В. И. Швецов Базы данных
 Скачать 8.45 Mb. Скачать 8.45 Mb.
|

3.5.1. Настольные СУБДНастольные СУБД используются для сравнительно небольших задач (небольшой объем обрабатываемых данных, малое количество пользователей). С учетом этого, указанные СУБД имеют относительно упрощенную архитектуру, в частности, функционируют в режиме файл-сервер, поддерживают не все возможные функции СУБД (например, не ведется журнал транзакций, отсутствует возможность автоматического восстановления базы данных после сбоев и т. п.). Тем не менее, такие системы имеют достаточно обширную область применения. Прежде всего, это государственные (муниципальные) учреждения, сфера образования, сфера обслуживания, малый и средний бизнес. Специфика возникающих там задач заключается в том, что объемы данных не являются катастрофически большими, частота обновлений не бывает слишком высокой, организация территориально обычно расположена в одном небольшом здании, количество пользователей колеблется от одного до 10–15 человек. В подобных условиях использование настольных СУБД для управления информационными системами является вполне оправданным, и они с успехом применяются. Одними из первых СУБД были так называемые dBase-совместимые программные системы, разработанные разными фирмами. Первой широко распространенной системой такого рода была система dBase III – PLUS (фирма Achton-Tate). Развитый язык программирования, удобный интерфейс, доступный для массового пользователя, способствовали широкому распространению системы. В то же время работа системы в режиме интерпретации обусловливала низкую производительность на стадии выполнения. Это привело к появлению новых систем-компиляторов, близких к системе dBase III – PLUS: Clipper (фирма Nantucket Inc.), FoxPro (фирма Fox Software), FoxBase+ (фирма Fox Software), Visual FoxPro (фирма Microsoft). Одно время достаточно широко использовалась СУБД PARADOX (фирма Borland International). В последние годы очень широкое распространение получила система управления базами данных Microsoft Access, которая входит в целый ряд версий пакета Microsoft Office(фирма Microsoft). 3.5.2. Серверные СУБДДля крупных организаций ситуация принципиально меняется. Там использование файл-серверных технологий является неудовлетворительным по описанным выше причинам. Поэтому на передний край борьбы за автоматизацию выходят так называемые серверные СУБД. Основными производителями таких систем обработки и хранения данных являются 3 корпорации: Oracle, Microsoft и IBM. Диаграмма соотношения объемов продаж соответствующих систем в 2005 году (источник: IDC Report, Май 2006) приводится на рис. 3.4. 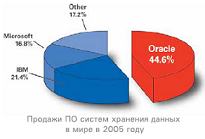  Рис. 3.4. Продажи ПО систем хранения данных в мире Наиболее распространенными клиент-серверными системами здесь соответственно являются системы Oracle (разработчик компания Oracle) , MS SQL Server ( разработчик компания Microsoft), DB2 , Informix Dynamic Server ( компания IBM ). Дадим краткую характеристику этим системам. MS SQL Server К настоящему времени разработано несколько версий систем: MS SQL Server-2000, MS SQL Server -2005, MS SQL Server-2008. Приведем информацию о системе MS SQL Server-2008 с сервера Microsoft (http://www.microsoft.com/rus/SQL/2008/default.mspx) Microsoft® SQL Server™ 2008 - это законченное предложение в области баз данных и анализа данных для быстрого создания масштабируемых решений электронной коммерции, бизнес-приложений и хранилищ данных. Оно позволяет значительно сократить время выхода этих решений на рынок, одновременно обеспечивая масштабируемость, отвечающую самым высоким требованиям. В SQL Server включена поддержка языка XML и протокола HTTP, средства повышения быстродействия и доступности, позволяющие распределить нагрузку и обеспечить бесперебойную работу, функции для улучшения управления и настройки, снижающие совокупную стоимость владения Использование MS SQL Server-2008:
Платформа бизнес-анализа SQL Server 2008, тесно интегрированная с Microsoft Office, предоставляет развитую маштабируемую инфраструктуру для внедрения мощных возможностей бизнес-анализа в рабочий процесс всех бизнес-подразделений вашей компании, открывая доступ к нужной бизнес-информации через знакомый интерфейс MS Excel и MS Word . MS SQL Server-2008 поддерживает создание и работу с корпоративным хранилищем данных, объединяющим информацию со всех систем и приложений, позволяющим получить единую комплексную картину бизнеса вашей компании, а встроенные возможности по интеграции данных. MS SQL Server-2008 предоставляет масштабируемый и высокопроизводительный «процессор данных» - для самых ответственных и требовательных бизнес-приложений, тем, кому необходим высочайший уровень надежности и защиты, позволяя при этом снизить совокупную стоимость владения за счет расширенных возможностей по управлению серверной инфраструктурой. MS SQL Server-2008 предлагает разработчикам развитую, удобную и функциональную среду программирования, включая средства работы с веб службами, инновационные технологии доступа к данным – все, что необходимо для эффективной работы с данными любых типов и форматов. Отдельные аспекты MS SQL Server – 2008 будут описаны в лекциях 10 и 14. Oracle К настоящему времени разработано несколько версий систем, каждая из которых включает целую линейку продуктов, например Oracle 8, Oracle 9i, Oracle 10g. Соответствующие линейки продуктов включают как собственно СУБД ( например Oracle Database 10g , Oracle Database 11g) , так и средства разработки и анализа данных. Приведем информацию о системе с сервера Oracle http://www.oracle.com/global/ru/mid/oracle_products/database.html). Oracle предлагает комплексные, открытые, доступные и удобные в использовании технологические решения. гГотовые пакетируемые решения автоматически включают в свою стоимость базу данных, сервер приложений, интеграционную платформу, инструменты аналитики и управления неструктурированными данными. Масштабируемые бизнес-приложения Oracle могут быть легко интегрированы с ИТ-инфраструктурой Вашего предприятия без потери уже вложенных в IT инвестиций. СУБД Oracle Database 11g обеспечивает улучшенные характеристики за счет автоматизации задач администрирования и обеспечения лучших в отрасли возможностей по безопасности и соответствию нормативно-правовым актам в области защиты информации. Появилось больше функций автоматизации, самодиагностики и управления. Среди характеристик системы можно отметить управление большими объемами данных с использованием распределенных таблиц и компрессии, эффективную ззЗащитау данных, возможность полного восстановления, возможность интеграции геофизических данных медиа-контента в бизнес-процеcc и т. д. Серверы баз данных компании IBM К настоящему времени разработаны линейки продуктов DB2 и Informix , включающая как собственно СУБД так и средства разработки и анализа данных (DB2 Universal Database ДDB2 Personal Edition, DB2 Enterprise 9 и др., а также Informix Dynamic Server, Informix Dynamic Server Express, Informix Extended Parallel Server и др. Приведем информацию о части таких систем с сервера (http://www-01.ibm.com/software/ru/data/?pgel=ibmhzn) Универсальный сервер баз данных DB2 Universal Database - это масштабируемая, обьектно-реляционная система управления базами данных с интегрированной поддержкой мультимедиа и Web, работающая на системах от персональных компьютеров и серверов на процессорах Intel до Unix, от однопроцессорных систем до симметричных многопроцессорных систем (SMP) и систем с массовым параллелизмом (MPP), на хостах AS/400 и мейнфреймах. DB2 Universal Database объединяет в себе высокую производительность систем обработки транзакций в режиме on-line, объектно-реляционные расширения, усовершенствованные средства оптимизации с возможностями параллельной обработки и поддержкой очень больших баз данных. DB2 Universal Database также имеет новые встроенные средства для облегчения переноса на свою базу приложений, разработанных на других системах управления базами данных, таких как Oracle, Microsoft, Sybase и Informix. Помимо этого, DB2 Universal Database включает в себя дополнительные средства поддержки систем аналитической обработки в реальном времени (OLAP) и систем поддержки принятия решений, множество простых в использовании расширений (DB2 extenders). DB2 Universal Database доступна на абсолютном большинстве ключевых платформ, что дает заказчикам ту гибкость, которая им необходима. Кроме вышеуказанных зарубежных систем отметим и отечественную разработку – СУБД НИКА, преемницу широко распространенной в Советском Союзе СУБД ИНЕС для ЕС ЭВМ. Мы привелиВ этой лекции был приведен краткий обзор незначительной части существующих СУБД. При огромном разнообразии СУБД вполне естественны споры (которые возникли с момента появления СУБД и, по-видимому, не утихнут никогда) о том, какая СУБД лучше. Нам представляется, что однозначного ответа на этот вопрос не существует. Каждая СУБД имеет свои границы применимости, у каждой из них существуют свои достоинства и недостатки, свое соотношение цена-качество. На форумах Интернета идут постоянные дискуссии пользователей и администраторов баз данных о том, какая СУБД лучше, которые, естественно, не дают окончательного ответа. Любой читатель может иметь личные пристрастия, которые в его глазах уменьшают недостатки и увеличивают достоинства некоторой конкретной СУБД. Мы считаем, что это нормально. Общие рекомендации о том, какой из СУБД воспользоваться в каком-то конкретном случае, придумать сложно. Выбор, прежде всего, зависит от класса задач, который нужно решать с использованием СУБД, от тех критериев, которые для соответствующего класса задач являются предпочтительными ( стоимость СУБД, простота разработки информационной системы, быстродействие системы при конкретных объемах данных, устойчивость в работе, возможность восстановления, защита от несанкционированного доступа и т.д.). Рекомендация может быть только одна: внимательно изучайте обзоры, читайте пресс-релизы, знакомьтесь с отзывами пользователей, сопоставляйте их наблюдения о плюсах и минусах систем с вашими потребностями и возможностями. Краткие итоги. В лекции рассмотрены Рразличные архитектурные решения, используемые при реализации многопользовательских СУБД. Централизованная архитектура. Технология с сетью и файловым сервером (архитектура «файл-сервер»). Архитектура «клиент – сервер» (распределенная модель вычислений). Трехзвенная (многозвенная) архитектура) клиент – сервер. Дан Ообзор современных СУБД (настольные СУБД, серверные СУБД). Контрольные тесты Задача 1. Какие технологии работы с базой данных поддерживают многопользовательский режим? Вариант 1. Какие технологии работы с базой данных поддерживают многопользовательский режим? ð+ +технология с централизованной архитектурой базы данных ð+ +технология с сетью и файловым сервером ð+ +технология клиент-сервер ð+ +технология с трехзвенной архитектурой Вариант 2. С чем связано развитие многопользовательских технологий работы с базами данных? +ð+ с развитием СУБД +ð+ Сс развитием вычислительных сетей Сс развитием технологий программирования Сс ростом квалификации программистов Вариант 3. Основные достоинства многопользовательского режима работы с базой данных возможность использования прикладных программ других пользователей сокращение затрат машинного времени +ð+ возможность работы многих пользователей с базой данных сокращение количества обращений к базе данных Задача 2. Что такое архитектура файл-сервер? Вариант 1. Где расположена база данных в такой архитектуре? на компьютере пользователя +ð+ на специально выделенном компьютере – сервере на компьютере пользователя и на специально выделенном компьютере – сервере на всех компьютерах пользователей в локальной сети Вариант 2. Где расположены программы пользователя и программы СУБД? +ð+ на компьютере пользователя на специально выделенном компьютере – сервере программа пользователя на компьютере пользователя, СУБДсубд на специально выделенном компьютере – сервере +ð+ СУБДсубд расположена на всех компьютерах пользователей в локальной сети Вариант 3. На каком компьютере происходит работа с базой данных? ð+ +Нна компьютере одного пользователя Нна специально выделенном компьютере – сервере пПрикладные программы работают на компьютере пользователя, программы СУБД работают на специально выделенном компьютере – сервере +ð+ пПрикладные программы и программы СУБД работают на компьютере пользователя. Задача 3. Как идет обмен информацией между компьютерами в технологии файл-сервер? Вариант 1. Что делает компьютер пользователя? +ð+ вВыполняет прикладную программу +ð+ Ввыполняет программы СУБД +ð+ рРеализует запросы пользователя к базе данных +ð+ Ввыполняет прикладную программу и программы СУБД Вариант 2. Что делает файл-сервер? фФормирует ответы на запросы к базе данных +ð+ Ииспользуется как внешняя память для хранения базы данных вВыполняет программы СУБД вВыполняет прикладные программы и программы СУБД Вариант 3. Как идет обмен информацией между компьютерами в технологии файл-сервер? вВ компьютер пользователя считываются все файлы базы данных Вв компьютер пользователя считываются только данные, удовлетворяющие запросу пользователя +ð+ Вв компьютер пользователя считываются только те файлы базы данных, которые необходимы для выполнения запросов +ð+ Вв компьютер пользователя считываются файлы базы данных, указанные в прикладной программе . Задача 4. Что такое архитектура клиент-сервер Вариант 1. Где расположена база данных в такой архитектуре? на компьютере пользователя +ð+ на специально выделенном компьютере – сервере на компьютере пользователя и на специально выделенном компьютере – сервере на всех компьютерах пользователей в локальной сети Вариант 2. Где расположены программы пользователя и программы СУБД в архитектуре клиент-сервер? Нна компьютере пользователя нНа специально выделенном компьютере – сервере +ð+ пПрограмма пользователя на компьютере пользователя, СУБД на специально выделенном компьютере – сервере СУБД расположена на всех компьютерах пользователей в локальной сети Вариант 3. На каком компьютере происходит работа с базой данных в архитектуре клиент-сервер? нНа компьютере одного пользователя +ð+ нНа специально выделенном компьютере – сервере +ð+ пПрикладные программы работают на компьютере пользователя, программы СУБД работают на специально выделенном компьютере – сервере +ð+ Пприкладные программы и программы СУБД работают на компьютере пользователя. Задача 5. Как идет обмен информацией между компьютерами в технологии клиент-сервер? Вариант 1. Что делает компьютер – клиент? + Ввыполняет прикладную программу Ввыполняет программы СУБД рРеализует запросы пользователя к базе данных ð+ вВыполняет прикладную программу и программы СУБД Вариант 2. Что делает сервер? +ð+ фФормирует ответы на запросы к базе данных иИспользуется как внешняя память для хранения базы данных +ð+ вВыполняет программы СУБД вВыполняет прикладные программы и программы СУБД Вариант 3. Как осуществляется обмен информацией между компьютером-клиентом и сервером? Вв компьютер-клиент считываются все файлы базы данных +ð+ вВ компьютер-клиент считываются только данные, удовлетворяющие запросу пользователя Вв компьютер-клиент считываются только те файлы базы данных, которые необходимы для выполнения запросов вВ компьютер-клиент считываются файлы базы данных, указанные в прикладной программе . Задача 6. Что такое трехзвенная (многозвенная) архитектура Вариант 1. Что отличает трехзвенную архитектуру от архитектуры клиент-сервер? большее количество компьютеров пользователей большее количество серверов баз данных +ð+ наличие серверов других типов другой способ взаимодействия с сервером баз данных Вариант 2. Где выполняются программы пользователя в трехзвенной архитектуре? на компьютере пользователя на сервере баз данных +ð+ на компьютере пользователя и сервере приложений на сервере приложений Вариант 3. Что делает сервер приложений? выполняет прикладные программы пользователя +ð+ формирует запросы к базе данных и обрабатывает результаты запросов формирует интерфейс пользователя отображает результаты обработки на компьютере пользователя Задача 7. Сравнение архитектуры клиент-сервер с файл-серверной архитектурой. Вариант 1. Какие черты характерны для компьютеров-клиентов в архитектуре клиент-сервер по сравнению с файл-серверной архитектурой? увеличение объема прикладной программы + уменьшение объема прикладной программы +ð+ уменьшение объема производимых вычислений ð+ увеличение объема занимаемой памяти + уменьшение объема занимаемой памяти Вариант 2. Как меняется объем данных, передаваемых по локальной сети в архитектуре клиент-сервер по сравнению с файл-серверной архитектурой? немного уменьшается увеличивается остается таким же ð+ существенно уменьшается Вариант 3. За счет чего улучшаются характеристики целостности и безопасности данных? из-за уменьшения объема передаваемых данных за счет более эффективного формирования запросов за счет реализации соответствующих функций СУБД на клиентских компьютерах ð+ +Зза счет реализации соответствующих функций СУБД на сервере баз данных Задача 8. Как классифицируются современные СУБД? Вариант 1. Какие СУБД относятся к клиент-серверным? ACCESS +ð+ MS SQL-сервер +ð+ ORACLE ð+ +DB2 Вариант 2. Какие СУБД относятся к файл-серверным? +ð+ ACCESS MS SQL-сервер ORACLE +ð+ FoxPro Вариант 3. Какие СУБД используются для организации баз данных в крупных организациях (относятся к промышленным)? ACCESS ð+ +MS SQL-сервер ð+ +ORACLE FoxPro Литература
Лекция 4. Различные представления о данных в базах данных. Основные этапы проектирования баз данных. В лекции рассматриваются различные представления о данных в базах данных. Описываются модели данных (внешнее представление, концептуальная модель, структура хранения) и основные этапы проектирования базы данных. Рассматривается жизненный цикл проектирования базы данных. Ключевые словатермины: концептуальные требования пользователя, концептуальная модель, модель данных СУБД, логическая модель, обобщенное представление о данных, внешнее представление, трехуровневая архитектура базы данных, проектирование баз данных, основные этапы проектирования базы данных. Цель лекции: Показать существование различных представлений о данных (различных моделей) у разных групп лиц, работающих с данными. Рассмотреть отражение этих представлений в трехуровневой архитектуре базы данных (внешний уровень, концептуальный уровень, внутренний уровень), сформулировать достоинство трехуровней архитектуры. Выделить основные этапы пректирования базы данных как процесса построения вышеуказанных моделей. 4.1. Различные представления о данных в базах данных Создание базы данных предполагает интеграцию данных, предназначенных для решения нескольких прикладных задач разных пользователей. Соответственно, при интеграции данных должны учитываться требования к данным каждого пользователя, основанные на его представлении о данных и связях между ними. Далее эти требования должны обобщаться в единое представление, которое и будет служить основой для построения единой базы данных (рис. 4.1). Обобщение представлений всех пользователей о данных называется концептуальной моделью (схемой) БД. Концептуальная модель представляет информационное описание предметной области с учетом логических взаимосвязей, поэтому её еще называют инфологической (информационно-логической) моделью. В модели отсутствуют какие-либо понятия, связанные с ЭВМ, памятью ЭВМ, способами размещения данных в памяти ЭВМ, и, по сути, это модель только предметной области. 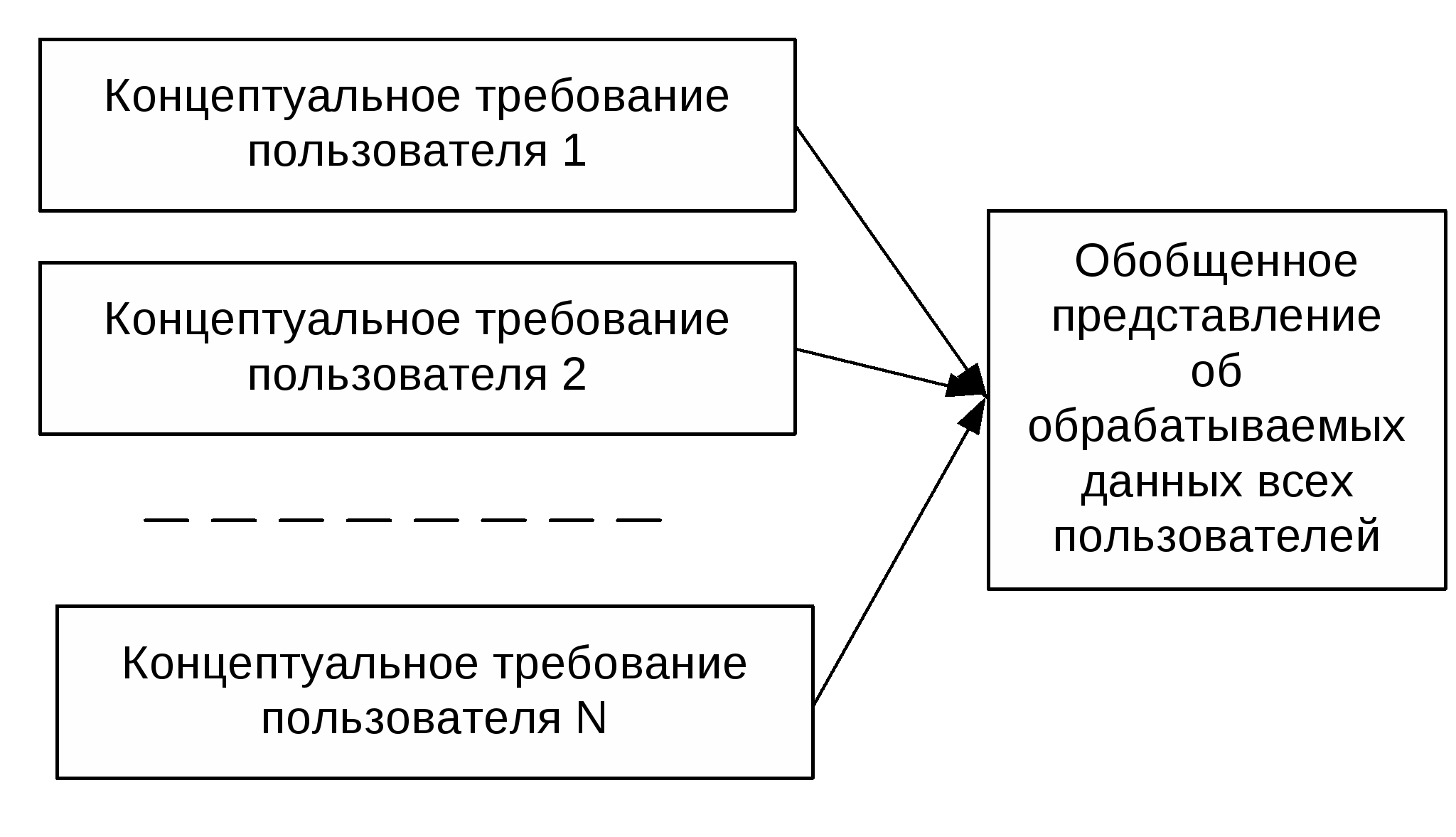 Рис. 4.1. Обобщение представления пользователей о данных Как уже отмечалось, для создания базы данных и работы с ней используется система управления базами данных. Каждая конкретная СУБД поддерживает определенный вид данных (форматов записей и отношений), называемый моделью данных СУБД. Следующий этап разработки базы данных предполагает выбор представления концептуальной модели с помощью модели данных конкретной СУБД. Полученное таким образом представление концептуальной модели называется логической моделью БД. Или другими словами, логическая модель – это концептуальная схема, специфицированная в языке конкретной СУБД. Логическая модель представляет данные и элементы данных вне зависимости от их содержания и среды хранения. Далее разработчик системы средствами СУБД отображает полученную логическую модель БД в память ЭВМ и определяет методы доступа. Полученное представление данных в памяти ЭВМ называется внутренним представлением или структурой хранения. Прикладные программы работают с логической моделью, причем каждому пользователю представляется подмножество этой логической модели (подсхема), отражающее его представление о предметной области. Каждая прикладная программа «видит» и обрабатывает только те данные, которые необходимы именно ей. Соответствующее «видение» данных прикладными программами (пользователями) представляет собой внешние представления. Взаимосвязь вышеуказанных моделей изображена на рис.4.2. 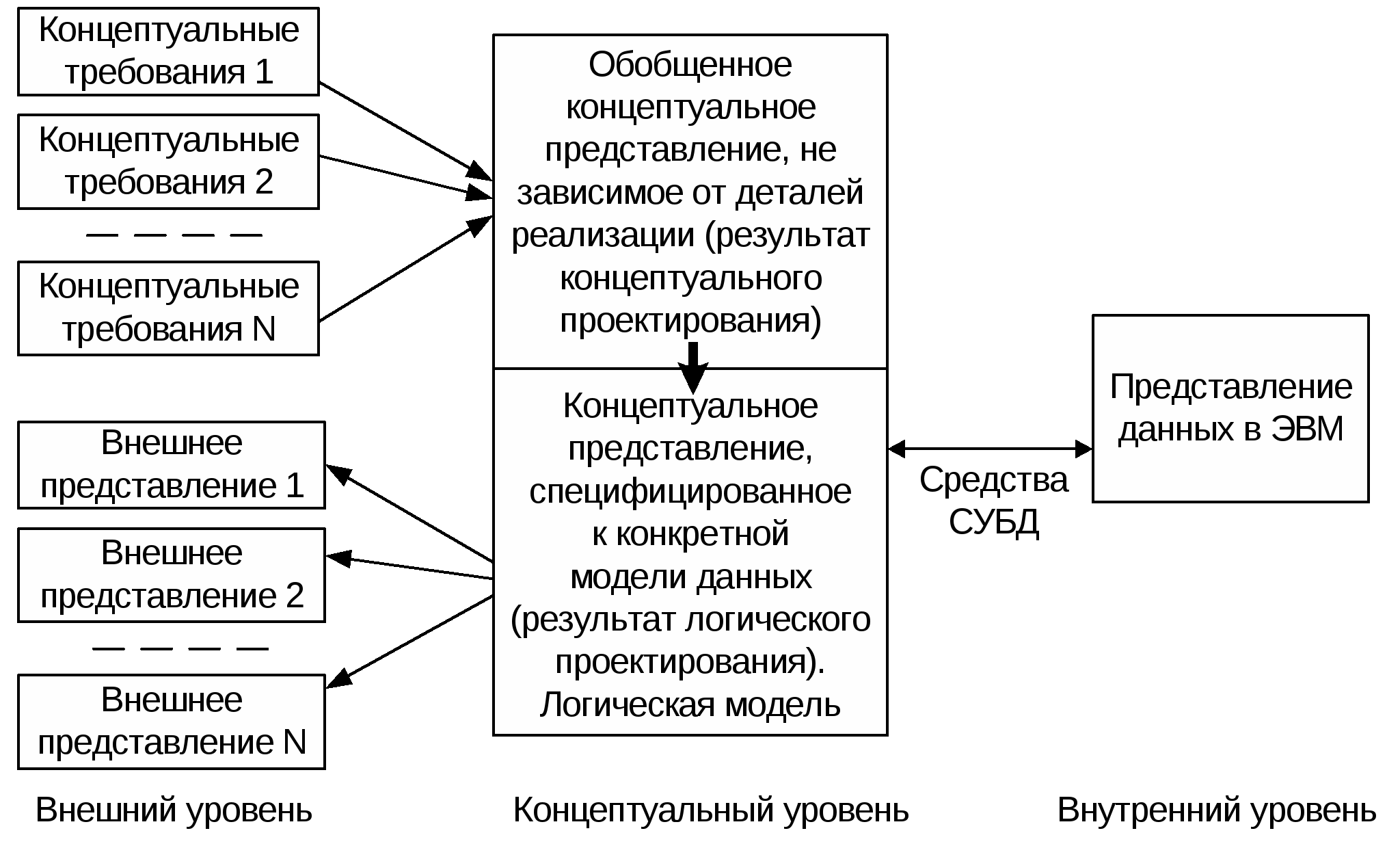 Рис. 4.2. Различные представления о данных в БД На данной схеме выделены три различных уровня описания данных (внешний, концептуальный, внутренний). Эти уровни формируют так называемую трехуровневую архитектуру ANSI/SPARC, предложенную в 1975 г. Комитетом планирования стандартов и норм SPARC (Standards Planning and Requirements Committee) Национального института стандартизации США (American National Standards Institute – ANSI). Основная цель этой архитектуры состоит в отделении пользовательского представления о данных в базе данных от их физического представления. Использование таких представлений о данных позволяет обеспечить выполнение основного требования к БД – независимости программ и данных. При изменении прикладных программ может измениться соответствующее внешнее представление, но логическая модель данных не изменяется и, соответственно, не будут изменяться другие прикладные программы. При изменении внутреннего представления (структур хранения) логическая модель не изменяется, соответственно, не изменяются прикладные программы. Использование соответствующих представлений также позволяет четко разграничить полномочия различных лиц, работающих с базой данных. Соответствующие представления позволяют описать «видение» базы данных разными лицами, работающими с ней:
4.2. Основные этапы проектирования базы данных Проектирование данных (базы данных) представляет собой процесс последовательного отображения исследуемых явлений реального мира в виде данных в памяти ЭВМ (рис. 4.3.). Рис. 4.3. Общая схема пректирования Конкретные явления реального мира, представляющие интерес для проводимого исследования, будем называть предметной областью. Проектирование (моделирование) базы данных представляет собой многоэтапный процесс. Основные этапы этого процесса приведены на рис. 4.4.). 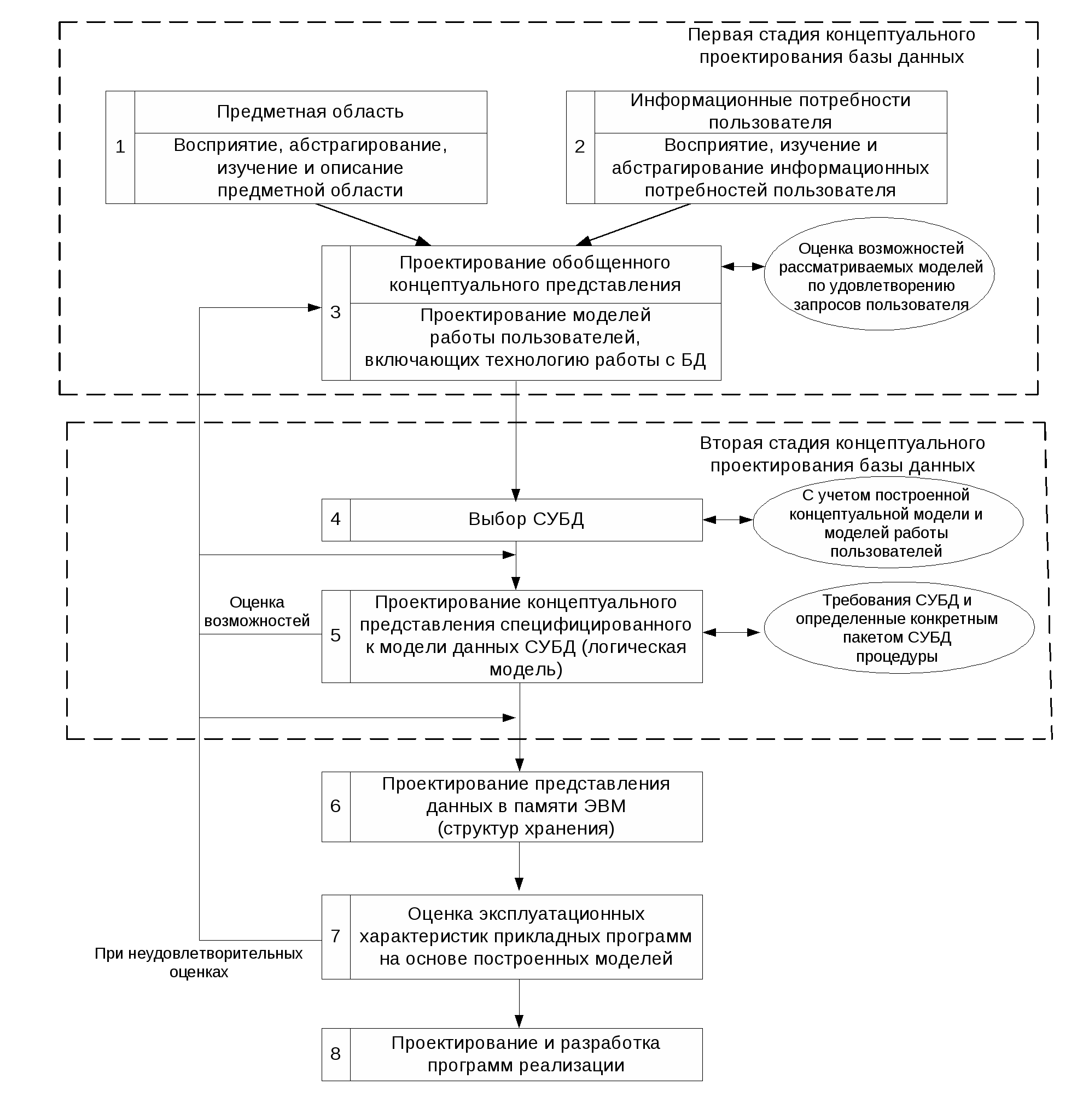 Рис. 4.4. Этапы проектирования базы данных Подробно действия, отраженные на приведенном рисунке, будут рассмотрены в следующих лекциях. Здесь дадим лишь краткие комментарии к соответствующим блокам. В блоках 1,2 необходимо особое внимание обратить на слово «абстрагирование». Имеется ввиду, что проектирование базы данных нужно вести не под конкретный документ, обрабатываемый пользователем, и не под конкретные действия пользователя с этим документом, а под обобщенный (абстрактный) образ документов и обобщенные (абстрактные) действия пользователей. Например, рассматривать документ не с конкретными числами строк и столбцов, а с абстрактными числами n и m; вместо требуемого пользователем поиска по конкретному полю (например, фамилии) рассматривать поиск по любому полю и т. д. Это очень важно, так как конкретные формы документов и действия пользователей при работе с ними достаточно часто изменяются. В этом случае при проектировании базы данных под конкретные формы документов и конкретные действия придется перепроектировать базу данных. что связано с существенными временными и стоимостными затратами. Очень важным является выбор СУБД (блок 4), от которого в значительной степени зависит работоспособность построенной базы данных. Проблема выбора СУБД уже обсуждалась в лекции 3. Заметим здесь, что выбор СУБД зависит от количества форм документов, от сложности связей между данными, от объема обрабатываемых данных, от количества пользователей, работающих с БД и т. д. Ранее отмечалось, что отображение логической модели базы данных в структуру хранения (представление данных в памяти компьютера) осуществляется системой управления базой данных. Тем не менее, во многих СУБД для повышения эффективности функционирования базы данных представляется возможность выбора ряда параметров, управляющих представлением данных в памяти компьютера. Выбор таких параметров и подразумевается в блоке 6. Заметим, что очень важно при проектировании базы данных делать оценки ее возможной работоспособности. Так, по завершении проектирования обобщенного концептуального представления нужно попытаться оценить необходимое число производимых операций с элементами моделей при реализации возможных запросов пользователей. При невозможности в рамках построенной модели ответить на какой-то запрос пользователя или при значительном числе производимых при этом операций (что приведет к невозможности реализации соответствующего запроса в реальном масштабе времени) необходим возврат по схеме рис. 4.4. на шаг назад (построение более эффективного обобщенного концептуального представления). Аналогичные оценки необходимо делать и при завершении других этапов проектирования (блоки 5, 7). При этом возможен возврат назад на один или несколько шагов. Так, например, при проектировании логической модели (блок 5) не удается достичь адекватного представления концептуальной модели средствами модели данных СУБД. В этом случае необходимо либо вернуться на шаг назад и выбрать другую СУБД, либо вернуться к блоку 3 и изменить вид концептуальной модели. Так же, если полученные при реализации блока 7 оценки эксплуатационных характеристик не отвечают требованиям пользователя, возможны пересмотры всех ранее полученных решений (блоки 7, 6, 5, 4, 3). Кроме этого, необходим возврат на проектирование обобщенного концептуального представления при изменении внешних требований пользователей, а также при выявленных ошибках проектирования. Краткие итоги: Рассмотрены различные представления о данных в базах данных - модели обрабатываемых данных (внешнее представление, концептуальная модель, структура хранения). Представлено отражение этих представлений в трехуровневой архитектуре базы данных (внешний уровень, концептуальный уровень, внутренний уровень), сформулировано достоинство трехуровней архитектуры. Описаны основные этапы проектирования базы данных как процесса построения вышеуказанных моделей и жизненный цикл проектирования базы данных (создание, апробация, исправление ошибок и улучшение характеристик, опытная эксплуатация). Вопросы данной лекции рассматриваются в [1-6]. Контрольные тесты Задача 1.Что такое концептуальная модель? Вариант 1. Что такое концептуальная модель? ð Интегрированные данные база данных +ð+ обобщенное представление пользователей о данных описание представления данных в памяти компьютера Вариант 2. Что входит в представление концептуальной модели? +ð+ информационное описание предметной области +ð+ логические взаимосвязи между данными описание представления данных в памяти компьютера описание решаемых прикладных задач Вариант 3. Как соотносятся понятия информационно-логической модели и обобщенного концептуального представления? ð+ +одно и тоже это разные понятия обобщенное концептуальное представление является частью информационно-логической модели информационно-логическая модель является частью обобщенного концептуального представления Задача 2. Что такое логическая модель базы данных? Вариант 1. Как соотносятся понятия логической модели и концептуальной модели? это разные понятия +ð+ логическая модель это вариант представления концептуальной модели это одно и то же логическая модель является частью концептуальной модели Вариант 2. Какая связь между логической моделью базы данных и СУБД? это не связанные понятия +ð+ логическая модель базы данных использует спецификации СУБД +ð+ СУБД отображает логическую модель базы данных в структуру хранения логическая модель базы данных описывает структуру хранения данных системой управления базами данных Вариант 3. Какое описание данных используется прикладными программами при работе с базой данных? описание структуры представления базы данных в памяти компьютера описание структуры хранения данных системой управления базами данных +ð+ описание логической модели данных описание данных в прикладных программах Задача 3. Какие уровни выделяются в архитектуре базы данных? Вариант 1. Как называются уровни архитектуры базы данных? нижний +ð+ внешний +ð+ концептуальный +ð+ внутренний верхний Вариант 2. Какой из уровней используется специалистом предметной области? нижний +ð+ внешний концептуальный внутренний верхний Вариант 3. Какой из уровней используется прикладным программистом? нижний внешний +ð+ концептуальный внутренний верхний Задача 4. Из каких составляющих элементов состоят уровни архитектуры базы данных? Вариант 1. Какие понятия соответствуют внешнему уровню архитектуры базы данных? +ð+ концептуальные требования пользователей +ð+ внешние представления пользователей концептуальная модель обобщенное представление Вариант 2. Какие понятия соответствуют концептуальному уровню архитектуры базы данных? концептуальные требования пользователей +ð+ логическая модель базы данных +ð+ концептуальная модель + обобщенное представление пользователей Вариант 3. . Какие понятия соответствуют внутреннему уровню архитектуры базы данных? логическая модель базы данных обобщенное представление пользователей ð+ +структура хранения данных +ð+ методы доступа к данным Задача 5. Что представляет собой процесс проектирования базы данных? Вариант 1. Основные этапы проектирования базы данных: +ð+ изучение предметной области +ð+ проектирование обобщенного концептуального представления +ð+ проектирование концептуального представления, специфицированного к модели данных СУБД (логической модели) разработка прикладных программ Вариант 2. Из каких составляющих состоит процесс проектирования концептуальной модели? +ð+ проектирование обобщенного концептуального представления (инфологической модели) +ð+ выбор СУБД +ð+ проектирование концептуального представления, специфицированного к модели данных СУБД (логической модели) проектирование представления данных в памяти компьютера (структур хранения) Вариант 3. Какие действия выполняются на этапе проектирования структур хранения? выбор СУБД разработка прикладных программ выбор способа размещения данных в памяти компьютера +ð+ выбор параметров размещения данных в памяти компьютера, представляемых СУБД Задача 6. Какие этапы входят в первую и вторую стадию концептуального проектирования? Вариант 1. Из каких этапов состоит первая стадия концептуального проектирования? +ð+ изучение предметной области +ð+ проектирование обобщенного концептуального представления проектирование концептуального представления, специфицированного к модели данных СУБД (логической модели) проектирование представления данных в памяти компьютера (структур хранения) разработка прикладных программ Вариант 2. Какие этапы проектирования базы данных не входят в первую стадию концептуального проектирования? проектирование обобщенного концептуального представления (инфологической модели) ð+ выбор СУБД +ð+ проектирование концептуального представления, специфицированного к модели данных СУБД (логической модели) +ð+ проектирование представления данных в памяти компьютера (структур хранения) Вариант 3. Какие этапы проектирования базы данных входят во вторую стадию концептуального проектирования? изучение предметной области проектирование обобщенного концептуального представления +ð+ проектирование концептуального представления, специфицированного к модели данных СУБД (логической модели) +ð+ проектирование представления данных в памяти компьютера (структур хранения) Задача 7. Что понимается под понятием «абстрагирование» при описании предметной области и информационных потребностей пользователя? Вариант 1. Что понимается под термином «абстрагирование» при описании предметной области описание форм конкретных обрабатываемых документов описание абстрактного документа, не связанного с рассматриваемой предметной областью +ð+ описание документов, представляющих абстрактный образ обрабатываемых документов описание обобщенного представления действий всех пользователей Вариант 2. Что понимается под термином «абстрагирование» при описании информационных потребностей пользователей? описание конкретных задач пользователя при работе с базой данных описание абстрактных действий с базой данных, не связанных с предметной областью +ð+ описание абстрактных действий с базой данных, обобщающих действия всех пользователей абстрактное описание документов, с которыми работают все пользователи Вариант 3. Что не соответствует понятию «абстрагирование» ? +ð+ описание форм конкретных обрабатываемых документов описание абстрактного документа, не связанного с рассматриваемой предметной областью описание документов, представляющих абстрактный образ обрабатываемых документов +ð+ описание конкретных задач пользователя при работе с базой данных описание абстрактных действий с базой данных, не связанных с предметной областью описание абстрактных действий с базой данных, обобщающих действия всех пользователей абстрактное описание документов, с которыми работают все пользователи Задача 8. С чем связана необходимость возврата к предыдущим этапам проектирования базы данных? Вариант 1. Как необходимо оценивать результат завершенного этапа проектирования базы данных? +ð+ по возможности ответа на все возможные запросы пользователей +ð+ по числу элементарных действий, необходимых для ответа на все возможные запросы пользователей по отсутствия дублирования информации +ð+ по адекватности представления предметной области Вариант 2. Что в процессе проектирования базы данных обуславливает необходимость возврата на начало этапа или на предыдущие этапы? +ð+ ошибки проектирования +ð+ изменение требований пользователей +ð+ невозможность ответа на все возможные запросы пользователей ð+ слишком большое число элементарных действий, необходимых для ответа на все возможные запросы пользователей Вариант 3. Какие этапы проектирования могут повторно пересматриваться? изучение предметной области +ð+ проектирование обобщенного концептуального представления +ð+ выбор СУБД +ð+ проектирование концептуального представления, специфицированного к модели данных СУБД (логической модели) +ð+ проектирование представления данных в памяти компьютера (структур хранения) Литература
Лекция 5. Первая стадия концептуального проектирования базы данных (концептуальное моделирование) Лекция посвящена моделированию предметной области. Здесь рассматриваются понятия, с помощью которых описывается предметная область, средства графического представления концептуальной модели предметной области в виде . ER-диаграммы, основные приемы, используемые при моделировании. Ключевые термины: информационное описание предметной области, атрибут, сущность, класс сущностей, связь, типы связей, диаграмма сущность-связь, . ER-диаграмма, концептуальная модель, этапы построения концептуальной модели, ограничения целостности. Цель лекции: показать, как описывается предметная область при концептуальном моделировании (с помощью каких понятий, средств представления и приемов построения) и как обеспечивается достоверность информации в базе данных за счет ограничений целостности концептуальной модели. 5.1. Описание информационного представления предметной области. ER-диаграмма. Иллюстрацию вводимых понятий и этапов проектирования базы данных будем проводить на примере близкой для читателя конкретной предметной области: представление данных о студентах вуза, Дадим краткое описание рассматриваемой предметной области. В вузе имеется несколько факультетов, на каждом их которых ведется подготовка по нескольким специальностям или направлениям. Для каждой специальности на факультете есть свой учебный план, в котором приводится перечень изучаемых учебных курсов с указанием количества часов занятий. Студенты изучают соответствующие дисциплины, сдают экзамены и зачеты, получают оценки. Чаще всего концептуальная модель представляется в виде диаграммы сущностей – связей (entity – relationship) или ER-диаграммы. Процесс построения ER-диаграммы называется ER-моделированием. Введем основные понятия, с помощью которых описывается предметная область. Сущность (Entity) или объект – то, о чем будет накапливаться информация в информационной системе (нечто такое, за чем пользователь хотел бы наблюдать). Если в системе обрабатывается информация о факультетах, сущностью будет являяться факультет, если о студентах, сущность – студент и т.п. Имя сущности при ER-моделировании , как правило, записывается заглавными буквами. Каждая сущность обладает определенным набором свойств (рассматриваем только свойства, представляющие интерес для пользователей в рамках проводимого исследования), которые запоминаются в информационной системе. Так, например, в качестве свойств сущности ФАКУЛЬТЕТ можно указать номер вакультета, название факультета, в качестве свойств сущности СТУДЕНТ можно указать фамилию, дату рождения, место рождения, в качестве свойств сущности ЭКЗАМЕН – предмет, дату проведения экзамена, экзаменаторов. Для информационного описания сущности вводится понятие атрибута. Атрибут – поименованное свойство (характеристика) сущности.Атрибут представляет собой информационное отображение свойства сущности и принимает конкретное значение из множества допустимых значений. Так, например, для сущности ФАКУЛЬТЕТ атрибут «название» у конкретного экземпляра сущности принимает конкретное значение «вычислительной математики и кибернетики». Таким образом, атрибут представляет информационное описание количественных или качественных свойств сущности, описывает состояние сущности, позволяет идентифицировать сущность. Информация о сущности представляется совокупностью атрибутов. Такую совокупность атрибутов часто называют записью об объекте. Совокупность сущностей, характеризующихся в информационной системе одним и тем же перечнем свойств, называется классом сущностей (набором объектов). Так, например, совокупность всех сущностей СТУДЕНТ составляет класс сущностей СТУДЕНТ, совокупность всех сущностей ФАКУЛЬТЕТ составляет класс сущностей ФАКУЛЬТЕТ. Класс сущностей описывается перечнем свойств сущностей, составляющих этот класс. Экземпляром сущности будем называть конкретную сущность (сущность с конкретными значениями соответствующих свойств). Выше мы определили сущность как то, о чем будет накапливаться информация в информационной системе. Это только одна сторона. Информация должна не просто храниться сама по себе, а использоваться для удовлетворения информационных потребностей пользователя. Для реализации подавляющего числа запросов пользователю прежде всего необходимо найти интересующий его экземпляр сущности (с целью обработки, корректировки, удаления). Поэтому важнейшим свойством сущности является однозначная идентификация ее экземпляров по одному или группе атрибутов (уникальному идентификатору). У сущности ФАКУЛЬТЕТ это, например, номер факультета, у сущности СТУДЕНТ это может быть атрибут «фамилия», если у всех студентов разные фамилии, группа атрибутов «фамилия», «»имя», «отчество», или специально введенный уникальный идентификатор, например дополнительно введенный атрибут «код студента». Наиболее распрстраненным способом представления концептуальной модели является так называемая ER-диаграмма. В разных источниках используются разные системы обозначений в ER-диаграммах. На практике использование различных способов записи ER-диаграмм не представляет особой сложности – беглое ознакомление с соответствующим разделом документации позволяет быстро освоить используемую систему обозначений. В данном пособии в ER-диаграмме класс сущностей будем представлять в виде четырехугольника. В четырехугольнике записано уникальное имя класса сущности (прописными буквами) и имена атрибутов строчными буквами. Пример класса сущностей СТУДЕНТ и конкретного экземпляра сущности показан на рис. 5.1.  Рис. 5.1.. Класс сущностей и экземпляр сущности Для реализации иформационных потребностей пользователя недостаточно найти интересующий его экземпляр сущности. Информационные потребности тесно связаны с функциональными взаимоотношениями, существующими в организации (например, необходимо определить, на каком факультете учится конкретный студент). Для реализации таких запросов (информационных потребностей пользователя) используются существующие в предметной области взаимоотношения между сущностями. Соответствующие взаимоотношения сущностей выражаются связями (Relationships). Различают классы связей и экземпляры связей. Классы связей – это взаимоотношения между классами сущностей, а экземпляры связи – взаимоотношения между экземплярами сущностей. Класс связей может затрагивать несколько классов сущностей. Число классов сущностей, участвующих в связи, называется степенью связи n = 2, 3, … Так, например, класс сущностей СТУДЕНТ связан с классом сущностей ФАКУЛЬТЕТ связью «учится на факультете». Степень этой связи равна двум. При n=2 связь называется бинарной. Заметим, что связь нужно рассматривать как двустороннюю: «студент учится на факультете» и «на факультете учатся студенты». Рассмотрим классификацию бинарных связей. В зависимости от того, сколько экземпляров сущности одного класса связаны со сколькими экземплярами сущности другого класса, различают следующие типы связей:
Числа, описывающие типы бинарных связей (1:1, 1:M, M:N), обозначают максимальное количество сущностей на каждой стороне связи. Эти числа называются максимальными кардинальными числами, а соответствующая пара чисел называется максимальной кардинальностью. В данном пособии на ER-диаграммах связи между сущностями будем обозначать стрелками, рядом со стрелками указываем имя связи, а также тип связи. Пример ER-диаграммы, представлющего сущности СТУДЕНТ, ФАКУЛЬТЕТ, СПЕЦИАЛЬНОСТЬ и их взаимосвязи приводится на рис. 5.2. Нпомним, что каждый экземпляр сущности должен уникально идентифицироваться (иметь уникальный идентификатор). Так как могут быть несколько студентов с одинаковой фамилией, введем дополнительный атрибут «код студента». У сущностей ФАКУЛЬТЕТ и СПЕЦИАЛЬНОСТЬ атрибут «номер» является уникальным идентификатором.  Рис.5.2. пПример фрагмента ер ER-диаграммы. Заметим, что по этой ER-диаграмме можно указать последовательность действий, производимых при реализации запроса пользователей. Например, для реализации запроса «на каком факультете учится студент Иванов» необходимо выполнить следующие действия: найти среди экземпляров сущности СТУДЕНТ экземпляр с фамилией Иванов, перейти по связи «Студент учится на факультете» к экземпляру сущности ФАКУЛЬТЕТ, значение атрибута «Название» этого экземпляра и есть искомое название факультета. Отметим также, что иногда на ER-диаграммах две связи между сущностями изображают одной двухсторонней стрелкой или просто линией. Заметим, что на приведенной ER-диаграмме не представлены какие-либо способы реализации этих связей (на логическом и, тем более , на физическом уровнях). Соответствующие способы реализации связей зависят от возможностей модели данных конкретной СУБД и будут рассмотрены в следующей лекции (лекция 6) на второй стадии концептуального проектирования при представлении концептуальной модели средствами модели данных СУБД. 5.2. Построение концептуальной модели в виде ER-диаграммы |