Задания по языку программирования R
 Скачать 258.37 Kb. Скачать 258.37 Kb.
|

Задания по языку программирования RЗадания предназначены для формирования простейших навыков в решении задач использования языка R с использованием платформы Rstudio. Большинство задач не имеют прикладной направленности и дифференциации по обучаемым. Однако отдельные задания являются индивидуальными и основаны на использовании индивидуальных наборов данных. Каждый студент может самостоятельно выбрать свой набор данных и решать задачи его исследования. Ниже приведен набор заданий с указанием их номеров и содержания. Построить векторы: Годов, начиная с 2000 года по 2022. 20 целых чисел. Числа начинаются с номера, соответствующего порядковому номеру студента в списке очередности. Месяцев года на русском и английском. Построить матрицу чисел от 1 до 20 с шагом равным 2, используя функцию seq. Изменить второй элемент матрицы на число -5. C помощью функции rep составить список, состоящий из пяти чисел 10. Построить квадратную матрицу размером 4 на 4, содержащую все единицы. Порядок заполнения по строкам. Используя функцию seq, заполнить матрицу 5х5 членами натурального ряда. Порядок заполнения по столбцам. Собрать матрицу из четырех векторов, которые содержат члены натурального ряда, используя функции cbind() (от сolum и bind – столбец и связывать) или rbind() (от row и bind – строка и связывать). В случае необходимости транспонировать полученную матрицу с помощью функции t. Возвести матрицу в квадрат. Найти обратную матрицу. Сложить две квадратные матрицы. Первая матрица получена из первых 25 чисел натурального ряда. Вторая из чисел натурального ряда, начиная с 50. Решить систему алгебраических уравнений матричным методом  Решить систему с помощью функции solve(A, b) Построить таблицу из трех векторов. Первый вектор содержит имя, второй фамилию, третий – год рождения для 10 студентов группы, начиная с себя. Назвать полученную таблицу Student.data. Первый вектор назвать FirstName. Второй LastName. Третий –Year. Для построения таблицы использовать функцию data.frame. Изменить данные второй строки таблицы. Извлечь данные из 1-3 элементов второго столбца. С помощью функции str посмотреть структуру полученной таблицы. Посмотреть начало и конец таблицы с помощью функции head, tail. Набрать аналогичные данные по студентам своей группы в блокноте и импортировать полученные данные в R. Задать квадратную матрицу размером nx5, где n-порядковый номер студента в группе 4х4. С помощью функции seq заполнить ее членами натурального ряда. С помощью функции apply найти минимальные значения в каждой строке и в каждом столбце. Скрипт должен быть по аналогии с представленным С использованием функции array создать массив данных размерностью nх3х4. Задать имена размерностей А1-Аn, В1-В3, С1-С4. В массив поместить числа натурального ряда, начиная с 1. Построить список из чисел от n до 100, используя функцию seq и ключевые слова from, to, by. С помощью функции sapply найти сумму всех элементов списка. Сгенерировать случайную последовательность размером в 500 наблюдений, распределенных по закону распределения, вид которого определен порядковым номером студента в группе.  Параметры закона определить самостоятельно. Например, для нормального закона можно задать математическое ожидание 5, ско 2. Найти оценку математического ожидания, ско, Построить гистограмму распределения. Построить огибающую плотности распределения. Построить ящичную, скрипичную диаграмму. Построить график функции распределения и плотности распределения. Для построения графика плотности и графика функции распределения можно использовать скрипты, подобные указанному x<-pretty(c(-10,10),500) y<-dnorm(x) plot(x,y,type="l")  y1<-pnorm(x) plot(x,y1,type="l") 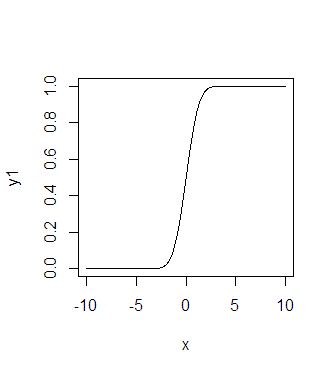 Построение гистограммы hist(n_number,breaks=10,freq=FALSE)  Построение ящичной диаграммы boxplot(n_number,col="coral",horizontal=TRUE) 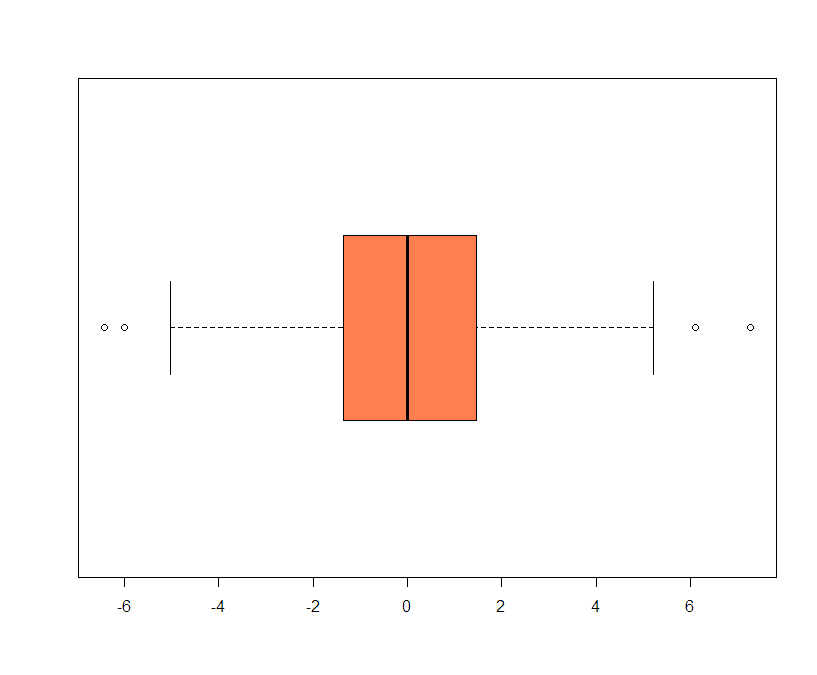 Указанные диаграммы построить с помощью библиотеки ggplot2 Сгенерировать еще две нормально распределенные случайные последовательности с параметрами 6, 2 и 8, 4 соответственно. Построить ящичные диаграммы для трех последовательностей с указанием названий осей, с использованием заливки цветом. Расположить диаграммы горизонтально и вертикально. Оценить выборочные характеристики mean(), median(), var(), sd(), min() , max(), quantile(), IQR(), quantile(,p(= seq(0, 1, 0.1)). Определить выборочные эксцесс и асимметрию. Для этого загрузить библиотеку install.packages("moments"). Рассчитать коэффициенты эксцесса и асимметрии можно, загрузив пакет library(moments) #загрузка пакета moments Для оценки выборочных характеристик использовать функции R kurtosis, skewness. Скачать набор данных из файла Кредит.txt. Пример синтаксиса функции приведен ниже y1 <- read.table("data/sol_y1.txt", header=TRUE, sep="\t", as.is=TRUE, check.names=FALSE, comment.char="", row.names=1). Если используется формат исходного файла csv, то можно использовать функцию: chem <- read.csv(file = "hydro_chem.csv", header = TRUE) Если подлежащий загрузке файл хранится в папке, отличной от рабочей папки R, то следует указать полный путь к нему. При этом пользователям операционной системы Windows необходимо помнить, что для указания полных путей к файлам в программе R используется не обратный одинарный слэш (\), а прямой одинарный (/) либо двойной обратный слеш (\\). Например, следующие две команды будут успешно восприняты R и приведут к идентичному результату – загрузке файла hydro_chem.txt и сохранению его в виде объекта chem: chem <- read.csv(file = "D:\\Documents\\hydrochem.txt", header = TRUE) chem <- read.csv(file = "D:/Documents/hydrochem.txt", header = TRUE) Для интерактивного выбора загружаемого файла, который хранится вне рабочей папки R, можно применить вспомогательную функцию file.choose() (выбрать файл). Выполнение этой команды приводит к открытию обычного диалогового окна операционной системы Windows, в котором пользователь выбирает папку с необходимым файлом. Очень удобно совмещать file.choose() с командами read.table() или read.csv(), например: chem <- read.table(file = file.choose(), header = TRUE, sep = ",") Сохранить результаты в файл. Пример функции приведен ниже write.table(y1, "data/new_y.txt", quote=FALSE, sep="\t", row.names=TRUE, col.names=TRUE) write.table(chem,"c:/Work/ex.txt",col.name=TRUE). Имя файла задать по своему имени Используя datasets cars, исследовать его структуру с помощью функции str. Создать два списка с именами speed, dist. Создать таблицу данных из данного набора данных именами столбцов speed, dist. Найти описательную статистики для каждого столбца таблицы. Построить диаграммы для каждого столбца (plot, hist, boxplot). Найти минимальные элементы в столбцах таблицы. table.cars<-cbind(speed,dist) Использовать библиотеку ggplot2. Для этого вызвать библиотеку library(ggplot2). Построить точечную диаграмму, гистограмму, ящичную диаграмму для данных из набора данных mpg. Для точечной диаграммы использовать данные набора mpg, включающие результаты наблюдений, подготовленных Управлением по защите окружающей среды США для 38 моделей автомобилей. Анализировать переменные displ – объем двигателя в литрах, hwy- расход топлива в милях пробега на галлон топлива. Найти статистические характеристики для одного из dataset, входящего в состав базового пакета datasets. Номер dataset выбрать по порядковому номеру в группе. При определении статистических характеристик выбрать один из признаков (столбцов) набора данных.
Используя библиотеку ggpolt2 провести графический анализ наборов данных. Исследуйте данные, находящиеся в библиотеке ggplot2 из набора данных diamonds. В данном наборе хранятся данные о примерно 54000 алмазов, включая цену, вес, цвет, чистоту и качество огранки каждого из них. При исследовании использовать графические средства, в том числе диаграмму geom_bar/ ggplot(data=diamonds)+geom_bar(mapping=aes(x=cut))  Выполнить графический анализ данных из учебного набора данных о стоимости жилья в Бостоне. Этот набор данных содержит 506 наблюдений, содержащих 14 признаков. Набор данных о ценах на жилье в Бостоне включает прогнозирование цены дома в тысячах долларов с учетом подробностей о доме и его окрестностях. В набор данных входят следующие признаки: CRIM -ПРЕСТУПЛЕНИЕ: уровень преступности на душу населения по городам. ZN: доля жилой земли, зонированной для участков более 25 000 кв. Футов. INDUS - ИНДУС: доля нерелевантных бизнес-акров на город CHAS: фиктивная переменная Чарльз-Ривер (= 1, если тракт ограничивает реку; 0 в противном случае). NOX: концентрация оксидов азота (частей на 10 миллионов). РМ: среднее количество комнат на одно жилище. AGE ВОЗРАСТ: доля домовладельцев, построенных до 1940 года. DIS: взвешенные расстояния до пяти бостонских центров занятости. RAD РАД: индекс доступности к радиальным магистралям. TAX - НАЛОГ: полная стоимость налога на недвижимость за 10 000 долларов США. PTRAYIO - ПТРАТИО: соотношение учеников и учителей по городам. BLACK - B: 1000 (Bk - 0,63) ^ 2, где Bk - доля чернокожих по городам. ISTAT:% ниже статуса населения. MEDV: средняя стоимость домов, занимаемых владельцами, в 1000 долларов (зависимая переменная). Выполнить графический анализ с использованием различных диаграмм. При решении задачи использовать библиотеку ggplot, а также функции plot, hist, boxplot. Номер набора данных определяется порядковым номером студента в группе.
Зарегистрироваться на сайте Kaggle. Загрузить данные об индексе счастья. World Happiness Report 2022. Отметим, что счастье в мире измеряется технологиями, социальными нормами и политикой правительства. Набор данных, созданный решением веб-сканирования. В таблице находятся данные по 153 странам. Показателем счастья считается среднее по стране нескольких факторов. Оценка счастья объясняется следующими факторами: ВВП на душу населения Ожидаемая продолжительность здоровой жизни Социальная поддержка Свобода делать жизненный выбор Щедрость Восприятие коррупции Остаточная ошибка |