НавчальнийПосібникРІАС. Вступ етапи проектування бд
 Скачать 255.69 Kb. Скачать 255.69 Kb.
|

1 2 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Назва | Автор | Сторінки | Ціна | Тираж | Телефон | Посада | З/п |
| Microsoft Office | Каменський Ю. Нікітін П. | 224 | 20 | 10 000 | 111-11-11 222-22-22 | Нач. відділу Старший викл. | 5 000 2 000 |
| Visual C++ Т1 | Шевченко Н. Сидоренко А. | 328 | 30 | 5 000 | 333-33-33 444-44-44 | Доцент Ст. викл. | 4 000 2 000 |
| Visual C++ Т2 | Шевченко Н. Сидоренко А. | 355 | 30 | 5 000 | 333-33-33 444-44-44 | Доцент Ст. викл. | 4 000 2 000 |
Ненормалізована таблиця, хоча й зручна для сприйняття людиною, має ряд недоліків, що робить її незручною для розміщення в БД:
Вид елементів таблиці стимулює суперечливість даних. Наприклад, значення Посада Старший викладач в одному місці введена як Старший викл., а в іншому, як Ст. викл.
Надмірність даних приводить до наступних аномалій:
Аномалії відновлення. Наприклад, зміна номера телефону для Шевченко Н. вимагає виконання цієї дії в декількох рядках таблиці.
Аномалії включення. Наприклад, якщо з'ясувалося, що в книги Visual C++ є третій автор, то інформацію про нього необхідно ввести в декількох рядках таблиці.
Аномалії видалення. Наприклад, якщо з'ясувалося, що для книги Visual C++ помилково був уведений інший автор, то необхідно вилучити цього автора з декількох рядків таблиці.
Перша нормальна форма вимагає, щоб таблиця була двовимірною й не містила чарунок, що включають кілька значень.
Приведення таблиці до 1НФ виконується шляхом процесу вставки: Таблицю в 1НФ називають універсальною таблицею, проектованої БД. Якщо число атрибутів у них невелике ( до 15), то вона може використовуватися в якості відправної точки при проектуванні БД.
| Назва | Автор | Сторінки | Ціна | Тираж | Телефон | Посада | Зарплата |
| Microsoft Office Microsoft Office Visual C++ Т1 Visual C++ Т1 Visual C++ Т2 Visual C++ Т2 | Каменський Ю. Нікітін П. Шевченко Н. Сидоренко А. Шевченко Н. Сидоренко А. | 224 224 328 328 355 355 | 20 20 30 30 30 30 | 10 000 10 000 5 000 5 000 5 000 5 000 | 111-11-11 222-22-22 333-33-33 444-44-44 333-33-33 444-44-44 | Нач. відділу Старший преп. Доцент Ст. препід. Доцент Ст. препід. | 5 000 2 000 4 000 2 000 4 000 2 000 |
Первинний ключ, що унікально визначає значення атрибутів таблиці, повинен бути комбінацією атрибутів Назва й Автор.
Визначимо залежності між атрибутами таблиці за допомогою діаграми залежностей:/
Лінії зі стрілками над сутностями вказують усі можливі бажані залежності, тобто залежності, засновані на первинному ключі.
Лінії зі стрілками в нижній частині діаграми вказують на необов'язкові залежності. Є два типи таких залежностей:
Часткова залежність, яка визначається тільки частиною складеного первинного ключа.
Транзитивна залежність – це залежність одного непервинного атрибута від іншого непервинного атрибута.
Говорять, що таблиця наведена по 2НФ, якщо:
Вона наведена до 1НФ;
У ній немає часткових залежностей.
Для перетворення 1НФ в 2НФ необхідно проробити наступне:
Записати кожний ключовий компонент в окремому рядку, а потім в останньому рядку записати вихідний складений ключ:
Назва;
Автор;
Назва Автор;
Кожний компонент стане ключем у новій таблиці. Назвемо ці три таблиці Книги, Автори й Зіставлення.
Після кожного нового ключа записати залежні атрибути:
Книги (Назва, Сторінки, Ціна, Тираж);
Автори (Автор, Телефон, Посада, Зарплата);
Зіставлення (Автор, Назва).
Остання таблиця дозволяє зіставити книги й авторів. Таблиці будуть виглядати в такий спосіб:
Книги:
| Назва | Сторінки | Ціна | Тираж |
| Microsoft Office Visual C++ Т1 Visual C++ Т2 | 224 328 355 | 20 30 30 | 10 000 5 000 5 000 |
Автори:
| Автор | Телефон | Посада | Зарплата |
| Каменський Ю. Нікітін П. Шевченко Н. Сидоренко А. | 111-11-11 222-22-22 333-33-33 444-44-44 | Нач. відділу Старший преп. Доцент Ст. препід. | 5 000 2 000 4 000 2 000 |
Зіставлення:
| Автор | Назва |
| Каменський Ю. Нікітін П. Шевченко Н. Шевченко Н. Сидоренко А. Сидоренко А. | Microsoft Office Microsoft Office Visual C++ Т1 Visual C++ Т2 Visual C++ Т1 Visual C++ Т2 |
Говорять, що таблиця наведена до 3НФ, якщо:
Вона наведена до 2НФ;
У ній відсутні транзитивні залежності.
Для перетворення 2НФ в 3НФ необхідно винести фрагмент таблиці із залежністю в окрему таблицю. Однак атрибут, від якого виходить транзитивна залежність, повинен залишатися у вихідній таблиці в якості зовнішнього ключа, щоб встановити зв'язок між вихідною таблицею й створеною.
У нашому прикладі після перетворення повинне бути чотири таблиці:
Книги (Назва, Сторінки, Ціна, Тираж);
Автори (Автор, Телефон, Посада);
Зіставлення (Автор, Назва);
Посади (Посада, Зарплата).
Автори: Посади:
| Автор | Телефон | Посада | |
| Каменський Ю. Нікітін П. Шевченко Н. Сидоренко А. | 111-11-11 222-22-22 333-33-33 444-44-44 | Нач. відділу Старший преп. Доцент Ст. препід. | |
| Посада | Зарплата | ||
| Нач. відділу Доцент Старший преп. | 5 000 4 000 2 000 | ||
Установити зв'язки між таблицями й задати обмеження цілісності даних цих таблиць.
Існує 3 типу зв'язків між таблицями:
«один до одного» - кожному запису однієї таблиці відповідає тільки один запис в іншій.
«один до багатьох» - кожному запису однієї таблиці може відповідати кілька записів в іншій таблиці
« багато до багатьох» - множині записів в одній таблиці відповідає множина записів в іншій таблиці.
При визначенні зв'язку, первинний ключ в одній таблиці містить посилання на записи в іншій таблиці. Поле, що не є ключовим для даної таблиці, але значення якого є значеннями первинного ключа іншої таблиці, називається зовнішнім ключем. У нашому прикладі між таблицями встановилися наступні відносини:
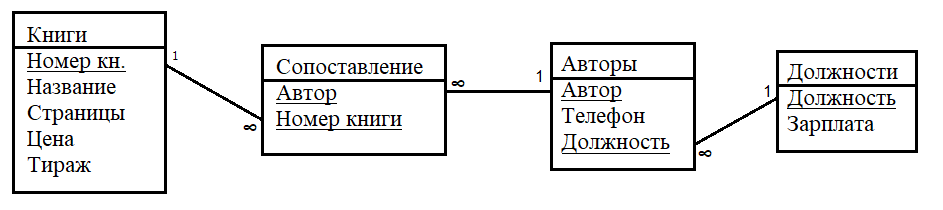
Книги й Зіставлення – один до багатьох;
Автори й Зіставлення – один до багатьох;
Посади й автори – один до багатьох;
Книги й Автори – багато до багатьох.
Зверніть увагу, що в таблиці Книги був уведений новий атрибут – Номер книги, який став первинним ключем замість атрибута Назва. Тепер навіть якщо зустрінуться дві різні книги з однаковою назвою, це не приведе до порушення цілісності таблиці на рівні сутності, тому що номера книг є унікальними.
ТРАНЗАКЦІЇ
Поняття транзакції. Неявні і явні транзакції
Транзакція - логічна одиниця роботи в базі даних а так само одиниця відновлення інформації при збої СУБД. При фіксації змін у базі даних гарантується збереження або всіх змін, або жодного. Більше того, виконуються всі правила й перевірки, що забезпечують цілісність даних.
Транзакції бази даних мають властивості, скорочено називані ACID (Atomicity, Consistency, Isolation, Durability).
Неподільність (Atomicity). Транзакція або виконується повністю, або не виконується.
узгодженість (Consistency). Транзакція переводить базу даних з одного узгодженого стану в інший.
Ізольованість (Isolation). Результати транзакції стають доступні для інших транзакцій тільки після її фіксації.
Тривалість (Durability). Після фіксації транзакції зміни стають постійними.
Усі команди, виконувані користувачами на сервері, проводяться в тілі транзакцій. Однак існує два підходи до вказівки границь транзакцій у потоці команд - явні й неявні транзакції.
Явні транзакції. За замовчуванням, кожна команда виконується як окрема транзакція. Користувач може об'єднати кілька команд в одну транзакцію, явно вказавши її початок і кінець. В MS SQL Server за замовчуванням виконуються явні транзакції.
Неявні транзакції. Не існує оператора початку транзакції. Транзакція починається з початком сеансу роботи із БД. Завершується транзакція при наступних подіях:
Явно виконаний оператор завершення транзакції - rollback або commit
Оператор DDL
Завершення сеансу.
Після закінчення транзакції відразу неявно починається нова транзакція.
Рівні ізольованості транзакцій.
Проблеми організації паралельної роботи:
Проблема загубленого відновлення.

Проблема залежності від незафіксованих результатів.
Неузгоджена обробка даних
Відповідно визначають чотири сценарії взаємовпливу декількох транзакцій з погляду обробки тих самих даних.
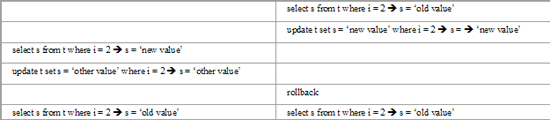
Брудне читання (dirty read). Допускається читання незафіксованих ("брудних") даних. При цьому порушується як цілісність даних, так і вимоги зовнішнього ключа, а вимоги унікальності ігноруються.
Неповторюваність при читанні (non-repeatable READ). Це означає, що якщо рядок читається в момент часу T1, а потім перечитується в момент часу T2, то за цей період вона може змінитися. Рядок може зникнути, може бути оновлена і так далі.
Читання фантомів (phantom read). Це означає, що якщо виконати запит у момент часу T1, а потім виконати його повторно в момент часу Т2, у базі даних можуть з'явитися додаткові рядки, що впливають на результати. Від неповторюваності при читанні це явище відрізняється тим, що прочитані дані не змінилися, але критеріям запиту стало задовольняти більше даних, чому колись.
Уводиться чотири рівні ізольованості транзакцій, що характеризуються ступенем взаємовпливу декількох транзакцій, що обробляють ті самі дані.

В MS SQL Server за замовчуванням рівень ізольованості транзакцій READ COMMITED. Його можна змінити за допомогою оператора Set:
Set Transaction Isolation Level Serializable
Оператори керування транзакціями
BEGIN TRAN[SACTION]
COMMIT (COMMIT WORK). Оператор COMMIT завершує транзакцію й робить будь-які виконані в ній зміни постійною (тривалими). У розподілених транзакціях використовуються розширення оператора COMMIT. Ці розширення дозволяють позначити оператор COMMIT (точніше, позначити транзакцію), задавши для нього коментар, а також примусово зафіксувати сумнівну розподілену транзакцію.
ROLLBACK (ROLLBACK WORK). Простий оператор відкоту завершує транзакцію й скасовує всі виконані в ній і незафіксовані зміни. Для цього він читає інформацію із сегментів відкоту й відновлює блоки даних у стан, у якому вони перебували до початку транзакції.
SAVEPOINT. Оператор SAVEPOINT дозволяє створити в транзакції "мітку", або крапку збереження. В одній транзакції можна виконувати оператор SAVEPOINT кілька раз, установлюючи кілька крапок збереження.
ROLLBACK TO <крапка збереження>. Цей оператор використовується разом із представленим вище оператором SAVEPOINT. Транзакцію можна відкотити до зазначеної крапки збереження, не скасовуючи всі зроблені до неї зміни.
SET TRANSACTION. Цей оператор дозволяє встановлювати атрибути транзакції, такі як рівень ізольованості й те, чи буде вона використовуватися тільки для читання даних або для читання й запису. Цей оператор також дозволяє прив'язати транзакцію до певного сегмента відкоту.
операції читання даних. Дозволяється читання даних іншою транзакцією, але заборонена зміна даних.
Exclusive Lock - монопольне блокування, яке застосовується при зміні даних. Це блокування повністю забороняє доступ до даних іншими транзакціями.
Update Lock - блокування відновлення, яке є проміжною між поділюваним і монопольним блокуванням. Використовується, коли транзакція прагне обновити дані в якийсь найближчий момент часу, але не зараз, і, коли цей момент прийде, не прагне очікувати іншої транзакції. У цьому випадку іншим транзакціям дозволяється встановлювати поділювані блокування, але не дозволяє встановлювати монопольні.
Відкати транзакцій
Відкати можуть віббуватися у двох формах: автоматичний відкат, який виконується SQL-сервером і програмований відкат.
Автоматичні відкати виконуються в наступних випадках;
Збій транзакції внаслідок серйозної помилки, такої як втрата мережного з’єднання або відмова клієнтського додатку або комп’ютера.
Відкат при відновленні SQL-сервера . Наприклад, якщо відключилося джерело живлення під час виконання транзакції. Під час перезавантаження системи SQL-сервер виконає автоматичне відновлення.
Якщо при виконанні якого-небуть оператора виникає помилка, така як порушення обмеження, то за умовчуванням SQL-сервер виконує відкат тільки до оператора, в якому виникла помилка. Щоб виконувався відкат всієї транзакції необхідно виконати оператор : SET XACT_ABORT ON
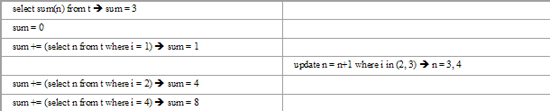
Програмований відкат виконується за допомогою оператора ROLLBACK. Наприклад, збільшення зарплатні для посади «доцент» до 5500 грн. У випадку, якщо зарплатня доцента більна ніж 6000 грн, то відбувається відкат транзакції.
USE books
BEGIN TRAN “D_TRAN”
IF EXISTS(SELECT “зарплатня” FROM “посади” WHERE “посада”=’доцент’ AND “зарплатня”<6000)
BEGIN
UPDATE “посади” SET “зарплатня”=5500 WHERE “посада”=’доцент’
COMMIT TRAN “D_TRAN”
END
ELSE
ROLLBACK TRAN “D_TRAN”
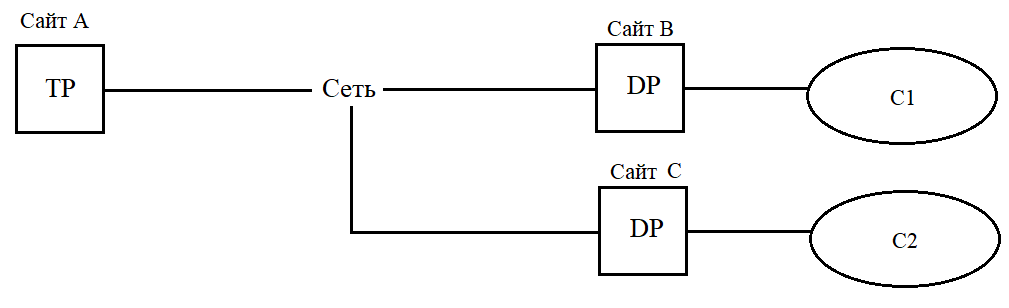
Поняття розподіленої бази даних
Під розподіленою (Distributed DataBase - DDB) звичайно розуміють базу даних, декомпозовану й фрагментовану на кілька вузлів обчислювальної мережі, з можливим керуванням різними СУБД.
Вузол 1
Вузол 2
Вузол 3
СУБД
СУБД
СУБД
Е1
Е2
Е3
Мережеві комунікації
Конфігурація прикладу розподіленої бази даних (РБД).
Е1, Е2 і Е3 – фрагменти РБД. Користувачі не зобов’язані знати імена і місцезнаходження кожного фрагменту для доступу до бази даних. З кожного вузла вони отримують доступ до БД як до логічно єдиної структури.
Етапи розвитку систем управління розподіленими базами даних.
Система управління розподіленою базою даних (СУРБД) керує зберіганням і обробкою логічно зв’язаних даних за допомогою взаємопов’язаних комп’ютерних систем, в яких як дані так і функції обробки даних розподілені по декільком вузлам.
В 70-х роках минулого століття корпорації використовували для обробки інформації централізовані СУБД. Доступ до даних відбувався через неінтелектуальні термінали.
В 1980 роки відбулися значні зміни в соціально-економічній та технологічній сферах, які вплинули на розробку БД:
- географічна децентралізація бізнес-операцій;
- зростання конкуренції в глобальних масштабах;
- зросли потреби ринку і запити користувачів, які віддавали перевагу децентралізованим системам управління;
- швидкий розвиток технологій, які привели до створення недорогих мікрокомп’ютерних систем, які використовували локальні обчислювальні мережі.
В 1990 роки до цих факторів додалися ще:
- зростаюче визнання Інтернету та служби WWW як платформи для доступа до даних і їх розповсюдження.
- підвищена увага до аналізу даних, що призвело до появи специфічних технологій аналізу інформації в БД (data mining) і створенню великих сховищ даних (data warehouse).
До всіх цих факторів додалися і проблеми централізованих баз даних:
погіршення продуктивності через зростаючу кількість місць, віддалених на великі відстані;
- висока вартість, пов’язана з обслуговуванням і підтримкою центральної бази даних, розміщеної на мейнфреймі;
недостатня надійність, пов’язана з залежністю від центрального вузла.
Ці фактори, а також недоліки централізованих БД призвели до появи розподілених баз даних, які керуються СУРБД.
Правила К. Дейта для розподілених баз даних.
К. Дейт - відомий фахівець в галузі реляційних баз даних, працював з Едгаром Коддом, який створив реляційну модель даних.
Правила Дейта грають важливу роль у розробці РБД, хоча жодна із сучасних РБД не відповідає усім цим правилам.
Незалежність локального вузла. Кожен локальний вузол може діяти як незалежна , автономна централізована БД.
Незалежність від центрального вузла. Жоден вузол в мережі не залежить від центрального, або якого-небудь іншого вузла.
Незалежність від збоїв. Функціонування системи не залежить від збою на будь-якому вузлі.
Прозорість місцезнаходження. Користувач не зобов’язаний знати місцезнаходження даних, щоб робити їх пошук.
Прозорість фрагментації. Користувач бачить перед собою єдину логічну БД, в незалежності від того, на скільки фрагментів розбита БД.
Прозорість реплікації. Зміни даних переносяться між базами даних засобами, які невидимі для користувача РБД.
Обробка розподілених запитів. Можливість виконання операцій вибірки над розподіленою базою даних, за допомогою звичайного запиту на мові SQL.
Обробка розподілених транзакцій.
Незалежність від обладнання. Система повинна виконуватися на будь-якій апаратній платформі.
Незалежність від операційної системи.
Незалежність від мережі. Система повинна виконуватися на будь-якій мережевій платформі.
Незалежність від бази даних. Система повинна підтримувати будь-яку базу даних.
Література: Роберт Виейра «Програмування баз даних Microsoft SQL Server 2005»; Пітер Роб, Карлос Коронел «Системи баз даних: проектування, реалізація й керування»
Компоненти СУРБД
У склад СУРБД повинні входити наступні компоненти:
- комп'ютерні робочі станції (сайти або вузли), які формують мережеву систему.
- Компоненти мережевого устаткування і програмного забезпечення кожної робочої станції (комп'ютери, операційні системи, мережі і т. д.). Вони дозволяють вузлам взаємодіяти одне з одним.
- Комунікаційні пристрої, які переносять дані з однієї робочої станції на іншу.
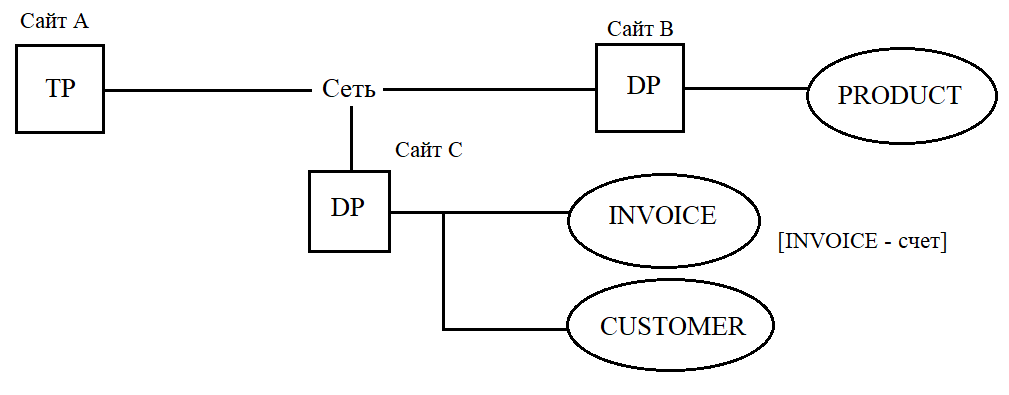
- Процесор транзакцій (TP), який являє собою програмний компонент, який знаходиться на кожному комп'ютері, де виконується запит даних. Процесор транзакцій отримує і обробляє дані запиту додатку (віддалені і локальні) (процесор додатків або менеджер транзакцій). В термінах архітектури клієнт-сервер процесор транзакцій буде клієнтом.
- Процесор даних (DP), являє собою програмний компонент, розміщений на кожному комп'ютері, де зберігаються і вибираються дані. В термінах архітектури клієнт-сервер процесор даних буде сервером.
В конкретних реалізаціях в якості процесора транзакцій може бути, наприклад, програмний компонент, написаний на будь-якій сучасні мові програмування – С++, Delphi, Java, C#, PHP і т.д. В якості процесора даних, може бути Microsoft SQL Server, MySQL, Microsoft Access, Visual Fox Pro та інші СУБД.
Компоненти СУРБД можуть розміщуватись, наприклад, таким чином:
Узел 1
Узел 2
Узел 3
Узел 4
Узел 5
Узел 6
TP
TP
TP
TP
DP
DP
DP
DP
Мережеві комунікації
Процесор даних і процесор транзакцій можна додавати в систему, не діючи на інші її компоненти. TP і DP можуть розміщуватись на одному вузлі, дозволяючи користувачеві отримувати доступ до локальних і віддалених даних, не піклуючись про іх місцезнаходженні.
Логічна модель РБД
Логічна модель РБД будується на 3-х рівнях (шарах) абстракції даних: подання інформації, обробки ( бізнес-логіки) і зберігання. Шари утворять строгу ієрархію: шар бізнес -логіки взаємодіє із шарами зберігання й подання. Фізично, шари можуть входити до складу одного програмного модуля, або ж розподілятися на декількох паралельних процесах в одному або декількох вузлах мережі.
Шар подання інформації
Забезпечує інтерфейс із користувачем. Як правило, одержання інформації від користувача відбувається за допомогою різних форм. А видача результатів запитів - за допомогою звітів.
Шар бізнес-логіки
Сполучний, саме він визначає функціональність і працездатність системи в цілому. Блоки програмного коду розподілені по мережі й можуть використовуватися багаторазово (CORBA, DCOM) для створення складних розподілених додатків.
Шар зберігання даних
Забезпечує фізичне зберігання, додавання, модифікацію й вибірку даних. На даний шар також покладає перевірка цілісності й несуперечності даних, а також реалізацію розділених транзакцій.
Шари розподіленої системи можуть бути по різному реалізовані й виконуватися в різних вузлах мережі. Звичайно розглядаються наступної архітектури
| Шар \ Тип архітектури | Файл-Сервер | Клієнт-Сервер (Бізнес-логіка на клієнті) | Клієнт-Сервер (бізнес-логіка на сервері) | N-Уровневая архітектура |
| Подання | Клієнт | Клієнт | Клієнт | Клієнт |
| Бізнес- логіки | Клієнт | Клієнт | Сервер БД | Сервер додатків (комп. кластер) |
| Зберігання | Файл-Сервер (або клієнт) Всі три шари утворять єдиний програмний модуль | Сервер БД Корист. інтерфейс і бізнес-логіка утворять єдиний модуль. Дані зберігаються на сервері БД | Сервер БД Вся бізнес логіка реалізований у вигляді збережених процедур, що виконуються на сервері БД | Сервер БД Всі шари виконуються на різних машинах. |
Файл-Сервер
У системах, побудованих по архітектурі файл-сервера всі шари системи представляють єдине й неподільне ціле. БД зберігається у вигляді файлу або набору файлів на файлі-сервері. Вся логіка вибірки, зберігання й забезпечення несуперечності даних покладає на клієнтську частину. Файл-Серверні системи орієнтовані на роботу з окремими записами в таблиці.
Переваги
Простота логіки.
Низькі вимоги до апаратного забезпечення й малий обсяг необхідної пам'яті.
Не вимагають надійних багатозадачних і багатокористувальницьких ОС.
Невисока ціна СУБД.
Недоліки
Обмеженість мови й негнучкість середовища розробки додатків
Слабка масштабованість
Не забезпечують багатокористувальницький режим роботи
Важко підтримувати цілісність і несуперечність даних
Необхідність ручного блокування записів або таблиць цілком.
Низький рівень захищеності як зовнішньої (від злому), так і внутрішньої (від помилок додатків) Наприклад індекси окремо від таблиць.
Не мають засобів шифрування мережного трафіка
Створюють високе навантаження на мережу
Висновки
Файл-Серверна архітектура є досить привабливою альтернативою для створення однокористувальницьких інформаційних систем зі слабкими вимогами до захисту даних.
Клієнт-Сервер з бізнесом-логікою на клієнті
У даних системах зберігання, вибірка й підтримка несуперечності даних покладає на сервер БД, а вся бізнес-логіка й логіка подання виконуються на клієнтських машинах. Тому що всі операції по маніпулюванню даними здійснюються тільки через сервер, продуктивність і схоронність даних залежить тільки від сервера БД. Сервери БД споконвічно розраховані на багатокористувальницький режим роботи, мають ефективні алгоритми кешировання даних. Сучасні сервери мають гарну масштабованість.
Клієнтська частина обмінюється даними із сервером за допомогою SQL запитів. Обробка інформації в клієнт-серверних системах ведеться на рівні безлічі кортежів.
Процес розробки розділяється на створення БД і написання клієнтської частини з бізнесом-логікою.
Переваги
Висока продуктивність, стабільність і надійність при багатокористувальницькій роботі.
Легко організується захист даних (шифрування мережного трафіка SSH, SSL)
Універсальність мови визначення й маніпулювання даними
Недоліки
Більше висока ціна СУБД. (сервер БД продається окремо).
Досить високі вимоги до кваліфікації розроблювачів
Навички адміністрування сервера БД
Підвищені вимоги до пропускної здатності мережі
Підвищені вимоги до клієнтських місць (на них виконується шар бізнес- логіки)
Висновки
При кількості користувачів від 2 до 50 вона є гарним варіантом. З ростом числа користувачів починає позначатися недостатня пропускна здатність мережі.
Клієнт-Сервер з бізнесом-логікою на сервері
Використовується можливість сучасних серверів БД виконувати збережені SQL процедури на сервері, куди й переноситься максимально можлива частина бізнесу-логіки. Вимоги до сервера БД зростають, однак різко знижуються вимоги до клієнтських машин (за рахунок виносу з них бізнес-логіки) і до пропускної здатності мережі (клієнтові передаються тільки дані, необхідні користувачеві).
Переваги
Знижені, у порівнянні з попереднім класом систем, вимоги до пропускної здатності мережі й клієнтських місць.
Більш простий процес створення бізнес-логіки.
Недоліки
Підвищені вимоги до сервера БД.(кожний сеанс "з'їдає" пам'ять із розрахунку граничного завантаження)
Невисока переносимість (мобільність) системи на інші сервери БД.
Висновки
У порівнянні з попередніми класами, дозволяє тримати більше навантаження.
N-рівнева архітектура
Основними елементами є сервера БД, сервер(кластер) додатків і клієнтська частина. Головна ідея n-рівневої архітектури полягає в максимальному спрощенні клієнта (тонкий клієнт) , виносі всієї бізнес-логіки із клієнта й сервера БД.
Тонкий клієнт являє собою деякий термінал типу HTML-browser або емулятори X-Термінала
Вся бізнес- логіка оформляється у вигляді набору додатків, що запускаються на сервері додатків під керуванням ОС типу UNIX.
Сервера БД займаються тільки проблемами зберігання, додавання, модифікації й підтримки несуперечності даних.
Сервер додатків з'єднаний із сервером БД за допомогою окремого високошвидкісного сегмента мережі.
Переваги
Підвищена захищеність.
Висока продуктивність.
Легкість розвитку й модифікації.
Легкість адміністрування.
Можливість створення системи з масовим паралелізмом (серверів БД може бути трохи, а сервером додатків можуть служити трохи з'єднаних у кластер комп'ютерів).
Недоліки
Висока складність.
Висока ціна рішення.
У деяких випадках уступає по продуктивності клієнт-серверним системам з бізнес-логікою на сервері.
Висновки
Єдина альтернатива для створення ІС для дуже великої кількості користувачів.
Прозорі властивості розподіленої БД
Система РБД має цілий ряд функціональних характеристик, які можна назвати прозорими (невидимими користувачеві). Прозорі властивості СУРБД дозволяють користувачеві вважати себе монопольним єдиним користувачем системи.
До прозорих властивостей СУРБД відносяться:
Прозорість розподілу.
Прозорість розподілу дозволяє вважати РБД єдиною логічною БД.
Розрізняють три рівні прозорості розподілу:
Прозорість фрагментації. Це незалежний рівень прозорості розподілу. Кінцевий користувач або програміст може нічого не знати про розподіл БД. Тому при доступі до даних не задаються ні ім'я фрагмента, ні його місце розташування.
Наприклад:
SELECT * FROM EMPLOYEE WHERE EMP_DOB < [Date Of Birthday?]
’01-JAN-1970’;
Прозорість місця розташування. У цьому випадку кінцевий користувач або програміст повинен задавати ім'я фрагмента БД, але місце розташування задавати не потрібно:
SELECT * FROM E1 WHERE EMP_DOB < ’01-JAN-1970’;
UNION
SELECT * FROM E2 WHERE EMP_DOB < ’01-JAN-1970’;
Прозорість локального відображення. При цьому необхідно визначати, як ім'я фрагмента ДБ, так і його місце розташування:
SELECT * FROM E1 NODE NY WHERE EMP_DOB < ’01-JAN-1970’;
SELECT * FROM E2 NODE ALT WHERE EMP_DOB < ’01-JAN-1970’;
Прозорість транзакцій.
Прозорість транзакцій гарантує, що всі транзакції БД будуть забезпечувати цілісність і несуперечність РБД.Тобто, транзакція буде завершена тільки в тому випадку, якщо на всіх сайтах БД, залучених у цю транзакцію, будуть завершені всі частини цієї транзакції.
У рамках РБД розрізняють віддалений запит, віддалену транзакцію, розподілену транзакцію й розподілений запит.
Віддалений запит може посилатися на дані, розташовані тільки на одному віддаленому сайті.
Віддалена транзакція, складена з декількох різних локальних і віддалених сайтів DP, хоча кожний запит у рамках транзакції може посилатися тільки на один вилучений сайт DP. Наприклад:
BEFIN TRAN
SELECT * FROM PRODUCT
WHERE PROD_NUM = ‘1010’;
UPDATE CUSTOMER
SET CUS_BALANCE = CSU_BALANCE + 120
WHERE CUS_NUM = ‘100’;
INSERT INTO INVOICE (CUS_NUM, INV_DATE, INV_TOTAL)
VALUES (‘100’, ’15-FEB-2011’, 120.00);
Розподілений запит дозволяє одержувати дані від декількох віддалених сайтів у рамках одного оператора SQL. Наприклад:
SELECT * FROM CUSTOMER WHERE CUS_BALANCE < 250;
Прозорість помилок.
Прозорість помилок гарантує, що система буде продовжувати виконання операцій у випадку несправності якого-небудь вузла. Функції, не виконані через збій вузла, будуть завершені на інших вузлах.
Прозорість продуктивності.
Дозволяє системі функціонувати як централізованої СУБД. Якість роботи системи не повинна погіршуватися через те, що вона працює на різних мережних платформах.
Прозорість гетерогенності.
Прозорість гетерогенності дозволяє поєднувати декілька різних локальних СУБД (реляційних, мережних і ієрархічних) у єдину схему.
Зберігання розподілених даних
У випадку реляційної моделі даних можна виділити три способи зберігання розподілених даних:
Фрагментація – таблиця розділяється на кілька фрагментів, що зберігаються на різних сайтах.
Реплікація – система підтримує множину копій даних, що зберігаються на різних сайтах, для більш швидкого доступу й відмовостійкості.
Комбінування фрагментації й реплікації.
Фрагментація даних
При цьому таблиця розбивається на логічні фрагменти, які можна знову об'єднати за допомогою комбінації операцій об'єднання union і з'єднання join.
Існує три типи стратегій фрагментації даних: горизонтальна, вертикальна й змішана.
Горизонтальна фрагментація. При цьому таблиця підрозділяється на фрагменти кортежів (рядків). Кожний фрагмент зберігається на окремому вузлі й має унікальні рядки. Однак усі унікальні рядки мають однакові атрибути (стовпці).
Приклад горизонтальної фрагментації.
Розглянемо таблицю CUSTOMER компанії XYZ:
| CUS_NUM | CUS_NAME | CUS_ADDR | CUS_STATE | CUS_LIMIT | CUS_BAL | CUS_RAITING |
| 10 11 12 | Sinex, inc Martin Corp NBC Corp | 12 Main St. 3 Cap St. 9 High Ave. | TN FL GA | $ 3,500.00 $ 6,000.00 $ 2,000.00 | $ 2,700.00 $ 1,200.00 $ 350.00 | 3 1 2 |
Припустимо, керівництву компанії XYZ необхідна інформація про клієнтів по всіх трьом штатам, але кожному підрозділу компанії необхідна інформація тільки по своїх локальних клієнтах. Тому було ухвалене рішення розподілити дані по штатах на основі горизонтальної фрагментації:
| Фрагмент: CUST_H1 – місцезнаходження Теннессі Вузол NAS (Nashville) |
| Фрагмент: CUST_H2 – місцезнаходження Джорджія Вузол ATL |
| Фрагмент: CUST_H3 – місцезнаходження Флорида Вузол TAM |
Вертикальна фрагментація. При цьому таблиця розбивається на вертикальні фрагменти, що представляють собою набори атрибутів. Кожний фрагмент має однакова кількість рядків, але містить у собі різні атрибути, що залежать від ключового стовпця.
Наприклад, у компанії є два підрозділи: відділ обслуговування й відділ приймання платежів. Кожний підрозділ розташований в окремому будинку й кожному підрозділу необхідна інформація тільки по декільком атрибутам таблиці CUSTOMER:
Фрагмент CUST_V1 Місце розташування: Обслуговування Вузол 1
-
CUS_NUM
CUS_NAME
CUS_ADDRESS
CUS_STATE
10
11
12
Sinex, inc
Martin Corp
NBC Corp
12 Main St.
3 Cap St.
9 High Ave.
TN
FL
GA
Фрагмент CUST_V2 Місце розташування: Приймання платежів Вузол 2
-
CUS_NUM
CUS_LIMIT
CUS_BAL
CUS_RATING
10
11
12
$ 3,500.00
$ 6,000.00
$ 2,000.00
$ 2,700.00
$ 1,200.00
$ 350.00
3
1
2
Ключовий атрибут CUS_NUM є загальним для обох фрагментів.
Змішана фрагментація. Потрібно, якщо необхідно, щоб дані таблиці були фрагментировані горизонтально, відбиваючи розподіл компанії на місцеві філії, і одночасно в рамках філії дані необхідно фрагментувати вертикально, щоб виділити підрозділи.
Змішана фрагментація проводиться у два етапи: спочатку виконується горизонтальна фрагментація, потім вертикальна.
Розподілені транзакції
Розподілені транзакції можуть одержувати доступ до даних, розміщених на декількох сайтах, тому з більшою ймовірністю можуть привести до суперечливості даних, ніж нерозподілені. Якщо один з DP не зможе записати результат транзакції, то це приведе до суперечливого (неузгодженного) стану БД, оскільки ми не можемо скасувати вже записані дані. Тому для вирішення таких проблем застосовують спеціальні протоколи.
Розподілені транзакції можуть оновлювати дані на декількох різних вузлах комп'ютерної мережі.
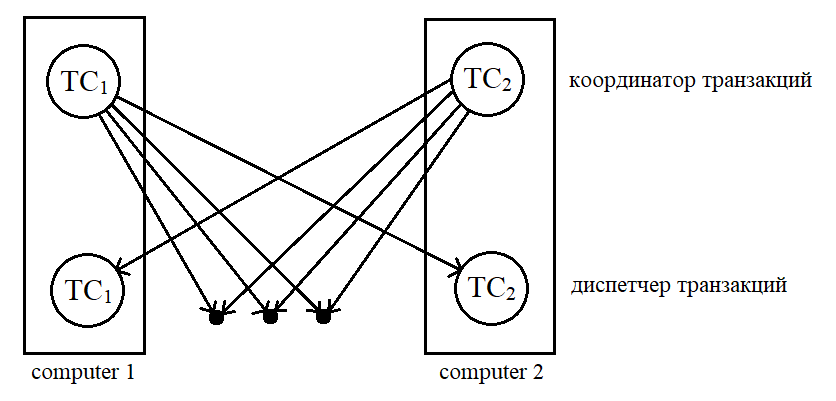
Кожний сайт має локальний диспетчер транзакцій, який відповідає за:
Ведення журналу для цілей відновлення.
Участь в узгодженні паралельного виконання транзакцій, що виконуються на сайті.
Кожний сайт має координатор транзакцій, який відповідає за:
Старт виконання транзакцій, які створюються на сайті.
Розподіл підтранзакцій на призначених сайтах.
Координування завершення кожної транзакції, яка виникла на сайті, що може привести або до завершення цієї транзакції на всіх сайтах, або до скасування транзакції на всіх сайтах.
Види помилок розподілених систем
Розподіленим системам властиві наступні види помилок:
Помилка сайту.
Втрата повідомлень. За надійність передачі повідомлень відповідальні протоколи транспортного рівня, такі як TCP.
Помилка комунікаційного зв'язку. Виправляється мережними протоколами, маршрутизацією повідомлень через альтернативні шляхи.
Поділ мережі. У цьому випадку мережа розділяється на дві підмережі, не з'єднані одна з одною.
Протоколи підтвердження (фіксації) транзакцій
Протоколи підтвердження використовуються для забезпечення атомарності розподілених транзакцій. Транзакція, що виконується на декількох сайтах, повинна або виконатися на всіх цих сайтах, або не виконатися на жодному. Не припустимо, щоб транзакція завершилася на одному сайті й не завершилася на іншому.
Існують:
Протокол двофазного підтвердження транзакції (two-phase commit protocol 2PC).
Протокол трифазного підтвердження транзакції.
2PC протокол
2РС протокол вимагає застосування протоколу DO-UNDO-REDO ( виконати-скасувати-повторити) і протоколу випереджаючого запису.
Протокол DO-UNDO-REDO використовується диспетчером транзакцій для відкату транзакції назад (roll back) або відкату транзакції вперед (roll forward) на основі записів у системному журналі транзакцій. Протокол DO-UNDO-REDO установлює три типи операцій:
DO виконує операцію й записує в журнал транзакцій значення «перед» і «після».
UNDO скасовує операцію з допомоги записів у журналі транзакцій, зроблених операцією DO.
REDO знову виконує скасовану операцію за допомогою записів у журналі, зроблених операцією DO.
Щоб гарантувати, що операції DO, UNDO, REDO зможуть забезпечити коректне виконання операцій при краху системи, використовується протокол випереджаючого запису. Він примушує фіксувати в журналі запис даних для постійного зберігання перед фактичним виконанням цієї операції.
2РС протокол складається з наступних фаз:
Фаза 1. Підготовка.
Координатор посилає повідомлення REPARE TO COMMIT ( підготовка до завершення) усім учасникам транзакції.
Диспетчери транзакцій одержують повідомлення, записують інформацію в журнал транзакцій відповідно до протоколу випереджаючого запису і посилають координаторові повідомлення YES/PREPARED TO COMMIT або NO/NOT PREPARED TO COMMIT.
Координатор переконується, що всі вузли готові до завершення, інакше, скасовує дію: поширює учасникам транзакції повідомлення ABORT.
Фаза 2. Останній оператор COMMIT (фаза фіксації).
Координатор сповіщає всіх учасників, розсилаючи повідомлення COMMIT, і очікує відповіді.
Кожний диспетчер транзакції, одержавши повідомлення COMMIT, обновляє базу даних відповідно до протоколу DO.
Учасники транзакції відповідають координаторові повідомленням COMMITED (завершене) або NOT COMMITED. Якщо один або більш диспетчерів транзакцій не виконали операцію завершення, координатор розсилає повідомлення ABORT і тим самим ініціалізує операцію UNDO.
Недолік – проблема блокування: якщо координатор вийде з ладу перед розсиланням повідомлення COMMIT, учасники транзакції будуть змушено очікувати відновлення координатора для ухвалення подальшого рішення ( тобто завершити або скасувати транзакцію).
На практиці ймовірність блокування досить мале, тому в більшості СУРБД використовується цей протокол.
Протокол трифазного підтвердження транзакції (3РС)
Для використання цього протоколу необхідне виконання наступних умов:
Не повинно бути помилки розподілу мережі;
Принаймні, 1 сайт завжди повинен бути доступний;
Відмовити одночасно може не більше ніж К сайтів;
3РС протокол складається з наступних фаз:
Фаза підготовки (аналогічна 2РС)
Фаза передфіксації (pre-commit):
Координатор сповіщає всіх учасників транзакції, розсилаючи повідомлення precommit, і очікує відповіді;
Учасники транзакції посилають координаторові повідомлення acknowledge (підтвердження);
Якщо координатор одержує всі повідомлення acknowledge від учасників, він переходить до 3 фази. Якщо ж закінчиться таймаут очікування координатора, він розсилає повідомлення ABORT.
Фаза фіксації (аналогічна 2РС)
Основна ідея протоколу полягає в тому, що учасник, що одержав повідомлення про передфіксацію, знає, що всі учасники проголосували за фіксацію результатів транзакції. Тому він надалі може сам ухвалити рішення щодо фіксації транзакції, незважаючи на відмову координатора транзакції.
Недоліки 3РС протоколу:
Більш високі накладні витрати;
Умови для виконання протоколу можуть не виконуватися на практиці.
1 2