Mpi реализация метода гауса. mpi_отчет3. Уразова Диляра Зуфаровна
 Скачать 5.57 Mb. Скачать 5.57 Mb.
|

|
Уразова Диляра Зуфаровна urazova.99@inbox.ru Реализация программы OpenMP В программе используются три основные функции: Функция init(), инициализирующая матрицу; Функция relax(), обновляющая состояние матрицы; Функция verify(), подсчитывающая контрольную сумму матрицы. Распараллелили функцию relax(). Она состоит из двух циклов, далее идет условия зависимости столбцов и строчек. Так как нет зависимости по данным, распараллеливание происходит двух циклов. Таблица 1. Результат работы программы при помощи OpenMP
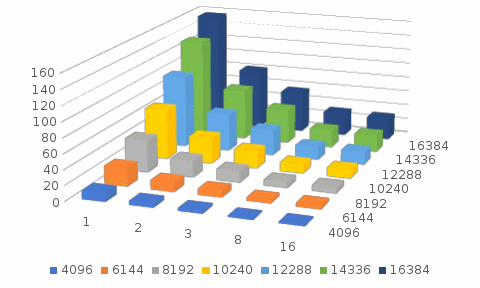 Рисунок 1. Графическое представление результата метода Реализация программы MPI (первый способ) В начале заполняем матрицу с добавлением теневых граней (указаны зеленым цветом); В каждую вторую теневую грань каждого процесса записываются значения первого столбца поэлементно последующего процесса (стрелочки фиолетового цвета). А на последнем процессе мы не принимаем. На всех процессах считаем построчно. При этом поэлементно отправляем (голубенькая стрелочка). Второй процесс на примере у нас последний, поэтому он ничего не отправляет. Текст программы представлен в приложении Б. 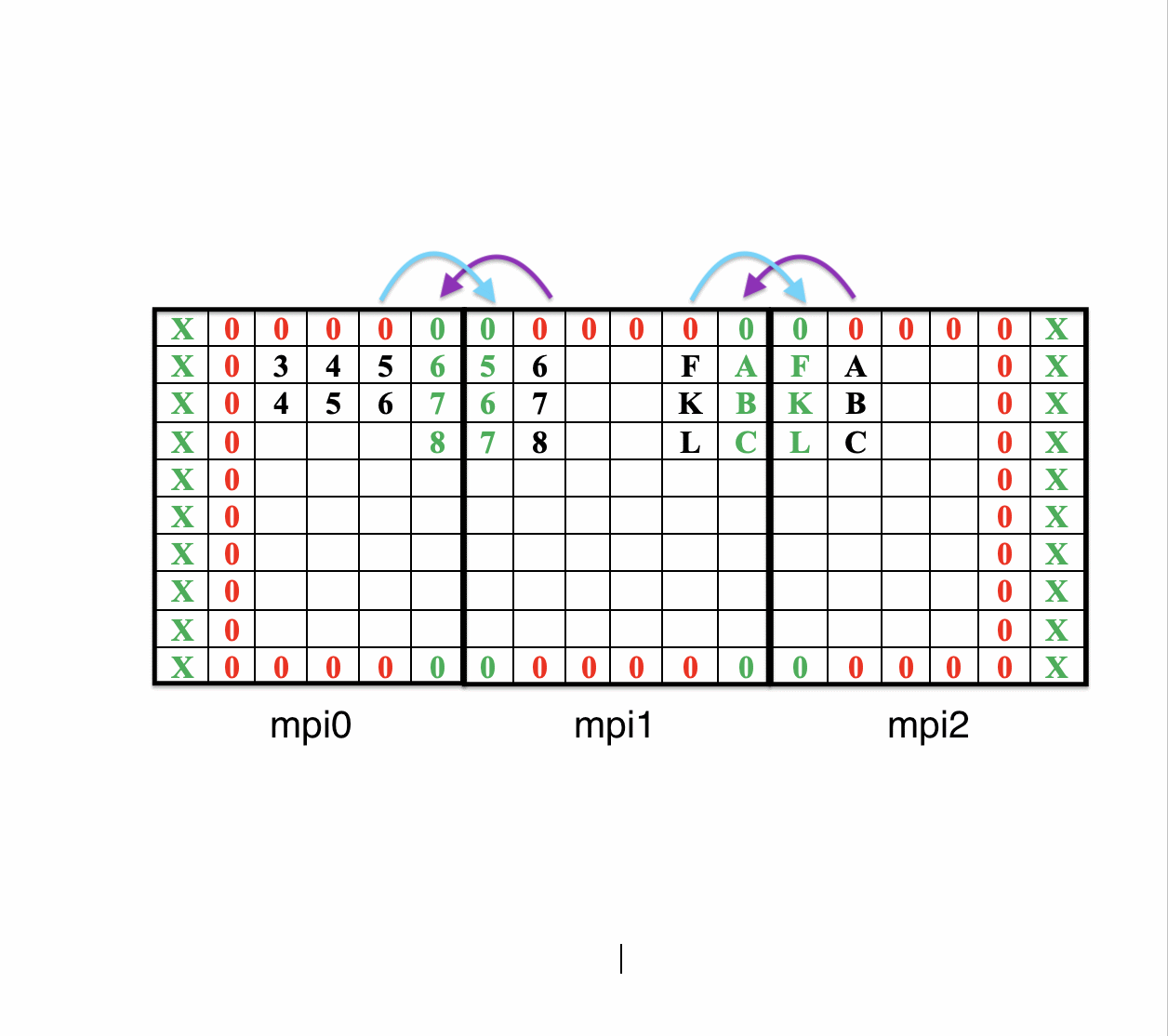 Рисунок 1. Реализация программы при помощи MPI первым способом Таблица 2. Результат работы программы при помощи MPI
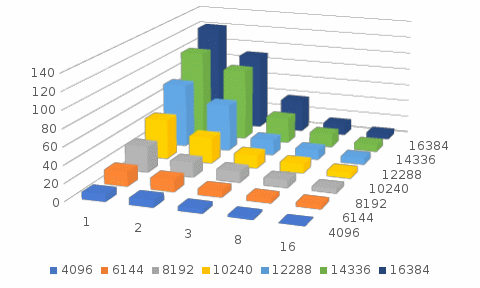 Рисунок 2. Графическое представление результата метода Реализация программы MPI (второй вариант) В начале заполняем матрицу с добавлением теневых граней (указаны зеленым цветом); В каждую вторую теневую грань каждого процесса записываются значения первого последующего процесса (стрелочки фиолетового цвета). А на последнем процессе мы не принимаем. Далее на всех процессах считаем оранжевые значения. При этом пересылаем значения, взятые в синий цвет (длина столбца = ff), после подсчёта оранжевых значений. Далее повторяем второй пункт. Далее на всех процессах считаем фиолетовые значения. При этом пересылаем значения, взятые в синий цвет, после подсчёта этих значений. Но надо учитывать, что на нулевом процессе мы не считаем значения в первом столбце (нумерация с нуля). А на последнем процессе не меняем значения перед последней теневой грани. Текст программы представлен в приложении В.  Рисунок 2. Реализация программы при помощи MPI вторым способом Таблица 3. Результат работы программы при помощи MPI ff = 16
 Рисунок 3. Графическое представление результата метода Приложение A. Текст программы OpenMP #include #include #include #include #include "omp.h" #define Max(a,b) ((a)>(b)?(a):(b)) void init(int); void printer(int); void verify(int, int); double maxeps = 0.1e-7; double **A; double eps; double w = 0.5; int size, rank; using std::cout; using std::endl; int main(int argc, char **argv) { int itmax = atoi(argv[1]); int N = atoi(argv[2]); int thr = atoi(argv[3]); //cout << "asdf"; init(N); //cout << "asdf"; //int local_row = N / size; double time, st, fn; for (int it = 0; it < itmax; it++) { eps = 0.0; double b = 0.0; st = omp_get_wtime(); #pragma omp parallel shared(A) reduction(max:eps) num_threads(thr) { #pragma omp for for (int i = 1; i < N - 1; i++) for (int j = 1; j < N - 1; j++) if ((i + j) % 2 == 1) { double b; b = w*((A[i - 1][j] + A[i + 1][j] + A[i][j - 1] + A[i][j + 1]) / 4. - A[i][j]); eps = Max(fabs(b), eps); A[i][j] = A[i][j] + b; } #pragma omp for for (int i = 1; i < N - 1; i++) for (int j = 1; j < N - 1; j++) if ((i + j) % 2 == 0) { double b; b = w*((A[i - 1][j] + A[i + 1][j] + A[i][j - 1] + A[i][j + 1]) / 4. - A[i][j]); eps = Max(fabs(b), eps); A[i][j] = A[i][j] + b; } } fn = omp_get_wtime(); //printer(N); if (rank == 0) { cout << "it = " << it << " eps = " << eps << endl; time += fn - st; } if (eps < maxeps) break; } if (rank == 0) cout << "time = " << time << endl; //verify(N, local_row); return 0; } void init(int N) { //cout << "asdf"; A = new double*[N]; for (int i = 0; i < N; i++) A[i] = new double[N]; //cout << "asdf"; for (int i = 0; i < N; i++) for (int j = 0; j < N; j++) { A[i][j] = 1.0 + i + j; } for (int i = 0; i < N; i++) { A[0][i] = 0.0; A[N - 1][i] = 0.0; A[i][0] = 0.0; A[i][N - 1] = 0.0; } } void printer(int N) { for (int i = 0; i < N; i++) { for (int j = 0; j < N; j++) { cout << A[i][j] << " "; } cout << endl; } } void verify(int N, int local_row) { double sum = 0; for (int i = 0; i < N; i++) for (int j = 0; j < local_row; j++) sum += A[i][j]; if (rank == 0) cout << "sum = " << sum << endl; } Приложение Б. Текст программы MPI (первый способ) #include #include #include #include #include "mpi.h" #define Max(a,b) ((a)>(b)?(a):(b)) void init(int); void printer(int, int); void verify(int, int); double maxeps = 0.1e-7; double **A; double eps; double w = 0.5; int size, rank; using std::cout; using std::endl; int main(int argc, char **argv) { MPI_Init(&argc, &argv); //инцилизация мпиай int itmax = atoi(argv[1]); //строку в число int N = atoi(argv[2]); MPI_Comm_size(MPI_COMM_WORLD, &size); //в аргумент size возращает число пар процессоров (ком-ры для всех процессов) MPI_Comm_rank(MPI_COMM_WORLD, &rank); //в аргументе rank возвращает номер процесса среди всех процессов (диапозон: (0, size-1) init(N); //вызывается функция с аргументом N (размер матрицы) MPI_Request rreq, sreq; MPI_Status status; //структура всех процессоров, парметры элементов int local_row = N / size; //делим строки между процессами double time = 0.0, st, fn; //задаем и создаем переменные //printer(N, local_row); for (int it = 0; it < itmax; it++) { eps = 0.0; st = MPI_Wtime(); //начало время работы программы double *tmp = NULL; //создаются два нулевых одномерных массива double *tmp1 = NULL; tmp = new double[N]; //длины N tmp1 = new double[N]; for (int i = 0; i < N; i++) //заполняем столбец номер 1 (простр переписываем первый столбец) tmp[i] = A[i][1]; if (rank != 0) //номер процесса не равен 0, тогда отправляем (нам, чтобы посчитать первый блок(0 процесс) до конца, необходимо знать первый столбец второго блока(первый процесс)) MPI_Isend(&tmp[0], N, MPI_DOUBLE, rank - 1, 123, MPI_COMM_WORLD, &sreq); //отправка от одного процесса к другому (начало посылки с чего начинается, число передаваемых элементов, тип передаваемые элементов, номер процесса получателя(чем мы находимся сейчас), метка сообщения(код), на все процессы, параметры) if (rank != size - 1) //номер процесса кроме последнего принимает (на последнем нам знать не надо и так все посчитается) MPI_Recv(&tmp1[0], N, MPI_DOUBLE, rank + 1, 123, MPI_COMM_WORLD, &status); //прием сообщения(адрес начала сообщения начало сообщения, максим чило приним элементов, тип приним элементов, номер процесса отправителя, метка сообщения (код), все процессы, параметры принятого сообщения) //MPI_Barrier(MPI_COMM_WORLD); if (rank != size - 1) //Заполныем первые столбцы соответсвующего блока, кроме первого for (int i = 0; i < N; i++) A[i][local_row + 1] = tmp1[i]; //printer(N, local_row); for (int i = 1; i < N - 1; i++) //заполняем внутренность { if (rank != 0) //при первом прохождении ранк равен 0, поэтому он в начале отправит { MPI_Recv(&A[i][0], 1, MPI_DOUBLE, rank - 1, 321, MPI_COMM_WORLD, &status); //получаем(адрес начала сообщения, макс число приним элементов, тип, номер процесса отправителя, метка сообщения, все процессы, параметры принятого сообщения) } for (int j = 2; j < local_row + 1; j += 2) //наши if в исходнике про деление на два { if ((rank == size - 1) && (j == local_row)) break; //мы дошли до последнего блока и последнего столбца //printf("rank = %d [%d][%d] \n", rank, i, j); double b = 0.0; b = w*((A[i - 1][j] + A[i + 1][j] + A[i][j - 1] + A[i][j + 1]) / 4. - A[i][j]); eps = Max(fabs(b), eps); A[i][j] = A[i][j] + b; } for (int j = 1; j < local_row + 1; j += 2) { if ((rank == 0) && (j == 1)) continue; //local_row=0? if ((rank == size - 1) && (j == local_row)) break; //мы дошли до последнего блока и последнего столбца double b; b = w*((A[i - 1][j] + A[i + 1][j] + A[i][j - 1] + A[i][j + 1]) / 4. - A[i][j]); //eps = Max(fabs(b), eps); A[i][j] = A[i][j] + b; } //A[i][local_row] = -1.0; if (rank != size - 1) //все процессы, кроме последнего отправляют MPI_Isend(&A[i][local_row], 1, MPI_DOUBLE, rank + 1, 321, MPI_COMM_WORLD, &rreq); //отправляем(начало посылки } //printer(N, local_row); MPI_Barrier(MPI_COMM_WORLD); fn = MPI_Wtime(); //printf("rank = %d [%g] \n", rank, eps); double eps1 = 0.0; MPI_Reduce(&eps, &eps1, 1, MPI_DOUBLE, MPI_MAX, 0, MPI_COMM_WORLD); //объединяет(из, в, 1 элемент, тип,максимум, номер главного процесса, со всех коммуникаторов) MPI_Bcast(&eps1, 1, MPI_DOUBLE, 0, MPI_COMM_WORLD); //передача всем процессам eps1 if (rank == 0) { cout << "it = " << it << " eps = " << eps1 << endl; time += fn - st; } if (eps1 < maxeps) break; } //if (eps < maxeps) break; if (rank == 0) cout << "time = " << time << endl; verify(N, local_row); MPI_Finalize(); //system("pause"); return 0; } void init(int N) { int local_row = N / size; //printf("local_row = %d \n", local_row); A = new double*[N]; for (int i = 0; i < N; i++) A[i] = new double[local_row + 2]; //добавляем теневые грани for (int i = 0; i < N; i++) for (int j = 0; j < local_row; j++) { A[i][j+1] = (1 + i + j + rank * local_row); } if (rank == 0) for (int i = 0; i < N; i++) A[i][1] = 0.0; if (rank == size - 1) for (int i = 0; i < N; i++) A[i][local_row] = 0.0; for (int i = 0; i < local_row+2; i++) { A[0][i] = 0.0; A[N - 1][i] = 0.0; } for (int i = 0; i < N; i++) { A[i][0] = 0.0; A[i][local_row + 1] = 0.0; } //printer(N, local_row); } void printer(int N, int local_row) { //cout << "rank = " << rank << endl; //local_row += 2; printf("rank = %d \n", rank); for (int i = 0; i < N; i++) { for (int j = 0; j < local_row+2; j++) { printf("%g ", A[i][j]); //cout << A[i][j] << " "; } printf("\n"); //cout << endl; } } void verify(int N, int local_row) { double sum = 0; for (int i = 0; i < N; i++) for (int j = 1; j < local_row+1; j++) sum += A[i][j]; MPI_Barrier(MPI_COMM_WORLD); double control = 0.0; MPI_Reduce(&sum, &control, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD); if (rank == 0) cout << "sum = " << control << endl; } Приложение В. Текст программы MPI (первый способ) #include #include #include #include #include "mpi.h" #define Max(a,b) ((a)>(b)?(a):(b)) void init(int); void printer(int, int); void verify(int, int); double maxeps = 0.1e-7; double **A; double eps; double w = 0.5; int size, rank; using std::cout; using std::endl; int main(int argc, char **argv) { MPI_Init(&argc, &argv); int itmax = atoi(argv[1]); int N = atoi(argv[2]); int ff = atoi(argv[3]); if (N%ff != 0) { if (rank == 0) cout << "lose" << endl; MPI_Finalize(); return 1; } MPI_Comm_size(MPI_COMM_WORLD, &size); MPI_Comm_rank(MPI_COMM_WORLD, &rank); init(N); MPI_Request rreq, sreq; MPI_Status status; int local_row = N / size; double st, fn; //printer(N, local_row); st = MPI_Wtime(); for (int it = 0; it < itmax; it++) { eps = 0.0; //double *tmp = NULL; double *tmp1 = NULL; double *tmp2 = NULL; //double *tmp3 = NULL; //tmp = new double[ff]; tmp1 = new double[N]; tmp2 = new double[N]; //tmp3 = new double[ff]; for (int i = 0; i < N; i++) //заполняем первыми столбцами tmp2[i] = A[i][1]; if (rank != 0) MPI_Isend(&tmp2[0], N, MPI_DOUBLE, rank - 1, 123, MPI_COMM_WORLD, &sreq); if (rank != size - 1) MPI_Recv(&tmp1[0], N, MPI_DOUBLE, rank + 1, 123, MPI_COMM_WORLD, &status); if (rank != size - 1) for (int i = 0; i < N; i++) A[i][local_row + 1] = tmp1[i]; for (int f = 0; f < N / ff; f++) { //printf("rank = %d \n", rank); //for (int i = 0; i < ff; i++) // printf("%g \n", tmp2[i]); //printf("rank = %d \n", rank); //for (int i = 0; i < ff; i++) // printf("%g \n", A[i][local_row + 1]); //printer(N, local_row); for (int i = 0; i < ff; i++) { if (f*ff + i == 0) continue; if (f*ff + i == N - 1) break; //printf("rank = %d [%d] \n", rank, f*ff + i); if (rank != 0) { MPI_Recv(&tmp1[0], ff, MPI_DOUBLE, rank - 1, 321, MPI_COMM_WORLD, &status); } if (rank != 0) for (int ii = 0; ii < ff; ii++) A[f*ff + ii][0] = tmp1[ii]; for (int j = 2 - i % 2; j < local_row + 1; j += 2) //это блять гениальная сторочка { if ((rank == 0) && (j == 1)) continue; if ((rank == size - 1) && (j == local_row)) break; //printf("rank = %d [%d][%d] \n", rank, f*ff + i, j); double b = 0.0; b = w*((A[f*ff + i - 1][j] + A[f*ff + i + 1][j] + A[f*ff + i][j - 1] + A[f*ff + i][j + 1]) * 0.25 - A[f*ff + i][j]); eps = Max(fabs(b), eps); A[f*ff + i][j] = A[f*ff + i][j] + b; } if (rank != size - 1) for (int ii = 0; ii < ff; ii++) tmp2[ii] = A[f*ff + ii][local_row]; if (rank != size - 1) MPI_Isend(&tmp2[0], ff, MPI_DOUBLE, rank + 1, 321, MPI_COMM_WORLD, &rreq); // for (int j = 1; j < local_row + 1; j += 2) // { // if ((rank == 0) && (j == 1)) continue; // if ((rank == size - 1) && (j == local_row)) break; // double b; // b = w*((A[i - 1][j] + A[i + 1][j] + A[i][j - 1] + A[i][j + 1]) / 4. - A[i][j]); // eps = Max(fabs(b), eps); // A[i][j] = A[i][j] + b; // } } } //printer(N, local_row); for (int i = 0; i < N; i++) //заполняем первыми столбцами tmp2[i] = A[i][1]; if (rank != 0) MPI_Isend(&tmp2[0], N, MPI_DOUBLE, rank - 1, 123, MPI_COMM_WORLD, &sreq); if (rank != size - 1) MPI_Recv(&tmp1[0], N, MPI_DOUBLE, rank + 1, 123, MPI_COMM_WORLD, &status); if (rank != size - 1) for (int i = 0; i < N; i++) A[i][local_row + 1] = tmp1[i]; for (int f = 0; f < N / ff; f++) { //printf("rank = %d \n", rank); //for (int i = 0; i < ff; i++) // printf("%g \n", tmp2[i]); //printf("rank = %d \n", rank); //for (int i = 0; i < ff; i++) // printf("%g \n", A[i][local_row + 1]); //printer(N, local_row); for (int i = 0; i < ff; i++) { if (f*ff + i == 0) continue; if (f*ff + i == N - 1) break; //printf("rank = %d [%d] \n", rank, f*ff + i); if (rank != 0) { MPI_Recv(&tmp1[0], ff, MPI_DOUBLE, rank - 1, 321, MPI_COMM_WORLD, &status); } if (rank != 0) for (int ii = 0; ii < ff; ii++) A[f*ff + ii][0] = tmp1[ii]; for (int j = 2 - (i + 1) % 2; j < local_row + 1; j += 2) { if ((rank == 0) && (j == 1)) continue; if ((rank == size - 1) && (j == local_row)) break; //printf("rank = %d [%d][%d] \n", rank, f*ff + i, j); double b = 0.0; b = w*((A[f*ff + i - 1][j] + A[f*ff + i + 1][j] + A[f*ff + i][j - 1] + A[f*ff + i][j + 1]) * 0.25 - A[f*ff + i][j]); eps = Max(fabs(b), eps); A[f*ff + i][j] = A[f*ff + i][j] + b; } if (rank != size - 1) for (int ii = 0; ii < ff; ii++) tmp2[ii] = A[f*ff + ii][local_row]; if (rank != size - 1) MPI_Isend(&tmp2[0], ff, MPI_DOUBLE, rank + 1, 321, MPI_COMM_WORLD, &rreq); } } //printer(N, local_row); //printf("rank = %d [%g] \n", rank, eps); double eps1 = 0.0; MPI_Allreduce(&eps, &eps1, 1, MPI_DOUBLE, MPI_MAX, MPI_COMM_WORLD); if (rank == 0) { cout << "it = " << it << " eps = " << eps1 << endl; // time += fn - st; } if (eps1 < maxeps) break; } MPI_Barrier(MPI_COMM_WORLD); fn = MPI_Wtime(); if (rank == 0) cout << "time = " << fn - st << endl; // verify(N, local_row); MPI_Finalize(); return 0; } void init(int N) { int local_row = N / size; //printf("local_row = %d \n", local_row); A = new double*[N]; for (int i = 0; i < N; i++) A[i] = new double[local_row + 2]; for (int i = 0; i < N; i++) for (int j = 0; j < local_row; j++) { A[i][j + 1] = (1 + i + j + rank * local_row); } if (rank == 0) for (int i = 0; i < N; i++) A[i][1] = 0.0; if (rank == size - 1) for (int i = 0; i < N; i++) A[i][local_row] = 0.0; for (int i = 0; i < local_row + 2; i++) { A[0][i] = 0.0; A[N - 1][i] = 0.0; } for (int i = 0; i < N; i++) { A[i][0] = 0.0; A[i][local_row + 1] = 0.0; } //printer(N, local_row); } void printer(int N, int local_row) { //cout << "rank = " << rank << endl; //local_row += 2; printf("rank = %d \n", rank); for (int i = 0; i < N; i++) { for (int j = 0; j < local_row + 2; j++) { printf("%g ", A[i][j]); //cout << A[i][j] << " "; } printf("\n"); //cout << endl; } } void verify(int N, int local_row) { double sum = 0; for (int i = 0; i < N; i++) for (int j = 1; j < local_row + 1; j++) sum += A[i][j]; MPI_Barrier(MPI_COMM_WORLD); double control = 0.0; MPI_Reduce(&sum, &control, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD); if (rank == 0) cout << "sum = " << control << endl; } |