Создание игры в среде разработки Unity
 Скачать 311.15 Kb. Скачать 311.15 Kb.
|

|
Муниципальное автономное образовательное учреждение города Ростова-на-Дону «Лицей №11» Секция «Информатика» Тема: «Создание игры в среде разработки Unity» Автор работы: Коновалов Андрей 10 «В» класс, МАОУ «Лицей № 11», г. Ростов-на-Дону, Ростовская область Руководитель: Чебан Дмитрий Сергеевич, учитель информатики, МАОУ «Лицей № 11», г. Ростов-на-Дону, Ростовская область г. Ростов-на-Дону 2022 год ОглавлениеВВЕДЕНИЕ 3 ГЛАВА 1. ТЕОРИЯ 3 1.1. TTS – Text-to-Speech. Понятие синтеза речи. 3 1.2. История появления технологии Text-to-Speech 4 1.3. Способы синтеза речи 5 1.3.1 Компиляционный синтез 5 1.3.2: Параметрический анализ 5 1.3.3. Синтез речи по фонетическим правилам 6 1.4. Устройство программ-синтезаторов 6 1.5. Развитие технологии TTS и её перспективы 7 ГЛАВА 2: ПРАКТИКА 9 1.1.Принцип работы программы 9 1.2. Скриншоты, фрагменты кода 9 ЗАКЛЮЧЕНИЕ 12 Выводы по итогам проделанной работы 12 1.2. Список используемой литературы 12 ВВЕДЕНИЕВ современном мире тема разработки игр актуальна как никогда. Ведь в сфере развлечений это наиболее крупный, а соответственно очень хорошо финансируемый сегмент. Людям интересно играть в игры, людям интересно создавать игры, аудитория игр растет не по дням, а по часам, разработчиков становится все больше и больше, крупным инвесторам это сфера становится интересней. Создание крупных игр, как их называют AAA игры, это очень сложный процесс, на который уходит очень много времени, денег и конечно, человеческих сил и нервов, а людей над такими проектами работает не мало. Для того чтобы погрузится в этот сложный процесс нужно разобраться в создании игр с нуля как независимый разработчик, и сейчас мы разберемся как это сделать и какие для этого нужны навыки. Задачи 1. Изучить историю создания игр 2. Изучить как происходит разработка в современном мире 3. Разобрать плюсы и минусы актуальных программ для создания игр 4. Подобрать наиболее подходящий под наши цели движок 5. Рассмотреть возможности нашего движка, научится их использовать 6. Написать примитивную игру и использовать ее как итог работы ГЛАВА 1. ТЕОРИЯ1.1. TTS – Text-to-Speech. Понятие синтеза речи.Синтез речи, или Text-to-Speech (TTS) — технология преобразования текста в речь [7]. Это компьютерное моделирование речи из текста при помощи различных методов. Синтез речи используется во многих сферах. Одни из самых известных – озвучка сообщений в городском транспорте, голосовые роботы (используются в чат-ботах известных компаний), озвучание различных сообщений от операторов связи, работа колл-центров и многие другие [5]. Среди перспективных направлений – создание естественной речи у роботов, замена системами синтеза речи дикторов на радио и ТВ, встраивание искусственного вокала в кино и музыку [4]. В общем, технология TTS актуальна – ведь синтез речи экономит время и деньги бизнеса, так как генерирует звук автоматически и этим избавляет компанию от ручной записи (и перезаписи) аудиофайлов. Благодаря синтезу речи можно прочитать любой текст голосом, идентичным естественному или приближенным к нему. Чтобы сделать это, необходимо, во-первых, преобразовать полученный текст в приемлемый для обработки вид, затем осуществить сам синтез речи, придать полученной речи посредством различных алгоритмов цельность, очистив от разного рода звуковых артефактов, выявляющих искусственность речи – например, пауз между фразами, появляющимися у большинства современных программ TTS, а также, по возможности, придать речи верную интонацию [3]. Для этого существуют три основных способа – параметрический, компиляционный и синтез речи по фонетическим правилам. 1.2. История появления технологии Text-to-SpeechВ конце XVIII века датский учёный Христиан Кратценштейн, действительный член Российской Академии Наук, создал модель речевого тракта человека, способную произносить пять долгих гласных звуков (а, э, и, о, у) [2]. Модель представляла собой систему акустических резонаторов различной формы, издававших гласные звуки при помощи вибрирующих язычков, возбуждаемых воздушным потоком. В 1778 австрийский учёный Вольфганг фон Кампелен дополнил модель Кратценштейна моделями языка и губ и представил акустическо-механическую говорящую машину, способную воспроизводить определённые звуки и их комбинации [1]. Шипящие и свистящие выдувались с помощью специального меха с ручным управлением. В 1837 учёный Чарльз Уитстоун представил улучшенный вариант машины, способный воспроизводить гласные и большинство согласных звуков. В конце XIX века знаменитый учёный Александр Белл создал собственную «говорящую» механическую модель, очень схожую по конструкции с машиной Уитстоуна. С наступлением XX века началась эра электрических машин, и учёные получили возможность использовать генераторы звуковых волн и на их базе строить алгоритмические модели [6]. В 1930-х годах работник Bell Labs Хомер Дадли, работая над проблемой поиска путей для снижения пропускной способности, необходимой в телефонии, чтобы увеличить её передающую способность, разрабатывает VOCODER (сокращенно от англ. voice — голос, англ. coder — кодировщик) — управляемый с помощью клавиатуры электронный анализатор и синтезатор речи. Идея Дадли заключалась в том, чтобы проанализировать голосовой сигнал, разобрать его на части и пересинтезировать в менее требовательный к пропускной способности линии. Усовершенствованный вариант вокодера Дадли, VODER, был представлен на Нью-Йоркской Всемирной выставке 1939 года [7]. Первые синтезаторы речи звучали довольно неестественно, и часто едва можно было разобрать производимые ими фразы. Однако качество синтезированной речи постоянно улучшалось, и речь, генерируемую современными системами синтеза речи, порой не отличить от реальной человеческой речи. Впрочем, абсолютное большинство среди таких систем используют либо громадные вычислительные мощности, либо базы данных, сформированных долгим и кропотливым трудом. 1.3. Способы синтеза речи1.3.1 Компиляционный синтезДанный способ предусматривает создание речи из текста путем склейки сопоставленных со словарем слов [4]. Словарь представляет собой базу данных, состоящую из заранее записанных диктором слов или их фрагментов. Разумеется, это сказывается на размере требуемой для синтеза памяти – чем больше фрагментов будет в базе данных, тем выше качество итоговой речи, и наоборот. Поэтому используются различные методики сжатия речевого сигнала для уменьшения требуемой памяти, что приводит к ухудшению качества итоговой речи. Да, качество отдельных фрагментов такой речи будет значительно выше, чем при использовании любых других способов (что неудивительно, ведь речь будет человеческой), но во фрагментах склейки это качество будет заметно проседать, сразу же будет угадываться неестественность речи [5]. Это почти никак не исправить, качество компиляционного синтеза пусть и высоко для малых, заранее определенных фрагментов текста, но его использование для больших массивов данных весьма затруднительно. Кроме того, неизвестный заранее отрывок программа посредством компиляционного синтеза не сможет озвучить впринципе, что делает ее неподходящей для использования в непредсказуемой обстановке, например обычным пользователем. Однако компиляционный синтез все же нашел применение. Многие простые синтезаторы речи, созданные, например, для помощи слабовидящим или незрячим, построены именно по такому принципу. Компиляционный синтез нашел применение в таких сферах, как военное дело, в бизнес-сегменте (колл-центры, например), и даже в общественном транспорте [3]. 1.3.2: Параметрический анализПараметрический синтез речи является итоговой операцией в вокодерных системах, где речевой сигнал представлен набором непрерывно изменяющихся во времени параметров, речевой сигнал реконструируется из параметрических представлений речи [2]. Данный метод речевого синтеза целесообразно использовать в случаях, когда набор текстовых сообщений ограничен и редко подвержен изменению. К достоинствам данного метода относится возможность записать речь для любого языка и любого диктора, гибкость, небольшое количество речевых артефактов и надежность. Однако основным болевым местом такого подхода стало качество синтезируемой речи, оно ниже такового у других способов. Благодаря своим достоинствам параметрический анализ быстро вытеснил остальные способы аудиосинтеза, и, хотя сейчас есть способы совершеннее, все же остается довольно популярным из-за отсутствия необходимости в значительных ресурсах компьютера. Например, известные голосовые помощники (ассистент Олег в приложении «Тинькофф») используют гибридные способы наряду с параметрическим [5]. 1.3.3. Синтез речи по фонетическим правиламСуществуют несколько разновидностей: дифонный, формантный, фонемный и т.д. [3]. Из полуслогов – сегментов из согласного и половины примыкающего к нему гласного звуков – строится речь из подающегося текста после первичной обработки. Достоинства – крайняя простота метода, возможность использовать малые объемы памяти для хранения полуслогов, недостатки – на месте слияния полуслогов неестественность речи видна очень хорошо, а из-за невозможности настроить эмоциональность у каждого отдельно взятого полуслога речь получается неестественно-нейтральной [5]. 1.4. Устройство программ-синтезаторовЧтобы преобразовать текст в голос, система должна пройти три этапа: преобразовать текст в слова, выполнить фонетическую транскрибацию и преобразовать транскрибацию в речь [6]. 1. Преобразовать текст в слова Специальный алгоритм должен подготовить текст и преобразовать его в удобный формат для чтения. Проблема в том, что исходный текст помимо слов содержит числа, сокращения, даты и пр. Такие компоненты необходимо расшифровать и записать словами. Затем алгоритм разделяет текст на отдельные фразы, которые потом система прочитает с подходящей интонацией. Для этого при создании фраз робот ориентируется на пунктуацию и устойчивые конструкции в тексте [2]. 2. Выполнить фонетическую транскрибацию Для компиляционного синтеза отсутствует. Итак, каждое предложение можно произносить по-разному в зависимости от смысла и эмоциональной окраски текста. Более того, даже одно слово может читаться разными способами. Чтобы понять, как произносится каждое слово и где именно ставить ударение, система использует встроенные словари. Если необходимое слово в них отсутствует, компьютер строит транскрибацию самостоятельно, используя академические правила. Если это тоже не помогает, то алгоритм опирается на записи дикторов и определяет, на каких частях слов они делали акценты. Затем система рассчитывает, сколько в составленной транскрибации фрагментов длиной 25 миллисекунд [7]. Каждый фрагмент она описывает различными параметрами: частью какой фонемы (фонема — минимальная единица звукового строя языка) он является, какое место в ней занимает, в какой слог входит эта фонема и т.д. После этого система воссоздает подходящую интонацию с помощью данных о фразах и предложениях 3. Преобразовать транскрибацию в речь Этот этап во многом зависит от используемого метода синтеза. Программа может просто сопоставлять имеющиеся в словаре отрывки и озвучивать речь путем склейки подходящих аудиофрагментов, как при компиляционном синтезе. Аналогичным образом (хотя и более совершенно) работает синтез по фонетическим правилам. Для параметрического синтеза схема другая. Чтобы прочитать подготовленный текст, система использует акустическую модель. Она устанавливает связь между фонемами и звуками, придавая им верную интонацию благодаря машинному обучению. Чтобы что-то сказать, робот использует генератор звуковых волн, в который загружаются все данные о частотных характеристиках фраз, полученные от акустической модели [6]. 1.5. Развитие технологии TTS и её перспективыНа данный момент существуют системы аудиосинтеза, уровень синтеза речи которых на одном уровне с человеческим (Tacotron, Wavenet и т.д.) [5]. Однако количество используемых для них вычислительных ресурсов слишком велико для рядового пользователя. Кроме того, речь создается данными системами посредством искусственного интеллекта и баз данных тысяч голосов, что является крайне трудоемкой задачей, в связи с чем постоянное использование таких программ не представляется возможным[3]. Однако главной проблемой таких систем является факт того, что даже они не создают речь, которую человек сможет отличить по тембру и другим тонкостям человеческой речи. Однако если не брать во внимание данные единичные системы, то пока что рано говорить о каком-то перспективном будущем на ближайшие десятилетия для синтеза речи по правилам, так как звучание все ещё напоминает больше всего речь роботов, а местами это ещё и труднопонимаемая речь [4]. Поэтому технология разработки частично отвернулась от фактического построения синтеза речевых сигналов, но все так же продолжает использовать простейшую сегментацию записи голоса. ГЛАВА 2: ПРАКТИКАПрограмма будет создана на языке программирования С++ при помощи фреймворка Qt. Первоначальный замысел – создать одну программу, иллюстрирующую наилучшую реализацию технологии компьютерного аудиосинтеза речи (TTS) был сменен на идею создания 2 программ – одна программа будет иллюстрировать формантный синтез, другая – параметрический. Конечная задача будет сравнить данные программы, их эффективность и тд. Программа, использующая параметрический синтез, будет оконной, формантный – консольная. Принцип работы программыПринцип работы обоих программ соответствует основному принципу работы программ – синтезаторов, описанному в п.1.4. Будет различаться лишь принцип работы относительно метода синтеза. Программа формантного синтеза загружает базу формант английского языка, найденную мною в сети Интернет, затем пользователь вводит в консоль необходимый текст, и печатает Enter. Затем модуль TTS производит озвучивание текста, который воспроизводится компьютером. Оконная программа с параметрическим синтезом работает так: пользователь вводит в поле ввода текст, затем выбирает путем нажатия необходимые параметры, затем модуль TTS, используя встроенную в программу акустическую модель, озвучивает введенный текст. 1.2. Скриншоты, фрагменты кода  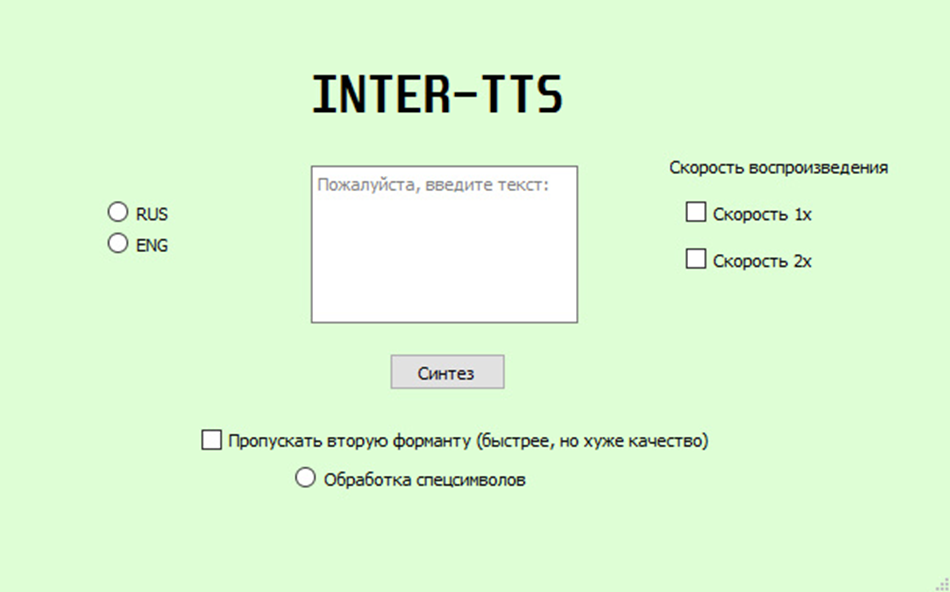 ЗАКЛЮЧЕНИЕВыводы по итогам проделанной работыФормантный синтез - морально устаревший способ аудиосинтеза Выполнить все цели и задачи проекта можно было бы лишь благодаря значительным ресурсам компьютера За связкой параметрический анализ - ИИ стоит будущее аудиосинтеза 1.2. Список используемой литературы1. Б. М. Лобанов, Л. И. Цирульник «Компьютерный синтез и клонирование речи». — Минск, «Белорусская Наука», 2008. — 316 стр. 2. Джеймс Л. Фланаган. Анализ, синтез и восприятие речи. — М., Связь, 1968. — 394 с. 3. В. Н. Сорокин. Синтез речи. — Наука, 1992. 4. Dutoit, Thierry. An Introduction to Text-to-Speech Synthesis. — Kluwer Academic Publishers, 1997. 5. Рыбин С. В. СИНТЕЗ РЕЧИ Учебное пособие по дисциплине «Синтез речи». — СПб: Университет ИТМО, 2014. — 92 с. 6. https://voximplant.ru/blog/how_does_text_to_speech_work 7. https: //en.wikipedia.org/wiki/Speech synthesis 8. Синтез и распознавание речи. Современные решения, Фролов А. и Г., 2003 9.https://ru.bmstu.wiki/%D0%A0%D0%B0%D1%81%D0%BF%D0%BE%D0%B7%D0%BD%D0%B0%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D1%80%D0%B5%D1%87%D0%B8 (Национальная библиотека им. Н. Э. Баумана) 10. Структура систем синтеза и распознавания речи, Р.В. Мещеряков, 2009 |