лабор. УД Задание 1 Горшков А.В. ВТ-22-1вз. Привести примеры представления иерархической, сетевой и реляционной моделей данных. Описать преимущества и недостатки данных моделей.
 Скачать 41.86 Kb. Скачать 41.86 Kb.
|

|
Привести примеры представления иерархической, сетевой и реляционной моделей данных. Описать преимущества и недостатки данных моделей. Привести примеры основных операций над отношениями. Рассмотреть реляционную модель данных , осуществить нормализацию отношений в базе данных. Иерархическая модель. Логическая модель данных в виде древовидной структуры, представляющая собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое дерево (граф). Данная модель характеризуется такими параметрами, как уровни, узлы, связи. Принцип работы модели таков, что несколько узлов более низкого уровня соединяется при помощи связи с одним узлом более высокого уровня. Узел — информационная модель элемента, находящегося на данном уровне иерархии. 1968 - Типичным представителем иерархических систем является Information Management System (IMS) фирмы IBM. Первая версия этого продукта вышла в свет в 1968 году. К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Узел - это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчиненную никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчиненные) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базе данных определяется числом корневых записей. К каждой записи базы данных существует только один (иерархический) путь от корневой записи. Операции над данными. ДОБАВИТЬ в базу данных новую запись. Для корневой записи обязательно формирование значения ключа. ИЗМЕНИТЬ значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям. УДАЛИТЬ некоторую запись и все подчиненные ей записи. ИЗВЛЕЧЬ: - извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей - извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева) В операции ИЗВЛЕЧЬ допускается задание условий выборки. Все операции изменения применяются только к одной "текущей" записи (которая предварительно извлечена из базы данных). Такой подход к манипулированию данных получил название "навигационного". Ограничения целостности: поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка). Пример иерархической модели. Рассмотрим модель данных предприятия (рисунок 1): предприятие состоит из отделов, в которых работают сотрудники. В каждом отделе может работать несколько сотрудников, но сотрудник не может работать более чем в одном отделе. Поэтому, для информационной системы управления персоналом необходимо создать групповое отношение, состоящее из родительской записи ОТДЕЛ (НАИМЕНОВАНИЕ_ОТДЕЛА, ЧИСЛО_РАБОТНИКОВ) и дочерней записи СОТРУДНИК (ФАМИЛИЯ, ДОЛЖНОСТЬ, ОКЛАД). Это отношение показано на рис. (а) (Для простоты полагается, что имеются только две дочерние записи). Для автоматизации учета контрактов с заказчиками необходимо создание еще одной иерархической структуры : заказчик - контракты с ним - сотрудники, задействованные в работе над контрактом. Это дерево будет включать записи ЗАКАЗЧИК(НАИМЕНОВАНИЕ_ЗАКАЗЧИКА, АДРЕС), КОНТРАКТ(НОМЕР, ДАТА,СУММА), ИСПОЛНИТЕЛЬ (ФАМИЛИЯ, ДОЛЖНОСТЬ, НАИМЕНОВАНИЕ_ОТДЕЛА) (рис. (b)). Из этого примера видны недостатки иерархических БД: Частично дублируется информация между записями СОТРУДНИК и ИСПОЛНИТЕЛЬ (такие записи называют парными), причем в иерархической модели данных не предусмотрена поддержка соответствия между парными записями. Иерархическая модель реализует отношение между исходной и дочерней записью по схеме 1:N, то есть одной родительской записи может соответствовать любое число дочерних. Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в котором ИСПОЛНИТЕЛЬ будет являться исходной записью, а КОНТРАКТ - дочерней (рис. (c)). Таким образом, мы опять вынуждены дублировать информацию. 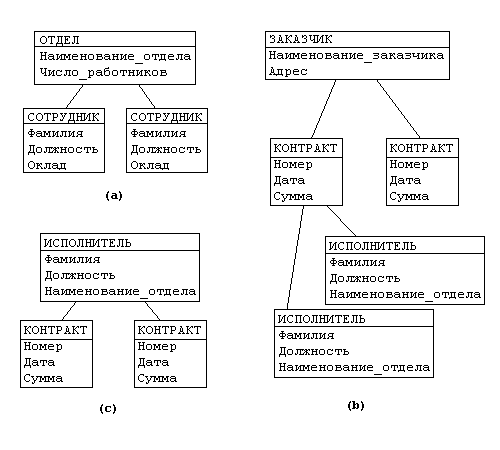 Рисунок 1. К основным недостаткам иерархических моделей следует отнести: неэффективность, медленный доступ к сегментам данных нижних уровней иерархии, четкая ориентация на определенные типы запросов и др. Также недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. Иерархические СУБД быстро прошли пик популярности, которая обусловливалась их ранним появлением на рынке. Затем их недостатки сделали их неконкурентоспособными, и в настоящее время иерархическая модель представляет исключительно исторический интерес. Сетевая модель данных - это логическая модель данных, представляющая их сетевыми структурами типов записей и связанные отношениями мощности один-к-одному или один-ко-многим. В отличие от реляционной модели, связи в ней моделируются наборами, которые реализуются с помощью указателей. Сетевые модели данных являются расширенной версией иерархической модели, однако основным отличием является то, что в сетевых моделях данных имеются указатели в обоих направлениях, которые соединяют родственную информацию. Сетевую модель можно представить как граф узлами, которого является запись, а ребрами - набор. Сегменты данных в сетевых БД могут иметь множественные связи с сегментами старшего уровня. При этом направление и характер связи в сетевых БД не являются столь очевидными, как в случае иерархических БД. Поэтому имена и направление связей должны идентифицироваться при описании БД. В 1971 группа DTBG (Database Task Group) представила в американский национальный институт стандартов отчет, который послужил в дальнейшем основой для разработки сетевых систем управления базами данных. Стандарт сетевой модели был создан в 1975 году организацией CODASYL (Conference of Data System Languages), которая определила базовые понятия модели и формальный язык описания. Типичным представителем систем, основанных на сетевой модели данных, является СУБД IDMS (Integrated Database Management System), разработанная компанией Cullinet Software, Inc. и изначально ориентированная на использования на мейнфреймах компании IBM. Архитектура системы основана на предложениях DBTG организации CODASYL. Пример сетевой модели. 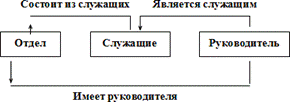 Рисунок 2 - сетевая БД. На рисунке 2 показаны три типа записи: Отдел, Служащие и Руководитель и три типа связи: Состоит из служащих, Имеет руководителя и Является служащим. В типе связи Состоит из служащих типом записи-предком является Отдел, а типом записи-потомком – Служащие (экземпляр этого типа связи связывает экземпляр типа записи Отдел со многими экземплярами типа записи Служащие, соответствующими всем служащим данного отдела). В типе связи Имеет руководителя типом записи-предком является Отдел, а типом записи-потомком – Руководитель (экземпляр этого типа связи связывает экземпляр типа записи Отдел с одним экземпляром типа записи Руководитель, соответствующим руководителю данного отдела). В типе связи Является служащим типом записи-предком является Руководитель, а типом записи-потомком – Служащие (экземпляр этого типа связи связывает экземпляр типа записи Руководитель с одним экземпляром типа записи Служащие, соответствующим тому служащему, которым является данный руководитель). Преимущества сетевой модели: Стандартизация. Появление стандарта CODASYL, который определил базовые понятия модели и формальный язык описания. Быстродействие. Быстродействие сетевых баз данных сравнимо с быстродействием иерархических баз данных. Гибкость. Множественные отношения предок/потомок позволяют сетевой базе данных хранить данные, структура которых была сложнее простой иерархии. Универсальность. Выразительные возможности сетевой модели данных являются наиболее обширными в сравнении с остальными моделями. Возможность доступа к данным через значения нескольких отношений (например, через любые основные отношения). Недостатки сетевой модели: Жесткость. Наборы отношений и структуру записей необходимо задавать наперёд. Изменение структуры базы данных ведет за собой перестройку всей базы данных. Связи закреплены в записях в виде указателей. При появлении новых аспектов использования этих же данных может возникнуть необходимость установления новых связей между ними. Это требует введения в записи новых указателей, т.е. изменения структуры БД, и, соответственно, переформирования всей базы данных. Сложность. Сложная структура памяти. Реляционная модель. Реляционная модель данных – логическая модель данных. Впервые была предложена британским учёным сотрудником компании IBM Эдгаром Франком Коддом (E. F. Codd) в 1970 году в статье "A Relational Model of Data for Large Shared Data Banks" (русский перевод статьи, в которой она впервые описана, опубликован в журнале "СУБД" N 1 за 1995 г.). В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД. В реляционной модели достигается гораздо более высокий уровень абстракции данных, чем в иерархической или сетевой. В упомянутой статье Е.Ф. Кодда утверждается, что "реляционная модель предоставляет средства описания данных на основе только их естественной структуры, т.е. без потребности введения какой-либо дополнительной структуры для целей машинного представления". Другими словами, представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название "реляционная" происходит от английского relation – "отношение"). В состав реляционной модели данных обычно включают теорию нормализации. Кристофер Дейт определил три составные части реляционной модели данных: Структурная часть модели определяет, что единственной структурой данных является нормализованное n-арное отношение. Отношения удобно представлять в форме таблиц, где каждая строка есть кортеж, а каждый столбец – атрибут, определенный на некотором домене. Данный неформальный подход к понятию отношения дает более привычную для разработчиков и пользователей форму представления, где реляционная база данных представляет собой конечный набор таблиц. Манипуляционная часть модели определяет два фундаментальных механизма манипулирования данными – реляционная алгебра и реляционное исчисление. Основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление. Целостная часть модели определяет требования целостности сущностей и целостности ссылок. Первое требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать). Пример реляционной модели. Предположим, создаётся таблица бронирования для теннисных кортов на день: {Номер корта, Время начала, Время окончания, Тариф, Член клуба}. Тариф зависит от выбранного корта и членства в клубе, для каждого из кортов имеется тариф для членов теннисного клуба и для сторонних клиентов. Тарифы для кортов не повторяются. Таким образом, возможны следующие составные первичные ключи: {Номер корта, Время начала}, {Номер корта, Время окончания}, {Тариф, Время начала}, {Тариф, Время окончания}. Таблица соответствует второй и третьей нормальной форме. Требования второй нормальной формы (2NF) выполняются, так как все атрибуты входят в какой-то из потенциальных ключей, а неключевых атрибутов в отношении нет. Также нет и транзитивных зависимостей, что соответствует требованиям третьей нормальной формы. (3NF). Тем не менее, существует функциональная зависимость тарифа от номера корта. То есть, по ошибке можно нарушить логическую целостность и, например, приписать тариф Premium для первого корта, хотя тариф Premium может относиться только ко второму корту. Можно улучшить структуру, разбив таблицу на две: {Номер корта, Время начала, Время окончания, Член клуба} и {Тариф, Номер корта, Член клуба}. Данное отношение будет соответствовать BCNF. Преимущества реляционной модели: Простота и доступность для понимания пользователем. Единственной используемой информационной конструкцией является "таблица"; строгие правила проектирования, базирующиеся на математическом аппарате; полная независимость данных. Изменения в прикладной программе при изменении реляционной БД минимальны; для организации запросов и написания прикладного ПО нет необходимости знать конкретную организацию БД во внешней памяти. Недостатки реляционной модели: Далеко не всегда предметная область может быть представлена в виде "таблиц"; в результате логического проектирования появляется множество "таблиц". Это приводит к трудности понимания структуры данных; БД занимает относительно много внешней памяти; относительно низкая скорость доступа к данным. Схема отношения базы данных — это именованное множество пар {имя атрибута, имя домена (или типа, если понятие домена не поддерживается)}. Если все атрибуты одного отношения определены на разных доменах, осмысленно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это является всего лишь удобным способом именования и не устраняет различия между понятиями домена и атрибута). Схема базы данных (в структурном смысле) — это набор именованных схем отношений. Кортеж, соответствующий данной схеме отношения в базе данных, — это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. «Значение» является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым, степень или «арность» кортежа, т.е. число элементов в нем, совпадает с «арностью» соответствующей схемы отношения. Попросту говоря, кортеж — это набор именованных значений заданного типа. Отношение — это множество кортежей данной базы данных, соответствующих одной схеме отношения. Иногда, чтобы не путаться, говорят «отношение-схема» и «отношение-экземпляр», иногда схему отношения называют заголовком отношения, а отношение как набор кортежей — телом отношения. На самом деле, понятие схемы отношения в базе данных ближе всего к понятию структурного типа данных в языках программирования. Число атрибутов в отношении называют степенью (или -арностью ) отношения. Мощность множества кортежей отношения называют мощностью отношения. Фундаментальные свойства отношений: 1) Отсутствие кортежей-дубликатов. Из этого свойства вытекает наличие у каждого отношения так называемого первичного ключа — набора атрибутов, значения которых однозначно определяют кортеж отношения. 2) Отсутствие упорядоченности кортежей. 3) Отсутствие упорядоченности атрибутов. 4) Атомарность значений атрибутов — Это следует из того, что лежащие в их основе атрибуты имеют атомарные значения. Это четвертое отличие отношений от таблиц — в ячейки таблиц можно поместить что угодно — массивы, структуры, и даже другие таблицы. Одна из важнейших проблем проектирования схемы БД заключается в выделении типов записей (отношений), определении состава их атрибутов. Группировка атрибутов должна быть рациональной, т. е. минимизирующей дублирование данных и упрощающей процедуры их обработки и обновления. Сначала эти вопросы решались интуитивно. Однако интуиция может подвести даже опытного специалиста, поэтому Коддом был разработан в рамках реляционной модели данных аппарат, называемый нормализацией отношений. И хотя идеи нормализации сформулированы в терминологии реляционной модели данных, они в равной степени применимы и для других моделей данных. Нормализация отношений (таблиц) — одна из основополагающих частей теории реляционных баз данных. Нормализация имеет своей целью избавиться от избыточности в отношениях и модифицировать их структуру таким образом, чтобы процесс работы с ними не был обременён различными посторонними сложностями. При игнорировании такого подхода эффективность проектирования стремительно снижается, что вкупе с прочими подобными вольностями может привести к критическим последствиям. Коддом выделено три нормальных формы отношений. Самая совершенная из них — третья. Предложен механизм, позволяющий любое отношение преобразовать к третьей нормальной форме. В процессе таких преобразований могут выделяться новые отношения. Вначале введем понятие простого и сложного атрибута. Простым назовем атрибут, если значения его атомарны, т. е. неделимы. В противовес ему сложный атрибут может иметь значение, представляющее собой конкатенацию нескольких значений одного или разных доменов. Аналогами сложного атрибута может быть вектор, агрегат данных, повторяющийся агрегат. 1) Таблица находится в первой нормальной форме тогда, когда она не содержит повторяющихся полей и составных значений полей (то есть каждое поле должно содержать одно значение, а не их комбинацию). 2) Таблица находится во второй нормальной форме, если она удовлетворяет требованиям первой нормальной формы и все ее поля, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом, то есть любое не ключевое поле однозначно идентифицируется полным набором ключевых полей. 3) Таблица находится в третьей нормальной форме, если она удовлетворяет определению второй нормальной формы и ни одно из ее неключевых полей функционально не зависит от любого другого неключевого поля. Можно сказать, что таблица находится в третьей нормальной форме, если она находится во второй нормальной форме и каждое неключевое поле нетранзитивно зависит от первичного ключа. |