В. И. Швецов Базы данных
 Скачать 8.45 Mb. Скачать 8.45 Mb.
|

В.И. Швецов Базы данныхУДК 681.3 ББК 32.97 Общая информация о курсе Курс «Базы данных» Краткая аннотация: Университетский курс, формирующий концептуальные представления о принципах построения БД и СУБД, представляющий фундаментальные понятия и математические модели, лежащие в основе БД и СУБД, принципы проектирования БД, а также технологии реализации БД и иллюстрирующий вышеуказанные понятия на примере ACCES и MS SQL-Server. Подробное описание: Учебное пособие посвящено важнейшей составляющей широко разрабатываемых и используемых информационных систем организационного управления – базам данных (БД), создаваемым и функционирующим на основе систем управления базами данных (СУБД). Главной целью пособия является формирование концептуальных представлений об основных принципах построения БД и СУБД, принципах проектирования БД, а также анализ основных технологий реализации БД. Особое внимание уделяется представлению фундаментальных понятий и математических моделей, лежащих в основе баз данных и систем управления базами данных. Изучение курса включает усвоение ряда фундаментальных понятий и теоретических основ организации баз данных и систем управления базами данных:
В задачи курса входит изучение процесса проектирования базы данных, включающего:
Рассмотрение указанных вопросов иллюстрируется на примерах конкретных систем управления базами данных – ACCES и MS SQL-Server. Предисловие Последние десятилетия в области программирования характеризуются резким ростом количества создаваемых информационных систем организационного управления. Практически в каждой организации функционирует (или создается) такая система (или её элементы). Важнейшей структурной частью информационных систем являются базы данных, создаваемые и функционирующие на основе использования специализированных программных систем – систем управления базами данных. Все это обусловливает большую потребность в квалифицированных кадрах, способных как создавать информационные системы на основе систем управления базами данных, так и обслуживать соответствующие информационные системы и базы данных. Цель данного учебного пособия состоит в формировании концептуальных представлений об основных принципах построения баз данных, систем управления базами данных; о математических моделях, описывающих базу данных; о принципах проектирования баз данных; а также анализе основных технологий реализации баз данных. Тематика, связанная с базами данных, чрезвычайно широка. Можно указать, в качестве примера, целый ряд возможных семестровых или годовых курсов по соответствующей тематике: введение в базы данных, проектирование баз данных, реляционные базы данных, язык запросов SQL, клиент-серверные системы, работа в среде конкретной СУБД и т. п. В связи с эти невозможно в одном курсе детально раскрыть все стороны этой тематики. В то же время очень важно дать читателю достаточно полное представление об общей структуре тематики баз данных и важнейших понятиях в этой области. Главной задачей настоящей книги является представление читателю фундаментальных понятий, лежащих в основе баз данных и систем управления базами данных, и иллюстрация способов реализации соответствующих понятий в конкретных программных системах. Рассмотрение указанных вопросов иллюстрируется на примерах конкретных систем управления базами данных – ACCES и MS SQL-Server.. Пособие разработано с учетом международных рекомендаций по стандартизации обучения информатике в университетах Computing Curricula 2001 ( совместная раработка Компьютерного общества Института инженеров по электротехнике и электронике (IEEE-CS) и Ассоциации по вычислительной технике (ACM)) и включает, в соответствии с этими рекомендациями, основную совокупность знаний по Управлению информацией (разделы IM2 – IM9). Структура пособия соответствует структуре курса CS270T. «Базы данных» из вышеуказанных рекомендаций. Цель курса: Цель данного курса состоит в формировании концептуальных представлений об основных принципах построения баз данных, систем управления базами данных; о математических моделях, описывающих базу данных; о принципах проектирования баз данных; а также анализе основных технологий реализации баз данных. Главной задачей учебного курса является представление слушателю фундаментальных понятий, лежащих в основе баз данных и систем управления базами данных, и иллюстрация способов реализации соответствующих понятий в конкретных программных системах. В задачи курса входит изучение процесса проектирования базы данных, включающее формализацию описания предметной области, (разработку концептуальной модели и ее специфицирование к конкретной модели данных СУБД. Рассмотрение указанных вопросов иллюстрируется на примерах конкретных систем управления базами данных – ACCES и MS SQL-Server. Предварительные знания Курс «Базы данных» опирается на материалы следующих курсов: Основы построения ЭВМ; ЭВМ и программирование; Дискретная математика. Автор: Швецов Владимир Иванович, доктор технических наук, профессор, проректор по информатизации ГОУ ВПО «Нижегородский государственный университет им. Н.И.Лобачевского». Профессиональные интересы: проектирование и создание баз данных, разработка программных систем обработки данных для конкретных классов задач. Лекция 1. Введение в базы данных. Общая характеристика основных понятий Лекция посвящена рассмотрению развития основных понятий обработки данных, связанного с постоянным расширением классов решаемых на ЭВМ задач. Показывается необходимость интеграции данных при решении неколькими пользователями задач, использующих общие данные. Вводится понятие базы данных. Ключевые термины: представление данных, элемент данных, логическая запись, экземпляр записи, логический файл, интеграция данных, база данных, система управления базами данных, СУБД, функции СУБД. Цель лекции: показать, что с изменением вида решаемых на ЭВМ задач в программировании возникают новые виды представления данных, в том числе такой вид, как базы данных. 1.1. Развитие основных понятий представления данных Любой вычислительный процесс представляет собой отображение (по определенному алгоритму) некоторых входных данных в выходные.  Соотношение сложности представления обрабатываемых данных и алгоритма вычислений определяет два класса задач:
На начальной стадии обучения программированию основное внимание уделяется разработке алгоритма решения задачи. Однако часто оказывается, что возможность (или невозможность) решения конкретной задачи зависит не только от выбранного алгоритма, но и от того, какие понятия используются для представления обрабатываемых данных. Рассмотрим простейший пример вычисления по формуле: где X и Y – определенные числа, которые являются здесь элементарными единицами данных (элементами данных). При программировании алгоритма решения этой задачи (программирование формулы) используется простейший вид данных – простая переменная (XиYпредставляются в программе простыми переменными). Заметим, что простая переменная в системах программирования характеризуется определенным типом ее значений, которые должны выбираться при программировании. Даже в этом простейшем случае необходимо правильно выбрать тип переменной, причем от этого выбора может зависеть возможность или невозможность решения конкретной прикладной задачи (например, для представления конкретных данных не хватит отведенных разрядов). Рассмотрим другой пример: Решение этой задачи в общем случае невозможно получить используя только простые переменные. Здесь обрабатывается не отдельное число, а последовательность чисел. В этом случае при программировании используется такой вид данных, как массив – совокупность элементов, с каждым из которых связан упорядоченный набор целых чисел, называемых индексами. Все элементы должны иметь одинаковый тип их значений, который и будет типом массива. В этом случае числа a1, a2,…, aN представляются в программе массивом A(1), A(2),…, A(N). Приведенные примеры показывают, что изменение вида задач обусловливает необходимость использования других видов данных. Ранние языки программирования (ФОРТРАН, АЛГОЛ-60) были предназначены для решения научно-технических вычислительных задач. В этих языках использовались только вышеуказанные виды данных (простые переменные и массивы) что было вполне достаточно. Начиная с конца 60-х годов компьютеры начинают интенсивно использоваться для решения так называемых невычислительных задач, связанных с обработкой различного рода документов. Рассмотрим появление новых видов данных на примере упрощенных задач обработки данных. Задача 1. Начисление заработной платы. Рассматриваем задачу при двух упрощающих предположениях:
Необходимые для решения этой задачи сведения о сотруднике представлены в следующей карточке НАЧИСЛЕНИЕ:
Для каждого работника начисленная сумма за определенный месяц рассчитывается по следующей формуле: где Kr – количество рабочих дней в данном месяце. Для каждого сотрудника соответствующие данные имеют конкретное значение, например:
Эти значения имеют смысл только во взаимосвязи друг с другом. Отдельно выбранное число 1800 теряет свой содержательный смысл, поэтому использовать такой вид данных, как простая переменная, здесь нельзя. В то же время набор соответствующих значений, характеризующих конкретного сотрудника, имеет разные типы (символьный и числовой), т.е. использовать для его представления такой вид данных, как массив, также нельзя. Таким образом, понятий «простая переменная» и «массив» недостаточно, чтобы представить соответствующую карточку. Для описания аналогичных представлений данных в предметной области невычислительных задач вводится ряд новых понятий [1]. Элемент данных (поле) – наименьшая единица поименованных данных. Для данного примера элементами данных являются FIO, O, Ko, S. Для описания карточки сотрудника используется понятие «Логическая запись». Логическая запись – поименованная совокупность элементов данных (полей). Экземпляр логической записи – текущее значение элементов записи. Для представления всего набора карточек сотрудников используется понятие «Логический файл» Логический файл - поименованная совокупность всех экземпляров записей заданного типа. Пример логического файла НАЧИСЛЕНИЕ:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
Таким образом, с помощью введенных понятий можно описывать соответствующие данные. Для отображения этих понятий в современных языках программирования, предназначенных как для вычислительных задач, так и для задач обработки данных, введены новые виды данных. В алгоритмическом языке Паскаль вводится такой вид данных, как запись (RECORD) – сложная переменная с несколькими компонентами, которые могут иметь разные типы. Кроме того, доступ к компонентам записи (полям) осуществляется не по индексу, а по имени. При программировании задачи 1 на языке Паскаль логическая запись НАЧИСЛЕНИЕ представляется видом данных RECORD, набор экземпляров логических записей сотрудников представляется (логический файл) представляется «физическим» файлом, формируемым средствами языка Паскаль и операционной системы.. Salary = RECORD FIO: string; O: real; Ko: real; S: real; END; Отметим важную специфику таких невычислительных задач. Для этих задач характерны большие объемы данных (большое количество сотрудников, большое количество производимых изделий и т. п.). Указанные данные, как правило, используются для решения задачи многократно (зарплата начисляется постоянно каждый месяц), поэтому данные должны достаточно долго храниться в памяти ЭВМ. Для длительного хранения всегда используется внешняя память. В связи с этим решение задачи 1 состоит из двух этапов. 1. Ввод исходных данных и занесение их во внешнюю память. type Salary = RECORD FIO: string; O: real; Ko: real; S: real; END; FSalary = File of Salary; var F: FSalary; … { Ввод исходных данных } repeat write(‘Введите количество сотрудников (не более’, MaxN,’ ): ’); readln(N); until (N>0) AND (N<=MaxN); For I := 1 to N do Begin Write(‘Введите фамилию сотрудника с номером ’,I,‘: ’); ReadLn(Sotr[i].FIO); Write(‘Введите оклад сотрудника с номером ’, I, ‘: ’); ReadLn(Sotr[i].O); Write(‘Введите кол-во отработанных дней сотрудника с номером ’, I, ‘: ’); ReadLn(Sotr[i].Ko); End; { Занесение данных во внешнюю память } Assign(F, ‘MyFile.fsf’); Rewrite(F); For I := 1 to N do Write(F, Sotr[i]); Close(F); … 2. Чтение исходных данных из внешней памяти, расчет начисленных сумм и вывод на печать. … { Чтение данных из внешней памяти } Assign(F, ‘MyFile.fsf’); Reset(F); For I := 1 to N do Read(F, Sotr[i]); Close(F); { Расчет и печать начисленных сумм } For I := 1 to N do Begin Sotr[i].S := Sotr[i].O * Sotr[i].Ko / Kr; WriteLn(Sotr[i].FIO, ‘: ’, Sotr[i].S); End; … Представленные программы решают поставленную задачу при сделанных предположениях. Необходимые для этого данные хранятся в файле MyFile.fsf, предназначенном только для решения этой задачи. Отметим, что в этом случае описание данных включено в прикладную программу. При изменении формата записей файла необходимо изменение прикладной программы. Таким образом, программная система, решающая поставленную задачу, определяет свои собственные данные и управляет ими. Такие программные системы называются файловыми системами [2], [3]. Задача 2. Учет кадрового состава. Здесь обрабатываются сведения о сотруднике, представленные в карточке СОТРУДНИК:
Решение задачи состоит из следующих этапов: Ввод исходных данных и занесение их во внешнюю память. Чтение исходных данных из внешней памяти с целью удаления, корректировки или добавления записи. … { Чтение данных из внешней памяти } Assign(F, ‘MyFile.fsf’); Reset(F); IsFound := False; For I := 1 to N do Begin Read(F, Sotr); If Sotr.FIO = KeyFio Then Begin IsFound := True; Sotr.D := ‘Начальник отдела’; Seek(F, FilePos(F)-1); Write(F, Sotr); Break; End; If IsFound Then WriteLn(‘Корректировка успешно произведена’) Else WriteLn(‘Сотрудника ’, KeyFio, ‘не обнаружено’); Close(F); … В рассматриваемом случае задача 2 решается независимо от задачи 1. Задача 3. Учет экономии фонда оплаты труда (ФОТ) в связи с болезнью сотрудников. Обрабатываются сведения, представленные записями ЭКОНОМИЯ ФОТ:
Программа решения задачи 3 аналогична программе решения задачи 1. Рассмотрим типичный случай, когда все три вышеуказанные программные системы функционируют в одной организации. Отметим следующие принципиальные эксплуатационные недостатки: Информация дублируется. В трех файлах присутствуют поля FIO, O, что приводит к существенному перерасходу памяти. При внесении изменений (например, изменении фамилии) приходится вносить одно и то же значение несколько раз в разные файлы, что приводит к увеличению затрат машинного времени. Существует потенциальная возможность противоречивости данных (в один файл изменения внесены, в другой – нет). Устранить перечисленные недостатки можно, объединив соответствующие записи и создав единую информационную базу для всех вышеназванных задач. На первый взгляд наиболее естественно объединить все записи в одну, убрав дублирующие поля. Получаем возможный вариант объединения:
Дублирование информации полностью убрано. Расход памяти минимален. Недостатки устранены. Рассмотрим, как в этом случае изменится время решения задач 1–3. Время решения задачи прямо пропорционально объему считываемых из внешней памяти данных. Обозначим Ti, li, Niсоответственно время решения, длину записи, число записей i-й задачи (i = 1, 2, 3) при использовании отдельных файлов для каждой задачи: Ti C* li *Ni, где C – некоторый коэффициент пропорциональности. Обозначим Ri, d, Nсоответственно время решения i-й задачи (i = 1, 2, 3) при использовании файла объединенных записей, длину записи, число записей: Ri C* d* N. Заметим, что N1 = N2 = N,N3 N. Тогда время решения i-й задачи (i = 1, 2) при использовании объединенного файла увеличится в Ri /Ti d/liраз. Для нашего примера время решения задач в зависимости от выбранной длины полей может изменяться в 2–3 раза. Таким образом, платой за исключение дублирования информации является увеличение времени решаемых задач. Заметим, что такое увеличение, как правило, допустимо. Время решения задачи 3 увеличится в R3/T3d*N / l3*N3 раз. Так как для данного примера N3 N, то R3>> T3. Время решения задачи 3 может увеличиться на несколько порядков, что совершенно недопустимо. Рассмотрим другой вариант построения единой информационной базы. Объединим записи задач 1 и 2, запись задачи 3 оставим отдельно. Получим два типа записей:
В этом случае дублирование остается (дублируются поля FIO, O). Но так как N3 N, то общий объем дублирования незначителен. Время решения задачи 1 и 2 в этом случае незначительно возрастет по сравнению с вариантом отдельных файловых систем, время решения задачи 3 такое же, как и в начальном варианте отдельного файла. Такое объединение позволяет значительно уменьшить влияние недостатков и в то же время существенно увеличивает время решения всех задач. Все три задачи можно решать, используя общую информационную базу из двух типов записей. Отметим, что два приведенных типа записей связаны друг с другом по полю FIO (находятся в некотором отношении). Отметим, что приведенные варианты интеграции не исчерпывают все возможные способы интеграции данных для приведенных задач и к вопросу выбора наилучшего варианта вернемся в последующих лекциях. Здесь очень важно, что в этом случае для решения вышеуказанных задач используется некоторый новый вид данных, формируемый на основе интеграции записей. Для описания этого вида данных вводится новое понятие «База данных» [1]. База данных – совокупность экземпляров различных типов записей и отношений между записями и элементами. Базу данных можно определить как совокупность взаимосвязанных хранящихся вместе данных при наличии такой минимальной избыточности, которая допускает их использование оптимальным образом для одного или нескольких приложений. Таким образом, появление понятие «Базы даннах» обусловлено возникновением нового класса невычислительных задач, при решении которых используются общие данные. В качестве основного критерия оптимальности функционирования базы данных,как правило, используются временные характеристики реализации запросов пользователей прикладными программами. Краткие итоги. Рассмотрено развитие основных понятий представления данных. Описаны классические понятия программирования, связанные с данными (переменная, массив) и появление новых понятий программирования (поле, запись, файл) как следствие расширения круга решаемых задач и их отражения в системах программирования. Поставлена задача интегрирования данных при использовании несколькими задачами общих данных. Определено понятие базы данных. Контрольные тесты Задача 1. С чем связано появление новых понятий обработки данных? Вариант 1. С чем связано появление новых понятий обработки данных? с развитием вычислительной техники с развитием операционных систем с повышением квалификации программистов ð+ с расширением круга решаемых на ЭВМ задач Вариант 2. Какие задачи относятся к задачам обработки данных? задачи с большим объемом сложных вычислений ð+ задачи учета кадрового состава организации ð+ задачи бухгалтерского учета решение систем линейных уравнений Вариант 3. Какие новые понятия в представлении данных появились с появлением задач обработки данных? простая переменная массив ð+ запись ð+ поле Задача 2. Что такое логическая запись? Вариант 1. Что является элементом логической записи? простые переменные элементы массива файлы ð+ поля Вариант 2. Что не является элементом логической записи? ð+ простые переменные ð+ элементы массива ð+ файлы поля Вариант 3. Из чего состоит логическая запись? из простых переменных и полей из элементов массива и переменных ð+ из полей из простых переменных Задача 3. Что такое логический файл? Вариант 1. Что такое логический файл? совокупность полей совокупность логических записей ð+ совокупность экземпляров логических записей набор данных во внешней памяти ЭВМ Вариант 2. Из каких составляющих элементов состоит логический файл? из полей из элементов массива ð+ из экземпляров логических записей из переменных Вариант 3. Какие понятия не используются при описании логического файла? экземпляр записи поле логическая запись ð+ массив Задача 4. Какие основные этапы решения задачи обработки организационных документов (обработки данных)? Вариант 1. Из каких основных этапов состоит решение задачи обработки организационных документов (обработки данных)? проведение сложных математических вычислений ð+ занесение данных во внешнюю память ð+ чтение данных из внешней памяти ð+ поиск неооходимых данных Вариант 2. Какие из перечисленных действий не входят в решение задач обработки организационных документов (обработки данных)? ð+ проведение сложных математических вычислений занесение данных во внешнюю память чтение данных из внешней памяти поиск неооходимых данных Вариант 3. Какие основные операции с данными производятся в задачах обработки организационных документов (обработки данных)? ð+ поиск необходимых данных ð+ модификация данных ð+ удаление данных ð+ добавление данных Задача 5. Основные свойства программных систем с отдельными файлами для каждой задачи (файловых систем). Вариант 1. Какие из перечисленных свойств характерны для комплекса программных систем с отдельными файлами для каждой задачи (файловых систем)? ð+ дублирование данных большое время решения каждой задачи высокая достоверность всей совокупности данных ð+ потенциальная противоречивость данных Вариант 2. Какие из перечисленных свойств не характерны для комплекса программных систем с отдельными файлами для каждой задачи (файловых систем)? дублирование данных ð+ большое время решения каждой задачи ð+ высокая достоверность всей совокупности данных потенциальная противоречивость данных Вариант 3. Какие из перечисленных свойств комплекса программных систем с отдельными файлами для каждой задачи (файловых систем) можно устранить объединением (интеграцией) данных? ð+ дублирование данных большое время решения каждой задачи высокая достоверность всей совокупности данных ð+ потенциальная противоречивость данных Задача 6. Как представляются интегрированные данные? Вариант 1. В каком виде представляются интегрированные данные? отдельный файл набор отдельных файлов набор экземпляров записей одного типа ð+ набор экземпляров записей разных типов и связей между ними Вариант 2. В каком виде не представляются интегрированные данные? ð+ отдельный файл набор связанных файлов ð+ набор экземпляров записей одного типа набор экземпляров записей разных типов и связей между ними Вариант 3. Какое понятие из нижеперечисленных является важнейшим при интеграции данных? файл запись экземпляр записи ð+ связь между записями (файлами) Задача 7. Определить понятие базы данных. Вариант 1. Что такое база данных? совокупность экземпляров записи одного типа совокупность экземпляров записей разных типов ð+ совокупность экземпляров записей разных типов и связей (отношений) между ними поименованная совокупность логических записей Вариант 2. Какие понятия соответствуют содержанию понятия базы данных? набор данных для решения отдельной задачи набор отдельных файлов ð+ набор связанных файлов файловая система Вариант 3. Какие понятия не соответствуют содержанию понятия базы данных? ð+ набор данных для решения отдельной задачи ð+ набор отдельных файлов набор связанных файлов ð+ файловая система Задача 8. Отметить основные свойства базы данных. Вариант 1. Отметить основные свойства базы данных. отсутствие дублирования ð+ минимальная избыточность минимальное время решения всех задач ð+ используется для решения ряда задач Вариант 2. Какие из перечисленных свойств характерны для базы данных.? ð+ минимальное дублирование данных ð+ интеграция данных каждая задача решается за минимально возможное время отсутствие дублирования Вариант 3. . Какие из перечисленных свойств не характерны для базы данных?. минимальное дублирование данных интеграция данных ð+ каждая задача решается за минимально возможное время ð+ отсутствие дублирования Литература
Вопросы Вариант 1 Вариант 2 Вариант 3 Литература Лекция 2. Системы управления базами данных Вводится понятие системы управления базами данных (СУБД).Дается характеристика основных функций системы управления базами данных. Ключевые термины: Система управления базами данных, СУБД, банк данных, функции СУБД, транзакции, блокировки Цель лекции: показать необходимость создания программного интерфейса между прикладными программами и базой данных, определить понятие системы управления базами данных и сформулировать основные функции СУБД, вытекающие из задачи взаимодействия многих пользователей с базой данных. В прикладной программе, использующей при решении задачи один или несколько отдельных файлов, за сохранность и достоверность данных отвечал программист, работающий с этой задачей. Использование базы данных предполагает работу с ней нескольких прикладных программ, решающих задачи разных пользователей. Естественно, что за сохранность и достоверность интегрированных данных программист, решающий одну из прикладных задач, отвечать уже не может. Кроме того, расширение круга решаемых с использованием базы данных задач может приводить к появлению новых типов записей и отношений между ними. Такое изменение структуры базы данных не должно вести к изменению множества ранее разработанных и успешно функционирующих прикладных программных систем, работающих с базой данных. С другой стороны, возможное изменение любой из прикладных программ, в свою очередь, не должно приводить к изменению структуры данных. Все вышесказанное обусловливает необходимость отделения данных от прикладных программ. Роль интерфейса между прикладными программами и базой данных, обеспечивающего их независимость, играет программный комплекс – система управления базами данных (СУБД) (рис. 2.1). СУБД – программный комплекс поддержки интегрированной совокупности данных, предназначенный для создания, ведения и использования базы данных многими пользователями (прикладными программами). 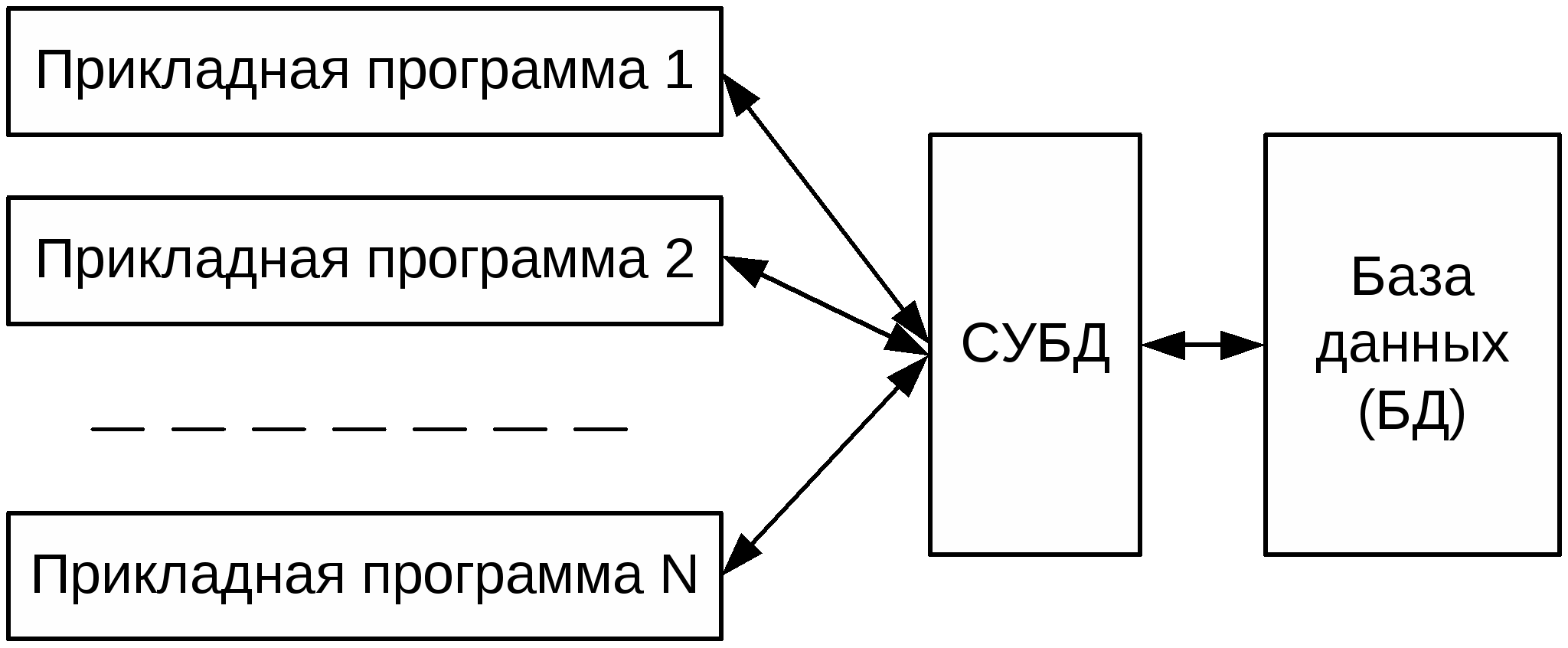 Рис.2.1. Обеспечение независимости прикладных программ и базы данных Определим еще одно понятие. Банк данных – система языковых, алгоритмических, программных, технических и организационных средств поддержки интегрированной совокупности данных, а также сами эти данные, представленные в виде баз данных. Перечислим основные функции системы управления базами данных. 1. Определение структуры создаваемой базы данных, ее инициализация и проведение начальной загрузки. Как правило, создание структуры базы данных происходит в режиме диалога. СУБД последовательно запрашивает у пользователя необходимые данные. В большинстве современных СУБД база данных представляется в виде совокупности таблиц. Рассматриваемая функция позволяет описать и создать в памяти структуру таблицы, провести начальную загрузку данных в таблицы. Примеры таких действий для СУБД MS Access приведены на рисунке 2.2.. 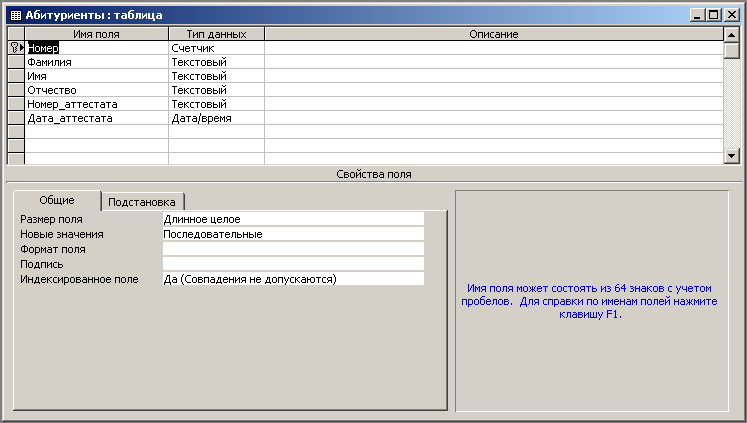 Рис. 2.2. Формирование структуры базы данных в СУБД Access 2. Предоставление пользователям возможности манипулирования данными (выборка необходимых данных, выполнение вычислений, разработка интерфейса ввода/вывода, визуализация). Такие возможности в СУБД представляются либо на основе использования специального языка программирования, входящего в состав СУБД, либо с помощью графического интерфейса. В MS Access реализация данной функции может быть реализована созданием запросов и форм ввода с помощью графического интерфейса (рис.2.3.). 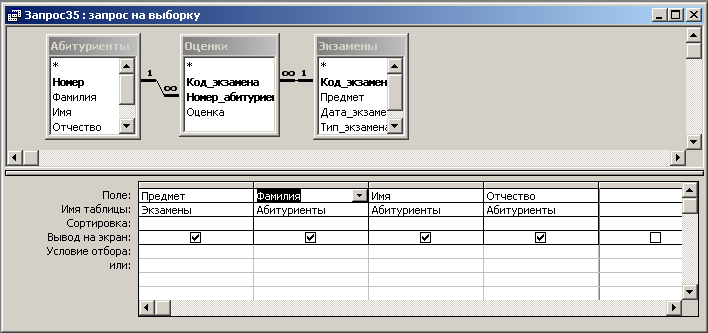 Рис. 2.3. Формирование запроса на выборку в СУБД Access Для клиент-серверных СУБД существуют средства, позволяющие выполнять запросы, и программные средства, позволяющие создавать графический интерфейс пользователя. 3. Обеспечение независимости прикладных программ и данных (3. Обеспечение логической и физической независимости данных.). Важнейшим свойством СУБД является возможность поддерживать два независимых взгляда на базу данных – «взгляд пользователя», воплощаемый в логическом представлении данных, и его отражения в прикладных программах; и «взгляд системы» – физическое представление данных в памяти ЭВМ. Обеспечение логической независимости данных предоставляет возможность изменения (в определенных пределах) логического представления базы данных без необходимости изменения физических структур хранения данных. Таким образом, изменение логического представления данных в прикладных программах не приводит к изменению структур хранения данных. Обеспечение физической независимости данных предоставляет возможность изменять (в определенных пределах) способы организации базы данных в памяти ЭВМ не вызывая необходимости изменения «логического» представления данных. Таким образом, изменение способов организации базы данных не приводит к изменению прикладных программ. |