СР по Организция комп. Структура принцип работы процессора Celeron
 Скачать 129.12 Kb. Скачать 129.12 Kb.
|

|
ТАШКЕНТСКИЙ УНИВЕРСИТЕТ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ Самостоятельная работа по Организация компьютера на тему: Структура принцип работы процессора Celeron Поток: CAO206-1 Студент: Калдарбеков Азимбек Ташкент-2022 План Общая характеристика Intel P6 Особенности архитектуры Достоинства Недостатки Общая характеристика Celeron — большое семейство низкобюджетных, офисных x86-совместимых процессоров компании Intel. Celeron - облегченный вариант процессора Pentium-2, появившийся на рынке в апреле 1998 года. Эти процессоры относятся шестому поколению процессоров. С точки зрения принципа организации вычислений, главное отличие этого поколения заключается в динамическом исполнении, при котором внутри процессора инструкции могут исполняться не в том порядке, который предполагает программный код.  Рисунок 1 – Процессор Intel Celeron Для обхода "узкого места" - внешней шины - применена архитектура двойной независимой шины. Процессор Celeron имеет следующие отличия от Pentium-2: Если есть вторичный кэш, то он работает на полной частоте ядра и имеет объем 128 кб. Разрядность шины адреса сокращена с 36 до 32 бит (адресуемая память 4 гб). Контроль четности шины адреса ишины запроса, ECC-контроль шины данных и контроль неисправимых ошибок шины отсутсвует, как и сигнал инициализации шины. Процессоры предназначены только для однопроцессорных конфигураций: из сигналов запроса шины офицально остался только BR0#, что не позволяет реализовать симметричные двухпроцессорные конфигурации. Реально сигнал BR1# в некоторых моделях присутствует. Коэффициенты умножения фиксированы. Внешняя частота - 66 МГц (задается заземленными линиями BSel[1:0]#). Все процессоры линеек Pentium Pro, Pentium-2, Celeron(Рисунок 1) и Xeon имеют одинаковую базовую микроархитектуру и по этому признаку относятся к одному большому семейству процессоров P6. Intel P6 P6 — суперскалярная суперконвейерная архитектура, разработанная компанией Intel и лежащая в основе микропроцессоров Pentium Pro, Pentium II, Pentium III, Celeron и Xeon. В отличие от x86-совместимых процессоров предыдущих поколений с CISC-ядром, процессоры архитектуры P6 имеют RISC-ядро, исполняющее сложные инструкции x86 не напрямую, а предварительно декодируя их в простые внутренние микрооперации. Первым процессором архитектуры P6 стал анонсированный 1 ноября 1995 года процессор Pentium Pro, нацеленный на рынок рабочих станций и серверов. Процессоры Pentium Pro выпускались параллельно с процессорами архитектуры P5 (Pentium и Pentium MMX), предназначенными для персональных компьютеров. 7 мая 1997 года компанией Intel был анонсирован процессор Pentium II, пришедший на смену процессорам архитектуры P5. В 2000 году на смену архитектуре P6 на рынке настольных и серверных процессоров пришла архитектура NetBurst, однако архитектура P6 получила своё развитие в мобильных процессорах Pentium M и Core. В 2006 году на смену процессорам архитектуры NetBurst пришли процессоры семейства Core 2 Duo, архитектура которых также представляет собой развитие архитектуры P6. Функциональные устройства Процессоры архитектуры P6 состоят из четырёх основных подсистем: Подсистема упорядоченной предварительной обработки (англ. In-Order Front End, IOFE) — отвечает за выборку и декодирование инструкций в порядке, предусмотренном программой, и предсказывает переходы. Ядро исполнения с изменением последовательности (англ. Out-of-Order Core, O2C) — отвечает за исполнение микроопераций в оптимальном порядке и организует взаимодействие исполнительных устройств. Подсистема упорядоченного завершения (англ. In-Order Retirement, IOR) — выдаёт результаты исполнения в порядке, предусмотренном программой. Подсистема памяти (англ. memory subsystem) — обеспечивает взаимодействие процессора с оперативной памятью. Подсистема упорядоченной предварительной обработки К устройствам этой подсистемы относятся: Модуль и буфер предсказания переходов (Branch Target Buffer, BTB) — предсказывают переходы и хранят таблицу истории переходов. Для предсказания используются как динамический, так и статический методы. Последний используется в том случае, если динамическое предсказание невозможно (в таблице переходов отсутствует необходимая информация). • Декодер инструкций (Instruction Decoder) — преобразует CISC-инструкции x86 в последовательность RISC-микроопераций, исполняемых процессором. Включает два декодера простых инструкций (Simple), обрабатывающих команды, которые могут быть выполнены одной микрооперацией, и декодер сложных инструкций (Complex), обрабатывающего команды, для которых нужно несколько (до четырёх) микроопераций. • Планировщик последовательностей микроопераций (Microcode sequencer) — хранит последовательности микроопераций, используемые при декодировании сложных инструкций x86, требующих более четырёх микроопераций. • Блок вычисления адреса следующей инструкции (Next IP Unit) — вычисляет адрес инструкции (англ. instruction pointer, IP), которая должна быть обработана следующей, на основании информации о прерываниях и таблицы переходов. • Блок выборки инструкций (Instruction Fetch Unit, IFU) — осуществляет выборку инструкций из памяти по адресам, подготовленным блоком вычисления адресаследующей инструкции. Процессоры на ядре Tualatin дополнительно содержат блок предвыборки инструкций (Prefetcher), который осуществляет предварительную выборку инструкций на основании таблицы переходов. Ядро исполнения с изменением последовательности Исполнение с изменением последовательности, при котором меняется очерёдность исполнения инструкций, так, чтобы это не приводило к изменению результата, позволяет ускорить работу за счёт более оптимального распределения запросов к вспомогательным блокам и минимизации их простоев. К устройствам организации исполнения с изменением последовательности относятся: Таблица назначения регистров (Register Alias Table) — задаёт соответствие между регистрами архитектуры x86/IA32 (Intel Architecture 32-bit) и внутренними регистрами, используемыми при исполнении микроопераций. Буфер переупорядочивания микроопераций (Reorder Buffer) — обеспечивает выполнение микроопераций в оптимальной с точки зрения производительности последовательности. Станция-резервуар (Reservation Station) — содержит инструкции, отправляемые на исполнительные устройства. К исполнительным устройствам ядра относятся: Арифметическо-логические устройства, АЛУ (Arithmetic Logic Unit, ALU) — выполняют целочисленные операции. Блок арифметики с плавающей запятой (Floating Point Unit, FPU) — выполняет операции над числами с плавающей точкой. Процессоры Pentium III и выше имеют также блок, осуществляющий исполнение инструкций SSE (SIMD FPU). Блок генерации адресов (Address Generation Unit, AGU) — вычисляет адреса данных, используемых инструкциями, и формирует запросы к кешу для загрузки/выгрузки этих данных. Подсистема упорядоченного завершения Регистровый файл (Register File) — хранит результаты операций (состояние регистров IA32 для исполняемых инструкций). Буфер переупорядочивания памяти (Memory Reorder Buffer) — управляет порядком записи данных в память для предотвращения записи неверных данных из-за изменения порядка выполнения инструкций. Блок завершения (Retirement Unit) — выдаёт результаты исполнения инструкций в той последовательности, в которой они поступили на исполнение. Подсистема памяти 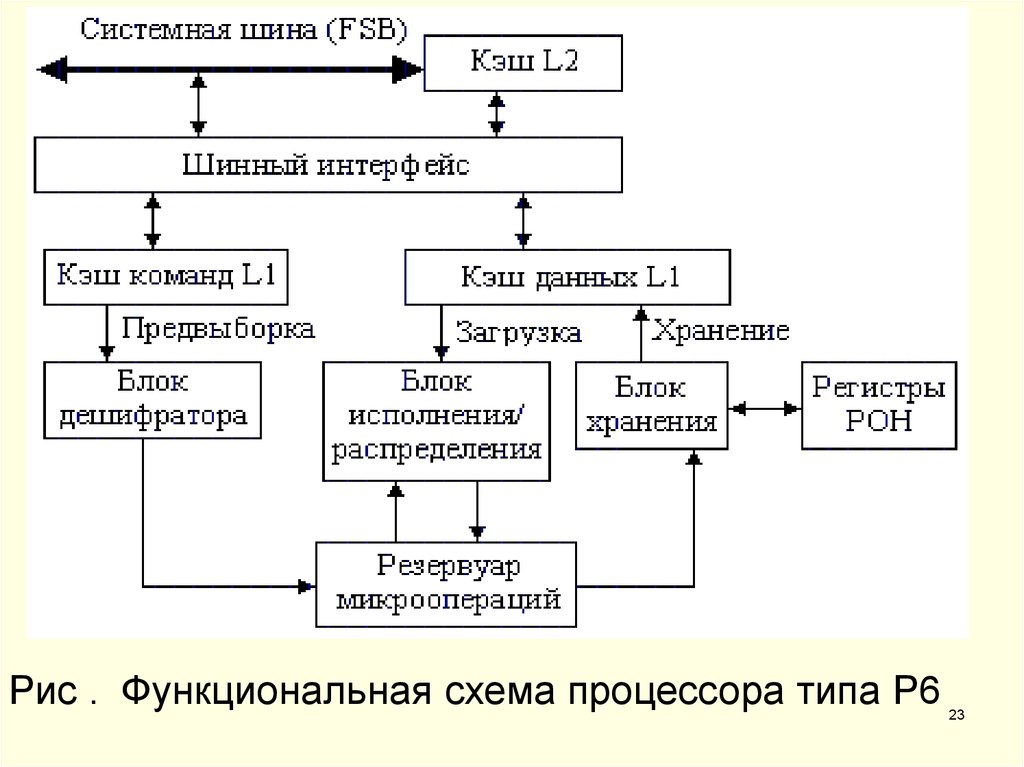 Рисунок 2 – Объём L2 процессоров архитектуры P6 Подсистема памяти осуществляет взаимодействие с оперативной памятью. К этой подсистеме относятся: Кэш первого уровня для данных (Level 1 Data Cache, L1D) — память с малым временем доступа объёмом 8 (для Pentium Pro) или 16 (для более новых процессоров) килобайт, предназначенная для хранения данных. Кэш первого уровня для инструкций (Level 1 Instruction Cache, L1I) — память с малым временем доступа объёмом 8 (Pentium Pro) или 16 килобайт, предназначенная для хранения инструкций. Кэш второго уровня (Level 2 Cache, L2). Память с малым временем доступа объёмом 128, 256, 512, 1024 или 2048 килобайт. Ширина шины L2 составляет 64 или 256 (для процессоров на ядре Coppermine и выше) бит. Процессоры Celeron на ядре Covington кэша второго уровня не имеют. Блок шинного интерфейса (Bus Interface Unit) — управляет системной шиной. На рисунке 2 показаны объёмы L2 кэша процессоров архитектуры P6 Исполнение инструкции Исполнение инструкции начинается с её выборки и декодирования. Для этого из кэш-памяти инструкций первого уровня по адресу из буфера предсказания переходов выбирается 64 байта (две строки). Из них 16 байт, начиная с адреса из блока вычисления адреса следующей инструкции, выравниваются и передаются в декодер инструкций, преобразующий инструкции x86 в микрооперации. Если инструкции соответствует одна микрооперация, декодирование проводит один из декодеров простых инструкций. Если инструкции соответствует две, три или четыре микрооперации, декодирование проводит декодер сложных инструкций. Если же инструкции соответствует большее число микроопераций, то они формируются планировщиком последовательностей микроопераций. После декодирования инструкций производится переименование регистров, а микрооперации и данные помещаются в буфер —станцию резервирования, откуда в соответствии с оптимальным порядком исполнения и при условии определённости необходимых для их исполнения операндов направляются на исполнительные блоки (максимум 5 инструкций за такт). Статус исполнения микроопераций и его результаты хранятся в буфере переупорядочивания микроопераций, а так как результаты исполнения одних микроопераций могут служить операндами других, они также помещаются и в станцию резервирования. По результатам исполнения микроопераций определяется их готовность к отставке (англ. retirement). В случае готовности происходит их отставка в порядке, предусмотренном программой, во время которой осуществляется обновление состояния логических регистров, а также отложенное сохранение результатов в памяти (управление порядком записи данных осуществляет буфер переупорядочивания памяти). Особенности архитектуры Первые процессоры архитектуры P6 в момент выхода значительно отличались от существующих процессоров. Процессор Pentium Pro отличало применение технологии динамического исполнения (изменения порядка исполнения инструкций), а также архитектура двойной независимой шины (англ. Dual Independent Bus), благодаря чему были сняты многие ограничения на пропускную способность памяти, характерные для предшественников и конкурентов. Тактовая частота первого процессора архитектуры P6 составляла 150 МГц, а последние представители этой архитектуры имели тактовую частоту 1,4 ГГц. Процессоры архитектуры P6 имели 36-разрядную шину адреса, что позволило им адресовать до 64 ГБ памяти (при этом линейное адресное пространство процесса ограничено 4 ГБ). Суперскалярный механизм исполнения инструкций с изменением их последовательности. Принципиальным отличием архитектуры P6 от предшественников является RISC-ядро, работающее не с инструкциями x86, а с простыми внутренними микрооперациями. Это позволяет снять множество ограничений набора команд x86, таких как нерегулярное кодирование команд, переменная длина операндов и операции целочисленных пересылокрегистр-память. Кроме того, микрооперации исполняются не в той последовательности, которая предусмотрена программой, а в оптимальной с точки зрения производительности, а применение трёхконвейерной обработки позволяет исполнять несколько инструкций за один такт. Суперконвейеризация. Процессоры архитектуры P6 имеют конвейер глубиной 12 стадий. Это позволяет достигать более высоких тактовых частот по сравнению с процессорами, имеющими более короткий конвейер при одинаковой технологии производства. Так, например, максимальная тактовая частота процессоров AMD K6 на ядре (глубина конвейера — 6 стадий, 180 нм. технология) составляет 550 МГц, а процессоры Pentium III на ядре Coppermine способны работать на частоте, превышающей 1000 МГц. Для того, чтобы предотвратить ситуацию ожидания исполнения инструкции (и, следовательно, простоя конвейера), от результатов которого зависит выполнение или невыполнение условного перехода, в процессорах архитектуры P6 используется предсказание ветвлений. Для этого в процессорах архитектуры P6 используется сочетание статического и динамического предсказания: двухуровневый адаптивный исторический алгоритм (англ. Bimodal branch prediction) применяется в том случае, если буфер предсказания ветвлений содержит историю переходов, в противном случае применяется статический алгоритм. Двойная независимая шина. С целью увеличения пропускной способности подсистемы памяти, в процессорах архитектуры P6 применяется двойная независимая шина. В отличие от предшествующих процессоров, системная шина которых была общей для нескольких устройств, процессоры архитектуры P6 имеют две раздельные шины: Back side bus, соединяющую процессор с кэш-памятью второго уровня, и Front side bus, соединяющую процессор с северным мостом набора микросхем. Достоинства Процессоры архитектуры P6 имели конвейеризованный математический сопроцессор (FPU), позволивший достичь превосходства над предшественниками и конкурентами в скорости вещественно численных вычислений. FPU процессоров архитектуры P6 оставался лучшим среди конкурентов до появления в 1999 году процессора AMD Athlon. Кроме того, процессоры архитектуры P6 имели превосходство над конкурентами и в скорости работы с кэш-памятью второго уровня. Pentium Pro и Pentium II имели двойную независимую шину, в то время как конкурирующие процессоры (AMD K5, K6, Cyrix 6x86, M-II) — традиционную системную шину, к которой подключался, в том числе, и кэш второго уровня. С появлением процессоров Athlon, также использующих архитектуру с двойной независимой шиной, разрыв в производительности сократился, но 256-разрядная BSB процессоров Pentium III (начиная с ядра Coppermine) позволяла удерживать преимущество в скорости работы с кэш-памятью второго уровня над процессорами архитектуры K7, имевшими 64-разрядную BSB. Однако, устаревшая на тот момент системная шина процессоров архитектуры P6 в сочетании с большим объёмом кэш-памяти первого уровня у процессоров архитектуры K7 не позволяла получить преимущество в пропускной способности памяти. Недостатки Основным недостатком первых процессоров архитектуры P6 была низкая производительность при работе с широко распространённым в то время 16-разрядным программным обеспечением. Это было связано с тем, что при работе с такими приложениями внеочередное исполнение инструкций было затруднено (так, например, процессор Pentium Pro не мог выполнить чтение из 32-битного регистра, если до этого была выполнена запись в его 16-битную младшую часть, а команда, выполнившая запись, не была отставлена). В процессоре Pentium II этот недостаток был исправлен, что привело к увеличению производительности при работе с 16-разрядными программами более чем на треть. Процессоры архитектуры P6 поддерживали работу в многопроцессорных системах, однако при этом использовалась разделяемая системная шина, что позволяло упростить трассировку системных плат, однако отрицательно сказывалось на производительности подсистемы процессор—память и ограничивало максимальное количество процессоров в системе. Отличия процессоров Pentium и Celeron, Athlon и Duron Процессор Celeron является бюджетной (урезанной) версией соответствующего (более производительного, но и значительно более дорогого) main-stream процессора, на основе ядра которого он был создан. У процессоров Celeron в два или в четыре раза меньше кэш памяти второго уровня. Так же у них по сравнению с соответствующими "родителями" понижена частота системной шины. У процессоров Duron по сравнению с Athlon в 4 раза меньше кэш памяти и заниженная системная шина 200МHz (266MHz для Applebred), хотя существуют и "полноценные" Athlon c FSB 200MHz. В ближайшее время Duron'ы на ядре Morgan совсем пропадут из продажи - их производство уже достаточно давно свернуто. Их должны заменить Duron на ядре Applebred, являющие собой ни что иное, как урезанные по кэшу AthlonXP Thoroughbred. Так же уже появились урезанные по кэшу Barton’ы, ядро которых носит название Thorton. Основные характеристики процессоров можно посмотреть в таблице в конце реферата. Есть задачи, в которых между обычными и урезанными процессорами почти нет разницы, а в некоторых случаях отставание довольно серьёзное. В среднем же, при сравнении с неурезанным процессором той же частоты, отставание это равно 10-30%. Зато урезанные процессоры имеют тенденцию лучше разгоняться из-за меньшего объёма кэш памяти и стоят при этом дешевле. Короче говоря, если разница в цене между нормальным и урезанным процессором значительная, то стоит брать урезанный. Хотя здесь необходимо отметить, что процессоры Celeron работают весьма плохо по сравнению с полноценными P4 - отставание в некоторых ситуациях достигает 50%. Это не касается процессоров Celeron D,в которых кэш второго уровня составляет 256 кбайт (128 кбайт в обычных Celeron) и отставание уже не такое страшное. |