НавчальнийПосібникРІАС. Вступ етапи проектування бд
 Скачать 255.69 Kb. Скачать 255.69 Kb.
|

1 2 Проектування розподіленої бази данихПри проектування РБД виникають три проблеми:
Фрагментація даних дозволяє розбити один об’єкт, наприклад таблицю, на декілька фрагментів, які можуть зберігатися на різних вузлах мережі. Існує три типи фрагментації таблиць:
Приклад, коли необхідна горизонтальна фрагментація. Компанія веде БД по клієнтах і має філіали в різних областях, причому керівництву потрібна інформація про всіх клієнтів, а філіалам тільки про локальних клієнтів. Тоді таблиця customer фрагментується по областям. Приклад, коли необхідна вертикальна фрагментація. Компанія має два підрозділи: відділ обслуговування і відділ прийому платежів, які містяться в різних будинках, яким потрібна інформація тільки по деяким атрибутам таблиці customer . Тоді після вертикальної фрагментації фрагмент відділу обслуговування буде мати атрибути, наприклад, номер клієнта, імя, і адресу, а фрагмент відділу прийому платежів номер клієнта, баланс і рейтинг клієнта. Реплікація даних пов'язана із зберіганням копій даних в мережі на декількох вузлах, призначених для операцій з даними. Оскільки копії фрагментів підвищують рівень доступності даних і зменшують рівень відгуку, реплікація допоможе зменшити загальні витрати на комунікації при виконанні запитів. Наприклад, можливий сценарій, коли розподілена і реплікована БД розміщена таким чином: фрагмент А1 зберігається на сайтах S1 i S2, а A2 на S2 i S3: 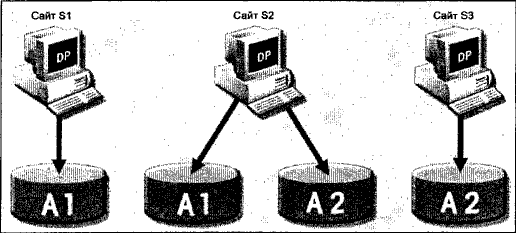 Можливі три варіанти реплікації БД:
На реплікацію БД впливають декілька факторів:
Якщо частота звернень до віддалених даних висока, а БД велика, то реплікація даних може зменшити затрати на обробку запитів (зменшити навантаження на мережу і підвищити швидкість обробки запитів). Функція реплікації включається в багатьох сучасних СУБД. Наприклад, в СУБД Oracle, так створюється локальна репліка з інформацією про ціни із віддаленої таблиці PRODUCTS: CREATE SNAPSHOT PRODPRICE AS SELECT MFR_ID, PRODUCT_ID, PRICE FROM PRODUCTS@REMOUTE_LINK Створюється локальна таблиця PRODPRICE, яка складається із трьох колонок, які задані в інструкції SELECT, що вибирають дані із віддаленої БД. Символи @ REMOUTE_LINK говорить, що таблиця PRODUCTS є віддаленою і доступна через канал зв'язку REMOUTE_LINK. Цей канал створюється і налаштовується адміністратором БД. Лабораторна робота №1. Microsoft SQL Server. Основні пройоми роботи, SQL-запити і представлення. Організація транзакцій. Завдання на лабораторну роботу. Завдання виконується на Microsoft SQL Server. Розробити структуру даних для даного варіанту і привести її у третю нормальну форму. Впровадити створену структуру у вигляді таблиць на сервері. Створити індекси пошуку по двом ключовим стовпцям таблиці зв’язку. Створити діаграму, яка відображає структуру створеної бази даних і її зв’язки. За допомогою програми MS SQL Server Management Studio виконати з’єднання з сервером, знайти свою базу даних, і заповнити таблиці даними, використовуючи інструкцію INSERT. Провести виправлення деяких рядків, видалити декілька рядків, проглянути результати. Експериментуючи із інструкціями “BEGIN TRAN”, “COMMIT”, “ROLLBACK” упевнитися, що сервер не зберігає результати операцій, якщо не була виконана інструкція “COMMIT”. Використовувати інструкції INSERT, DELETE, UPDATE, SELECT. Створити представлення за своїм варіантом за необхідності додавши необхідні дані в базу, якщо потрібно змінивши її структуру. За допомогою інструкції SELECT вивести необхідну інформацію із представлення.
Лабораторна робота №2. Microsoft SQL Server. Збережені процедури, тригери. Завдання на лабораторну роботу. Написати і перевірити на практиці збережені процедури згідно зі своїм завданням для таблиць в базі даних. Розробити тригери INSERT/UPDATE/DELETE для перевірки складних обмежень, що накладаються на схему предметної області. Відповісти на питання викладача. Зручно спочатку перевірити на практиці сам текст процедури, як послідовності інструкцій в консолі MS SQL Server Management Studio, а потім відіслати її на сервер власне як збережену процедуру. Варіанти завдань для збережених процедур (дані передаються в процедуру через параметри).
3. Web-додаток. Робота виконується у середовищі веб-сервера Apache на мові програмування PHP або іншої, та СУБД MS SQL Server. Вивід потрібно робити у форматі HTML. Створити скрипт, який буде під'єднуватись до системного джерела даних ODBC, створеного на основі БД (із лаб. 2), та читати із вказаної таблиці всі записи. 4. Розподілена база даних. Фрагментація БД Реалізувати гомогенну розподілену БД (із лаб. 2) шляхом горизонтальної фрагментації таблиць і розміщення фрагментів на двох СУБД MS SQL Server. Зв'язати два сервера MS SQL Server. Вдосконалити процесор транзакцій та процесор даних, реалізувавши функціональність додавання оновлення та видалення записів таблиць РБД. СУРБД повинна мати архітектуру клієнт-сервер із бізнес логікою на сервері, реалізованою за допомогою збережених процедур Лабораторна робота №5. Реплікація БД. Базуючись на завданні лабораторної роботи №1, реалізувати гомогенну розподілену БД на двох вузлах комп’ютерної мережі шляхом горизонтальної фрагментації таблиць та реплікації всіх фрагментів БД. Доступ до РБД реалізувати через веб-інтерфейс на мові PHP, або іншій, з можливістю редагувати, додавати та видаляти записи локальних фрагментів та перегляду віддалених фрагментів таблиць РБД. В якості процесорів даних використати СУБД MySQL. Порядок виконання лабораторної роботи
[якщо в масиві $row[$i] замість [] записати ():$row($i), то виникає помилка « Fatal error. Function name must be a string in…»]. Примітки до виконання.
Якщо два sql-сервера працюють на одній машині, то необхідно сконфігурувати їх на різні ТСР-порти, наприклад 3306 і 3307. Наприклад: локальний sql-сервер на порт 3307, віддалений – 3306 (sql-сервери можуть входити до складу ХАМРР).
У нашому випадку головним сервером буде віддалений сервер, додатковим – локальний сервер. Для налаштування головного сервера спочатку необхідно запустити бінарний журнал оновлень (binary log). Для цього треба у конфігураційному файлі my.ini (my.cnf у випадку linux) розкоментувати рядок log-bin = mysql-bin. Далі, в тому самому файлі у секції [mysqld] вказати унікальний ID сервера та ім’я БД для реплікації: server-id = 1 replicate-do-db = books (необхідно достатньо місця на диску для бін.журналів). Далі треба додати користувача replication, під правами якого буде виконуватися реплікація, і надати йому привілей «replication slave»: grant replication slave on *.* to «replication» @ «127.0.0.1» identified by «password» (краще це зробити у Navicat). Перевантажити сервер і перевірити його роботу: show master status File: mysql-bin.000001 Position: 105 Binlog_Do_DB: Binlog_Ignore_DB: Для налаштування додаткового сервера необхідно в my.ini в секції [mysqld] вказати ID сервера, ім’я БД для реплікації і шлях до relay-бінлогам: server-id = 2 relay-log = mysql-relay-bin relay-log-index = mysql-relay-bin.index replicate-do-db = books
Далі переносимо дані з головного на допоміжний сервер. Для цього спочатку заблокуємо БД для запису і якщо таблиці MyISAM робимо також flush tables: flush tables rbith read lock; set global read_only = on; Запам’ятаємо значення File I Position: show master status File: mysql-bin: 000001 Position: 105 Робимо дамп БД і після завершення операції знімаємо блокування головного сервера: set global read_only = off; unlock tables; Переносимо дамп на допоміжний сервер і відновлюємо із нього дані. На допоміжному сервері запускаємо реплікацію: change master to master_host = «127.0.0.1», master_user = «replication», master_password = «password», master_log_file = mysql – bin.000001, master_log_pos = 105; start slave; Значення master_log_file і master_log_pos беремо з основного сервера. Переглянути хід реплікації можна за допомогою команди show slave status (можлива помилка «error connecting to master repl@127.0.0.1:3306» - перевірити правильність IP адреси і порти. - файервол - привілеї replication. Спробувати дати всі привілеї) 1 2 |