Вопросы 6. Задача обеспечения их продолжительного функционирования
 Скачать 60.38 Kb. Скачать 60.38 Kb.
|

|
Назовите основные направления повышения надежности ИС Одной из основных проблем построения ИС остается задача обеспечения их продолжительного функционирования. Главной целью повышения надежности ИС является целостность хранящихся в них данных. Единицей измерения надежности является среднее время наработки на отказ (MTBF - Mean Time Between Failure), иначе - среднее время безотказной работы. Основными направлениями для повышения надежности являются: предотвращение неисправностей обеспечение отказоустойчивости. Дайте определение понятия «отказоустойчивость». Отказоустойчивость — это способность вычислительной системы продолжать действия, заданные программой, после возникновения неисправностей. Каковы причины отказов ИС? По экспертным оценкам причины отказов в ИС выглядят следующим образом: отказы дисков - 27%, отказы сервера или его ядра - 24%, отказы в программах - 22%, отказы в коммуникационном оборудовании - 11%, отказы в каналах передачи данных - 10%, отказы из-за ошибок персонала - 6%. Какая часть ИС является наиболее слабой в смысле отказоустойчивости? Наиболее "слабой" в смысле отказоустойчивости частью компьютерных систем всегда являлись жесткие диски, поскольку они, чуть ли не единственные из составляющих компьютера, имеют механические части. Данные, записанные на жесткий диск доступны только пока доступен жесткий диск, и вопрос заключается не в том, откажет ли этот диск когда-нибудь, а в том, когда он откажет При круглосуточной работе среднее время наработки на отказ может составлять Т=60 000 часов. Тогда Интенсивность отказов составит λ = 1/T=0,000016 1/ч = 0,0000171/ч Пусть на восстановление информации по отказам жёстких дисков тратится 10% годового бюджета времени. Тогда количество рабочих дней tр. д будет равно: tр. д = 365 – 36,5 = 328,5 (рабочих дней), или в часах: tч (l) = 328,5 *24 = 7884 (ч), где tч (1) – количество часов работы винчестера в год. Какие технологии используются для защиты от отказов отдельных дисков? Используются технологии RAID, которые применяют дублирование данных, хранимых на дисках. Акроним RAID (Reudant Array of Independed Disks) избыточный массив независимых дисков, впервые был использован в 1988 году исследователями из института Беркли Паттерсоном (Patterson), Гибсоном (Gibson) и Кацем (Katz). Они описали конфигурацию массива из нескольких недорогих дисков, обеспечивающих высокие показатели по отказоустойчивости и производительности. RAID обеспечивает метод доступа к нескольким жестким дискам, как если бы имелся один большой диск (SLED - single large expensive disk), распределяя информацию и доступ к ней по нескольким дискам, обеспечивая снижение риска потери данных, в случае отказа одного из винчестеров, и увеличивая скорость доступа к ним Что такое репликация данных? Репликация — это процесс создания копий файлов, между которыми может осуществляться обмен обновляемыми данными или объектами. Такие копии называются репликами, а такой обмен — синхронизацией. 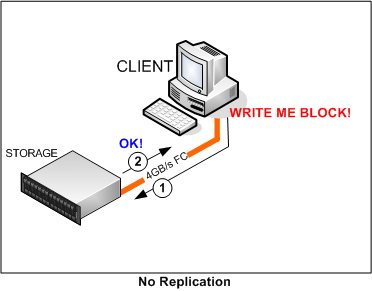 В чем состоят достоинства и недостатки синхронной репликации? Синхронная репликация - это зеркалирование данных на две системы хранения или два дисковых раздела внутри одной системы. Популярный RAID-1 («зеркало») для дисковых контроллеров есть по сути просто синхронная репликация на два диска, выполняемая контроллером диска. При этом каждый блок данных записывается более или менее одновременно, параллельно, на оба устройства. Аналогичным образом это осуществляется на два «диска» в разных дисковых системах хранения. Это «идеальная репликация», обе копии данных полностью идентичны, потому что пока данные не будут гарантированно записаны на оба устройства, оно не может приступить к записи следующего блока Общая скорость системы ограничена самым узким каналом передачи данных. Если мы соединены с системой хранения каналом в 4GB/s, а система хранения синхронно реплицируется на удаленную систему по каналу в 10MB/s, то скорость обмена по каналу 4GB/s будет 10MB/s и ни байтом больше. 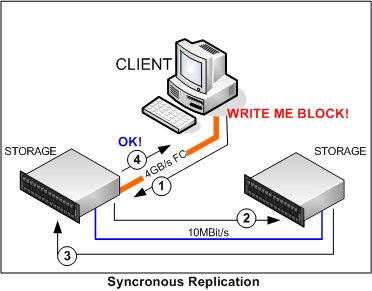 Какую репликацию называют асинхронной? Асинхронной называют репликацию, которая осуществляется не в тот же момент, когда осуществляется запись оригинального блока данных, а в «удобное время». Это позволяет преодолеть вышеописанный недостаток синхронной репликации, поскольку процесс записи данных и процесс их переноса на «реплику» разделены и не связаны больше. Какие информационные системы относят к системам высокой готовности? Предполагается, что конфигурация таких систем обеспечивает ее быстрое восстановление после обнаружения неисправности, для чего в ряде мест используются избыточные аппаратные и программные средства. Длительность задержки, в течение которой программа, отдельный компонент или система простаивает, может находиться в диапазоне от нескольких секунд до нескольких часов, но более часто в диапазоне от 2 до 20 минут. Какова роль кластеров в повышении надежности ИС? Основное назначение кластера, ориентированного на максимальную надежность, состоит в обеспечении высокого уровня доступности (иначе - уровня готовности) и удобства администрирования по сравнению с разрозненным набором компьютеров или серверов. Кластеры должны быть нечувствительны к одиночным отказам компонентов (как аппаратных, так и программных); в общем случае при отказе какого-либо узла сетевые сервисы или приложения автоматически переносятся на другие узлы. При восстановлении работоспособности отказавшего узла приложения могут быть перенесены на него обратно. Назовите современные методы кластеризации. Современные методы кластеризации, уменьшают расходы и улучшают готовность, обеспечивая максимальную эффективность работы центров обработки данных: Ассиметричная кластеризация Симметричная Кластеризация N+1. В чем состоят преимущества кластеризации N+1? низкие затраты: В традиционном кластере активный/пассивный для обеспечения этого уровня готовности потребовалось бы 8 серверов. Используя кластер N+1, мы уменьшим число серверов до 5 при том же уровне готовности. В реальных ценах это выражается следующим образом - если каждый сервер стоит 5000 евро (без учета обслуживания), то, купив на 3 сервера меньше, вы сэкономите 15000 евро нет ухудшения производительности: В кластере N+1 всегда есть выделенный сервер, готовый взять на себя нагрузку вышедшей из строя системы. Это означает, что на каждом сервере выполняется только одно приложение и при переключении нагрузки производительность приложений не уменьшается. Нет проблем из-за усложнения: риск отказа из-за несовместимости программного обеспечения, выполняемого на одной системе, уменьшается, поскольку есть выделенный сервер. экономия времени: Вместо управления четырьмя 2-узловыми кластерами надо управлять одним кластером из 5 узлов, что экономит время и силы администратора. |