1 Заметки Питон. Переменные Print(Какой текст) печатает текст Print(а) печатает значение переменной а (вместо а может быть любое имя переменной) a input(Поясните что
 Скачать 84.3 Kb. Скачать 84.3 Kb.
|

|
Переменные: Print(‘Какой текст’) – печатает текст Print(а) – печатает значение переменной а (вместо а может быть любое имя переменной) A = input(‘Поясните что надо ввести ’) – ожидает ввода пользователя какого-то значения int(a) – преобразовывает строку в число float(x) – преобразовывает строку в число с плавающей запятой str(i) – преобразовывает любой тип данных в строку Условные операторы: If, elif, else – действие == if - если elif – иначе-если else - иначе and – это сложное условие при котором выполняет проверка двух условий or – это сложное условие при проверке который один из условий должен выполняться Булевый тип данных – True и False True – правда / истина / да False – не правда / ложь / нет == – равно != – не равно Сложные условия: in – оператор вхождения, определяет наличие какого-то слова или словосочетания в строке. Списки и циклы: Массив или по-другому Python список. Например список может быть таким a = [4, 2, 9, 3, 6, 2, 7, 8] или таким a = [56, ‘sad’ [6, 3, 5, 4], 3, ‘gg’] Нумерация (индексация) в списке идёт с нуля, т.е. 0, 1, 2, 3 … Continue - пропускает Break – останавливает For in/and – что если Range – оператор подсчета List – разбивает на списки Len() – смотреть длину списка Методы для списка: x.append(4) – добавляет элемент в конец списка x.insert(1, 5) – вставляет элемент по указанному индексу x.count(7) – позволяет посмотреть сколько одинаковых элементов в списке x.sort() – сортирует список по возрастанию x.reverse() – переворачивает в обратную сторону x.pop(0) – удаляет элемент по индексу указанной в скобке (если ничего не указывать то удалится последний элемент. x.remove(7) – удаляет конкретный элемент, удаляет один раз x.clear() – полностью очищает список x.extend([‘a’, ’s’]) – можно добавить в конец списка, другое значение из другого списка x.copy() – позволяет продублировать (позволяет скопировать в другую переменную полностью список) x.replace заменяет а строке первую полученную подстроку на вторую 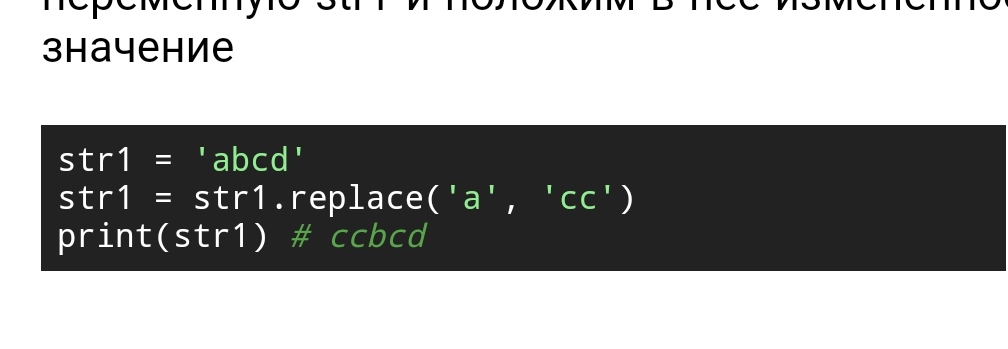 % - оператор остатка при делении Синтаксис срезов …=…[::] – скопировать полностью список [0::2] - диапазон скопированные списка (от нуля в шаг 2) [0:5] – от начала списка до индекса 5 [::-1] – меняем порядковый номер list1 = [a:b:c] a – номер элемента с которого берется срез b – последний элемент среза c – интервал, через который мы берем элемент Цикл - это блок команд, которое повторяется определенное количество раз. Есть циклы For и While. Цикл for – используется, когда нам нужно выполнить какой-то код определенное количество раз или когда нам нужно пройти по всем элементам последовательности. Функция range – выполняет команды определенное количество раз. Кортежи, тип данных tuple Кортеж – это неизменяемый тип данных. Это факт перечисление значений через запятую. Например - x = (9, 8, 7) Функция tuple при помощи которой можем создать кортеж. Например - x = tuple (‘stroki’) Выйдет так - (‘s’, ’t’, ’r, ’o’, ’k’, ’i’) Методы кортежей x.count = - позволяет посмотреть сколько одинаковых элементов входит в кортеж. x.index = - возвращает индекс элемента. Парсер файлов import os – модуль по работе с операционной системой. walk – функция которая позволяет сгенерировать пути к всем файлам на компьютере с помощью которого создадим алгоритм поиска и можем фильтровать ( с помощью названия или даты создания). Эта функция генератор. os.walk() - в скобке () подаем аргумент path – это вложенный модуль в модуль os Функция walk выдает кортеж из трех элементов: адрес, папка и файлы. os.path.join(***, ***) – автоматически будет добавлять слэш (\). Функция getctime(***) – выдает время создания файла с момента начала эпохи Функции def, определение и вызов Функция — это скрытый участок кода котором прописаны определенные команды и этот участок кода выполняется по нашей команде, команде запуска функций. def – определение функций и далее дается имя фунции, например show. (Примерно будет выглядеть так «def show (): print: функция » ) Команда запуска функции это ее имя, в нашем случае show. Функция должна быть определена до точки запуска. Для того чтобы использовать значение из функции дальше в программе, есть оператор return который вернет значение в точку запуска функции. Например dew show (): x = 7 return x Функции def, параметры def count_list(par, count = 0): #параметр, #параметр по умолчанию, так как изначально прописано значение в определении функции. Если параметр по умолчанию записать первой то возникнет ошибка. for i in par: count += 1 return count j = [9, 8, 7, 4] print (count_list(j)) #аргумент h = ['a', 's', 'f'] print (count_list(h)) k = [5, 4, 1, 6, 5, 9] print (count_list('stroka')) #можно написать строка и она будет обработано так как она последовательно Параметр – это переменная которая записывается в скобках в определении функции, задается любое имя. Это переменная определенная внутри функции, и в ней будет содержать список. Количество параметров и количество аргументов всегда должно совпадать. print (count_list(j, -1)) - если таким образом записать, а именно с -1 то оно будет показывать индекс последнего элемента. def count_list(par, par2 = False, count = 0): if par2 == True: typ = type(par[0]) for i in par: count += 1 return count, typ else: for i in par: count += 1 return count j = [9, 8, 7, 4] h, p = count_list(j, True, -1) Можно распаковать их на 2 переменны, в этом случае h = 3(будут показывать длину списка), p = int (будут показывать тип) Функции переменное количество аргументов, параметр args def name(f, h, *args, key): print(f) # f = 2 print(h) # h = 4 print(args) # args = (6, 7, 9) name (2, 4, 6, 7, 9, key = 5) f и h – позиционные параметры, назначается по одному неименному аргументу, остальные неименованные аргументы упаковывается в кортеж - *args а ключевые параметры которые стоят после *args в них значение можно присвоить только при помощи именного аргумента, имя это имя параметра к которому присваивается значение (в нашем случае key = 5) В Python есть две зоны видимости, глобальная(global) и локальная(nonlocal). x = 5 # глобальная часть def t(): x=6 # локальная часть (то что внутри функции, является локальной) print(x) # в данном случае команда видит только локальную часть и выдаст ответ “х = 5”. x = 5 def t(): global x x = 8 print(x) t() print(x) #ответ 8 global х – ключевым словом глобал и указывая переменную мы даем команду в функции (в локальной зоне) что не создаем новую локальную переменную а мы хотим внести изменения в глобальную переменную которая объявлена глобальной уровне видимости x = 5 def t(): x = 8 def t2(): x = 10 print (x) t2() print(x) t() print(x) (ответ: 10 8 5) nonlocal x – функция внутри функции не создает новую переменную и с помощью данной команды берет значение переменной из предыдущей переменной, и при этом локальная переменная не задействовано. nonlocal можно использовать только во вложенных функция. x = 5 def t(): x = 8 def t2(): nonlocal x x = 10 print (x) t2() print(x) t() print(x) (ответ: 10 10 5) Функции и структурирования кода import math PI = math.pi def radius(): n = float(input('Диаметр цилиндра в см: ')) n /= 2 return n def height(): m = float(input('Высота цилиндра в см: ')) return m def volume(): r = radius() h = height() s = PI*r**2 v = s*h return v def massa(g): # аргументирует из def volume(): n = float(input('Удельный вес г/м3: ')) return g*n/1000 print ('Вес цилиндра в кг: ', massa(volume())) import math – выдает математические значения PI = math.pi – выдает число Пи Словари, тип данных dict – варианты и методы d1 = {'a': 7} #создания словаря при помощи фигурной скобки, создаете пустой словарь d2 = dict (a=7) # при помощи dict d3 = dict.fromkeys([1, 2, 3, 4, 5], 'value') # при помощи метода dict.fromkeys() price = {'meat': 3, 'bread': 1, 'potato':0.5, 'water':0.2} users = { 'Alex7': {'password': 9856214, 'id': 1957}, 'Jimmy99': {'password': 5432893, 'id': 5642}, 'Bob33': {'password': 2158463, 'id': 1136}, } def buy(): pay = 0 while True: enter = input('Что покупаем???\n') if enter == 'end': break pay += price[enter] return pay Словарь очень похож на список, хранит в себе перечень каких либо значений и объектов. Главное отличие от списка в том, что в списке хранились при помощи индексов, а в словаре используется ключи. d2 = dict (a=7) # ключ а значение 7 Можем добавлять значения в словарь: d1[‘b’] = 9 # указываем имя нового ключа [‘b’] и значения 9. Ответ выходит {‘a’:7, ‘b’:9} Вызываете по ключу d1[‘b’] Если хотите удалить т о удаляете по ключу del del d1[‘b’] Тем самым у Вас удаляется d1. Словарь это изменяемый тип данныз d1 = {'a': 7} d2 = dict (a=7) d3 = dict.fromkeys([1, 2, 3, 4, 5], 'value') d5 = d1.copy() #позволяет скопировать словарь в новую переменную print(d1.items()) #возвращает список из кортежа (бывший ключ и бывший значение) print(d1.keys()) #возвращает ключи в словаре в виде списка print (d1.values()) #возвращает значение в словаре в виде списка d1.update(d2) #позваляет добавить ключ/значение от одного словаря в другой print(d1) if 'c' in d1: d1['c'] y = d1.get('c', 'value') #берет значение из словаря print(y) t = d1.pop('a') #не просто удаляет и еще возвращает значение print(t, d1) Чтение, запись и кодировка файлов. import os list_paths = [] for adress, papka, file in os.walk('C:\\'): #используя парсер сохраним файлы которые сохранены в диске С for i in files: full_paths = os.path.join(adress, i) list_paths.append(full_path) 'r' открыть для чтения (по умолчанию) 't' в текстовом режиме (по умолчанию) 'w' для записи, содержимое файла удаляется, если файла нет, создается новый 'a' открыть для дозаписи в конец файла, если файла нет, создается новый 'b' в бинарном режиме '+' открыть для чтения и записи 'r+', 'w+', 'a+' r = open() # для сохранения используем функцию опен и аргументы . например r=open(‘text.txt’) тем самым открываем расширение файла текст и далее указываем режим работы r=open(‘text.txt’, ‘w’) по умолчанию ‘r’ - чтение работы, в нашем случаем выбираем ‘w’для записи. Выходит так: r=open(‘C:\\other\text.txt’, ‘w’) #создаем файл текст для записи r.write(‘Строка текста’) #записываем в файл с помощью метода write и в него записываем то что хотим передать r.close() #закрываем файл Тем самым у нас в диске С в файле other создается текстовый файл в котором сохранен текст «Строка текста» Теперь для чтения файла пишем данную команду: r = open('C:\\Other\TXT.txt') u = r.read() #записываем команду прочитать и передаем его в переменную print (u) #выводим переменную на экран r.close() Если хотим сохранить пути файлов С и их сохранить, то: import os list_paths = [] for adress, papka, file in os.walk('C:\\'): for i in files: full_paths = os.path.join(adress, i) list_paths.append(full_path) r = open('C:\\Other\TXT.txt', 'w') for x in list_paths: r.write r.close() С помощью парсера все пути к фалам сохраняется далее открываем файл и с помощью метода «w» записываем пути. Записать можно только тип данных строка а у нас список значит нам нужно пройтись по нашему списку при помощи цикла fot (пример: for x in list_paths: r.write(x + '\n') ) и по каждой сработке по одному циклу будем записывать имя файла х и чтоб не записались слитно а с каждой новой строки к иксу добавляем n, так (x + '\n'). Далее можем прочитать такими способами r.reader – прочитать все r.readerline – прочитать построчно r.readerlines – прочитать построчно но в переменной будет список из всех строк в документе Есть более простой способ через цикл for. В переменную i указываем r чтение файла. Ставим условие если в имени пути будет 'read.py' то этот путь выводит. r = open('C:\\Other\TXT.txt') for i in r: if 'read.py' in i: print(i) r.close() Бинарный режим работы Позволяет читать и записывать бинарные файлы (.ехе). r = open('C:\\Other\ee.exe', 'rb') #как текст мы его прочитать не можем, поэтому с помощью метода 'rb' читаем в бинарном режиме, но работать в таком режиме не можем поэтому копируем его в у y = open('C:\\Other\Копия ee.exe', 'wb') #даем имя 'Копия ee.exe' и режим работы w тем самым оно просто создастся и записываем бинарный файл b while True: var = r.read(1048576) # будем записывать его кусками с помощью цикла. Данный цикл будет считывать по одному Мб за раз это 1048576 байтов print(var.__sizeof__()) #метод __sizeof__ - позволяет посмотреть сколько сейчас оперативной памяти занимает объект. y.write(var) #записываем новый файл, бинарный код/значение который хранится в переменной var print('Kontrol') r.close() y.close() После запуска кода у нас вышло 33 столько байт весит объект чтения, это повод создать условия для прерывания цикла r = open('C:\\Other\ee.exe', 'rb') y = open('C:\\Other\Копия ee.exe', 'wb') while True: var = r.read(1048576) print(var.__sizeof__()) if var.__sizeof__() == 33: break y.write(var) print('Kontrol') r.close() y.close() Тем самым можно задать ритм копирования любого файла. Нюанс работы функции open это кодировка файла с которым вы будете работать. Если файл был создан не на вашем компьютере то может быть совершенно другое кодировка. r = open('C:\\Other\text2.txt', 'w', encoding = 'utf-8') r.write('stroka текста') r.close() encoding – дополнительная кодировка и указываем например 'utf-8' ( кодировок много). И далее то что запишем нами указанный файл, оно закодируется. И далее если попробуете файл прочитать не указав кодировку произойдет или ошибка или не правильная кодировка. r = open('C:\\Other\e.txt', 'w', encoding = 'utf-8') #создаем файл с кодировкой 'utf-8' r.write('stroka текста') r.close() h = open ('C:\\Other\e.txt', encoding='utf-8') #считываем файл указав кодировку 'utf-8' print(h.read()) |