфликтов в кодировках данных в системах источниках. 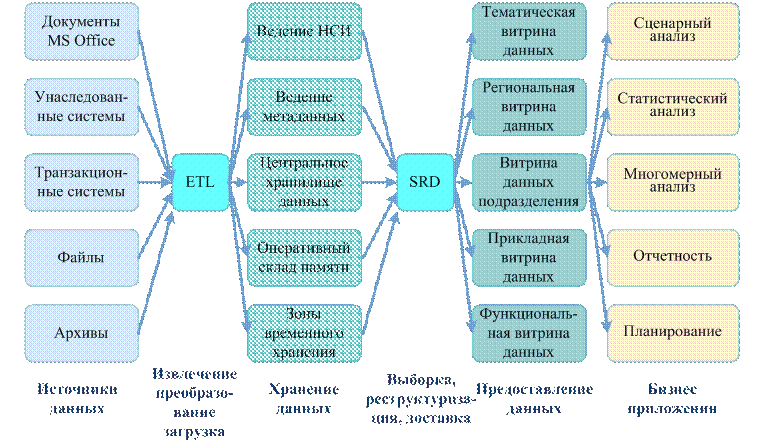 |