Лабораторная работа 1. Лабораторная работа Разворачивание Hadoop на кластере из одного узла Virtual
 Скачать 320.08 Kb. Скачать 320.08 Kb.
|

|
Лабораторная работа 1. Разворачивание Hadoop на кластере из одного узла (Virtual Box, Ubuntu) ПРИМЕЧАНИЕ: если вы ищите инструкцию по установке системы в параллельном режиме (два и более компьютеров в кластере), то вам сюда. Будем использовать виртуальную машину с платформой виртуализации VirtualBox доступной на Windows, со следующими компонентами: Операционная система: ubuntu - установите её "на виртуалбокс", и создайте общую папку. Рекомендации по созданию общей папки: создадим на компе папку share (например, на диске С:). Подключим её через меню вирутальной машины (предварительно установив дополнения гостевой ОС) - в поле "имя папки" укажем имя - ну например - share. Прежде всего - если не подключен CD/DVD-привод - подключите его, затем - Следует просто выбрать из главного меню машины (виртуал бокс) Устройства -> Установить дополнения гостевой ОС, после чего, собственно, должен смонтироваться образ с дополнениями - ubuntu12 "сама" предложит запустить его исполняемый код и в консоли будет выведен отчёт о процессе установки, после чего нужно будет перезапустить систему. Ещё вариант подключения общей папки: Создадим на компе папку share (например на диске С:) Подключим её через меню вирутальной машины (предварительно установив дополнения гостевой ОС) - в поле "имя папки" укажем имя - например - share.  Samba — пакет программ, которые позволяют обращаться к сетевым дискам и принтерам на различных операционных системах по протоколу SMB/CIFS. Имеет клиентскую и серверную части. Потом создадим уже в убунте папку к которой мы примонтируем наш "сетевой диск" - создадим её в домашней директории (и тоже назовём share) то есть по адресу: /home/name/ гдe name - имя пользователя. например если моего пользователя зовут уникальным именем qwe, то создим папку расположенную по адресу: /home/qwe/share. А дальше выполним команду монтирования: sudo mount -t vboxsf share /home/qwe/share. И теперь в папке /home/qwe/share будет отображаться всё, что мы забросим туда из хост-системы. Java 1.7 - установите её в убунту Рекомендации по установке Java Выполним команду в терминале: sudo apt-get install default-jdk Hadoop 7.7.0 hadoop-2.7.7.tar.gz https://hadoop.apache.org/ apache-mirror.rbc.ru/pub/apache/hadoop/common/hadoop-2.2.0/ Создание новых пользователя и группы Итак, запускаем терминал (командную строку ubuntu) и делаем так и создаём нового пользователя в группе hadoop (её тоже придётся создать, что мы и делаем первой командой): $ sudo addgroup hadoop $ sudo adduser --ingroup hadoop hduser Настройки SSH Secure Shell, т. е. SSH – протокол, обеспечивающий защищённые соединения и передачу данных между двумя удалёнными компьютерами. Для связи с узлами hadoop использует SSH - а потому нам следует настроить эту службу. Сгенерируем SSH ключ, для созданого нами на предыдущем шаге пользователя hduser - для этого выполним две такие команды - сменим пользователя: su - hduser и запустим генерацию ключа: ssh-keygen -t rsa -P "" Далее ubuntu попросит ввести имя для файла - введи - и запомните путь куда сохранится. 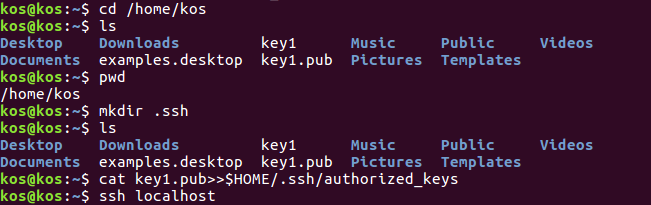  Далее разрешим доступ к нашей машине с только что созданным ключом: сat имя_ключа.pub>>.ssh/ authorized_keys Пробуем подключиться: ssh localhost. Проверить установлен ли сервер (sshd start), если нет - то установить (sudo apt-get install ssh) и опять же пробовать подключиться (если не работает - проверьте параметры /etc/ssh/sshd_config). Выключаем IPv6 Также перед установкой рекомендуется выключить IPv6, а именно Добавьте в файл /etc/sysctl.conf редактор nano такие строки: # disable ipv6 net.ipv6.conf.all.disable_ipv6 = 1 net.ipv6.conf.default.disable_ipv6 = 1 net.ipv6.conf.lo.disable_ipv6 = 1 Сохраните его и перезагрузите систему. Проверить включен ли IPv6 можно так: cat /proc/sys/net/ipv6/conf/all/disable_ipv6 если возвращается ноль - значит поддержка включена Установка Hadoop Перейдём в папку: cd /usr/local/  Запускаем команду распаковки и установки hadoop: sudo tar xzf hadoop-2.7.0.tar.gz 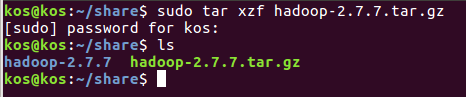 Переместим в папку в с более изящным названием, чем то, где указана версия и сделаем владельцем её специально созданного ранее пользователя: sudo mv hadoop-2.2.0 hadoop sudo chown -R hduser:hadoop hadoop Ну вот теперь хадуп установлен в папку /usr/local/hadoop (проверьте путь в проводнике) Далее поправим файл опций терминала для нашего спец. пользователя. Откройте .bashrc файл ,который лежит к домашней папке созданного нами пользователя (он может быть скрыт - и его придётся показать) Запустите терминал с полными правами (sudo nautilus) далее в главном меню : Edit -> Preferences и поставьте галочку: Show hidden and backup files.Ещё способы Кликните на на оконо проводника (nautilus-а) и нажмите Ctrl+H Далее добавьте в конец файла следующее (внимательно посмотрите пути к яве и хадупу) source .bashrc 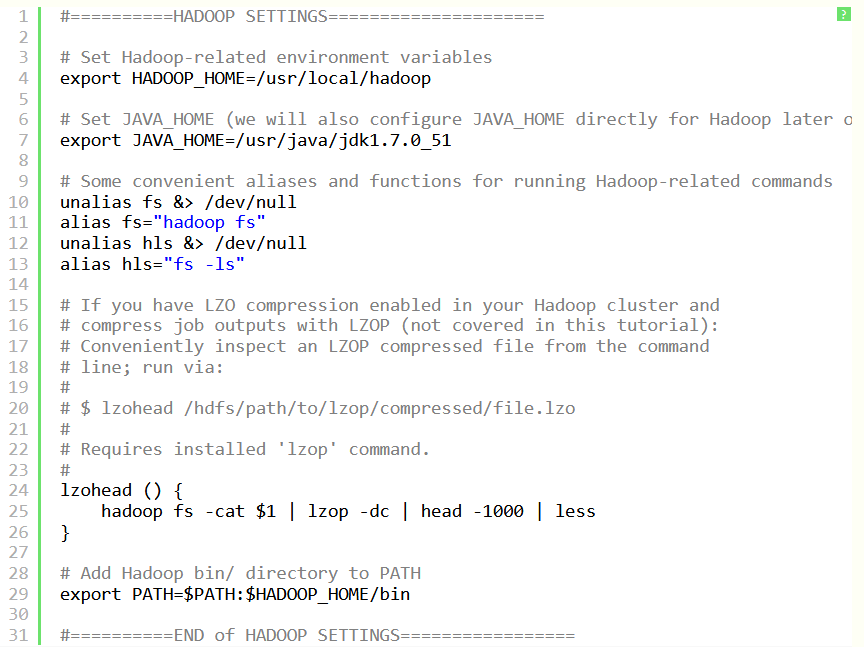 Зайдите под пользователем для которого редактировали этот скрипт и просто выполните команду: hadoop HADOOP почти заработал! Итак после того как hadoop установлен, мы можем запустить его базовой командой которая выведет опции запуска - команда: Получим 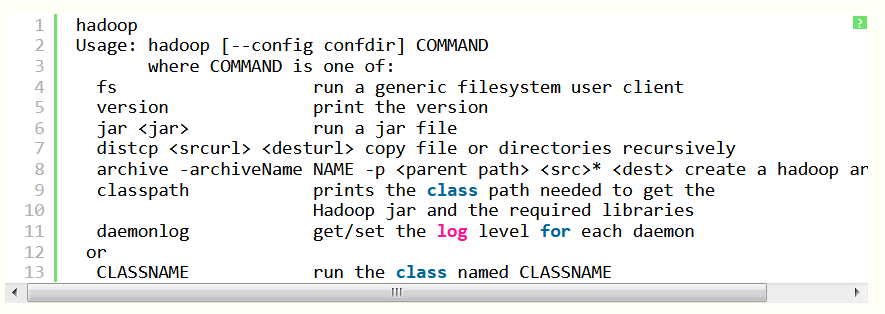 Теперь давайте попробуем такую команду (позволит нам увидеть список доступных примеров): wordcount При её использовании может возникнуть подобная решаемая проблема 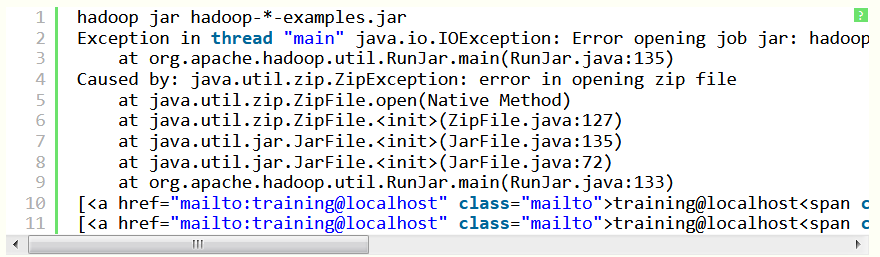 То есть файл найти не удаётся чтобы справится с ней нужно указать конкретное имя файла (hadoop-examples.jar) - переходим в папку где действительно лежит файл например путь может быть таким: и выполняем команду: Получим список стандартных примеров (в виде предупреждения о том что нужно указывать имя программы в качестве параметра):  Пример - программа посчёта слов. Теперь запустим конкретный пример wordcountполучим предупреждение о том, что необходимо создать входной и выходной каталоги: Создадим входной каталог input c использованием команды: Положим туда какие-нибудь текстовые документы (например, можно скопировать пару-тройку статей из википедии). Далее добавим входную директорию в "файловую систему" hadoop, в качестве такой директории будем использовать /home/training/input:, поэтому выполняется команда: Теперь мы можем выполнить команду запуска программы подсчёта слов: hadoop jar hadoop-examples.jar wordcount /home/training/input /home/training/output Источники http://fkn.ktu10.com/?q=node/5576 https://www.cloudera.com/downloads/hortonworks-sandbox/hdp.html |