ОТЦ. Задание Исследование системы команд и элементов программирования цсп семейства adsp
 Скачать 427.96 Kb. Скачать 427.96 Kb.
|

|
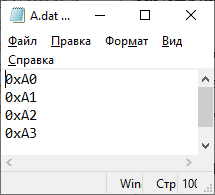
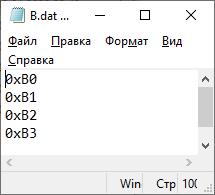
Цель работы: закрепление теоретических знаний об архитектуре и системе команд цифровых сигнальных процессоров (ЦСП) путем их программирования и исследования на ПЭВМ. З а д а н и е 1. Исследование системы команд и элементов программирования ЦСП семейства ADSP Согласно варианту (4) системы ЦОРС, требовалось написать программу, выполняющую вычисления с записью в память. Обобщенное описание инструкции имеет следующий вид: 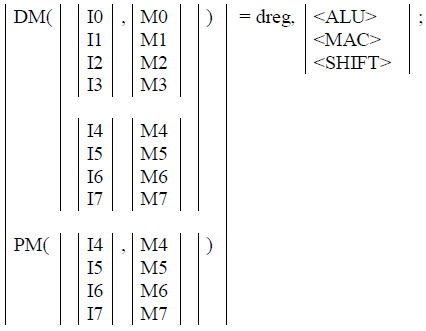 где символ | – разделитель возможных вариантов операндов; Область памяти, в которой будут храниться данные: 1. DM – Data memory; 2. PM – Program Memory; dreg – допустимые регистры данных: 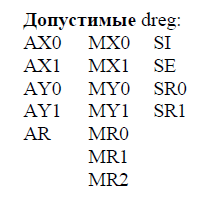 Описание команды: Команда выполняет указанную арифметическую операцию одновременно с пересылкой данного. Операция записи пересылает содержимое регистра источника в память назначения. Содержимое источника записывается в регистр назначения всегда с правым выравниванием. Операция вычисления должна быть безусловной. Допустимы все команды ALU, MAC и SHIFTER кроме команд непосредственных сдвигов, а также команд DIVS и DIVQ. Фундаментальным принципом выполнения многофункциональных команд является то, что регистры (и память) считываются в начале цикла выполнения команда, а записываются в конце. Принятый порядок доступа к регистрам данных вычислительных устройств (сначала считывание, потом запись) позволяет использовать один и тот же регистр в качестве источника для одной операции и приемника для другой. Например, команда DM(I0, M0) = AR; AR = AX0 + AY0; является правильной, причем содержимое АR сначала считывается для записи в память, а затем записывается (загружается) в ходе выполнения арифметической операции. Руководствуясь этим принципом, были созданы файлы A.dat, B.dat (Рисунок 1) массивы значений которых были изначально записаны в память программ (Рисунок 2), далее поданы на устройства АЛУ, а с выхода АЛУ записаны в память данных (Рисунок 3), после чего в выходной файл (Рисунок 4).
Рисунок 1 – Входные массивы 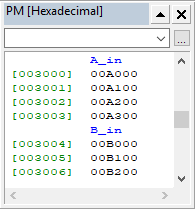 Рисунок 2 – Входные массивы в памяти программ (PM) П р и м е ч а н и е – два нуля справа – ошибка отображения программы 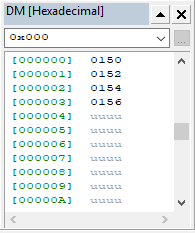 Рисунок 3 – Сумма, записанная в память данных (DM) 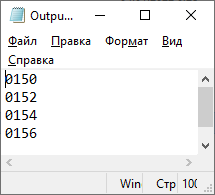 Рисунок 4 – Значения суммы, выведенные в файл Код программы представлен в таблице Таблица 1. Таблица 1 – Код программы 1-го задания
З а д а н и е 2. Программирование и отладка цифровых фильтров на основе ЦСП семейства ADSP Структурная схема биквадратного звена для канонической формы реализации представлена на рисунке Рисунок 5.  Рисунок 5 – Структурная схема биквадратного звена для канонической формы его реализации Такое звено описывается двумя разностными уравнениями: 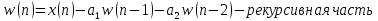 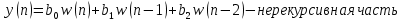 Эти уравнения подобны паре разностных уравнений звена в прямой форме (Рисунок 6), если поменять местами его нерекурсивную и рекурсивную части и обозначения символов. 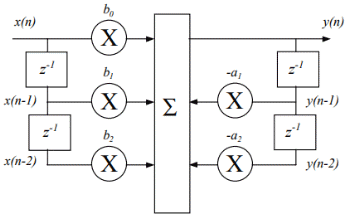 Рисунок 6 – Структурная схема биквадратного звена для прямой формы его реализации Начальные нулевые условия для канонического звена имеют вид 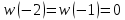 . Они обеспечиваются обнулением сигнальной памяти до начала обработки. После обработки очередного отсчета сигнала осуществляются сдвиг сигнальной памяти. После этого на вход звена может подаваться следующий обрабатываемый отсчет сигнала. . Они обеспечиваются обнулением сигнальной памяти до начала обработки. После обработки очередного отсчета сигнала осуществляются сдвиг сигнальной памяти. После этого на вход звена может подаваться следующий обрабатываемый отсчет сигнала.Предварительно необходимо было синтезировать фильтр в программе РЦФ_СИНТЕЗ, согласно варианту. Коэффициенты синтезируемого фильтра приведены на рисунке Рисунок 7. 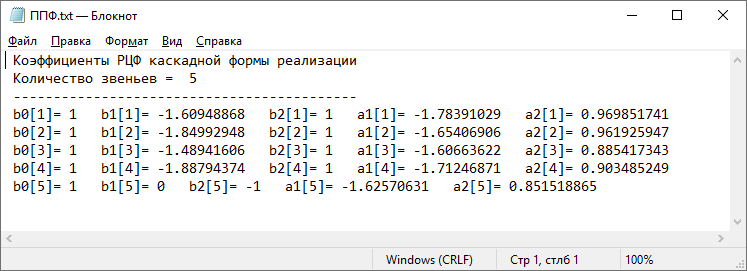 Рисунок 7 – Коэффициенты РЦФ каскадной формы реализации Следующим шагом коэффициенты фильтра были переведены в двоичный дополнительный коде в формате 1.15 (Рисунок 8, третий столбец) и выгружены в файл Coef_hex.dat (Рисунок 9), с которого в дальнейшем и происходило считывание коэффициентов в программе (Таблица 2). 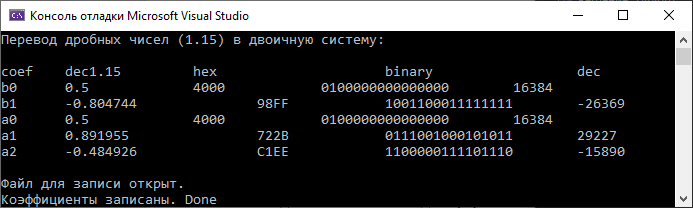 Рисунок 8 – Перевод коэффициентов в дополнительный код формата 1.15 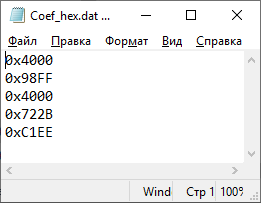 Рисунок 9 – Коэффициенты, записанные в файл Coef_hex.dat На вход РЦФ был подан единичный импульс, сигнал на выходе фильтра представлял из себя – импульсную характеристику. График выходного сигнала РЦФ в среде VisualDSP++ представлен на рисунке Рисунок 10. 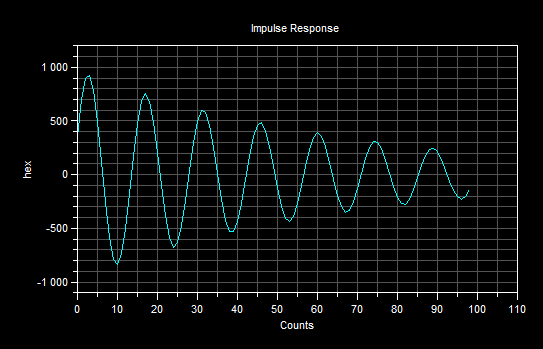 Рисунок 10 – Отклик РЦФ Для проверки правильности реализации РЦФ была собрана схема в SDCAD, на вход которой был также подан единичный импульс (Рисунок 11). 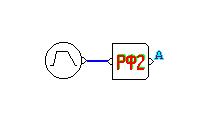 Рисунок 11 – Структурная схема РЦФ в SDCad Отклик РЦФ фильтра среды SDCAD представлен на рисунке Рисунок 12. 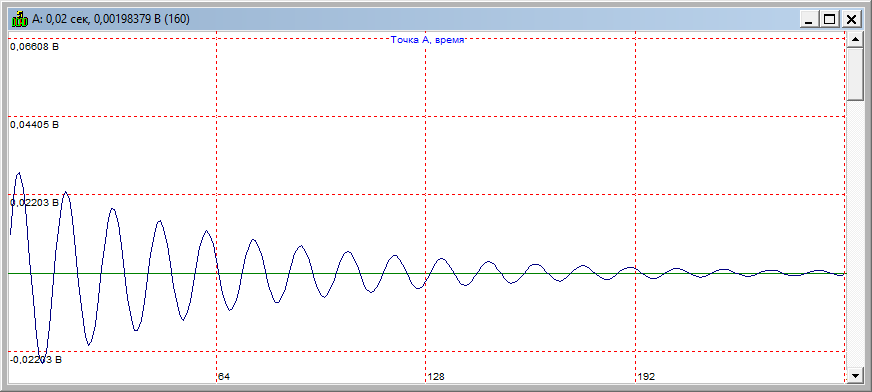 Рисунок 12 – ИХ, синтезированного фильтра в SDCAD Сравнивая Рисунок 10 и Рисунок 12 видно, что фильтр, синтезированный в среде разработки VisualDSP++ и фильтр, синтезированный в среде разработки SDCad идентичны. Код программы представлен в таблице Таблица 2. Таблица 2 – Код программы 2-го задания
Вывод: В ходе лабораторной работы были закреплены знания об архитектуре и системе команд цифровых сигнальных процессоров (ЦСП) путем их программирования и исследования на ПЭВМ. |