АРИС Текст 2. Водяхо А. И., Выговский Л. С., Дубенецкий В. А., Цехановский В. В. Архитектурные решения информационных систем
 Скачать 4.65 Mb. Скачать 4.65 Mb.
|

|
3.3. Взаимодействие процессов через сокеты Самым старым способом взаимодействия между элементами распределенных приложений являются сокеты, которые позволяют связывать приложения напрямую, записывая данные в и читая данные из сокета. API для сокетов является низкоуровневым, и предоставляет максимальный контроль над передаваемыми данными. Однако сокеты плохо подходят для работы со сложными структурами данных, особенно если программные компоненты, поэтому разработка сложных приложений с использованием сокетов достаточно проблематична. Работа с сокетами в самом общем виде выглядит следующим образом. Любой процесс может создать серверный сокет и привязать его к какому-нибудь порту. После этого сервер переходит в режим ожидания и ожидает запрос со стороны клиента. Клиент также создает сокет, через который он может взаимодействовать с сервером. Взаимодействие может реализовываться как с установлением соединения, так и без установления соединения. В первом случае в качестве транспорта используется протокол TPC, а во втором – UDP. Механизм работы с сокетами поддерживается практически во всех современных языках программирования. Самую подробную информацию по программированию сокетов можно найти в [31]. 3.4. Вызов удаленных процедур Основная идея механизма сокетов состоит в использовании операций send и receive для обмена данными между процессами, которые выполняются на разных хостах. Основной недостаток сокетов – это сложность программирования, поскольку программирование осуществляется на низком уровне. Идея вызова удаленных процедур состоит в обеспечении возможности программам вызывать процедуры, код которых находится на другом компьютере. Когда процесс, запущенный на компьютере А, вызывает процедуру с компьютера В, вызывающий процесс на компьютере А приостанавливается, а выполнение вызванной процедуры происходит на компьютере В. Информация может быть передана от вызывающего процесса к вызываемой процедуре через параметры и возвращена процессу в виде результата выполнения процедуры. Для программиста вызов удаленной процедуры ничем не отличается от вызова локальной процедуры. Данный метод известен под названием удаленный вызов процедур (Remote Procedure Call, RPC). Использование подпрограмм (процедур) в программе — традиционный способ структурировать задачу и сделать ее более ясной. Обычно подпрограммы собираются в библиотеки. Применительно к локальным вызовам данный подход используется давно и повсеместно. Удаленный вызов процедуры существенным образом отличается от традиционного локального с точки зрения реализации, однако с точки зрения программиста такие отличия практически отсутствуют. В случае локального вызова программа передает параметры в вызываемую процедуру и получает результат работы через стек, то в случае удаленного вызова передача параметров превращается в передачу запроса по сети, а результат выполнения процедуры находится в пришедшем ответе. Если основная программ и реализуемая подпрограмм находятся на компьютерах с разной архитектурой, работающих под управлением различных ОС и написаны на разных языках программирования, то задача корректной реализации удаленного вызова процедур усложняется. Первая проблема состоит в том, что нельзя напрямую передать управление программе, которая работает в другом адресном пространстве. Это можно сделать только с помощью заглушек. Заглушка (stub), которую иногда называют заместителем (proxy), представляет собой фрагмент кода, который несет ответственность за обмен данными. В самом общем виде ситуация выглядит следующим образом. Когда необходимо вызвать удаленную процедуру на вызывающей стороне основная программа обращается к клиентской заглушке, которая связывается с серверной заглушкой и передает ей параметры вызова. Серверная заглушка получает параметры вызова и уже от своего имени вызывает требуемую процедуру. Результаты выполнения передаются серверной заглушке. Получив результаты, серверная заглушка передает их клиентской заглушке, которая, в свою очередь, возвращает их основной программе. Рассмотрим данный процесс более подробно. При описании механизма RPC будем традиционно называть вызывающий процесс — клиентом, а удаленный процесс, реализующий процедуру - сервером. Можно выделить следующие шаги вызова удаленной процедуры. 1. Программа клиент производит локальный вызов процедуры, посредством обращения к заглушке на своей стороне. 2. Заглушка, расположенная на стороне клиента выполняет процесс перекодирования запроса в стандартный формат. Этот процесс называют маршаллингом (marshalling). 3. Заглушка, расположенная на стороне клиента связывается с серверной заглушкой. Задача связывания распадается на две подзадачи: нахождение удаленного компьютера, который может выполнить нужную процедуру; нахождение требуемого серверного процесса на найденном сервере. Обычно эти задачи решаются посредством использования централизованного репозитария, в котором хранится информация об имеющихся сервисах. Данный репозитарий располагается по адресу, который известен всем серверам и клиентам. При запуске сервера он регистрирует свои сервисы в репозитарии, а клиент, когда ему требуется выполнить связывание, обращается к репозитария и считывает информацию о месте нахождения сервиса. После того, как клиент узнал место нахождения сервера, клиентская заглушка связывается через сокет с серверной заглушкой и пересылает ей параметры вызова и обычно переходит в режим ожидания. 4. Получив запрос на выполнение удаленной процедуры, серверная заглушка выполняет операцию демаршаллинга (unmarshalling). Демаршаллинг предполагает выполнение операции обратной операции маршаллинга, т.е. преобразования параметров запроса из сетевого во внутренний формат. 5. Северная заглушка вызывает требуемую процедуру. 6. Процедура выполняется на сервере, результаты выполнения процедуры передаются серверной заглушке. 7. Серверная заглушка выполняет операцию маршаллинга и отправляет результат клиентской заглушке. 8. Получив результат выполнения удаленной процедуры, клиентская заглушка выполняет операция демаршаллинга и передает результат основной программе. При работе с удаленными процедурами параметры передаются по значении. Передача параметров по ссылке не используется. Использование RPC предполагает использование соответствующей среды разработки, которая значительно облегчает процесс программирования, основным из которых является генератор заглушек. Генератор заглушек функционирует следующим образом. На специальном языке описания интерфейсов описываются параметры вызова. Это очень простой непроцедурный язык, который позволяет определить параметры аргументов и результатов. Описание интерфейса, которое представляет собой обычный текстовый файл, обрабатывается с помощью генератора заглушек. На выходе получаем текстовые файлы, в которых содержится код клиентской и серверной заглушек. Обычно это код на языке С. Сгенерированный кок вставляется в программы клиента и сервера и выполняется их компиляция. Если клиент и сервер работают на разных платформах, то процесс генерации выполняется как на серверной, так и на клиентских платформах. Использование RPC существенно облегчает работу прикладного программиста, поскольку ему не требуется иметь дело с сокетами. Приведенное выше описание RPC достаточно поверхностное. Подробное описание можно найти, например в [31]. Идея RPC была предложена и реализована еще в начале 80-х годов прошлого века и достаточно долго и успешно использовалась и продолжает использоваться. Однако RPC имеет существенные недостатки: RPC ориентирован на процедурный стиль программирования, а подавляющее большинство современных приложений – объектно-ориентированные; в рамках RPC реализуются статические вызовы, т.е. заглушки встраиваются в текст, как клиента, так и сервера на этапе разработки. 3.5. Распределенные системы объектов Дальнейшим развитием RPC можно считать Среду распределенных вычислений (DistributedComputingEnvironment, DCE), разработанную организацией OSF (Open Software Foundation), которая позже была переименована в Open Group. DCE изначально она была разработана для использования совместно с ОС UNIX, однако позже был были созданы версии для других ОС. DCE включает ряд сервисов таких как поддержка работы с нитями (Threads), Вызов удаленных процедур и аутентификация, служба времени, служба каталогов, служба безопасности и файловый сервис. Архитектура DCE показана на рис. 3.3. Служба распределенных файлов (distributedfileservice) представляет собой всемирную файловую систему, предоставляющую прозрачные методы доступа к любому файлу системы одинаковым образом. Служба каталогов (directoryservice) используется для отслеживания местонахождения любого из ресурсов системы Служба каталогов позволяет процессу запрашивать ресурсы, не зная, где они находятся, если это не необходимо для процесса. Служба защиты (securitysewice) позволяет защищать ресурсы любого типа, кроме того, получение некоторых данных может быть открыто только тем, кому это разрешено.  Рис. 3.3 Архитектура DCE Служба распределенного времени (distributedtimeservice) предоставляет механизмы синхронизации часов различных хостов. Модель программирования, лежащая в основе всей системы DCE, — это модель клиент-сервер, в которой связь между клиентами и серверами осуществляется посредством использования RPC. В основе своей DCE представляет собой традиционную, основанную на RPC, систему. Время появления DCE совпало с появлением объектно-ориентированных языков и поэтому разработчики были вынуждены ввести поддержку работы с объектами, однако эта поддержка носит достаточно ограниченный характер. Правильным будет считать, что DCE представляет собой «мост» между RPC и системами распределенных объектов. Распределенные объекты были добавлены в DCE в форме расширений языка определения интерфейсов (IDL) вместе с привязкой к языку C++. Другими словами, распределенные объекты в DCE описываются на языке описания интерфейсов и реализуются на C++. Распределенные объекты представляют собой удаленные объекты, реализация которых находится на сервере. Сервер создает объекты C++ и обеспечение доступа к их методам удаленным клиентам. Других способов создания распределенных объектов не существует. В рамках DCE поддерживаются два типа распределенных объектов: динамические распределенные объекты (distributed dynamic objects); именованные распределенные объекты (distributed named objects). Динамические распределенные объекты создаются сервером по требованию клиента и ним имеет доступ только один клиент. Именованные распределенные объекты создаются сервером для совместного использования несколькими клиентами и регистрируются службой каталогов, так что клиент может найти объект и выполнить привязку к нему. За объектом сохраняется уникальный идентификатор.Все обращения к удаленным объектам в DCE производятся средствами RPC. Клиент, обращаясь к методу, передает серверу идентификатор объекта, идентификатор интерфейса, содержащего метод, идентификацию самого метода и параметры. Сервер поддерживает таблицу объектов, с помощью которой он идентифицирует объект, к которому обратился клиент, а затем он выбирает запрошенный метод и передает ему параметры. DCE предоставляет возможность помещать объекты при необходимости во вспомогательное временное хранилище данных. У распределенных объектов в DCE имеется серьезная проблема, связанная с их чрезвычайной близостью с RPC, которая состоит в том, что не существует механизма прозрачных ссылок на объекты. Клиент может использовать только дескриптор привязки (binding handle), ассоциированный с именованным объектом, который может быть преобразован в строку и в таком виде передан другому процессу. Более подробную информацию по DCE можно найти в [23]. Программный интерфейс вызова удаленных методов в языке Java (JavaRemoteMethodInvocation, RMI). В DCE распределенные объекты были добавлены достаточно искусственно в качестве расширения вызовов удаленных процедур. При этом клиент работает со ссылкой на удаленную процедуру для объекта. Фактически ссылки на объекты отсутствуют. В качестве полноценной системы работы с распределенными объектами можно рассматривать программный интерфейс вызова удаленных методов в языке Java (Java Remote Method Invocation (RMI)). В Java распределенные объекты интегрированы с языком. Java поддерживает распределенные объекты в форме удаленных объектов, т.е.объектов, тело которого постоянно находится на одном и том же хосте, а интерфейсы доступны удаленным процессам. Интерфейсы реализованы обычным образом через заглушки, которые предоставляют интерфейсы, идентичные интерфейсам удаленных объектов, при этом заглушка для клиента представляется в виде локального объекта, находящегося в адресном пространстве клиента. В Java между локальными и удаленными объектами существует ряд различий. Во-первых, отличаются механизмы клонирования локальных и удаленных объектов. При клонировании локального объекта создается новый объект такого же типа, что и исходный с таким же состоянии. При клонировании удаленного объекта операция клонирования выполняется только на сервере и приводит к созданию точной копии объекта в адресном пространстве сервера, при этом заместители объекта не клонируется. Поэтому, если клиент на удаленной машине хочет получить доступ к новому объекта на сервере, то необходимо выполнить повторную привязку. Другим различием между локальными и удаленными объектами в Java заключается в семантике блокировки объектов. Для блокировки объекта в Java достаточно объявить один из методов синхронизируемым (synchronized). Если два процесса одновременно вызовут этот метод, то доступ к нему получит только один. Таким образом, можно гарантировать, что доступ к внутренним данным объекта реализуется только последовательно. Java RMI ограничивает блокировку удаленных объектов блокировкой заместителей, т.е. если процессы используют разные заместители, то удаленные объекты невозможно защитить от одновременного доступа процессов. Java в ходе обращений к удаленным методам скрывать большую часть различий между ними, в частности, при работе с RMI в качестве параметров можно передавать любой простой или объектный тип. В терминологии Java это означает, что типы сериализуемы (serializable). Сериализации можно подвергнуть большинство объектов, но не зависящие от платформы объекты, такие как дескрипторы файлов или сокеты. Основным различие между удаленными и локальными объектами состоит в том, что локальные объекты передаются по значению, а удаленные - по ссылке. В Java ссылка на удаленный объект содержит сетевой адрес и конечную точку сервера, а также локальный идентификатор необходимого объекта в адресном пространстве сервера. Удаленный объект состоит из двух различных классов, один из которых содержит реализацию кода сервера и называется классом сервера, а другой класс содержит реализацию кода клиента и называется классом клиента. Класс клиента содержит реализацию заместителя. Таким образом, заместитель обладает всей информацией, необходимой для обращения клиента к методу удаленного объекта. В Java заместители можно сериализовать, подвергнуть маршалингу и переслать в виде набора байтов другому процессу, в котором он может быть подвергнут обратной операции (демаршалингу) и использован для обращения к методам удаленного объекта. Косвенным результатом этого является тот факт, что заместитель может быть использован в качестве ссылки на удаленный объект. В принципе при маршалинге заместителя вся его реализация, то есть его состояние и код, превращаются в последовательность байтов. Маршалинг подобного кода не слишком эффективен и может привести к слишком объемным ссылкам. Поэтому при маршалинге заместителя в Java на самом деле происходит генерация дескриптора реализации, точно определяющего, какие именно классы необходимы для создания заместителя. Возможно, некоторые из этих классов придется предварительно загрузить с удаленного узла. Дескриптор реализации в качестве части ссылки на удаленный объект заменяет передаваемый при маршалинге код. В результате ссылки на удаленные объекты в Java имеют размер порядка нескольких сотен байт. Такой подход к ссылкам на удаленные объекты отличается высокой гибкостью и представляет собой одну из отличительных особенностей RMI в Java. В частности, это позволяет оптимизировать решение под конкретный объект. Так, рассмотрим удаленный объект, состояние которого изменяется только один раз. Мы можем превратить этот объект в настоящий распределенный объект путем копирования в процессе привязки всего его состояния на клиентскую машину. Каждый раз при обращении клиента к методу он работает с локальной копией. Чтобы гарантировать согласованность данных, каждое обращение проверяет, не изменилось ли состояние объекта на сервере, и при необходимости обновляет локальную копию. Таким же образом методы, изменяющие состояние объекта, передаются на сервер. Разработчик удаленного объекта должен разработать только код, необходимый для клиента, и сделать его динамически подгружаемым при присоединении клиента к объекту. Возможность передавать заместителя в виде параметра существует только в том случае, если все процессы работают под управлением одной и той же виртуальной машины. Другими словами, каждый процесс работает в одной и той же среде исполнения. Переданный при маршалинге заместитель просто подвергается демаршалингу на приемной стороне, после чего полученный код заместителя можно выполнять. В противоположность этому в DCE, например, передача заглушек невозможна, поскольку разные процессы могут запускаться в разных средах исполнения, отличающихся языком программирования, операционной системой и аппаратным обеспечением. Вместо этого в DCE производится компоновка (динамическая) с локальной заглушкой, скомпилированной в расчете на среду исполнения конкретного процесса. Путем передачи ссылки на заглушку в виде параметра RPC достигается возможность выхода за границы процесса. Для того чтобы клиент мог найти удаленный объект, на сервере имеется RMI-peecтp (RMI registry), который представляет собой небольшую базу данных, в которой хранится информацию об удаленных объектах, находящихся на этом сервере. Каждый удаленный объект должен быть зарегистрирован в RMI-реестре. RMI-реестр обслуживает процесс демон, который по умолчанию прослушивает порт 1099 и ждет запросы от клиента. RMI-реестр рассматривается как удаленный объект. Кроме того, на сервере создается и хранилище (stub) объекта. 1. Удаленный объект создается на сервере, регистрируется в RMI-реестре и ждет запрос от клиента, прослушивает порт 1099. 2. RMI-реестр прослушивает порт, по умолчанию 1099, и ждет клиента. 3. Клиент, который хочет обратиться к удаленному объекту обращается к RMI-реестру и запрашивает объект по имени. 4. Реестр отыскивает заместителя объекта (stub), и пересылает ее клиенту. В заместителе, в частности, содержится информация местоположении. 5. Заместитель запускается и запрашивает у сервера описание методов удаленного объекта, указав его местоположение. 6. Сервер составляет список сигнатур методов удаленного объекта и отправляет их заместителю. 7. Клиент обращается к методам заместителя так, как будто это собственные методы. 8. Если аргументы метода являются локальные объекты (находятся на стороне клиента), то заместитель выполняет сериализациюи отправляет их на сервер. Если аргументы находятся на сервере, то серверу пересылается ссылка на них. 9. Сервер выполняет десериализацию параметров, передает их методу удаленного объекта, который выполняется. Результат передается заместителю, находящемуся на серверной стороне, который выполняет их сериализацью и отсылает клиенту. RMI может работать не только с реестром RMI, но и использовать службы каталогов, включая Java Naming and Directory Interface (JNDI) [33]. Более подробную информацию о других распределенных системах объектов можно найти в [23]. 3.6. Промежуточное ПО Основное назначения промежуточного ПО (Middleware) состоит в том, чтобы максимально упростить для прикладного программиста задачу создания сложных распределенных приложений. Идея состоит в том, чтобы скрыть от прикладного программиста реальную структуру распределенной системы. Для решения этой задачи поверх сетевой ОС располагается дополнительный слой ПО, который предоставляет прикладному программисту набор сервисов, отличающихся от сервисов, предоставляемых «родной» сетевой ОС (рис. 3.4). 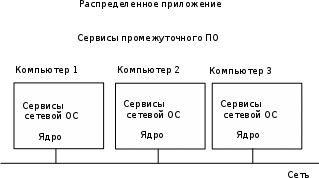 Рис. 3.4. Промежуточное ПО Использование промежуточного ПО избавляет пользователя реализовывать сетевые взаимодействия и позволяет делать программирование независимым от платформы. Имеется достаточно много разновидностей промежуточного ПО. Более подробную информацию о промежуточном ПО можно найти в [23]. 3.7. Распределенные файловые системы Идея распредеделенной файловой системы состоит в том, что один компьютер может работать с файловой системой другого компьютера. Можно выделить 2 основных альтернативных подхода к построения распределенных файловых систем: файл-сервер и монтируемая файловая система. Файл-серверные приложения – приложения, схожие по своей структуре с локальными приложениями и использующие сетевой ресурс для хранения программы и данных. Классическое представление информационной системы в архитектуре "файл-сервер" представлено на рис. 3.5. 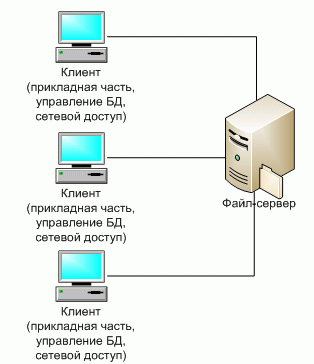 Рис. 3.5. Архитектура "файл-сервер" Организация ИС на основе использования выделенных файл-серверов все еще является распространенной в связи с наличием большого количества персональных компьютеров разного уровня развитости и сравнительной дешевизны связывания PC в локальные сети. Конечно, основным достоинством данной архитектуры является простота организации. Проектировщики и разработчики информационной системы находятся в привычных и комфортных условиях IBM PC в среде MS-DOS, Windows или какого-либо облегченного варианта Windows Server. Имеются удобные и развитые средства разработки графического пользовательского интерфейса, простые в использовании средства разработки систем баз данных и/или СУБД. Достоинства такой архитектуры: многопользовательский режим работы с данными; удобство централизованного управления доступом; низкая стоимость разработки; высокая скорость разработки; невысокая стоимость обновления и изменения ПО. Недостатки: проблемы многопользовательской работы с данными: последовательный доступ, отсутствие гарантии целостности; низкая производительность (зависит от производительности сети, сервера, клиента); плохая возможность подключения новых клиентов; ненадежность системы. Простое, работающее с небольшими объемами информации и рассчитанное на применение в однопользовательском режиме, файл-серверное приложение можно спроектировать, разработать и отладить очень быстро. Очень часто для небольшой компании для ведения, например, кадрового учета достаточно иметь изолированную систему, работающую на отдельно стоящем PC. Однако, в уже ненамного более сложных случаях (например, при организации информационной системы поддержки проекта, выполняемого группой) файл-серверные архитектуры становятся недостаточными. Монтируемые файловые системы можно рассматривать как реализацию файл-серверного подхода в Р2Р системах. Идея монтируемой файловой системы состоит в том, каждый компьютер, работающий в сети может разрешить другим пользователям работать с частью своей файловой системы. Для этого выполняется операция экспорта. После этого данный фрагмент доступен для монтирования другим компьютером. Каждый из компьютеров может, как импортировать фрагменты своей файловой системы, так и монтировать. Широкое распространение данный подход получил в Unix системах. Дополнительную подробную информацию по распределенным файловым системам можно найти в [23]. 3.8. Классические клиент-серверные архитектуры Архитектура "клиент-сервер" (Client-server) – вычислительная или сетевая архитектура, в которой задания или сетевая нагрузка распределены между поставщиками услуг (сервисов), называемых серверами, и заказчиками услуг, называемых клиентами. Нередко клиенты и серверы взаимодействуют через компьютерную сеть и могут быть как различными физическими устройствами, так и программным обеспечением. Первоначально системы такого уровня базировались на классической двухуровневой клиент-серверной архитектуре (Two-tier architecture). Под клиент-серверным приложением в этом случае понимается информационная система, основанная на использовании серверов баз данных. Схематически такую архитектуру можно представить, как показано на рис. 3.6. 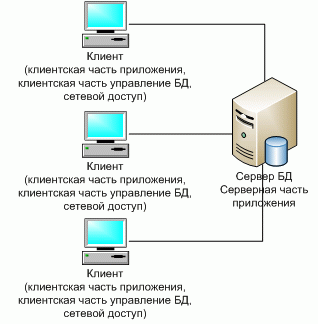 Рис. 3.6. Архитектура "клиент-сервер" На стороне клиента выполняется код приложения, в который обязательно входят компоненты, поддерживающие интерфейс с конечным пользователем, производящие отчеты, выполняющие другие специфичные для приложения функции. Клиентская часть приложения взаимодействует с клиентской частью программного обеспечения управления базами данных, которая, фактически, является индивидуальным представителем СУБД для приложения. Заметим, что интерфейс между клиентской частью приложения и клиентской частью сервера баз данных, как правило, основан на использовании языка SQL. Поэтому такие функции, как, например, предварительная обработка форм, предназначенных для запросов к базе данных, или формирование результирующих отчетов выполняются в коде приложения. Наконец, клиентская часть сервера баз данных, используя средства сетевого доступа, обращается к серверу баз данных, передавая ему текст оператора языка SQL. Посмотрим теперь, что же происходит на стороне сервера баз данных. В продуктах практически всех компаний сервер получает от клиента текст оператора на языке SQL. Сервер производит компиляцию полученного оператора. Далее (если компиляция завершилась успешно) происходит выполнение оператора. Разработчики и пользователи информационных систем, основанных на архитектуре "клиент-сервер", часто бывают неудовлетворены постоянно существующими сетевыми накладными расходами, которые следуют из потребности обращаться от клиента к серверу с каждым очередным запросом. На практике распространена ситуация, когда для эффективной работы отдельной клиентской составляющей информационной системы в действительности требуется только небольшая часть общей базы данных. Это приводит к идее поддержки локального кэша общей базы данных на стороне каждого клиента. Фактически, концепция локального кэширования базы данных является частным случаем концепции реплицированных баз данных. Как и в общем случае, для поддержки локального кэша базы данных программное обеспечение рабочих станций должно содержать компонент управления базами данных – упрощенный вариант сервера баз данных, который, например, может не обеспечивать многопользовательский режим доступа. Отдельной проблемой является обеспечение согласованности (когерентности) кэшей и общей базы данных. Здесь возможны различные решения – от автоматической поддержки согласованности за счет средств базового программного обеспечения управления базами данных до полного перекладывания этой задачи на прикладной уровень. Преимуществами данной архитектуры являются: возможность, в большинстве случаев, распределить функции вычислительной системы между несколькими независимыми компьютерами в сети; все данные хранятся на сервере, который, как правило, защищен гораздо лучше большинства клиентов, а также на сервере проще обеспечить контроль полномочий, чтобы разрешать доступ к данным только клиентам с соответствующими правами доступа; поддержка многопользовательской работы; гарантия целостности данных. Недостатки: неработоспособность сервера может сделать неработоспособной всю вычислительную сеть; администрирование данной системы требует квалифицированного профессионала; высокая стоимость оборудования; бизнес логика приложений осталась в клиентском ПО. При проектировании информационной системы, основанной на архитектуре "клиент-сервер", большее внимание следует обращать на грамотность общих решений. Технические средства пилотной версии могут быть минимальными (например, в качестве аппаратной основы сервера баз данных может использоваться одна из рабочих станций). После создания пилотной версии нужно провести дополнительную исследовательскую работу, чтобы выяснить узкие места системы. Только после этого необходимо принимать решение о выборе аппаратуры сервера, которая будет использоваться на практике. Увеличение масштабов информационной системы не порождает принципиальных проблем. Обычным решением является замена аппаратуры сервера (и, может быть, аппаратуры рабочих станций, если требуется переход к локальному кэшированию баз данных). В любом случае практически не затрагивается прикладная часть информационной системы. Также данный вид архитектуры называют архитектурой с "толстым" клиентом. |