с прошлых лет. Использование AllFusion erwin Data Modeler при проектировании баз данных (основные возможности, элементы модели, уровни представления)
 Скачать 314 Kb. Скачать 314 Kb.
|

Возможности: Позволяет создать 2 вида модели: физическая и логическая. Логическая представляет собой абстракт взгляд на данные. Данные представлены как в реальном мире. Нет привязки к СУБД, предназначена для обсуждения и экспертизы. Физическая модель ориентирована на целевую СУБД и представляет собой отображение системного каталога (таблицы, типы данных, ограничения, индексы). ERwin позволяет проводить процессы прямого и обратного проектирования БД. Это означает, что по модели данных можно сгенерировать схему БД или автоматически создать модель данных на основе информации системного каталога Логическая модель Физич модель        Позволяет проводить документирование модели: описание сущности и ее атрибутов, пример запроса, пример кортежа. Различают 2 вида связей: идентифицирующая (между независимой сущностью и зависящей от нее сущностью) и неид-щая. П  ри ид-й связи внеш ключ мигрирует в первичный. При неид связи ключ мигрирует в неключевой атрибут. Связи м.б. 1 ко многим и многие ко многим. Для указания наследования использ связь категоризаций ри ид-й связи внеш ключ мигрирует в первичный. При неид связи ключ мигрирует в неключевой атрибут. Связи м.б. 1 ко многим и многие ко многим. Для указания наследования использ связь категоризаций С   лева – полн, справа неполная. лева – полн, справа неполная.AllFusion Data Model Validator позволяет автоматич анализировать структ БД с целью выяснения ошибок и недочетов, а так же внесения исправлений. Исходн мб: 1.модель ERWIN; 2.БД; 3.Скрипт проекта Oracle Сущности и атрибуты Основные компоненты диаграммы ERwin – это сущности, атрибуты и связи. Каждая сущность является множеством подобных индивидуальных объектов, называемых экземплярами. Каждый экземпляр индивидуален и должен отличаться от всех остальных экземпляров. Атрибут выражает определенное свойство объекта. С точки зрения БД (физическая модель) сущности соответствует таблица, экземпляру сущности – строка в таблице, а атрибуту – колонка таблицы. Построение модели данных предполагает определение сущностей и атрибутов, т.е. необходимо определить, какая информация будет храниться в конкретной сущности или атрибуте. Сущность можно определить как объект, событие или концепцию, информация о которой должна сохраняться. Идентифицирующая связь устанавливается между независимой (родительский конец связи) и зависимой (дочерний конец связи) сущностями. Когда рисуется идентифицирующая связь. ERwin автоматически преобразует дочернюю сущность в зависимую. Экземпляр зависимой сущности определяется только через отношение к родительской сущности. При установлении идентифицирующей связи атрибуты первичного ключа родительской сущности автоматически переносятся в состав первичного ключа дочерней сущности. Эта операция дополнения атрибутов дочерней сущности при создании связи называется миграцией атрибутов. В дочерней сущности новые атрибуты помечаются как внешний ключ – (FK). 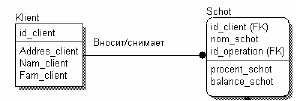 При установлении неидентифицирующей связи дочерняя сущность остается независимой, а атрибуты первичного ключа родительской сущности мигрируют в состав неключевых компонентов родительской сущности. Неидентифицирующая связь служит для связывания независимых сущностей.  Связь многие-ко-многим возможно только на уровне логической модели данных. Такая связь обозначается сплошной линией с двумя точками на концах.  Элементы модели: На логическом уровне:
На физическом уровне:
Моделирование можно производить на разных уровнях. ERwin имеет несколько уровней отображения диаграммы: уровень сущностей, уровень атрибутов, уровень определений, уровень первичных ключей и уровень иконок. Уровни логической модели Различают три уровня логической модели, отличающихся по глубине представления информации о данных: * диаграмма сущность-связь (Entity Relationship Diagram (ERD)); * модель данных, основанная на ключах (Key Based model (KB)); * полная атрибутивная модель (Fully Attributed model (FA)). Диаграмма сущность-связь - представляет собой модель данных верхнего уровня. Она включает сущности и взаимосвязи, отражающие основные бизнес-правила предметной области. Диаграмма сущность-связь может включать связи многие-ко-многим и не включать описание ключей. Модель данных, основанная на ключах - более подробное представление данных. Она включает описание всех сущностей и первичных ключей и предназначена для представления структуры данных и ключей, которые соответствуют предметной области. Полная Атрибутивная модель – наиболее детальное представление структуры данных: представляет данные в третьей нормальной форме и включает все сущности, атрибуты и связи.
Концептуальное (инфологическое) проектирование Концептуальное (инфологическое) проектирование — построение информационной модели наиболее высокого уровня абстракции. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных. Конкретный вид и содержание концептуальной модели базы данных определяется выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобные ER-диаграммам. Чаще всего концептуальная модель базы данных включает в себя: описание информационных объектов, или понятий предметной области и связей между ними. описание ограничений целостности, т.е. требований к допустимым значениям данных и к связям между ними. По сути – тупо словесное описание предметной области. Логическое (даталогическое) проектирование Логическое (даталогическое) проектирование — создание схемы базы данных на основе конкретной модели данных, например, реляционной модели данных. Для реляционной модели данных даталогическая модель — набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи. На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД. Включает в себя
Физическое проектирование Физическое проектирование — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т.п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и т.д. Физическое проектирование обычно завершается генерацией базы в соответствующую целевую СУБД.
AllFusion Data Model Validator позволяет автоматич анализировать структ БД с целью выяснения ошибок и недочетов, а так же внесения исправлений. Инструмент для проверки структуры баз данных и моделей, создаваемых в ERwin Data Modeler. Продукт дополняет функциональность ERwin Data Modeler, автоматизируя трудоемкую задачу поиска и исправления ошибок. - возможность прямой и обратной проверки структур: при помощи продукта можно оптимизировать структуры существующих баз данных или проверять на корректность созданные в AllFusion Data Modeler модели - автоматизирует сложные рутинные функции проверки на ошибки - встроенная система подсказок предлагает варианты исправления выявленных ошибок и методы повышения эффективности баз данных Зачастую инструмент автоматически не исправляет ошибки, а только выдает предупреждение о них. Типовые ошибки: Ошибки и недостатки мод-ния колонок 1.противоречивое определение групп колонок (в таблице оплата1 – number, оплата2 – number, оплата3 – varchar(20)) 2.неправильное или недостаточное моделирование колонок (в одной табл номер города varchar(20), в другой number) 3.таблица не имеет колонок () 4.длина поля больше, чем позволяет СУБД 5.противоречивость значений по умолчанию 6.колонки представляют собой одни и те же данные, но имеют разный тип данных 7.наимен колон совпадает с зарезервированными словами SQL 8. таблица с неуникальными именами колонок Ошибки,связанные с моделир индексов и ограничений 1.атрибуты потенциальных ключей допускают неопределенное значение 2.аномалии в определении индексов(*индекс функционально эквивалентен первичному ключу,*индекс содержит супернабор первичного ключа, *индекс содерж супернабор другого уник индекса) 3.неверно определен альтернативный ключ 4.различные определения ограничения CHECK 5.таблица не имеет уникальных ключей 6.табл не имеет кластеризованных индексов 7.первичн ключ имеет колонку/атрибут с типом «действительное число» 8.ненужные индексы (* индекс, построенный на атрибуте, принимающем одно значение, * индекс, атрибуты которого целиком включены в другой индекс или первичный ключ) 9. ненужный внешний ключ 10. отсутствие индексов Ошибки связей 1.некорректная рекурсивная иерархическая связь 2.неопределенные связи 3.ненужый внешний ключ 4.бесконечные циклы 5.взаимно-пересекающ связи 6.таблица не имеет связей Н.заказа Н.сотрудн Заказы клиенты Н.клиента Н.клиента  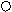 ФИО Подчинен      Not null Not null    6. Концепция и назначение хранилища данных, типовая обобщенная схема. Основные отличия от OLTP-систем Хранилище данных – предметно-ориентированный, интегрированный, привязанный ко времени и неизменяемый набор данных, предназначенный для поддержки принятия решений. Предполагают, что хранилище данных содержит сведения, поступающие из различных источников, а также накапливает и свои данные. Свойства хранилищ данных:
Конечной целью создания хранилища является интегрированных корпоративных данных, обращение к которым с помощью запросов. 
Основные проблемы, связанные с хранилищем данных:
7. Основные способы хранения данных в OLAP-системах: MOLAP, ROLAP, HOLAP. MOLAP (Multidimensional OLAP) –— исходные и агрегатные данные хранятся в многомерной базе данных. Хранение данных в многомерных структурах позволяет манипулировать данными как многомерным массивом, благодаря чему скорость вычисления агрегатных значений одинакова для любого из измерений. Однако в этом случае многомерная база данных оказывается избыточной, так как многомерные данные полностью содержат исходные реляционные данные. Преимущества: 1) высока производительность. 2) структура и интерфейс наилучший образом соответствуют анатомии запросов. 3) в многомерной СУБД легко включать разнообразные встроенные функции. Недостатки: 1) могут работать только под своими СУБД и явл дорогими. 2) по сравнению с реляц неэффективно использует память. 3) имеет менее эффективный механизм обработки транзакций. 4) отсутствует единый стандарт на интерфейс, языки описания и манипуляции данными. 5) не поддерживают репликацию данных ROLAP (Relational OLAP) — исходные данные остаются в той же реляционной базе данных, где они изначально и находились. Агрегатные же данные помещают в специально созданные для их хранения служебные таблицы в той же базе данных. Преимущества: 1) реляц СУБД имеют опыт раб с большими БД, развиты ср-ва администрирования. 2) идеальна в случае изменения размерности задачи, т.к. физическая реорганизация данных не трубуется. 3) обладает более высоким уровнем защиты данных и развитой системой привилегий пользователей. 4) производительность этих систем сравнима с многомерными, если тщательно разработать структуру. Недостатки: 1) ограничены возможно с точки зрения проведения анализа. 2) производительность ниже HOLAP (Hybrid OLAP) — исходные данные остаются в той же реляционной базе данных, где они изначально находились, а агрегатные данные хранятся в многомерной базе данных. 8. Реализация хранилища данных по схеме «звезда». Достоинства и недостатки 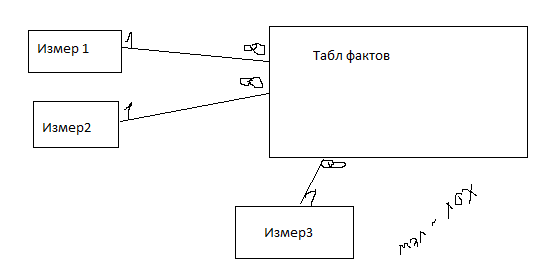 1.Таблица фактов, находится в сильно денормированной форме. Содержит суммированные данные, с помощью которых проводится анализ 2 Таблицы измерений находятся в денормированной форме и содержат описательную информацию. Это позволяет пользователю быстро переход от таблицы фактов к доп инф. Таблица фактов и таблица измерений связаны идентиф связями.  Преимущества: 1) благодаря денормализованной таблице измерений упрощается восприятие структуры данных и формул запросов. 2) ускоряется время выполнения запросов за счет уменьшения операция соединения. 3) в нек. СУБД уменьшается время выборки за счет сокращения времени выполнения запросов. Недостатки: 1) высокая избыточность данных -> дополнительные объемы памяти. 2) если агрегат хранится совместно с исходными данными, необходимо использовать дополнительный параметр - уровни иерархии 9 Реализация хранилища данных по схеме «снежинка». Достоинства и недостатки. таблица фактов тов измер. 1 измер. 3      * 1  * измер. 2 1 Схема снежинки получила свое название за свою форму, в виде которой отображается логическая схема таблиц в многомерной базе данных. Схема снежинки представлена централизованной таблицей фактов, соединенной с таблицами измерений. Здесь таблицы измерений нормализованы с рядом других связанных измерительных таблиц, — в то время как в схеме звезды таблицы измерений полностью денормализованы, и каждое измерение представлено в виде единой таблицы, без соединений на связанные таблицы в схеме снежинки. Чем больше степень нормализации таблиц измерений, тем сложнее выглядит структура схемы снежинки. Создаваемый «эффект снежинки» затрагивает только таблицы измерений, и не применим к таблицам фактов. Достоинства: 1) Экономит ресурсы памяти за счет нормализации таблицы измерений. 2) Т.к. табл нормализована, быстро выполняются запросы, связанные со структурой значений измерений. Недостаток: большое время выполнения запросов, связанных с аналитической обработкой. 10 Концепция и характеристика распределенных баз данных. Правила Дейта. Развитие вычислительных систем способствовало децентрализации БД. В этом случае нужно доставить данные к тому месту, где они наиболее часто исп-ся и дать доступ ко всем данным. Распределенные БД – это набор логически связанных между собой совокупностей данных (и их описаний), которые физически распределены в некоторой комп. сети.  Узел Узел Узел    Клиент Клиент Клиент Клиент Клиент Клиент Клиент           Каждый узел может иметь свою СУБД с БД, но это не обязательно. Узлы взаимосвязаны между собой т.о., что пользователь любого из них может получить доступ к данным в сети т.о., как будто они находятся на его собственном узле. Это является основным принципом распред-й БД. Распр-я БД для пользователя должна выглядеть как нераспр-я. Распр СУБД – программный комплекс, предназначенный для управления распр-й БД и обеспечения прозрачного доступа пользователя к распределенной информации. Пользователь взаимодействует с распр СУБД через приложения ,которые делятся на локальные и глобальные. Глобальные требуют для выполнения доступ к данным, наход-ся в других узлах, а локальные требуют обращения только к своей БД. Правила Дейта:
11 Неоднородные базы данных, проблемы эксплуатации неоднородных баз данных. Возможны однородные и неоднородные распределенные базы данных. В однородном случае каждая локальная база данных управляется одной и той же СУБД. В неоднородных БД фрагменты распределённой БД в разных узлах сети поддерживаются средствами нескольких СУБД. Сетевая интеграция неоднородных баз данных - это актуальная, но очень сложная проблема. Многие решения известны на теоретическом уровне, но пока не удается справиться с главной проблемой - недостаточной эффективностью интегрированных систем. Основной задачей интеграции неоднородных БД является предоставление пользователям глобальной схемы БД, представленной в некоторой модели данных, и автоматическое преобразование операторов манипулирования БД глобального уровня в операторы, понятные соответствующим локальным СУБД. В теоретическом плане проблемы преобразования решены, имеются реализации. При строгой интеграции неоднородных БД локальные системы БД утрачивают свою автономность. После включения локальной БД в федеративную систему все дальнейшие действия с ней, включая администрирование, должны вестись на глобальном уровне. Поскольку пользователи часто не соглашаются утрачивать локальную автономность, желая, тем не менее, иметь возможность работать со всеми локальными СУБД на одном языке и формулировать запросы с одновременным указанием разных локальных БД, развивается направление мульти-БД. В системах мульти-БД не поддерживается глобальная схема интегрированной БД и применяются специальные способы именования для доступа к объектам локальных БД. Как правило, в таких системах на глобальном уровне допускается только выборка данных. Это позволяет сохранить автономность локальных БД. Как правило, интегрировать приходится неоднородные БД, распределенные в вычислительной сети. Это в значительной степени усложняет реализацию. Дополнительно к собственным проблемам интеграции приходится решать все проблемы, присущие распределенным СУБД: управление глобальными транзакциями, сетевую оптимизацию запросов и т.д. Очень трудно добиться эффективности. Как правило, для внешнего представления интегрированных и мульти-БД используется (иногда расширенная) реляционная модель данных. В последнее время все чаще предлагается использовать объектно-ориентированные модели, но на практике пока основой является реляционная модель. Поэтому, в частности, включение в интегрированную систему локальной реляционной СУБД существенно проще и эффективнее, чем включение СУБД, основанной на другой модели данных 12 Распределенные базы данных: способы распределения данных между узлами. РБД состоит из набора узлов, связанных коммуникационной сетью, в которой:
Распределённую систему баз данных можно рассматривать как партнёрство между отдельными локальными СУБД на отдельных локальных узлах. Каталог распред системы: 1.Централизованный катал (весь каталог хранится в одном месте в центр узле) 2.Полноценный репликационный каталог(на каждом узле хранится полный катал) 3.Секционированный (на каждом узле хранится свой собственный системный каталог,а полный сетевой каталог получаем при объединении) 4.Комбинир 1 и 3 (на одном узле хранится полный , на другом свой собственный) Распределение осуществл с помощью фрагментации. Отношения могут быть фрагментированны на вертикальные и горизонтальные разделы. При горизонтальной фрагментации отношение делается с помощью операции селекции или предиката фрагм. При верт - с помощью отношения проекции. 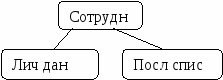 За счет фрагментации данные можно хранить там, где они чаще используются , что позвол снизить время на передачу данных и За счет фрагментации данные можно хранить там, где они чаще используются , что позвол снизить время на передачу данных и уменьшить размнер отношений, тем самым повысив скорость выполн запроса. Репликация заключается в том что создаются дубликаты данных которые поддерживают синхронизацию с нек главной копией. Теоретически все данные в репликационном объекте должны обновляться единовременно, но на практике это не получается. 1.Синхронная Самый высокий уровень надежности Недостат: дополнительная нагрузка при выполнении транзакции, меняющей данные. Проблемы, связанные с доступностью копий. 2.Асинхр – Изменение данных сохраняется только на сервере, где выполняется транзакция. Сервер заботится о передаче данных всем остальным серверам. Обновление спустя некот время. Существует момент времени, когда репликации не идентичны. 3.Репликация по расписанию: В периоды между реплик данные могут расходиться. 13 Механизм выполнения транзакций в распределенных базах данных.Для обработки распределенных транзакций в современных СУБД предусмотрен так называемый протокол двухфазной фиксации транзакций (two-phase commit). Т.е. фиксация распределенной транзакции выполняется в две фазы. Фаза 1 начинается, когда при обработке транзакции встретился оператор COMMIT. Сервер распределенной БД (или компонент СУБД, отвечающий за обработку распределенных транзакций) направляет уведомление подготовиться к фиксации всем серверам локальных БД, выполняющим распределенную транзакцию. Если все серверы приготовились к фиксации (то есть откликнулись на уведомление, и их отклик был получен), сервер распределенной БД принимает решение о фиксации. Серверы локальных БД остаются в состоянии готовности и ожидают от него команды зафиксировать. Если хотя бы один из серверов не откликнулся на уведомление в силу каких-либо причин (аппаратная или программная ошибка), то сервер распределенной БД откатывает локальные транзакции на всех узлах, включая даже те, которые подготовились к фиксации и оповестили его об этом. Фаза 2 - сервер распределенной БД направляет команду зафиксировать всем узлам, затронутым транзакцией, и гарантирует, что транзакции на них будут зафиксированы. Если связь с локальной базой данных потеряна в интервал времени между моментом, когда сервер распределенной БД принимает решение о фиксации транзакции, и моментом, когда сервер локальной БД подчиняется его команде, то сервер распределенной БД продолжает попытки завершить транзакцию, пока связь не будет восстановлена. Подготовка к транзакции заключается в блокировке объектов. В случае отката транзакции, откат производится на каждом сервере на основе журнала транзакций. Обнаружение тупиков осуществляется на каждом узле графа ожидания (двудольный граф, вершины – транзакции и объекты,). Петля – тупик. Если найдена петля, то производится откат той транзакции на которую нужно больше ресурсов. Правила обработки транзакций 1. В процессе выполнения транзакции пользователь (или программа) видит только согласованные состояния базы данных. Пользователь (или программа) никогда не может получить доступ к незафиксированным обновлениям в данных, достигнутым в результате действий другого пользователя (программы). 2. Если две транзакции, A и B, выполняются параллельно, то СУБД полагает, что результат будет такой же, как если бы: - транзакция A выполнялась первой, за ней была бы выполнена транзакция B; - транзакция B выполнялась бы первой, за ней была бы выполнена транзакция A. |